说到这个话题的时候,很多人再熟悉不过了,因为听到太多了,而且百度一大堆,但是理解到什么程度了呢,或者说只是知道这回事,但是为什么这样设计,代码中有什么可以借鉴的,在实际业务中有什么用
问题
- spring为什么需要三级缓存
- spring三级缓存为什么存放的是ObejctFactory,而不是原始对象呢,这个地方不能说是bean哟,因为还早呢
- spring为什么说使用三级缓存可以解决setter方式的注入和注解形式的单例,而比如bean的原型和构造器却无法解决
spring如何使用三级缓存
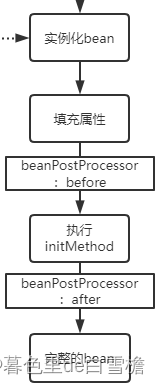
简单描述bean的创建过程
下图是bean创建的一个大体流程,先实例化bean—>填充bean里的属性—>执行实现了aware接口的实现类—>执行beanPostProcessor接口中before方法—>初始化(执行配置的initMethod方法)—>执行beanPostProcessor接口中after方法
其实大家都知道spring中大部分的bean都可以使用二级缓存来解决的,简单简述下流程
那么先说下三级缓存都分别存放什么东西:

一级缓存(单例池):完成bean,是经过完整的生命周期的包括后置处理器之后的bean
二级缓存:bean的实例化(原始对象或者代理对象)并没有经过属性填充阶段
三级缓存:bean的工厂(为什么这样做,下面有解释)
让我们来分析一下“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情景
- A 调用doCreateBean()创建Bean对象:由于还未创建,从第1级缓存singletonObjects查不到,就从第2级缓存中找,如果找不到那么就对A进行实例化,并存放在第二级缓存中,接下来就对A进行属性填充了,发现依赖注入的B还没有实例化,那么就需要对B去第1级缓存中找,发现肯定是没有的,因为还没存放进去呢,所以就需要从第2级缓存中找,那也是没有的,所以和A一样需要先实例化并存放到第2级缓存中,那么B还没结束呢,B已经实例化了需要进行接下来的属性填充了,发现又需要依赖A,那么就需要先去第1级缓存中找,找不到的,因为上面说了我们只是把实例化的A放到了第2级缓存中,第1级缓存肯定是没有的,所以A就能在第2级缓存中找到,那么就可以给B进行属性填充,那么B继续初始化完成一系列的后置处理,那么B就得到了完成的bean了,此时需要将完整的bean存放到第1级缓存中,并移除第2级缓存中(为什么需要移除,因为我们都是先从第1级缓存开始寻找的,如果找到那么就不会继续从第2级缓存找了,所以留着也只是浪费内存而已)
- 好了,上面已经创建好了完成的B的bean了,那么继续A的,A刚刚在卡在了属性填充B上,现在已经可以找到了,那么也和上面一样继续执行bean的完整生命周期了,进行初始化、后置处理器等等操作了,此时也需要将A的bean放在第1级缓存,并移除第2级缓存
这样,循环依赖就解决了
tips:这里注意一个点,下面可能要用到,所谓的实例化就是从磁盘加载.class文件到jvm中,通过反射调用其无参构造器实现实例化
让我们来分析一下“A的某个field或者setter依赖了B的代理对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情景
我们可以尝试去推下按照上面的步骤,因为刚开始我们肯定不会想到直接使用第3级缓存来处理,思路是一点点去优化和堆砌起来的
A 调用doCreateBean()创建Bean对象:由于还未创建,从第1级缓存singletonObjects查不到,就从第2级缓存中找,如果找不到那么就对A进行实例化创建对象,但是有个问题,这个时候我们肯定都不知道A需要循环依赖的,换句话说A依赖B,B依赖A,但是我先对A进行实例化创建对象的时候,还没到属性填充的阶段,更加不知道后面的B需要依赖A,所以这个时候我们只知道要对A进行实例化创建,那么问题就是这个时候到底是创建原始对象呢?还是代理对象呢?假设我们不管,就直接实例化,不生产代理对象,然后放到第2级缓存中,然后发现需要依赖B,实例化B,同样道理,此时我们也不知道此时B是生产代理对象发到缓存中呢?还是原始对象放到缓存中?那么我们也和A一样,直接把原始对象放到缓存中,这样下来B肯定是可以完成完整bean的生命周期的,然后需要对A进行属性填充阶段了,此时B肯定是可以从第2级缓存获取到,但是注意的是此时获取到的肯定是B的原始对象,但是问题是我们需要在A类中依赖的是B的代理对象呀,那怎么办呢?是不是走不对了,那么此时我们肯定会这样想,那既然A需要依赖注入的是B的代理对象,那么在刚刚B实例化的时候产生代理然后将代理对象存放到第2级缓存中不就可以了吗?的确是可以的,但是别忘记哈,刚刚是我们走到了后面才发现需要依赖的是代理对象呀,但是bean的生命周期不可能逆向执行吧,只能一个步骤一个步骤去执行,等你需要使用发现不对的时候,肯定不会再次执行一次了,也就是说第2级缓存无论是存放代理对象还是存放原始对象都无法解决,而且如果都提前在第2级缓存中存放所有的代理对象,会出现2个问题①违反了spring bean创建的生命周期设计初衷,我们都知道,bean产生代理是在初始化之后的后置处理器②就算所有的代理操作都提前到实例化阶段了,性能就很差,因为生产代理本身就耗费性能的,所以只有有需要的情况下才不得不去产生代理,如果已经生成了代理对象之后,在初始化的时候进行后置处理器中就不会再次生成了,会进行判断的,如果有代理对象就跳过,因为第3级缓存存放的是对象工厂在整个bean加载中只能调用getObject()一次,否则每次调用就会产生不同的代理对象
有代理情况存在的循环依赖了,此时就需要第3级缓存了,这个缓存就专门来处理代理对象的存放
- 按照上面的思路我们使用三级缓存来处理下如何解决呢?A 调用doCreateBean()创建Bean对象:由于还未创建,从第1级缓存singletonObjects查不到,此时只是一个半成品(提前暴露的对象),放入第3级缓存singletonFactories(这个地方只是存放获取对象工厂,刚刚上面也分析此时你并不知道是后续是需要代理对象还是原始对象)
- A在属性填充时发现自己需要B对象,但是在三级缓存中均未发现B,于是创建B的半成品,放入第3级缓存singletonFactories
- B在属性填充时发现自己需要A对象,从第1级缓存singletonObjects和第2级缓存earlySingletonObjects中未发现A,但是在第3级缓存singletonFactories中发现A,将A放入第2级缓存earlySingletonObjects,同时从第3级缓存singletonFactories删除
- 将A注入到对象B中
- B完成属性填充,执行初始化方法,将自己放入第1级缓存singletonObjects中(此时B是一个完整的对象),同时从第3级缓存singletonFactories****和第2级缓存earlySingletonObjects中删除
- A得到“对象B的完整实例”,将B注入到A中
- A完成属性填充,执行初始化方法,并放入到第1级缓存singletonObjects中
一张图解释下:

public class DefaultSingletonBeanRegistry extends SimpleAliasRegistry implements SingletonBeanRegistry {
//第1级缓存 用于存放 已经属性赋值、完成初始化的 单列BEAN
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
//第2级缓存 用于存在已经实例化,还未做代理属性赋值操作的 单例BEAN
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
//第3级缓存 存储创建单例BEAN的工厂
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
//已经注册的单例池里的beanName
private final Set<String> registeredSingletons = new LinkedHashSet<>(256);
//正在创建中的beanName集合
private final Set<String> singletonsCurrentlyInCreation =
Collections.newSetFromMap(new ConcurrentHashMap<>(16));
//缓存查找bean 如果第1级缓存没有,那么从第2级缓存获取。如果第2级缓存也没有,那么从第3级缓存创建,并放入第2级缓存。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName); //第1级
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName); //第2级
if (singletonObject == null && allowEarlyReference) {
//第3级缓存 在doCreateBean中创建了bean的实例后,封装ObjectFactory放入缓存的bean实例
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//创建未赋值的bean
singletonObject = singletonFactory.getObject();
//放入到第2级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
//从第3级缓存删除
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
}
spring为什么无法解决bean的原型或构造器的循环依赖
其实在上面的文字描述中提到过,我们都知道bean刚开始需要进行实例化,而所谓的实例化就是从磁盘加载.class文件到jvm中,通过反射调用其无参构造器实现实例化,如果是有参构造器就会出现在实例化阶段就无法完成了,还没到缓存阶段就歇菜了,spring三级缓存设计都是利用提前暴露的实例化对象或者代理对象,如果都无法实例化那就没办法使用三级缓存解决了;bean都是单例的才能放到缓存中,试想下缓存的结构都是map结构,key都是beanName肯定是唯一的,如果不是单例的,也就没有意义了