Gavin大咖亲自授课:将大语言模型与直接偏好优化对齐
Align LLMs with Direct Preference Optimization

直接偏好优化( Direct Preference Optimization)这绝对是天才性的算法。你会看到数学的巨大力量和巨大价值,你一定会很兴奋和激动。那个时候,Gavin大咖讲直接偏好优化的时候,说直接偏好优化确实是非常棒的,不过那个时候模型本身还不是那么强。所以虽然数学公式非常优美,非常优雅,但在测试直接偏好优化的时候,发现跟官方说的效果不一致,确实也不如近端策略优化算法的效果。但现在尤其是GPT4的版本或者其他同类型的新模型出现之后,我们发现这个模型,在识别什么是好的一种行为和选项方面,发现确实是增强了很多。 在实际工程中测试的时候会发现, 直接偏好优化算法在突破了某个点,就是模型本身已经足够强的情况下,直接偏好优化算法确实是比近端策略优化算法强很多。
这个时候 就会设计一个很重要的一个地方,就是到底你在做 不同的算法选项的时候,你考虑的一些核心问题是什么?大家可以分享一下自己思考的一些核心问题。 大模型 是一个分布式的概率的模型,它本身原生的不可控 ,那你会考虑哪些因素?
有同学反馈是并行计算,而且是可靠的并行计算, 我们在最开始的时候,跟他们分享十道算法以及实现工程化实践的时候。因为Gavin大咖授课是完全从工程化的角度,如果是讲学术,那每一个点都可以讲很多天,但大家要产出价值,而且是要直接产出价值。就是我有这样一个业务需求,你让这个模型服从于你的业务分布。因为你所有的目标都是让你的模型可控的服从于你业务的分布。那你设计一个算法,你做这个模型对齐的时候,是否能并行的快速的计算,而且这次计算是否一定能够成功。
当基座模型本身不够强的时候,发现由于Hugging Face提供了很多库,确实是使用近端策略优化的时候效果更好。但是发现GPT 4和同类的开源模型或者其他产品发布之后,会发布整个的参数之类,直接可以下载,在它的基础上进行进一步的优化。当你不依赖外在的组件,什么叫无依赖外在的组件?因为你这里面必须依赖一个,其实依赖必须依赖两个事情。第一个事情你要依赖于奖励模型reward model,这肯定会涉及reward model本身的质量以及可靠性。另外一个必须依赖很多人工层面的干预,包括实时的一些人工层面的干预。大家没做过像这种级别的落地,当然也不希望你做这个落地,因为这个过程确实是很痛苦。
最重要的是你一次大概率不会成功。你做了很多事情,你的经理或者老板直接问,下次一定会成功吗?这个就比较恐怖了。所有的落脚点就在你怎么有一种方式,能够确保你在模型对齐的时候一定是成功的。但这个成功,你可能面临的一个问题,只是多大程度成功的问题。所以就很有必要去除掉其他很多依赖的组件。
直接偏好优化就是这样的一个里程碑式的算法。直接偏好优化算法来自于斯坦福大学,直接偏好优化算法是最近大模型或者生成式行业发展史的一个转折性的里程碑,它的价值相当于什么呢?拿一下类比,你就知道了,相当于就是CoT的概念。大家如果做应用开发,就知道CoT是多么重要,或者相当于ReAct带来对实际生产力提升的影响。
只不过直接偏好优化算法是从模型的层面来考虑的,现在想问大家的一个很重要的事情,就是你觉得它如果不依赖于这个奖励模型,该怎么去调整模型服从于人们的价值,或者所谓正确的行为呢?你在思考这个问题的时候,该怎么考虑你做什么呢?当你要考虑做什么的时候,你肯定考虑是一组关系的相互作用。这一组关系的相互作用结果,转过来是让你这个目标模型变得服从于业务的分布,或者是人类的价值观,或者领域的价值观。
那你要考虑你有哪些东西可用,你现在如果不要奖励模型了,但你会有训练数据,训练数据可能是preference data,或者是the prompt instructing data,然后还有这个instructing fine tune model,没有其他的东西了,这个时候怎么让模型知道什么是更期待的行为。
大家可以表达一下自己的想法,基于目前的一个理解。但这个问题有点难。如果不难的话,也不会说直接偏好优化算法这篇paper是里程碑式的,是业界转折性的成果,也导致很多公司都可以很好的去做foundation model。
大家可以输入一下自己的想法。然后你就会发现我们在看到直接偏好优化算法和实现的时候,就会发现这确实是天才性的。
模型相互评价,磊子提供的这个想法是非常好的一个想法。磊子,我想反问一下你,你觉得大模型可以自己评价吗?告诉模型我们的偏好是什么,你觉得模型可以自己知道自己的偏好是什么吗?
同学回答:在强化学习的最大奖励化转化为损失函数,可以直接基于监督学习进行训练。但是强化学习最大奖励和转化为什么可以直接基于监督学习?这个监督学习的数据是来自于什么地方呢? 当初读了直接偏好优化的这个论文之后,Gavin大咖读到这篇论文,就立即自己站起来,起身为作者鼓掌的那种感觉。确实感觉这人的智慧太厉害了。 这是你对大模型有本质提升的另外一个极为关键的力量。
我看你们用偏好训练来回答,这个确实也是一个非常好的方式。大家提的这些想法,基本上都是一致的信息。这个一致的信息就是你要有个参照物,尝试建立一种关系,这些想法都是正确的。那我们来看一下,上午发的两幅图,一个是公式的推导,还有一个是sigmoid函数的图,再次转发一下,马上我们会见到作者是天才性的创新。
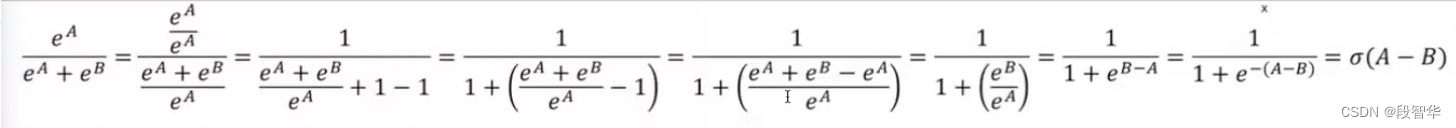
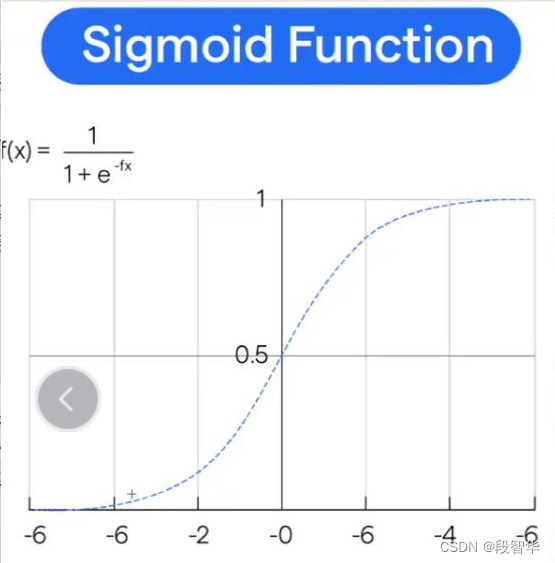
我们先看一下它到底是怎么表述的,他的名称就非常有意思, Direct Preference Optimization,直接偏好优化,它的核心叫direct。我看一下大家的聊天区。偏好这件事情是我们前面已经反复谈了,非常感谢智华,转发了上午发的公式图片。另外一个叫做数学公式,是sigmoid函数。 刚才问了大家该具体怎么做,大家都比较倾向于有一个参照物,但是这篇论文本身立即就直接告诉你, 是direct preference optimization。 论文非常精彩的地方是在说,your language model is secretly a reward model.

在训练的时候,进行模型对齐时,基础模型是instructions fun tune的model,它本身就是一个reward model。所以这篇论文的一个想法,如果模型本身就是一个reward model。模型能够识别出这是一个好的,还是一个不好的东西。你自己想一下,模型对齐之后,从基础模型的角度来讲,模型具有能够识别出什么是preferred,什么是not preferred的这样一种能力,但模型为什么具有这种能力?这个问题很关键
模型基于KL divergency,让自己的参数服从数据的分布,数据本身是人类产生的,人类所有产生的数据都在表达我喜欢这个东西,或者我不喜欢这个东西,因为他比较擅长基于comparison对比或者contrast对比,在A和B之间,他会做出一个选择。而由于模型基于所有的数据,就习得了人类天生的这种基于对比关系做出的,相对喜欢和不喜欢的这种选择;或者说第一喜欢,第二喜欢,第三喜欢的这种选择。
当看见这篇论文标题的时候,就感觉很震惊,我就立即知道他会产生一种什么方式了。就是他使用你要训练的这个目标模型本身作为一个reward model,这时候就去掉了一个组件了。但去掉了一个组件,也会涉及一个很重要的点,就是它去掉了这个近端策略优化,我们前面说了为什么要做近端策略优化的时候,要用这个奖励模型reward model。所有的东西都是环环相扣的。所以这篇论文就涉及了一个直接偏好优化的概念,这是石破天惊的。Gavin大咖过去两三年读的很多论文,第一次读完之后站起来远程为对方鼓掌。我们现在知道它是去掉了这个reward model,把为自己作为一个reward model。

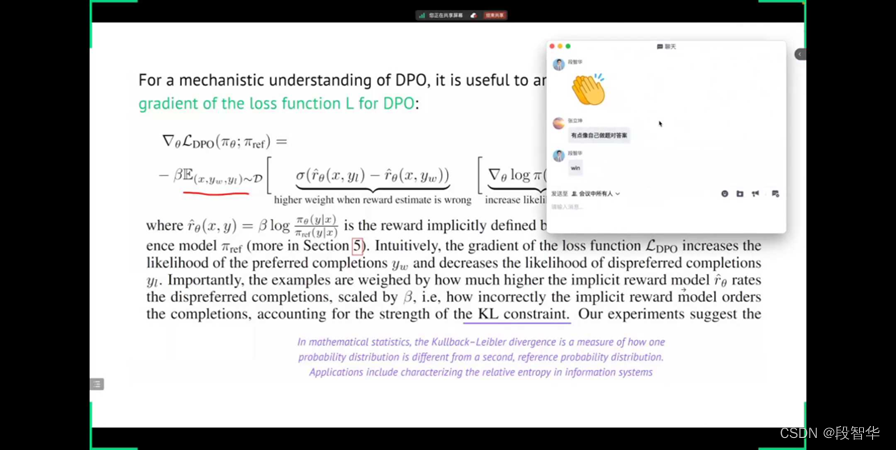
这个时候他是借助了模型本身的行为特征。这个模型本身行为特征是通过KL divergence无限的趋近于数据,而数据是由人类产生的,所以它很好的表达了这个偏好。
直接偏好优化实现了两点。
-
第一点就是explicitly reward estimation and reinforcement to learning to learn the policy using a single maximum likelihood objective。第一它是一个奖励模型,模型本身是一个奖励模型,就是任何一个大模型本身都是一个奖励模型。因为它是基于人的数据,人天生就最擅长搞对比,说自己喜欢和不喜欢,这就形成了一个奖励模型。另外一点,就是绕过不谈这个奖励模型。
-
第二个是它本身可以实现这个强化学习。也就是在算法层面,在实际工程落地层面,通过direct preference model的optimization的方式,等价于强化学习位置。其实这也可以很直观的去理解,因为它本身这个奖励模型,你给他输入数据的时候,他本身在强化自己特定的奖励的模式。
所以直接偏好优化直接就是取代了这两者。就是我们在做模型对比的时候,已经不再需要强化学习了。而且Gavin大咖个人强烈的建议,你能不接触强化学习就尽量不接触,因为里面的陷阱太多了,而且理论和框架也太多,主要是实际上不实用。那他就要绕过这两者,同时又要实现两者同等的功效。
绕过他们要实现同等的功效,他该怎么做呢?这显然就是一个很重要的一个问题了, 这个时候会有一个喜好偏置。
我们可以首先来看一下直接偏好优化的一个基本的数学公式,大家不要太紧张,你看见这个数学公式不要紧张,Gavin大咖一定会让你彻底的理解,而且你会感觉这绝对是天才性的实现。
立坤同学讨论这有点类似于自己做题对答案。马上再具体分析一下你这句话。我们拿这个具体的公式的细节来分析立坤的这句话。

在这边显然是期望,期望什么?我现在画一下。你对这个直接偏好优化的理解可以区分出你和身边绝大多数人,就是你对这个东西掌握了,可以直接说你掌握了这个大模型和深层次AI的精髓了,它背后代表了大模型和生成式AI的精髓。 其他很多都是工程层面的,我们在这个地方上是求期望。这个时候,X是什么?是你输入的prompt,X是prompt,这个Yw是什么?就是prefer response,就是你喜欢的那一个response。然后这个Yl显然是不喜欢的。这个一个是喜欢,一个是不喜欢,这个数据集大家已经太熟悉了

这边会有几个部分,我们先看右侧的这个increase likelihood和decrease the likelihood
- Yw这个是它偏好preferred的部分
- Yl是他不喜欢的部分
那我扩大喜欢的概率,然后我同时减少这个不喜欢的概率。他这样做的这个方式是实现用一个减法进行计算,减法表示这个差异,肯定是想把这个差异最大化
大家看他这个概率本身是怎么计算的。Yw基于prompt会产生一个结果。对这个结果取log。为什么取log?我们上午已经跟大家说的很清楚, 在Yl这个lose层面也是完全一样的计算步骤。这就是机器学习最简单、最基本的的计算。
在这个基础上的左侧,大家看一下,在这个地方它会有一个 σ。这边做higher weight when reward estimates is the wrong。这边会进行一个比较,这边会有一个 σ 的概念。

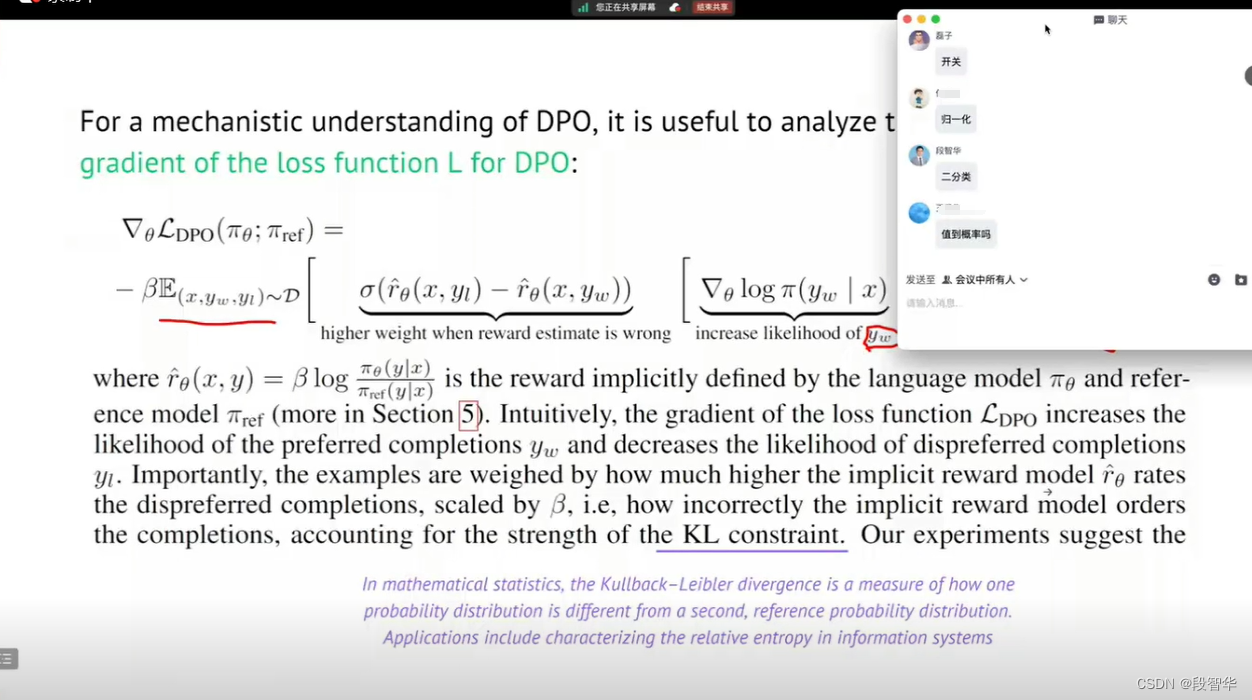
所以我们现在看一下群中大家前面发的 σ的 内容。
这个 σ,我不知道大家是否知道 σ的这个数学概念, σ的数学概念是什么?大家可以表达一下自己的想法。 σ他实际模拟的是物理世界中的什么内容。
有同学反馈是归一化,这个确实是归一化,比如说做激活函数,或者说你想归一的时候,这个确实是其中一种方式。智华的这个输入(二分类)非常好,还有磊子说是开关,这两种想法都非常好啊。
σ表达的一种意思就是当你有两个选项的时候,A、B选项,你喜欢A,不喜欢B,我怎么能够服从现实,去量化这种喜欢与不喜欢?你喜欢A,就是A大于B这件事情,从数学的角度讲,A大于B,我怎么把这个A大于B这件事情,变成数学量化的一个东西,这是 σ完成的一个很重要的内容。
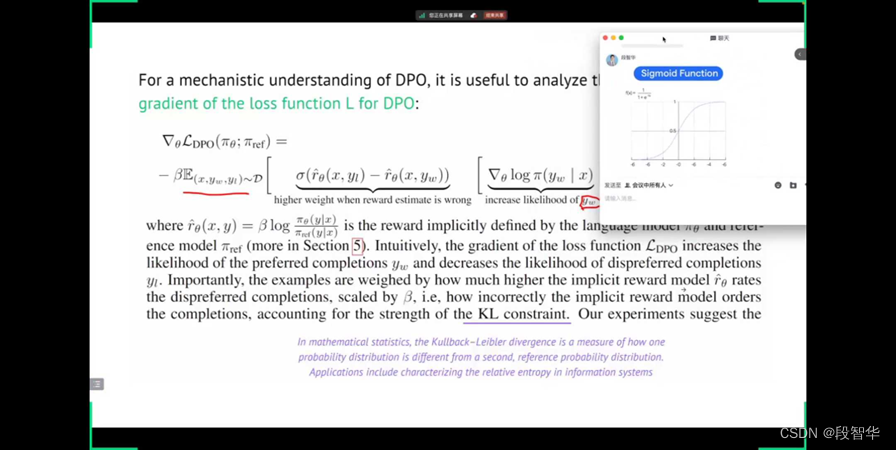
现在大家看一下,智华给我们发的这个公式,这个公式大家可以看清吗?这个公式大家应该是可以看清的。

在这边 EA除以EA加上EB,它是一个关于 σ的一个计算方式。首先,这个EA除以EA加EB是什么? 你可能会考虑这个东西,它表达的就是A大于B这件事情。也就是说你喜欢一个事情,你要想把喜欢这件事情做量化,我不知道现在大家对这个地方有没有问题,我们马上还会继续谈这个量化的过程,你就会发现他确实是天才性的。
我们正式进入这个数学公式中,看一下这个paper的部分,Kullback-Leibler (KL) divergence, or relative entropy, is a metricused to compare two data distributions. It is a concept of information theory that contrasts the information contained intwo probability distributions.。
Kullback-Leibler(KL)散度或相对熵是一种用于比较两个数据分布的度量集。它是信息论的一个概念,将包含在两个概率分布中的信息进行对比。
这里面有一个很重要的一个点, 是服从于实际的数据的情况。 我们往下来看,这边有个很重要的概念,这个叫KL divergency本身。
我们来看一下KL divergency。 回顾了一件什么事情?就是KR divergency的这个概念,我们反复的在重复这个东西, 我相信大家应该是很清楚这个KL divergency的。
它表达的是两个分布之间的差异程度, 如果没有差异就变成 零了。 如果有差异,它就是非零的一种关系, 它是要表达这个精确的量化关系。 这个时候,我们再次回到屏幕的共享部分。在KL divergency的这个基础上,会有另外一个叫Bradley–Terry model。这个model就是 DPO的基础或者说核心原理。
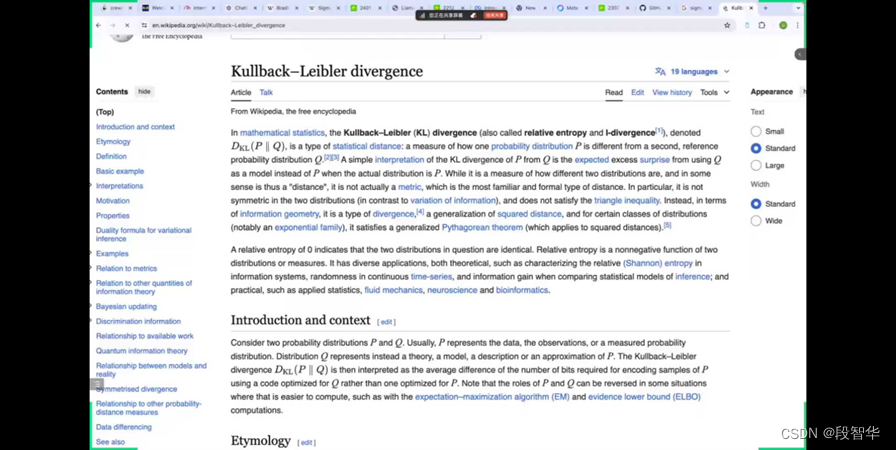

Bradley-Terry 模型是项目、团队或对象之间成对比较结果的概率模型。给定从某个总体中抽取的一对项目i和j ,该模型估计成对比较i > j 的 概率。比较i > j,可以理解为“ i优于j ”,“ i排名高于j ”或“ i击败j ”,具体取决于应用。
这个model它表达的是什么? 你要表达i大于j的数,这个怎么去表达?他会通过一个概率,也就是Pi的概率除以Pi加上Pj的概率。这个我相信大家是没有任何问题的,因为这个时候,只是一个基本的概率统计的概念。你说Pi大于Pj,那我要表达对它进行量化的话,肯定要看一下Pi的概率是什么,Pj的概率是什么。
然后要表达Pi到Pj的这样的一个关系的时候,所谓的这个关系就是模拟现实当中人们对两个选项的好恶程度。这个时候, Pi除以Pi加Pj,就表达了这种可能性,这个就很重要了。
为什么这个东西很重要?因为你就可以基于这种偏好计算出量化的损失,从而让你的模型自己训练自己, 你就不需要一个reward model了。为什么你不需要一个reward model?是因为你在这里面表达i大于j的时候,已经做出了你的选择。
这个模型本身,现在只不过是对i的这个概率除以i、j他们两个的概率之和。
这个时候我们再次来回到这里,我相信现在大家看见的是这个公式本身。
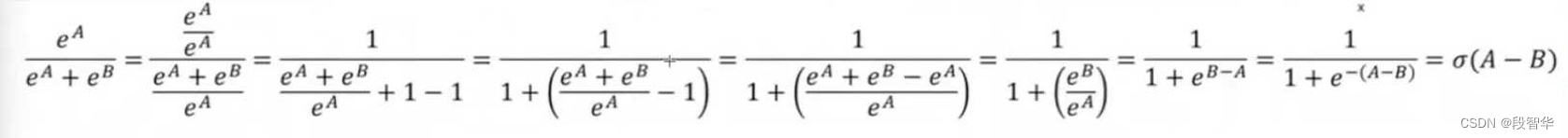
你在看见这个公式的时候, 是EA除以EA加EB的方式,你现在先不用担心这个内容,我们先看这个形式上能否走得通。因为形式能走通,其实你是P还是E这都是一样的.你现在发现这个神奇的数学公式.

致谢
感谢Gavin老师在克服时差的情况下倾囊相授[玫瑰],其深厚的知识底蕴、丰富的经验见解、详实的案例分析,赢得了学员们的极高赞誉与热烈掌声,我协会CIIT人才培养工程将持续努力,致力于研发更多能够精准解决行业痛点的高端智库课程,为企事业单位的高管学者们提供更优质的研修服务与发展思路。




《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。
LlaMA 3 系列博客
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (五)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (六)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (七)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (八)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (九)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(一)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(二)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(三)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(四)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(五)
你好 GPT-4o!
大模型标记器之Tokenizer可视化(GPT-4o)
大模型标记器 Tokenizer之Byte Pair Encoding (BPE) 算法详解与示例
大模型标记器 Tokenizer之Byte Pair Encoding (BPE)源码分析
大模型之自注意力机制Self-Attention(一)
大模型之自注意力机制Self-Attention(二)
大模型之自注意力机制Self-Attention(三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(三)
大模型之深入理解Transformer位置编码(Positional Embedding)
大模型之深入理解Transformer Layer Normalization(一)
大模型之深入理解Transformer Layer Normalization(二)
大模型之深入理解Transformer Layer Normalization(三)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(一)初学者的起点
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(二)矩阵操作的演练
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(三)初始化一个嵌入层
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(四)预先计算 RoPE 频率
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(五)预先计算因果掩码
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(六)首次归一化:均方根归一化(RMSNorm)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(七) 初始化多查询注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(八)旋转位置嵌入
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(九) 计算自注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十) 残差连接及SwiGLU FFN
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十一)输出概率分布 及损失函数计算
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(一)加载简化分词器及设置参数
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(二)RoPE 及注意力机制
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(三) FeedForward 及 Residual Layers
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(四) 构建 Llama3 类模型本身
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(五)训练并测试你自己的 minLlama3
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(六)加载已经训练好的miniLlama3模型
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (六)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (七)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (八)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(四)
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(一)Code Shield简介
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(二)防止 LLM 生成不安全代码
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(三)Code Shield代码示例
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(一) LLaMA-Factory简介
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(二) LLaMA-Factory训练方法及数据集
大模型之Ollama:在本地机器上释放大型语言模型的强大功能
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(三)通过Web UI微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(四)通过命令方式微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(五) 基于已训练好的模型进行推理
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(六)Llama 3 已训练的大模型合并LoRA权重参数
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(七) 使用 LoRA 微调 LLM 的实用技巧
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(八) 使用 LoRA 微调 LLM 的实用技巧
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(九) 使用 LoRA 微调常见问题答疑
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(十) 使用 LoRA 微调常见问题答疑
Llama模型家族训练奖励模型Reward Model技术及代码实战(一)简介
Llama模型家族训练奖励模型Reward Model技术及代码实战(二)从用户反馈构建比较数据集
Llama模型家族训练奖励模型Reward Model技术及代码实战(三) 使用 TRL 训练奖励模型
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(一)RLHF简介
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(二)RLHF 与RAIF比较
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(三) RLAIF 的工作原理
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(四)RLAIF 优势
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(五)RLAIF 挑战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(六) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(七) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(八) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(九) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(十) RLAIF 代码实战
Llama模型家族之拒绝抽样(Rejection Sampling)(一)
Llama模型家族之拒绝抽样(Rejection Sampling)(二)均匀分布简介
Llama模型家族之拒绝抽样(Rejection Sampling)(三)确定缩放常数以优化拒绝抽样方法
Llama模型家族之拒绝抽样(Rejection Sampling)(四) 蒙特卡罗方法在拒绝抽样中的应用:评估线与样本接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(五) 蒙特卡罗算法在拒绝抽样中:均匀分布与样本接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(六) 拒绝抽样中的蒙特卡罗算法:重复过程与接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(七) 优化拒绝抽样:选择高斯分布以减少样本拒绝
Llama模型家族之拒绝抽样(Rejection Sampling)(八) 代码实现
Llama模型家族之拒绝抽样(Rejection Sampling)(九) 强化学习之Rejection Sampling
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(一)ReFT简介
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(二) PyReFT简介
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(三)为 ReFT 微调准备模型及数据集
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(四) ReFT 微调训练及模型推理
Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预
Llama模型家族之Stanford NLP ReFT源代码探索 (二)interventions.py 代码解析
Llama模型家族之Stanford NLP ReFT源代码探索 (三)reft_model.py代码解析
Llama模型家族之Stanford NLP ReFT源代码探索 (四)Pyvene学习
Llama模型家族之Stanford NLP ReFT源代码探索 (五)代码库简介
Llama模型家族之Stanford NLP ReFT源代码探索 (六)pyvene 基本干预示例-1
Llama模型家族之Stanford NLP ReFT源代码探索 (七)pyvene 基本干预示例-2
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (一)Vertex AI 简介
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (二)Generative AI on Vertex AI 概览
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (三)Vertex AI 调优模型概览
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (四) Vertex AI 如何将 LLM 提升到新水平
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (五) Vertex AI:你的微调伙伴
Generative AI原理本质、技术内核及工程实践之基于Vertex AI的大模型 (六)
LangChain 2024 最新发布:LangGraph 多智能体工作流(Multi-Agent Workflows)
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(一)简介
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(二)创建代理
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(三)定义工具
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(四) 定义工具节点及边逻辑
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(五)定义图
大模型应用开发技术:Multi-Agent框架流程、源码及案例实战(六) 多智能体通用统计
大模型应用开发技术:LangChain+LangGraph+LangSmith接入Ernie Speed 大模型 Multi-Agent框架案例实战(一)
大模型应用开发技术:LangChain+LangGraph+LangSmith接入Ernie Speed 大模型 Multi-Agent框架案例实战(二)实战代码
大模型应用开发技术:LangGraph 使用工具增强聊天机器人(二)
大模型应用开发技术:LangGraph 为聊天机器人添加内存(三)
大模型应用开发技术:LangGraph Human-in-the-loop(四)
大模型应用开发技术:LangGraph 手动更新状态 (五)
大模型应用开发技术:LangGraph 自定义状态(六)
大模型应用开发技术:LangGraph 时间旅行(七)
大模型应用开发技术:LlamaIndex 案例实战(一)简介
大模型应用开发技术:LlamaIndex 案例实战(二) 功能发布和增强
大模型应用开发技术:LlamaIndex 案例实战(三)LlamaIndex RAG Chat
大模型微调:零样本提示在Amazon SageMaker JumpStart中的Flan-T5基础模型中的应用(一)
大模型微调:零样本提示在Amazon SageMaker JumpStart中的Flan-T5基础模型中的应用(二)
大模型微调:零样本提示在Amazon SageMaker JumpStart中的Flan-T5基础模型中的应用(三)
大模型应用开发 Giskard之机器学习中的biases (偏见)从何而来?(一)



![[leetcode]minimum-absolute-difference-in-bst 二叉搜索树的最小绝对差](https://img-blog.csdnimg.cn/direct/0df5dba0258a4927b8d0961be46a87f2.png)
![[吃瓜教程]南瓜书第4章决策树](https://img-blog.csdnimg.cn/direct/2d627345373f464490e8e676e718d806.png)