前言:
💞💞大家好,我是书生♡,今天主要和大家分享一下拉链表的原理以及使用,希望对大家有所帮助。 大家可以关注我下方的链接更多优质文章供学习参考。
💞💞代码是你的画笔,创新是你的画布,用它们绘出属于你的精彩世界,不断挑战,无限可能!
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞、收藏⭐、留言💬
目录
- 1. 引言
- 2. 什么是拉链表
- 3. 拉链表的基本原理
- 3.1 基本原理描述
- 3.2 拉链表原理详解
- 3.2.1 全量导入
- 3.2.2 增量导入
- 4 . 拉链表的应用场景
- 5. 拉链表的优化策略
- 6. 实现方式
1. 引言
在大数据和数据库领域,拉链表(Slowly Changing Dimension, SCD)是一种常用的数据处理技术,用于处理维度表中缓慢变化的数据。拉链表通过记录数据的历史状态,实现了对数据变化的高效追踪和查询。本文将详细介绍拉链表的基本原理、应用场景以及优化策略。

2. 什么是拉链表
拉链表是针对数据仓库设计中表存储数据的方式而定义的一种数据模型,主要用于记录数据变更历史。
- 定义:
拉链表是一种用于记录数据变更历史的表结构,它记录了事物从开始到当前状态的所有变化信息。
通过记录数据的创建时间、更新时间等字段,可以方便地查询数据变更历史。
- 结构特点:
拉链表中的每个记录通常包含字段如创建时间(create_time)、更新时间(update_time)、数据本身(如order_id、user_id等)以及可能的操作者信息等。
为了更好地跟踪数据变化,有些拉链表设计会包含起始时间(start_time)和结束时间(end_time)字段,用于标识数据的有效期。
案例:
1 . 假设有一个订单表,每天都会有新的订单产生或已有订单的状态发生变化。
2. 通过监听订单表的变化(如使用Canal等工具),可以捕获每天的订单变更数据。
3. 将这些变更数据合并到拉链表中,形成订单的历史记录。
4. 通过查询拉链表,可以方便地获取某个订单从创建到当前的所有状态变化信息。
3. 拉链表的基本原理
3.1 基本原理描述
拉链表的核心思想是将数据表中的每一行记录都视为一个版本,通过添加额外的字段(如有效开始日期和有效结束日期)来标识该版本数据的有效期。当数据发生变化时,不是直接修改原数据,而是插入一条新的记录,并将原记录的有效结束日期设置为当前时间戳,新记录的有效开始日期也设置为当前时间戳
这样,通过查询有效开始日期和有效结束日期在指定范围内的记录,就可以获取到指定时间点的数据状态。
拉链表操作步骤一般分为两部分:
- 全量导入(仅限于第一次)
- 增量导入(对于被修改以及新增的数据)
3.2 拉链表原理详解
原理详解假设第一次导入,之前数仓中没有人任何数据的,因此我们的原理详解包括 全量导入 和 增量导入。
注意:
我们一般导入都是导入前一天的数据
原始输入表:
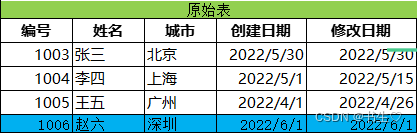
我们要的结果表:大家对比一下有什么不一样?
- 我们新增了两条数据,一个是修改的一个是我们新增的数据
- 我们原本被修改数据的失效日期变为了失效当天的日期
3.2.1 全量导入
假设我们现在有这么一个mysql数据。我们第一次导入需要全部导入到我们的数仓的ods层。
原始表创建语句:
-- 在mysql中创建库和表
DROP DATABASE IF EXISTS db_1_mysql;
CREATE DATABASE db_1_mysql
DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
USE db_1_mysql;
CREATE TABLE db_1_mysql.tb_user
(
id int,
name varchar(32),
address varchar(32),
create_date date,
update_date date
);
INSERT INTO tb_user VALUE (1003, '张三', '北京', '2022-05-30', '2022-05-30');
INSERT INTO tb_user VALUE (1004, '李四', '上海', '2022-05-01', '2022-05-15');
INSERT INTO tb_user VALUE (1005, '王五', '广州', '2022-04-01', '2022-04-26');
INSERT INTO tb_user VALUE (1006, '赵六', '深圳', '2022-06-01', '2022-06-01');
SELECT *
FROM tb_user;
数仓 ods层和dwd层建表
-- 在hive中创建库和表
drop database if exists db_ods cascade;
create database db_ods;
use db_ods;
drop table tb_user_ods;
-- truncate table db_ods.tb_user_ods;
create table db_ods.tb_user_ods
(
id int,
name string,
address string,
create_date string,
update_date string
)
partitioned by (dt string)
row format delimited fields terminated by '\t';
desc formatted tb_user_ods;
drop database if exists db_dwd cascade;
create database db_dwd;
create table db_dwd.tb_user_dwd
(
id int,
name string,
address string,
create_date string,
update_date string,
end_date string
)
partitioned by (start_date string)
row format delimited fields terminated by '\t'
;
create table db_dwd.tb_user_dwd_temp
(
id int,
name string,
address string,
create_date string,
update_date string,
end_date string
)
partitioned by (start_date string)
row format delimited fields terminated by '\t'
;
注意:
我们将dwd层的表成为拉链表,也就是说我们要将数据通过吗,mysql导入到ods中在插入到dwd的拉链表中。
我们的全量导入是不包括今天的数据的,因此我们导入的时候要筛选一下(我们假设今天是2022-06-01)因此我们要选出今天之前的数据导入
我们导入到ods层是通过Datax导入的,具体的导入方法,大家可以看我的关于Datax使用的博客。
筛选的条件
SELECT *
FROM tb_user
WHERE coalesce(update_date, create_date) < '2022-06-01';
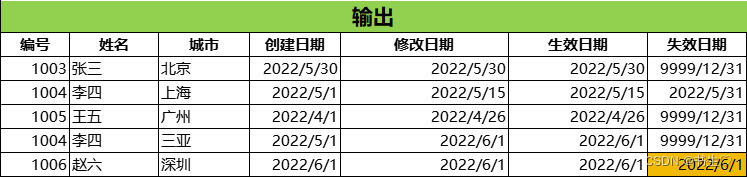
原始输入表:
将数据从mysql通过Data X导入到ods层中(分区为处理的前一天)
WHERE coalesce(update_date, create_date) < '2022-06-01'
导入到ods层的数据

我们第一次的全量导入,导入到ods层之后就可以全部导入到我们的dwd层的拉链表了。
注意:
我们在插入的时候要指定我们的开始时间和失效时间,因为是第一次导入就说我们现在的数据都是有效的,因此有效日期就是我们的分区日期,至于结束日期,我们的数据都没有结束因此我们设置为‘9999-99-99’
-- 全量数据插入拉链表
insert overwrite table db_dwd.tb_user_dwd partition (start_date)
select id,
name,
address,
create_date,
update_date,
'9999-99-99' as end_date,
dt as start_date
from db_ods.tb_user_ods;

3.2.2 增量导入
前提:假设今天时间是6月2号,处理6月1号的数据(被修改和新增的数据)
假设我们在6月1号。将id为1004的数据进行修改,城市被修改了,那么修改日期也要变,并且新增了一条数据(我表中标为蓝色的部分)
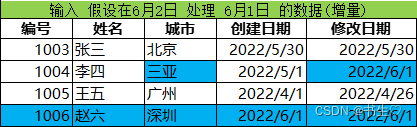
这里是MySQL的数据修改,我们还要将数据导入到ods中。
并且,我们导入的数据只是我们在6月1号修改的,所以需要筛选一下。
WHERE coalesce(update_date, create_date) = '2022-06-01'
我们通过查看 分区为‘2022-06-01’的数据

我们怎么将原本数据进行修改呢?hiv SQL是不支持行级修改的。
此时我们就要通过引入一个拉链表的临时表,进行修改数据后的存储。
我们将我们原本的拉链表与我们新增的数据进行左关联
select *
from db_dwd.tb_user_dwd a
left join (select *
from db_ods.tb_user_ods
where dt = '2022-06-01') b on a.id = b.id;

我们关联之后的表就是上面这个图这个样子。
我们怎么修改数据,由图可以看见我们关联上的数据是不为空的,因此我们直接,将失效日期变为修改日期-1
关联的条件是什么?
如果(b.id is null or a.失效日期!=‘9999-12-31’, a.失效日期,上一天日期-1(dt-1))
if(b.id is null or (b.id is not null and a.end_date != '9999-99-99'), a.end_date,
date_add('2022-06-01', -1)) as end_date,
我们将这个数据插入到我们的拉链表的临时表中
-- 临时表插入数据,拉链表关联筛选出来的
insert overwrite table db_dwd.tb_user_dwd_temp partition (start_date)
select a.id,
a.name,
a.address,
a.create_date,
a.update_date,
if(b.id is null or (b.id is not null and a.end_date != '9999-99-99'), a.end_date,
date_add('2022-06-01', -1)) as end_date,
a.start_date
from db_dwd.tb_user_dwd a
left join (select *
from db_ods.tb_user_ods
where dt = '2022-06-01') b on a.id = b.id;

此时我们的临时表存储的数据就是我们原始数据被修改之后数据了。
我们只需要将新增的数据也插入到临时表中就可以了。
--- 将新增的直接插入进来
insert into db_dwd.tb_user_dwd_temp partition (start_date)
select id,
name,
address,
create_date,
update_date,
'9999-99-99' as end_date,
dt as start_date
from tb_user_ods
where dt = '2022-06-01'
;
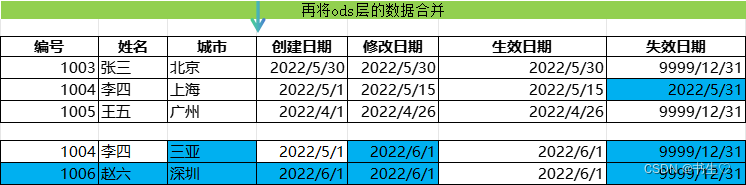
最后我们只需要**将临时表的数据覆盖到拉链表**中我们的操作就完成了。
这个地方有两个方法:
- 通过将临时表的数据覆盖到拉链表
- 先将拉链表数据清空,在insert into插入就可以了,不需要覆盖
insert overwrite table db_dwd.tb_user_dwd partition (start_date)
select id,
name,
address,
create_date,
update_date,
end_date,
start_date
from db_dwd.tb_user_dwd_temp;

注意:
我们在将数据插入到拉链表中后,要将临时表情况,因为下一次增量操作我们还要使用临时表
4 . 拉链表的应用场景
- 数据仓库:在数据仓库中,维度表的数据经常会发生变化,如客户信息的更新、产品属性的修改等。使用拉链表可以方便地追踪这些变化,并生成历史报表。
- 数据分析:在数据分析中,经常需要比较不同时间点的数据状态,以发现数据的变化趋势。拉链表可以方便地提供这种比较功能。
- 实时数据监控:在实时数据监控系统中,需要实时反映数据的最新状态。通过定期更新拉链表,可以实时获取数据的最新状态,并进行相应的处理。
5. 拉链表的优化策略
- 索引优化:为了提高查询效率,可以为拉链表的关键字段(如主键、有效开始日期和有效结束日期)建立索引。这样可以加快查询速度,提高系统的响应能力。
- 数据压缩:由于拉链表会记录数据的多个版本,因此可能会占用较多的存储空间。为了节省存储空间,可以采用数据压缩技术对拉链表进行压缩。常用的压缩算法包括gzip、snappy等。
- 分区存储:对于数据量较大的拉链表,可以采用分区存储的方式将数据分散到多个物理存储设备上。这样可以提高数据的读写性能,并降低单点故障的风险。
- 定期清理:随着时间的推移,拉链表中的历史数据可能会变得不再重要。为了节省存储空间和提高查询效率,可以定期清理这些不再重要的历史数据。清理策略可以根据业务需求和数据保留期限来制定。
6. 实现方式
拉链表的实现通常涉及到数据的增量抽取、转换和加载(ETL)过程。
在数据仓库中,可以通过ETL工具对操作型数据库按照时间字段增量抽取数据,形成每天的增量数据,并合并到拉链表中。










![[leetcode]minimum-absolute-difference-in-bst 二叉搜索树的最小绝对差](https://img-blog.csdnimg.cn/direct/0df5dba0258a4927b8d0961be46a87f2.png)