上期我们讲到可观测性是什么,以及它能给企业带来的价值,
戳→「老杨说运维 | AIOps如何助力实现全面可观测性(上)」一键回看上期精彩内容。
说完了什么是可观测性,这期我们来看看可观测性是如何落地实践的。
一、可观测性的建设实践
如前文提到,建设基于AIOps的全面可观测性需要能对四大运维支柱数据进行基本处理(如清洗,提取,聚合等),而后关联融合(如通过标签传递,CMDB同步等),再实现简单功能场景(如指标异常检测,多维分析,告警收敛等),最终通过可视化引擎将其编排成贴合运维事务中的综合场景,如“紧急处置”,“复盘分析”等。建设可观测性,从总体上来讲也是为了对运维全流程进行监测和追踪,对应用运行风险实行全面管控。

1.可观测的数据采集及管理
四大支柱数据的传统分析工具往往各自孤立,但是所采集的源头,也就是被监控对象却是相同的。根据大多数企业中的实战经验往往分为五层,依次为“业务-应用-软件服务-基础资源-基础环境”,这五层的数据采集方式往往有很大差异。

首先,以业务端数据的采集为例,一般指的是业务交易的数据,典型的就是交易日志,一般分为落盘的文件采集和不落盘的流推送消费。通过对交易日志进行清洗,提取以及聚合统计,可将其持久化成经典的黄金三指标(业务成功率,交易量和平均响应时长),而交易日志本生也可串联为追踪数据,对业务进行端到端的观察。
再者,对于基础资源的数据,需要对常用的操作系统日志(诸如message,syslog等)做收集,对“算、存、传”的资源指标进行采集,通常数据源会来自于zabbix或Prometheus,最终通过数据中台的流式处理持久化为资源指标,而在CMDB侧最重要的运维主数据,目前多会利用系统代理的发现能力,将主机和以及其上运行的软件服务进行闭环管理。

一般来说对于大型金融机构,如上的运维数据处理链条会有数百上千,这就需要对整个链条的管理和编排都要能做到可观测才能心里有底。
可观测性前期阶段,很多数据处理工作都是需要人工来完成,而对于多维的数据来源以及复杂的数据关系处理,需要一个集中的数据平台或数据中台来支撑。同时应该能以非常低的成本实现数据的处理,包括对数据的编排、调试以及发布等操作。降低数据准备的成本,提升数据处理的效率,为分析场景做好数据支撑。
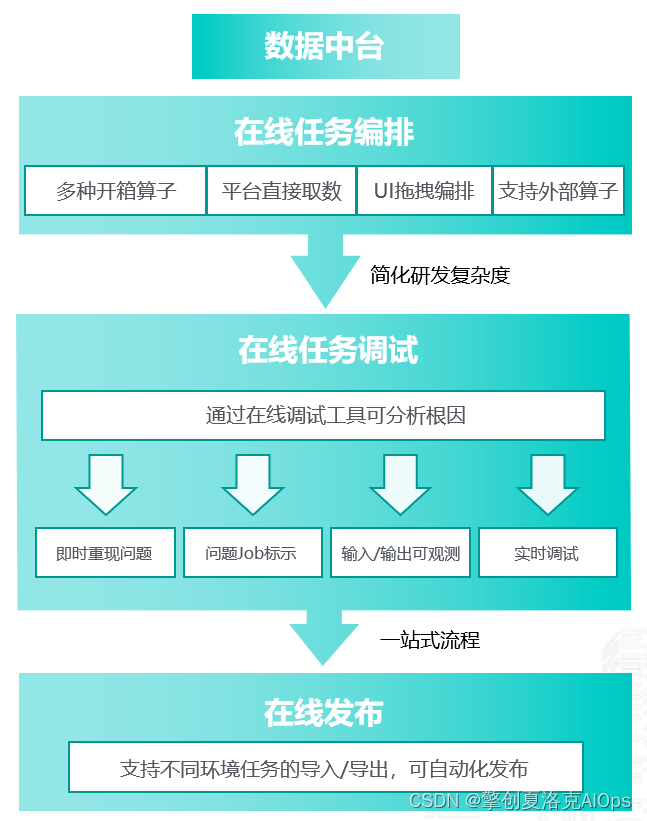
2.场景化分析
在可观测的场景化分析过程中,还是要遵从自顶向下的分析逻辑。首先要对整体的业务运行状态以及应用健康状态进行监测。包括业务健康墙、应用健康概览以及报告中心等不同展示方式。
关注应用的核心指标以及实时运行状态。当出现问题时(实时告警)可快速切换至异常处理的流程中。

通过告警自动降噪以及收敛的能力,能够快速对问题场景化,指导问题的分析路径,实现面向业务的主动式告警。
有了指标化的数据可进一步探索关联及下钻的问题。通过不同的角度观测告警,如个性化定制工作台,告警全生命周期追踪,拓扑时序融合分析等。通过交易链路分析进行时序回溯寻找根因事件,结合链路分析锁定问题的源头和错误内容。
对于发现到的问题可以总结归纳,从指标、日志等分析维度进行验证。
从日志中可以按日志模式进行异常检测,从而更早地发现异常问题;对于指标的变化可通过学习历史数据规律规划容量并预测变化趋势。
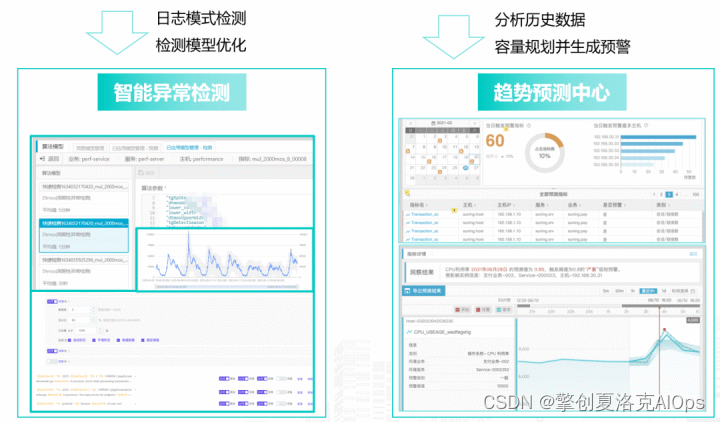
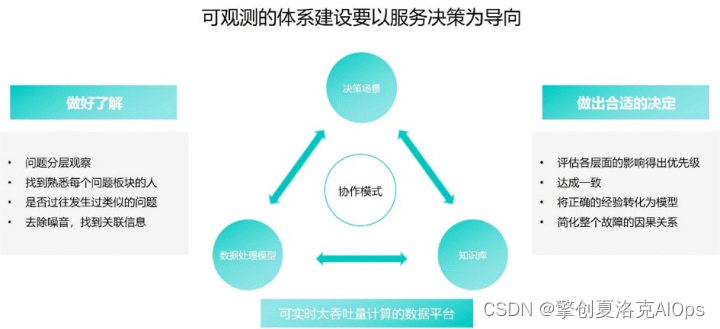
3.构建可观测的决策体系
运维自动化和智能化的大趋势中,系统可观测性是建设的基础一环,完善的可观测体系可以帮助我们屏蔽系统的复杂性,使系统整体的运行状态清晰可见,在故障防御和排查方面发挥巨大的作用。
同时我们在进行可观测的体系建设时,一定要注意以服务决策为导向。一方面事前做好各方面的监控,分层次,找关联;另一方面在观测到问题后应该能够快速评估问题影响,收敛问题并找到根因。在整个分析的过程中不断积累总结经验,持续优化到可观测体系中。
二、可观测性的用户收益
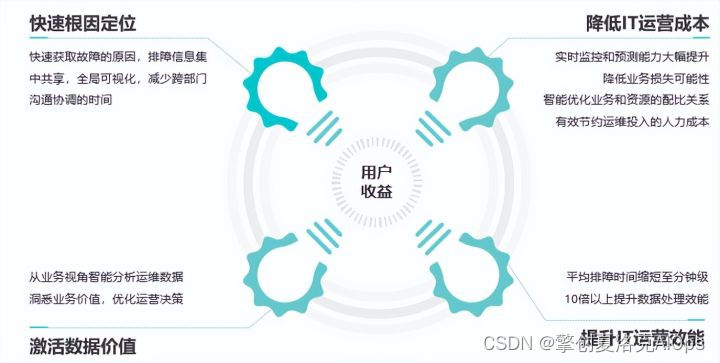
建设基于AIOps的全面可观测性的用户收益总结为以下四点:
- 快速根因定位
基于AIOps的全面可观测性能够帮助运维人员快速发现故障的原因。通过排障信息的集中共享,全局可视化,能够减少跨部门沟通协调的时间。
- 降低运营成本
实时监控和预测能力会得到大幅提升,降低业务损失可能性。能够智能优化业务和资源的配比关系,有效节约运维投入的人力成本。
- 激活数据价值
能够从业务视角智能分析运维数据,洞悉业务价值,优化运营决策。
- 提升IT运营效能
平均排障时间能够缩短至分钟级,可以达到10倍以上提升数据处理效能。
*本文部分内容来源于“双态IT联盟”

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司致力于协助企业客户提升对运维数据的洞见能力,优化运维效率,充分体现科技运维对业务运营的影响力。
行业龙头客户的共同选择

更多运维思路与案例持续更新中,敬请期待~
随手点关注,更新不迷路~