数据结构
数据结构可视化:https://www.cs.usfca.edu/~galles/visualization/
树
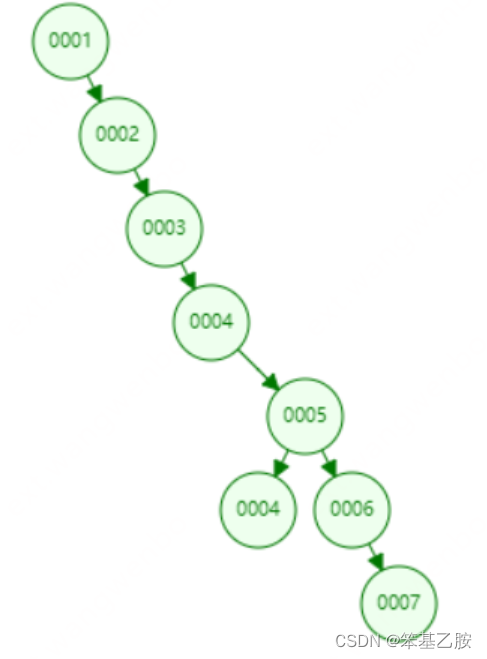
二叉树缺点: 单边节点过多时无法提高效率
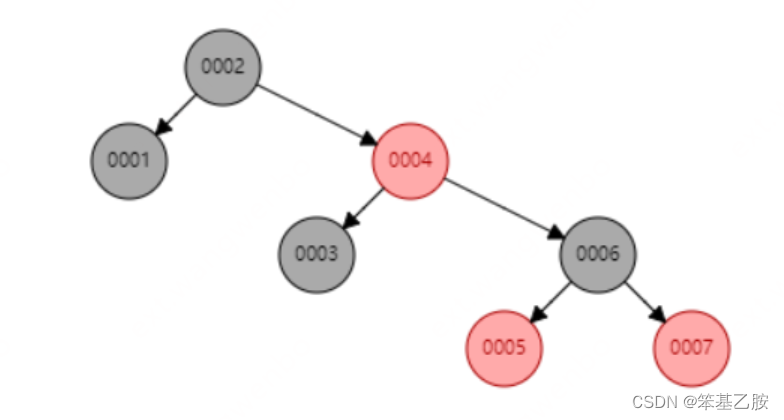
红黑树: 具有平衡功能的二叉树,解决了单边节点过多导致的效率无法提高的问题,缺点是平衡算法带来的开销以及层数过高带来的遍历开销
B树
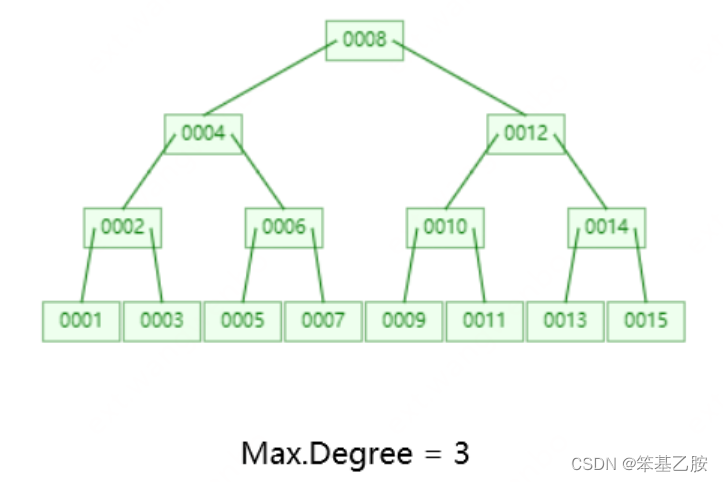
B-树:
叶节点具有相同深度,叶子节点指针为空
所有索引元素不重复
节点数据索引从左到右递增
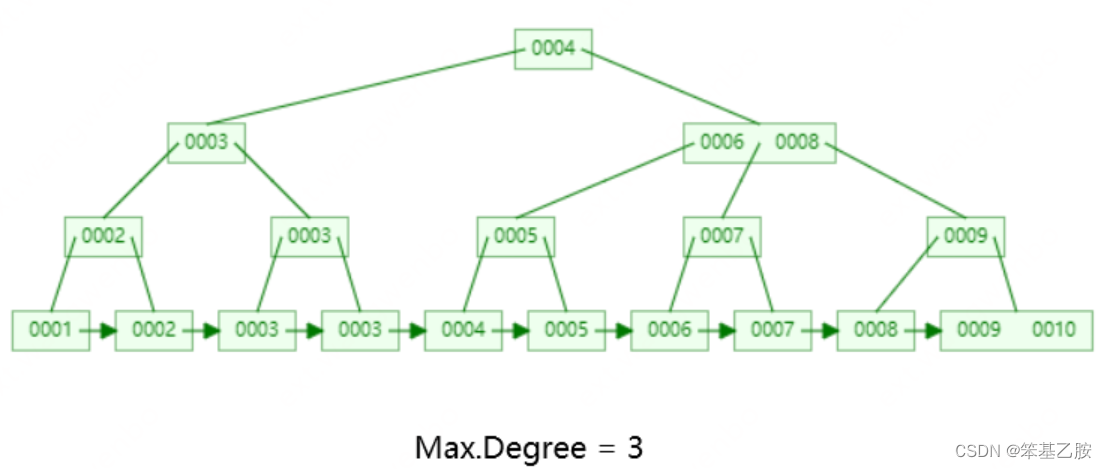
B+树:
多路平衡树
非叶子结点不存储data,只存储冗余索引,所以可以存放更多索引
叶子节点包含所有索引字段
叶子节点索引有序,用双向指针连接,提高区间访问性能
Hash表
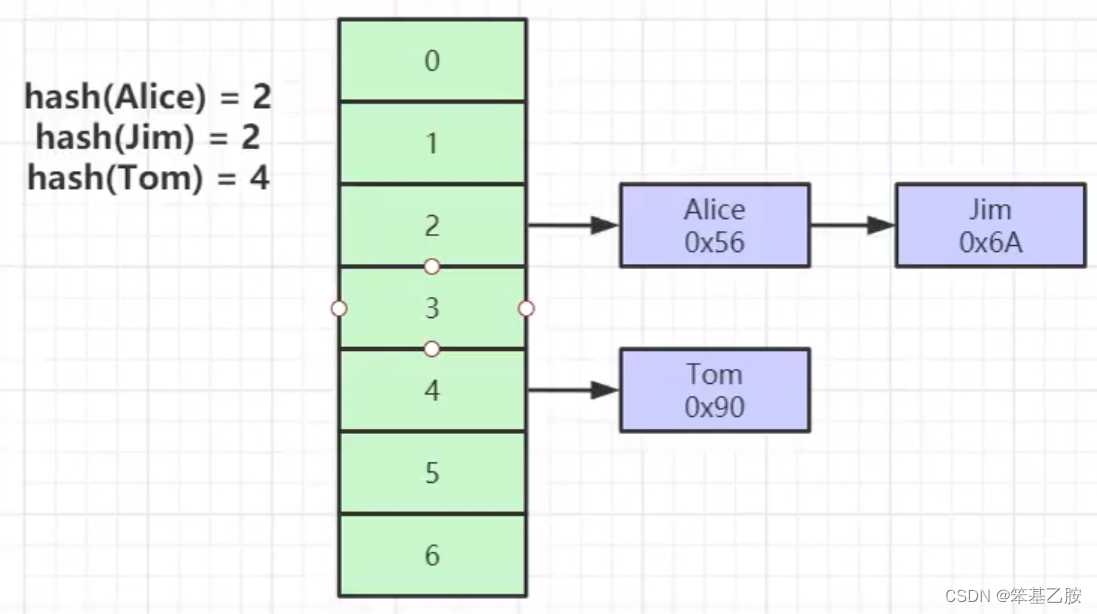
对索引的key进行一次hash计算就可以定位出数据存放位置(计算hash->遍历链表)
很多时候Hash索引比B+树索引更高效
仅能满足“=”,“IN”,不支持范围查询
hash冲突问题
存储引擎
存储引擎是介于表而言的,数据库底层数据是以文件的形式存放在磁盘上的,数据存储在数据库安装目录的data子目录里,在data目录中,每个数据库都用一个同名子目录来表示
linux中,目录为/var/lib/mysql/
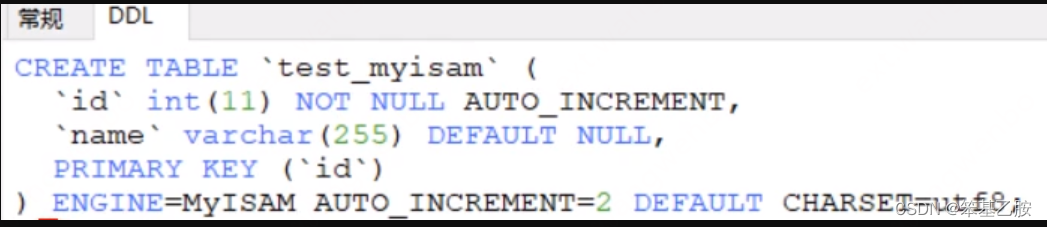
MyISAM(非聚集)
MyISAM索引文件和数据文件是分离的(非聚集)

-
frm文件存放的是表结构信息
-
MYI文件存放的是B+树的数据结构
-
- 叶子节点存的是索引数据对应的磁盘地址
-
MYD文件存放的是表中的真实数据
查询时,通过MYI索引查找到对应数据的磁盘地址,再通过地址,到MYD中查询数据
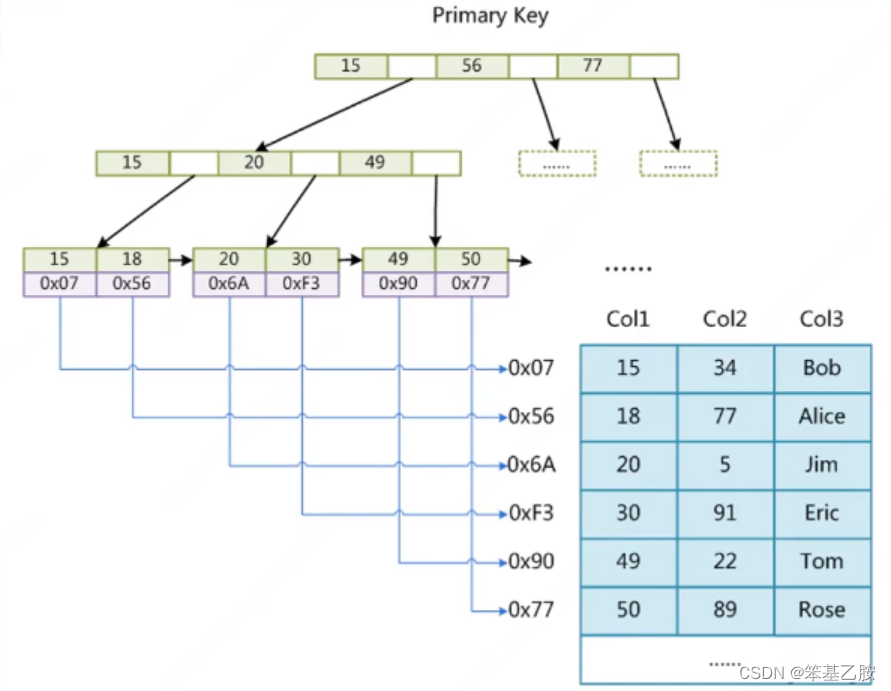
InnoDB(聚集)
-
表数据本身就是按B+Tree组织的一个索引结构文件(ibd文件)

-
聚集索引叶节点包含了完整的数据记录,一张表有且只有唯一一个聚集索引
-
InnodeDB底层用B+树来组织,如果用户没有设定主键,那么会搜索每一列,找到每条记录都唯一的一个字段来作为主键建立数据,如果找不到这样的列,则会维护一个隐藏列保证每个字段唯一,用它来作为主键构建B+树,组织数据
-
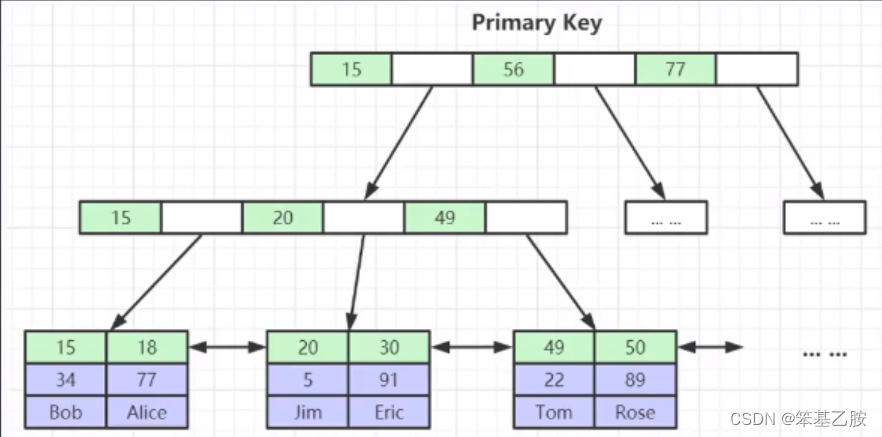
推荐使用整型的自增数据来建立主键,其一因为整型数据比较大小较快,易于建立和遍历B+树,字符串和UUID的计算(逐位比较)较慢,其二因为如果索引不自增,可能导致拆入数据后B+树叶子节点分裂,以及可能存在的树平衡操作,消耗资源
-
非聚集索引(二级索引)存放的是索引数据的主键,为了一致性和节省存储空间,查找时通过回表进行查找
Memory
在内存中存储所有数据,因此Memory类型的表访问数据非常快,但是一旦服务关闭,表中的数据就会丢失
默认使用HASH索引
应用于对非关键数据快速查找的场景
BLACKHOLE
黑洞存储引擎,类似于 Unix 的 /dev/null,Archive 只接收但却并不保存数据。对这种引擎的表的查询常常返 一个空集
这种表可以应用于 DML 语句需要发送到从服务器,但主服务器并不会保留这种数据的备份的主从配置中
工作流程
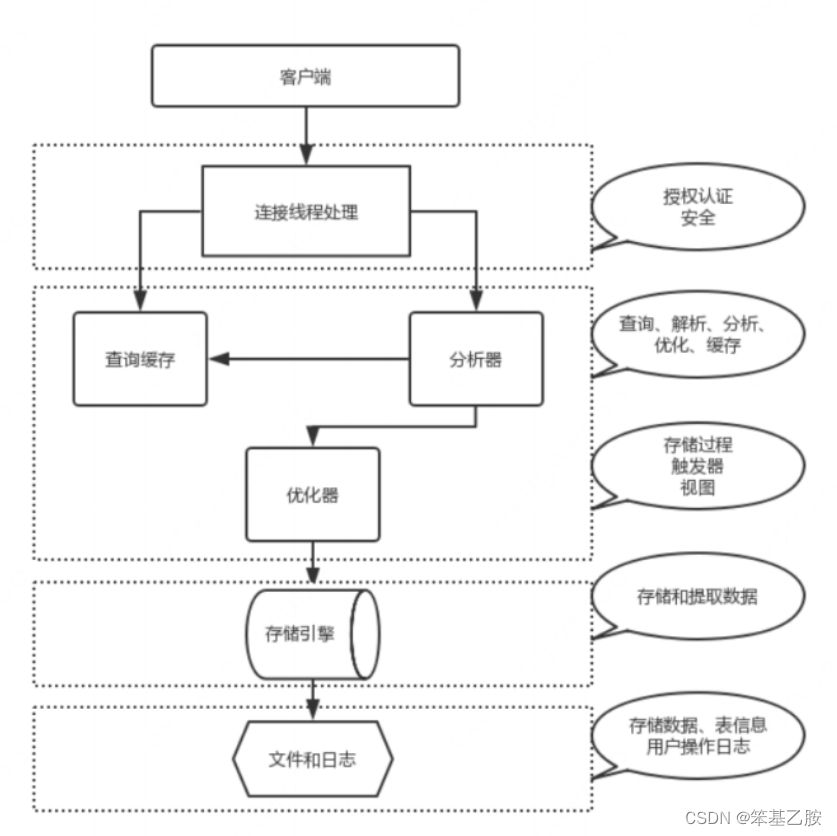
MySQL架构总共四层,上图中以虚线划分:
第一层,对客户的进行身份认证,连接处理,确保安全,并不是MySQL独有的,大多数给予网络的客户端/服务器的工具或者服务都有类似的架构。比如:连接处理、授权认证、安全等。
第二层,分析命令,查询缓存,优化命令,所有的内置函数,同时所有跨存储引擎的功能:存储过程,触发器,视图,是MySQL核心服务。
第三层:存储引擎负责MySQL中数据的组织和提取
第四层:文件系统负责存储数据,将数据存储到硬盘
事物特性
Innodedb存储引擎支持事务,事务的特性指的是ACID,原子性,一致性,隔离性,持久性。
参考文献 https://www.cnblogs.com/Bennyzion/p/14451807.html






![[NSSRound#7 Team]Web学习](https://img-blog.csdnimg.cn/2f598c448fff486b805bede0e0c9a325.png)