Rust
- 一、Kafka基本概念
- 1.Kafka是什么?Kafka与Flume?
- 2.Kafka的整体架构:
- 3.kafka的生产者与消费者:
- 4.kafka的Topic与日志、分区【分区可以提高咱们kafka的写入能力和存储能力】
- 5.kafka的顺序写入:
- 6.kafka的零拷贝技术
- 7.kafka的Leader到Follow之间的同步机制
- 8.kafka的offset偏移量控制
- 9.kafka的Acks与Retries【应答机制、重试】
- 10.kafka的幂等性
- 11.kafka的生产者事务、kafka的消费者&生产者事务
- 二、Kafka实操
- 巨人的肩膀
一、Kafka基本概念
1.Kafka是什么?Kafka与Flume?
- 为啥要用这个货,可能得先看看这个–做项目经验之~高速项目大数据及机器学习算法方面的思路总结
Flume算是一个日志收集工具,可以从不同的源(比如不同的节点,如Nginx服务器)中收集到数据,用来从sources源把数据发送到一个物理机上【物理源上】- Flume与kafka的区别:
- 两个都可以从不同的源中收集数据,但是
kafka的数据是直接写磁盘的,速度很快而且数据不会丢,此外kafka集群能承担的并发量还特别高。flume要持久化的话【不管你是写进磁盘中还是写进文件中还是其他什么,你flume反正很慢】肯定会拖慢你的执行速度的。- kafka为什么比flume快:
- 因为
kafka用到了顺序读写,所以kafka很快 - 因为
kafka用到了零拷贝,所以kafka很快
- 因为
- kafka为什么比flume快:
- 另外,
kafka可以重复消费,多个线程可以把某个东西重复读【该消息可以被多个消费者同时消费,并且同一个消费者可以多次消费消息服务器中的同一个记录,这也主要是因为消息服务器中可以长时间存储海量消息】,而flume中sink从channel中拿到source向channel中塞的数据后,拿一个少一个,不能重复消费。也因为这kafka可以做消息队列以及存储引擎【存磁盘速度快呀】,flume只能做日志收集工具【从不同数据源拿到数据转存到不同地方】- 一般的MQ中消息一旦被确认消费之后,消息服务器就会主动删除队列中数据,也就是消息队列中的数据不允许被重复消费
- 两个都可以从不同的源中收集数据,但是
2.Kafka的整体架构:
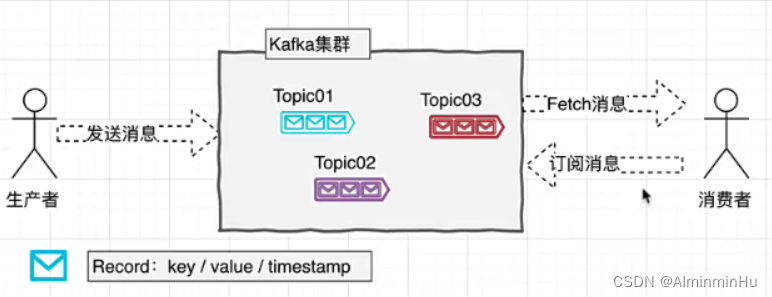
- Kafka集群
以Topic形式负责分类集群中的Record,每一个Record属于一个Topic. - 每个Topic底层都会对应一组分区的日志,分区的日志用于持久化Topic中的Record。同时在Kafka集群中,Topic的每一个日志的分区都一定会有1个Borker担当该分区的Leader,其他的Broker担当该分区的follower
Leader负责分区数据的读写操作,follower负责同步该分区的数据。这样如果分区的Leader宕机,该分区的其他follower会选取出新的leader继续负责该分区数据的读写。其中集群中的Leader的监控和Topic的部分元数据是存储在Zookeeper中.
- 生产者一次只能向一个Topic发送或者说生产消息。而消费者这里消息可以被多个消费者同时消费,并且同一个消费者可以多次消费消息服务器中的同一个记录,这也主要是因为消息服务器中可以长时间存储海量消息
3.kafka的生产者与消费者:
- kafka中每个消费者都属于一个Consumer Group组【并且发布到Topic的每条记录都会传递到每个订阅Consumer Group中的一个消费者实例】,消费者消费Topic中数据时,每个消费者都会维护本次消费对应分区的偏移量。
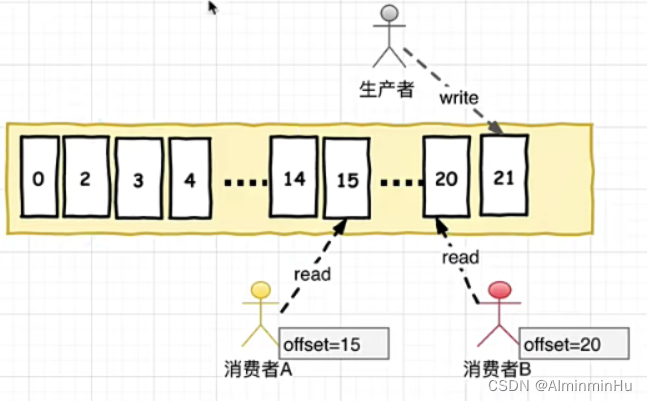
- 在消费者消费Topic中数据的时候,每个消费者会维护本次消费对应分区的偏移量,消费者会在消费完一个批次的数据之后,会将本次消费的偏移量提交给Kafka集群,因此对于每个消费者而言可以随意的控制该消费者的偏移量,因此在Kafka中,消费者可以从一个topic分区中的任意位置读取队列数据,由于每个消费者控制了自己的消费的偏移量,因此多个消费者之间彼此相互独立。
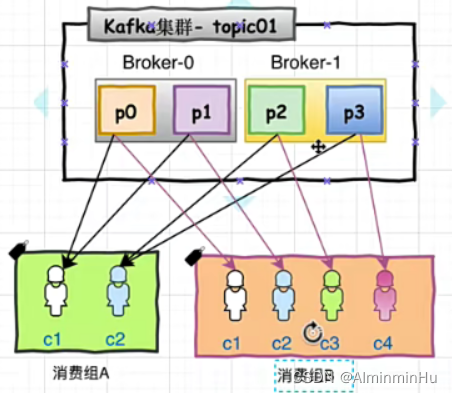
- 同一消费者组内会均分kafka集群发来的消息
- 不同消费组之间相互独立,不存在重复消费
- 消费者组内的消费者数量一般小于等于kafka集群中的分区数量,消费者组内多出来的消费者会先进行闲置,等前面有消费者断开连接之后这个闲置的或者说对于出来的消费者才能上岗消费
- 在消费者消费Topic中数据的时候,每个消费者会维护本次消费对应分区的偏移量,消费者会在消费完一个批次的数据之后,会将本次消费的偏移量提交给Kafka集群,因此对于每个消费者而言可以随意的控制该消费者的偏移量,因此在Kafka中,消费者可以从一个topic分区中的任意位置读取队列数据,由于每个消费者控制了自己的消费的偏移量,因此多个消费者之间彼此相互独立。
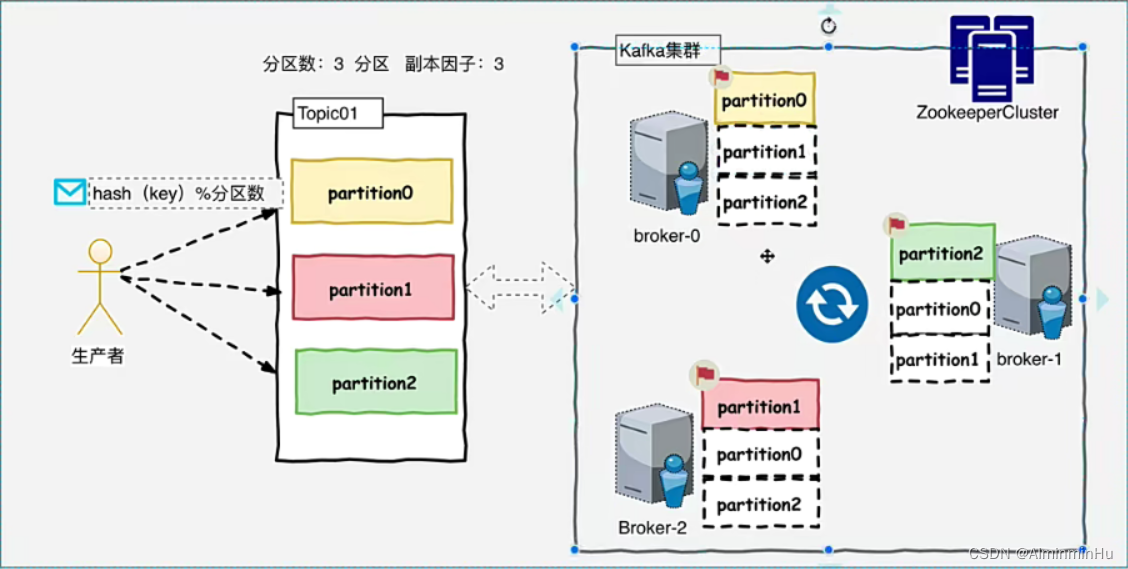
4.kafka的Topic与日志、分区【分区可以提高咱们kafka的写入能力和存储能力】
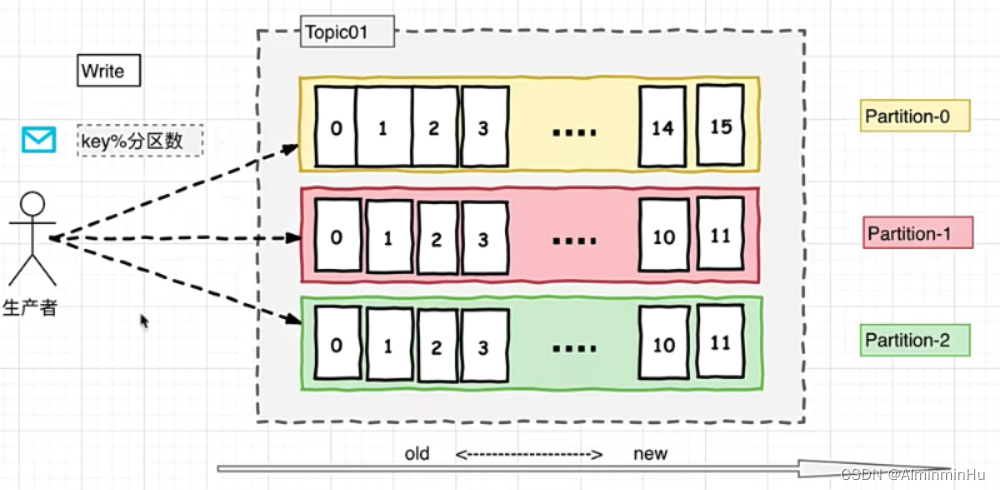
- Kafka中,生产者负责生产消息到指定分区,所有消息是通过Topic为单位进管理【每个消息最终会落到Topic的某个Partition中】,每个Kafka中的Topic通常会有多个订阅者,负责订阅发送到该Topic中的数据,Kafka负责管理集群中每个Topic的一组日志分区数据.
- 生产者一次只能向一个Topic发送或者说生产消息。而消费者这里消息可以被多个消费者同时消费,并且同一个消费者可以多次消费消息服务器中的同一个记录,这也主要是因为消息服务器中可以长时间存储海量消息
- kafka中对Topic实现日志分区的目的如下:【
分区可以提高咱们kafka的写入能力和存储能力,就是多个消费者组(中的消费者们)和kafka集群中的分区们一块在那玩】- 首先,它们允许日志扩展到超出单个服务器所能容纳的大小。每个单独的分区都必须适合托管它的服务器,但是一个Topic可能有很多分区,因此它可以处理任意数量的数据.
- 其次每个服务器充当其某些分区的Leader,也可能充当其他分区的Follwer,因此群集中的负载得到了很好的平衡。
5.kafka的顺序写入:
- Kafka的特性之一就是高吞吐率, 但是
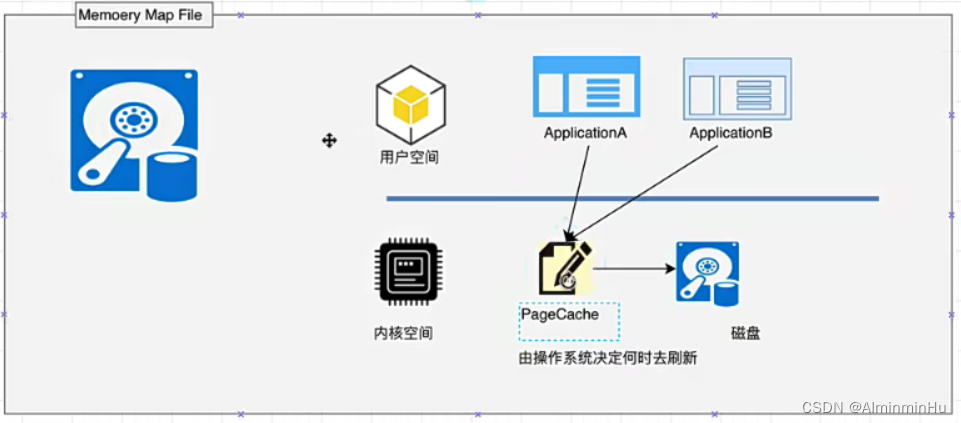
Kafka的消息是保存或缓存在磁盘上的(一般认为在磁盘上读写数据是会降低性能的),但是Kafka即使是普通的服务器,Kafka也可以轻松支持每秒百万级的写入请求,超过了大部分的消息中间件。这种特性也使得Kafka在日志处理等海量数据场景广泛应用。Kafka会把收到的消息都写入到硬盘中,防止丢失数据。同时为了优化写入速度Kafka采用了两个技术顺序写人和MMFile- 因为硬盘是机械结构,每次读写都会寻址->写人,
其中寻址是一个“机械动作”,它是最耗时的。所以硬盘最讨厌随机/O,最喜欢顺序/O.为了提高读号硬盘的速度,Kafka就是使用顺序I/O,这样省去了大量的内存开销以及节省了IO寻址的时间。但是单纯的使用顺序写入,Kafka的写入性能也不可能和内存进行对比(因为kafka这样一来也是机械写入),因此Kafka的数据并不是实时的写人硬盘中。 Kafka充分利用了现代操作系统分页存储来利用内存提高I/O效率。Memory Mapped Files(后面简称mmap)也称为内在映射文件,在64位操作系统中般可以表示20G的数据文件,Memory Mapped Files(后面简称mmap)也称为内在映射文件的工作原理是直接利用操作系统的Page(PageCache,算是内存的利器,内存的利器和磁盘完成映射,用我相当于用你,又快又稳又大,太牛B了)实现文件到物理内存的直接映射,完成MMP映射后,用户对内存的所有操作会被操作系统自动的刷新到磁盘上,极大地降低了IO使用率。
- 因为硬盘是机械结构,每次读写都会寻址->写人,
6.kafka的零拷贝技术
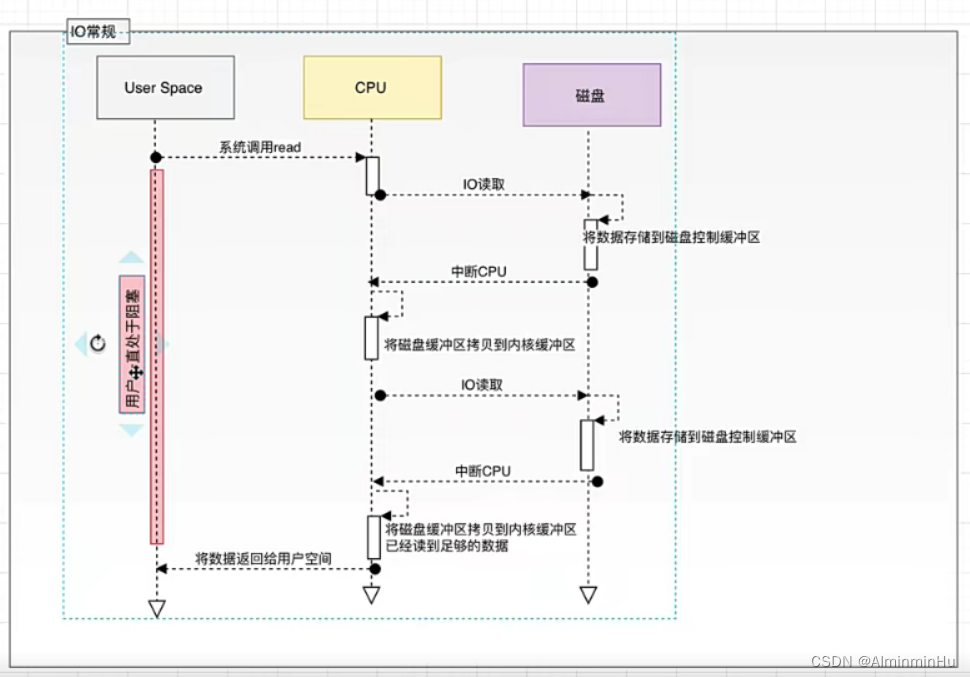
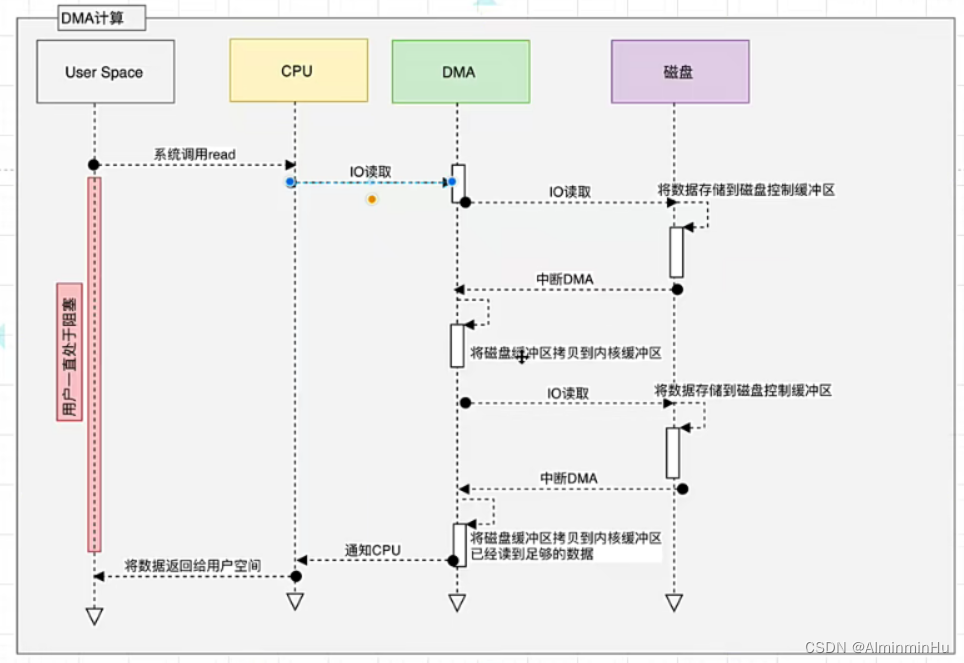
- Kafka服务器在响应客户端读取的时候,底层使用ZeroCopy技术,
直接将磁盘无需拷贝到用户空间,而是直接将数据通过内核空间传递输出,数据并没有抵达用户空间【因为经过一次用户空间,相当于要进行一次系统调用,这不是费时间费财力物力嘛】。- 常规IO
- 引入DMA计算【相当于减轻了CPU的压力,CPU轻松了,可以处理其他好多事喽】
- 常规IO
零拷贝与常规拷贝的比较
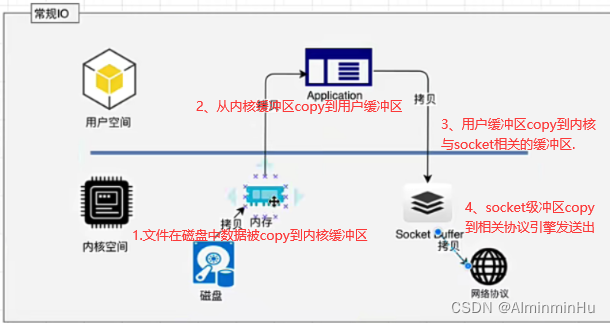
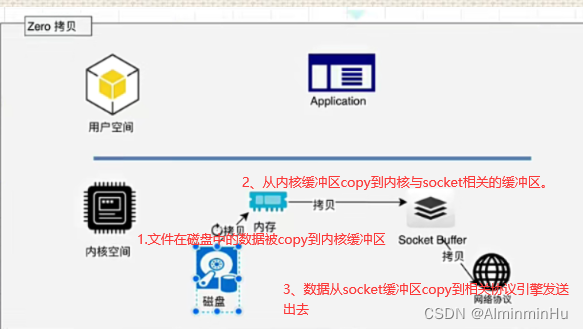
7.kafka的Leader到Follow之间的同步机制
Kafka的Topic被分为多个分区,分区是按照Seqments存储文件块。分区日志是存储在磁盘上的日志序列,Kafka可以保证分区里的事件是有序的。- 其中
Leader负责对应分区的读写、Follower负责同步分区的数据,0.11 版本之前Kafka使用highwatermarker机制保证数据的同步,但是基于highwatermarker的同步数据可能会导致数据的不一致或者是乱序。 - 在Kafka数据同步有以下概念:
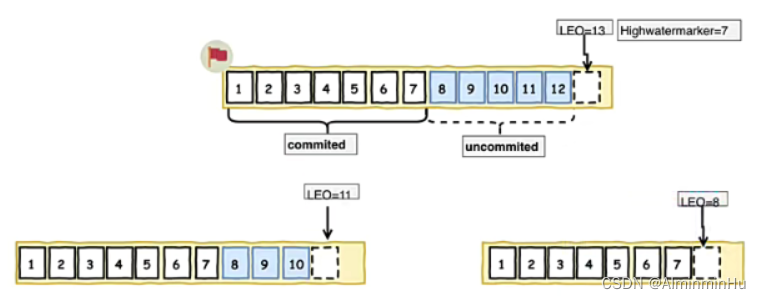
- LEO: log end offset标识的是每个分区中最后一条消息的下一个位置, 分区的每个副本都有自己的LEO.
- HW: high watermarker称为高水位线,所有HW之前的的数据都理解是已经备份的,当所有节点都备份成功,Leader会更新水位线。
- ISR:In-sync-replicas,kafka的leader会维护一份处于同步的副本集和,如果在replica.lag.time.max.ms时间内系统没有发送fetch请求,或者已然在发送请求,但是在该限定时间内没有赶上Leader的数据就被剔除ISR列表。在Kafka-0.9.0版本剔除replica.lag.max.messages消息个数限定,因为这个会导致其他的Broker节点频繁的加入和退出ISR.
Leader Epoch:规避了数据的丢失和不一致性
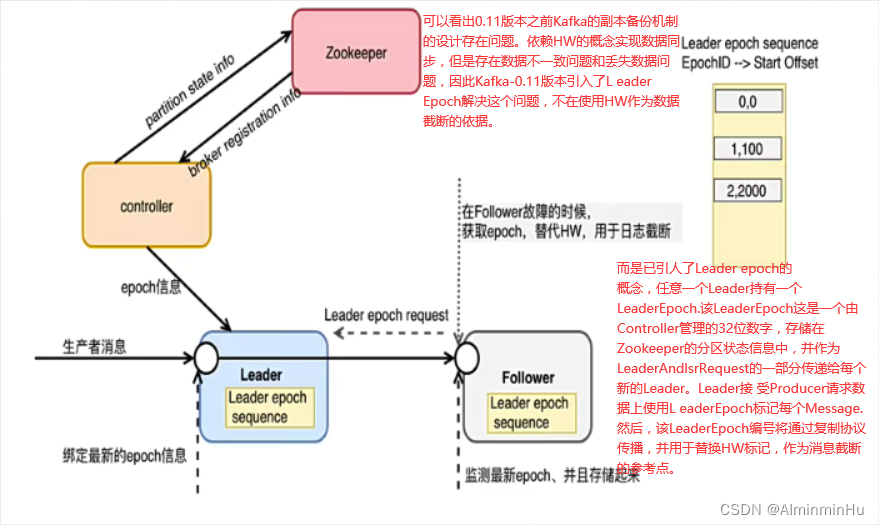
- 改进消息格式,以便每个消息集都带有一个4字节的Leader Epoch号.在每个日志目录中,会创建一个新的Leader Epoch Sequence文件,在其中存储LeaderEpoch的序列和在该Epoch中生成的消息的Start Offset.它也缓存在每个副本中,也缓存在内存中
- follower变成Leader
- 当Follower成为Leader时,它首先将新的LeaderEpoch和副本的LEO添加到Leader Epoch Sequence序列文件的末尾并刷新数据。给Leader产生的每个新消息集都带有新的“Leader Epoch”标记.
- Leader变成Follower
- 如果需要从本地的Leader Epoch Sequence加载数据,将数据存储在内存中,给相应的分区的Leader发送epoch请求,该请求包含最新的EpochlD,StartOffset信息. Leader接收到信息以后返回该EpochID所对应的LastOffset信息。该信息可能是最新EpochID的StartOffset或者是当前EpochID的Log End Offset信息
8.kafka的offset偏移量控制
- 【auto.offset.reset】:Kafka消费者默认对于未订阅的topic的offset的时候,也就是系统并没有存储该消费者的消费分区的记录信息,默认Kafka消费者的默认首次消费策略是latest
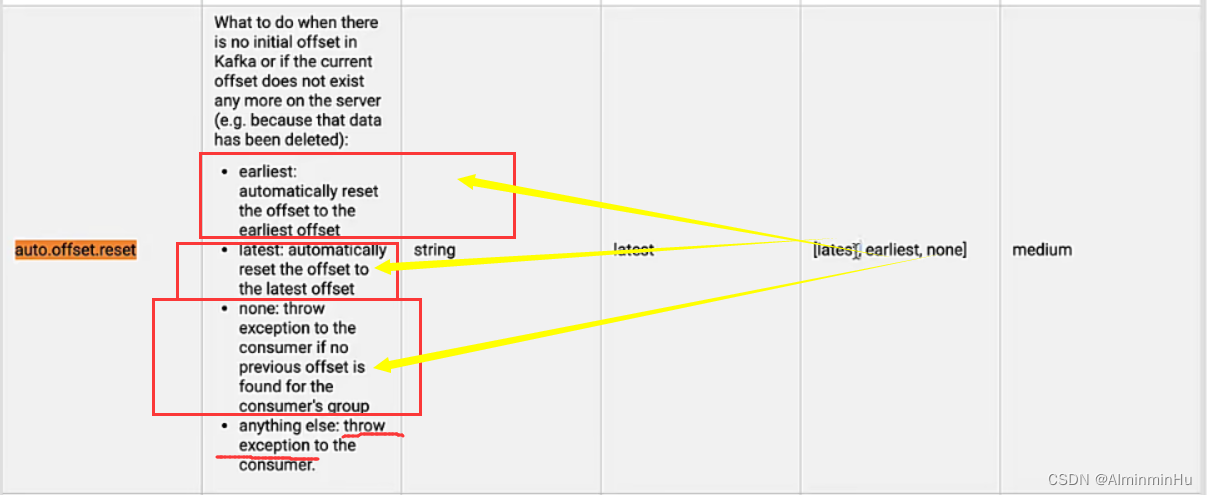
- offset的自动控制与用户手动控制:

- offset的自动控制与用户手动控制:
9.kafka的Acks与Retries【应答机制、重试】
- kafka的Acks与Retries【应答机制、重试】:Kafka生产者在发送完一个消息之后,要求Broker在规定的时间Ack应答,如果没有在规定时间内应答,Kafka生产者会尝试n次重新发送消息。
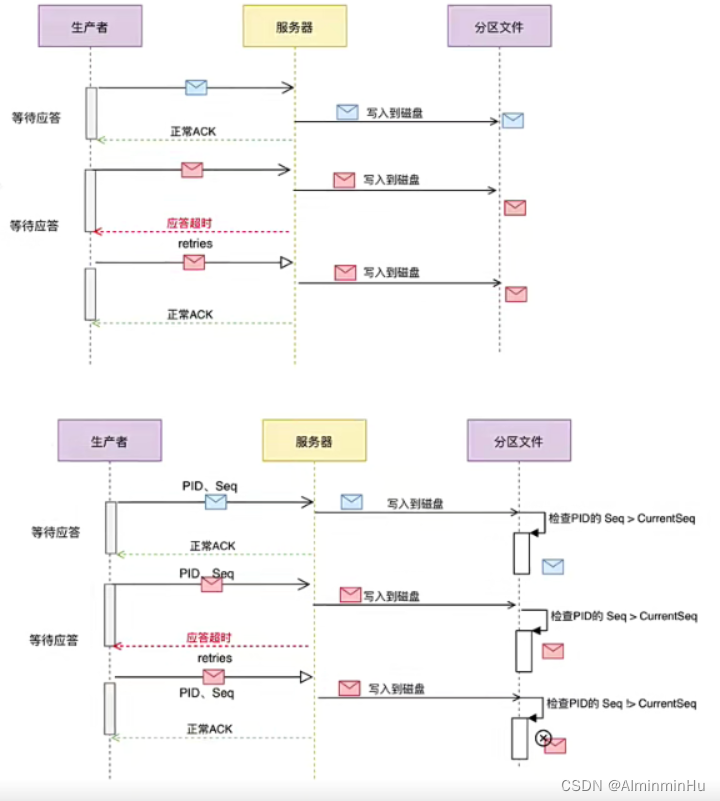
- 如果生产者在规定的时间内,并没有得到Kafka的Leader的Ack应答,Kafka可以开启reties机制。【request.timeout.ms = 30000 默认、retries = 2147483647默认】
- 应答和重复,会出现重复写入的情况,如果是下订单这种场景,那你重复写入是会出现问题的
- acks的几种模式:
- acks=1
- Leader会将Record写到其本地日志中,但会在不等待所有Follower的完全确认的情况下做出响应。在这种情况下,如果Leader在确认记录后立即失败,但在Follower复制记录之前失败,: 则记录将丢失。
- acks=0
- 生产者根本不会等待服务器的任何确认。该记录将立即添加到套接字缓冲区中并视为已发送。在这种情况下,不能保证服务器已收到记录。
- acks=all
- 这意味着Leader将等待全套同步副本确认记录。这保证了只要至少一个同步副本仍处于活动状态,记录就不会丢失。这是最有力的保证。
- acks=1
10.kafka的幂等性
- kafka的幂等性:数据有了,系统就不会再尝试去不停的发了

- 【HTTP/1.1中对幂等性的定义是:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。】Kafka在0.11.0.0版本支持增加了对幂等的支持。
幂等是针对生产者角度的特性。幂等可以保证上生产者发送的消息,不会丢失,而且不会重复。实现幂等的关键点就是服务端可以区分请求是否重复,过滤掉重复的请求。- 要区分请求是否重复的有两点:
- 唯一标识:要想区分请求是否重复,请求中就得有唯一标识。 例如支付请求中, 订单号记录下已处理过的请求标识:
- 光有唯一 标识还不够,还需要记录下那些请求是已经处理过的,这样当收到新的请求时,用新请求中的标识和处理记录进行比较,如果处理记录中有相同的标识,说明是重复记录,拒绝掉。
- 要区分请求是否重复的有两点:
- 【HTTP/1.1中对幂等性的定义是:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。】Kafka在0.11.0.0版本支持增加了对幂等的支持。
11.kafka的生产者事务、kafka的消费者&生产者事务
- kafka的生产者事务:
- Kafka的幂等性,只能保证一条记录在分区发送的原子性,但是如果要保证多条记录(多分区)之间的完整性,这个时候就需要开启kafk的事务操作。
- 在Kafka0.11.0.0除了引人的幂等性的概念,同时也引入了事务的概念。通常Kafka的事务分为生产者事务、消费者&生产者事务。
一般来说默认消费者消费的消息的级别是read_uncommited数据,这有可能读取到事务失败的数据,所有在开启生产者事务之后,需要用户设置消费者的事务隔离级别。【isolation.level = read_uncommitted 默认,该选项有两个值read_committed | read uncommitted, 如果开始事务控制,消费端必须将事务的隔离级别设置为read_committed】 开启生产者事务的时候,只需要指定transactional.id属性即可,一旦开启了事务,默认生产者就已经开启了幕等性。但是要求"transactional.id"的取值必须是唯一的, 同一时刻只能有一个"transactional.id"存储在,其他的将会被关闭。

- 在Kafka0.11.0.0除了引人的幂等性的概念,同时也引入了事务的概念。通常Kafka的事务分为生产者事务、消费者&生产者事务。
- Kafka的幂等性,只能保证一条记录在分区发送的原子性,但是如果要保证多条记录(多分区)之间的完整性,这个时候就需要开启kafk的事务操作。
- kafka的消费者&生产者事务
二、Kafka实操
- kafka的API
- 基本的admin或者说客户端创建以及方法的调用、生产者生产发送消息、消费者订阅及消费消息等对应的方法、拦截器及序列化、自定义分区设置等

- 然后客户端、生产者、消费者等你再new出来,不就可以愉快的玩耍了嘛
- 基本的admin或者说客户端创建以及方法的调用、生产者生产发送消息、消费者订阅及消费消息等对应的方法、拦截器及序列化、自定义分区设置等
- kafka的监控:kafka-eagle
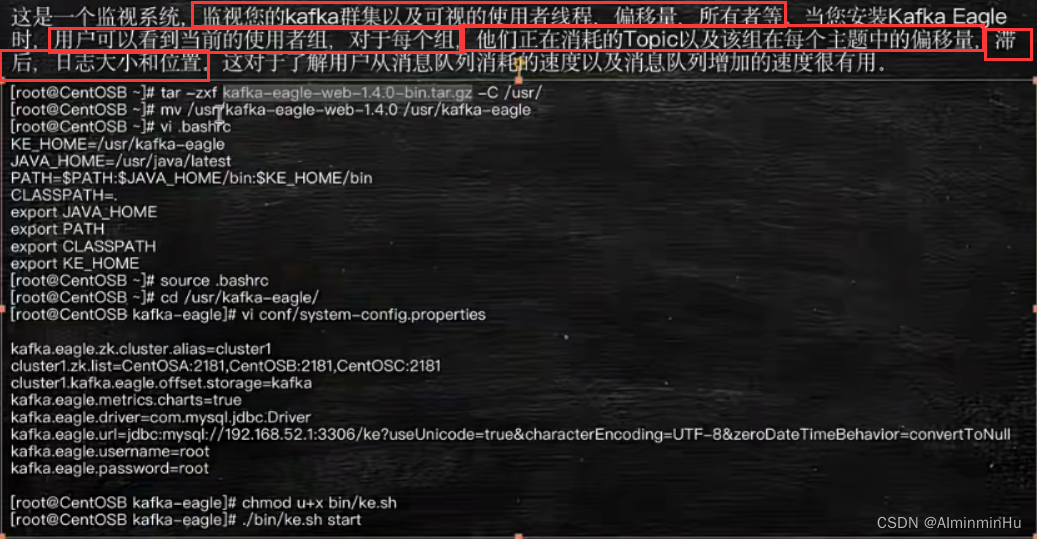
- 下载:https://github.com/smartloli?tab=repositories、https://www.nbagogo.com/nbaluxiang/16191/
- kafka单机配置:【单机情况下副本因子不能超过broker节点个数】
- 先解压,安装好JDK等环境,config/server.properties中该kafka监听地址、分区数量等
- 开启关闭
- 开启kafka:进入到kafka解压目录中,执行./bin/kafka-server-start.sh -deamon config/server.properties
- 关闭kafka:进入到kafka解压目录中,执行./bin/kafka-server-stop.sh
- kafka集群配置:
- 安装JDK、配置JAVA_HOME,配置主机名和IP映射、关闭防火墙&防火墙开机自启动、同步时钟 ntpdate cn.pool.ntp.org | ntp[1-7].aliyun.com,然后安装启动Zookeeper和kafka启动
- 常见配置命令(参数):
- 修改、删除
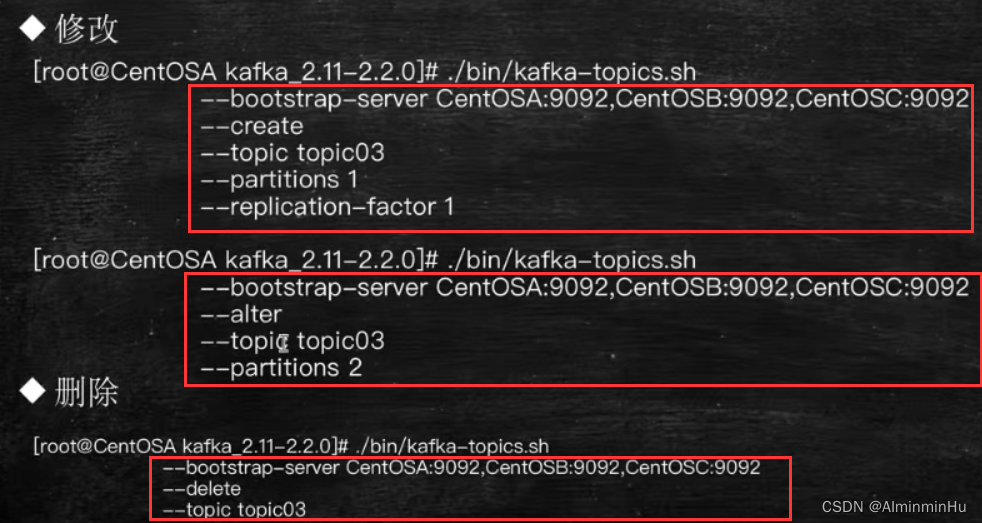
- 消息的生产发布及订阅

- 修改、删除
- kafka与flume集成
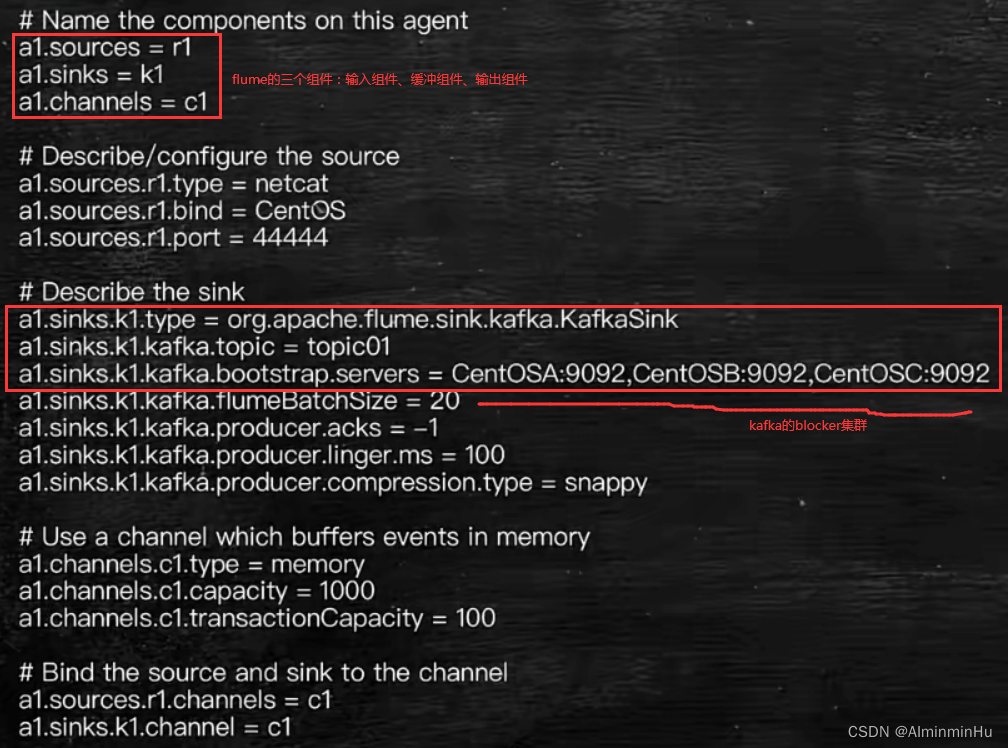
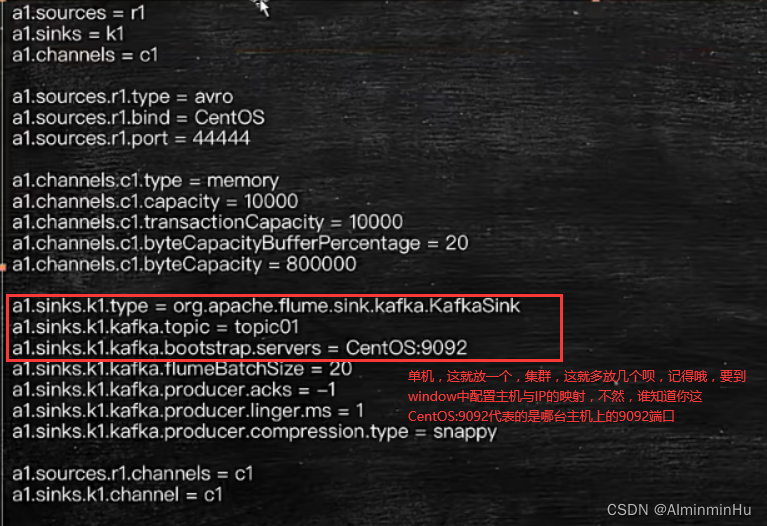
- 你服务器上肯定得有flume安装包吧,然后测试搭建flume(解压flume压缩包,写好配置文件,flume那个配置文件很重要),记得照着flume官方文档去使用flume
- 启动flume,有一些全局参数也可以放在配置文件中

- 启动flume,有一些全局参数也可以放在配置文件中
- 你服务器上肯定得有flume安装包吧,然后测试搭建flume(解压flume压缩包,写好配置文件,flume那个配置文件很重要),记得照着flume官方文档去使用flume
- kafka与SpringBoot的集成
- 引入依赖:

- 配置文件:
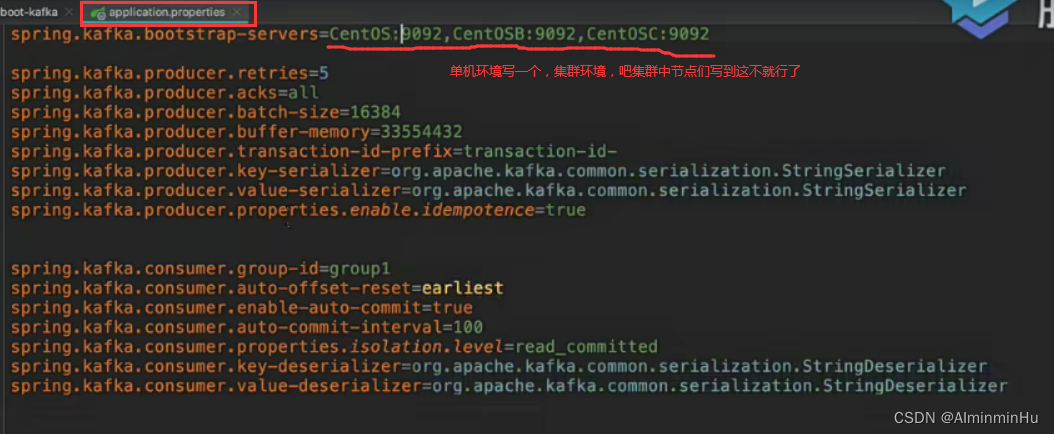
- api的使用:
- kafka消费者:通过kafka Listener去接收数据
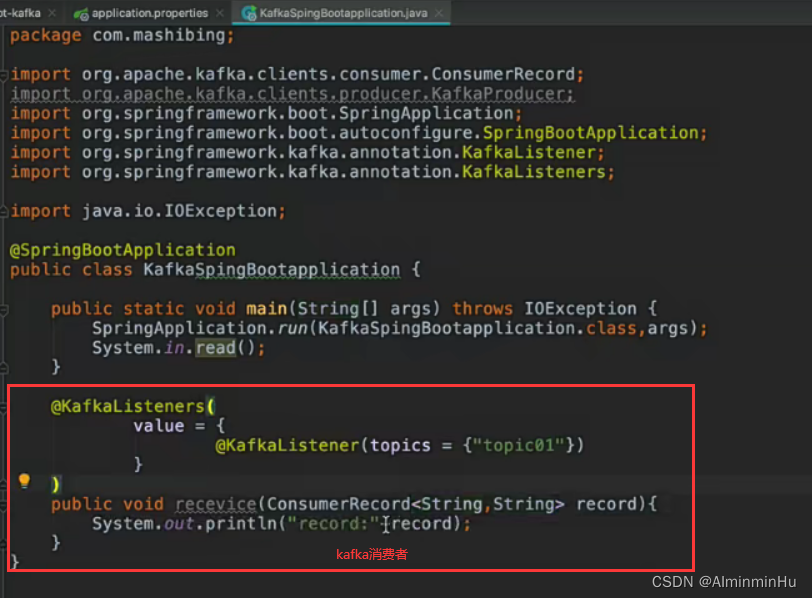
- @SendTo注解
- kafka消费者:通过kafka Listener去接收数据
- kafkaTemplate
- 非事务下进行
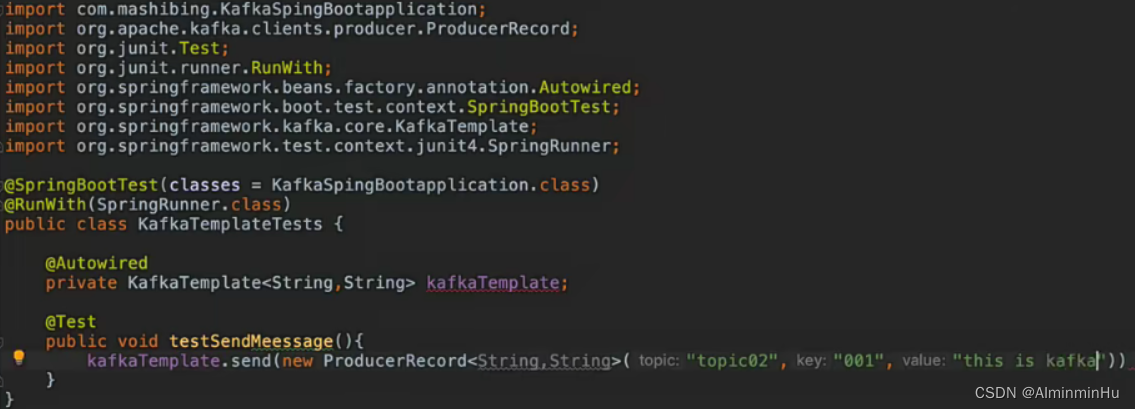
- kafka Template发送数据通常会放到事务中发送
- 第一种方式:
- 在配置文件中加一句:

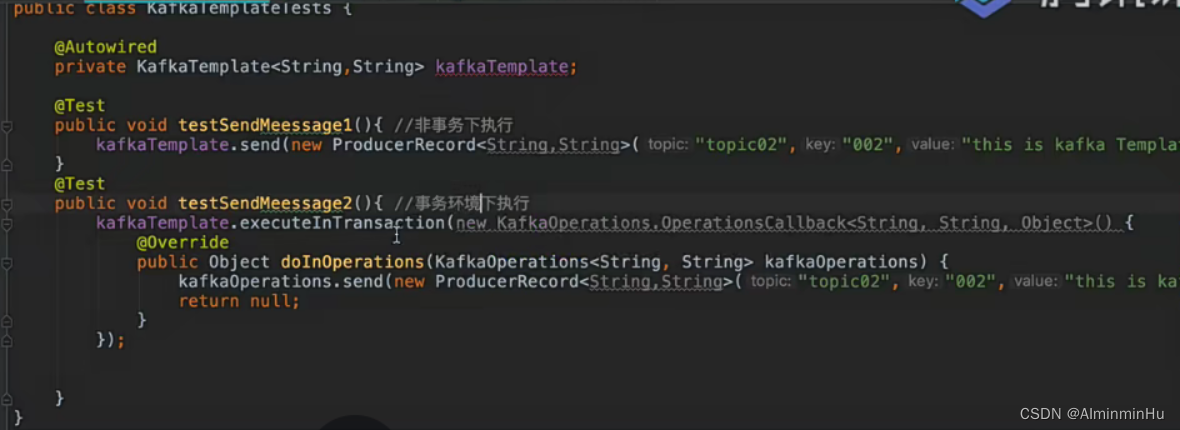
- 在配置文件中加一句:
- 第二种方式:
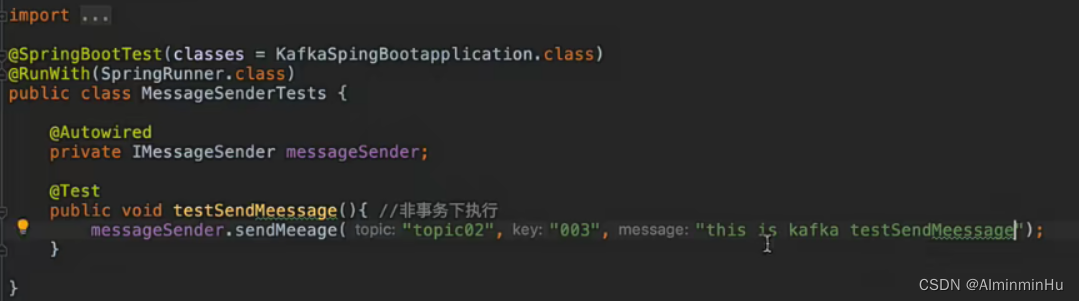
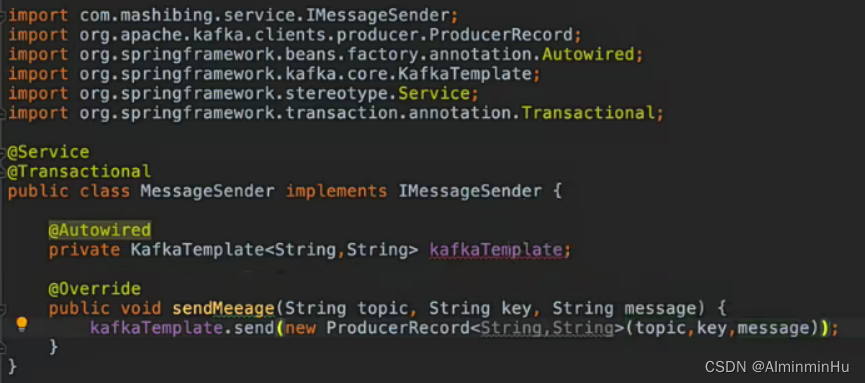
- 第一种方式:
- 非事务下进行
- 引入依赖:
巨人的肩膀
Flume官方文档
Hadoop权威指南