程序经常需要访问文件和目录,读取文件信息或写入文件信息,在Python语言中对文件的读写是通过文件对象(file object)实现的。Python的文件对象也称为类似文件对象或流(stream),因为Python提供一种类似于文件操作的API实现对底层资源的访问。文件对象可以是实际的磁盘文件,也可以是其他存储或通信设备,如内存缓冲区、网络、键盘和控制台。
文件操作
打开文件
文件对象可以通过 open()函数获得。open()函数是 Python 内置函数,它屏蔽了创建文件对象的细节,使得创建文件对象变得简单。open()函数语法如下:
open(file,mode='r',buffering=-1,encoding=None,errors=None,newline=None,closefd=True,opener=None)其中file、mode 和 encoding 是最常用的参数,其它参数很少使用。
(1)file参数
file参数是要打开的文件,可以是字符串或整数。如果 file 是字符串表示文件名,文件名可以是相对路径,也可以是绝对路径;如果 file 是整数表示文件描述符,文件描述符指向一个已经打开的文件(文件描述符是一个整数值,它对应到当前程序已经打开的一个文件。例如标准输入文件描述符为0,标准输出文件描述符为1,标准错误文件描述符为2,打开其他文件的文件描述符依次是3、4、5等数字)。
(2)mode参数
mode 参数用来设置文件打开模式
| 字符串 | 说明 |
|---|---|
| r | 只读模式打开(默认) |
| w | 写入模式打开文件,会覆盖已经存在的文件 |
| x | 独占创建模式,如果文件不存在则创建并以写入模式打开文件,如果文件已存在则抛出异常 FileExistsError |
| a | 追加模式,如果文件存在,写入内容追加到文件末尾 |
| b | 二进制模式 |
| t | 文本模式(默认) |
| + | 更新模式 |
注意:
- b 和 t 是文件类型模式,如果是二进制文件需要设置 rb、wb、xb、ab,如果是文本文件需要设置 rt、wt、xt、at,由于 t 是默认模式,因此可以省略为 r、w、x、a。
- +必须与 r、w、x 和 a 组合使用来设置文件为读写模式,对于文本文件可以使用 r+、w+、x+ 和 a+,对于二进制文件可以使用 rb+、wb+、xb+ 和 ab+。
- r+、w+、和 a+ 的区别:r+ 打开文件时如果文件不存在则抛出异常;w+ 打开文件时如果文件不存在则创建文件,文件存在则清除文件内容;a+打开文件时如果文件不存在则创建文件,文件存在则在文件末尾追加。
(3)buffering参数
使用缓冲区可以提高效率减少 IO 操作,文件数据首先被放到缓冲区中,当文件关闭或刷新缓冲区时,数据才会真正写入到文件中。buffering 是设置缓冲区策略,默认值为 -1,此时系统会自动设置缓冲区,通常是 4096 字节或 8192 字节;buffering=0 时关闭缓冲区,此时数据会直接写入到二进制文件中,这种模式主要应用于二进制文件的写入操作;当buffering>0时,buffering 用来设置缓冲区字节大小。
(4)encoding 参数 和 errors 参数
encoding 用来指定打开文件时的文件编码,主要用于文本文件的打开。errors 参数用来指定编码发生错误时如何处理。
(5)newline参数
用来设置换行模式
(6)closefd 参数和 opener 参数
这两个参数在 file 参数为文件描述符时使用。closefd 为True 时,文件对象调用close()关闭文件,同时也会关闭文件描述符;closefd 为 为 False 时,文件对象调用close()方法关闭文件,但文件描述符不会关闭。opener参数用于打开文件时执行的一些加工操作,opener 参数执行一个函数,该函数返回一个文件描述符。
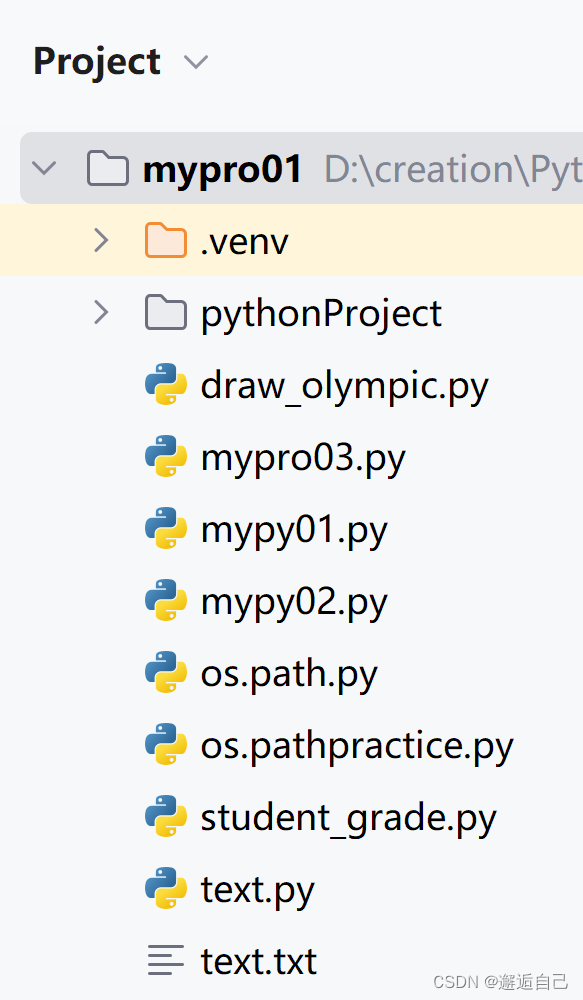
可以看到此时我的项目中是没有“a.txt”文件
示例代码如下
#由于a.txt文件不存在,会创建文件,且文件内容为写入的World
with open("a.txt","w+") as f:
f.write('World')
#此时为r+,会覆盖文件内容为Hello
with open("a.txt","r+") as f:
f.write('Hello')
#此时为a+,会在文件原内容的末尾增加 World
with open("a.txt","a+") as f:
f.write(' ')
f.write("World")代码运行结果
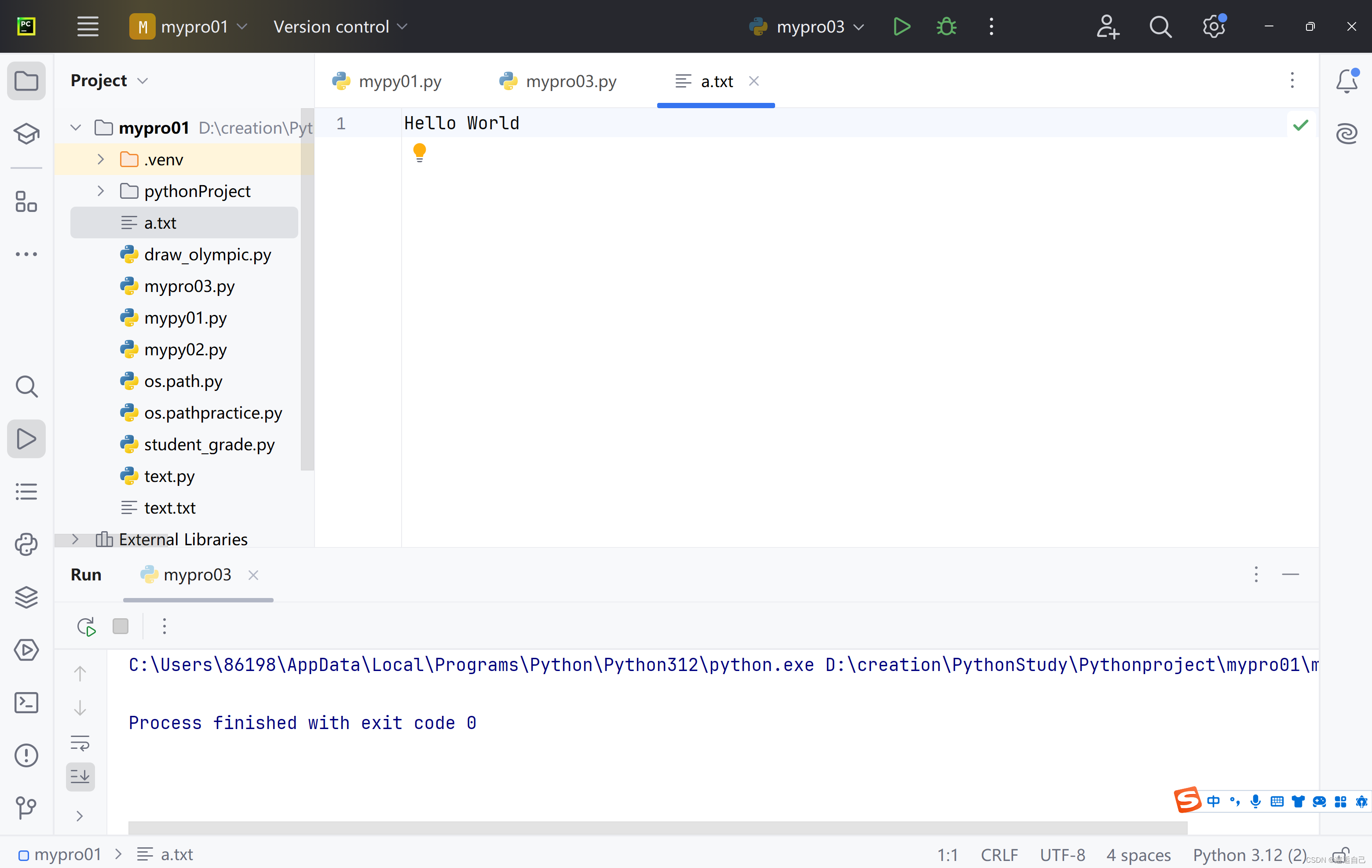
可以看到结果为我们输入的“Hello World”字符,且新建了一个 a.txt 文件
关闭文件
当使用 open()函数打开文件后,若不再使用文件应该调用文件对象的close()方法关闭文件。文件的操作往往会抛出异常,为了保证文件操作无论正常结束还是异常结束都能关闭文件,调用close()方法应该放在异常处理的finally代码块中,也可以用 with as 代码块进行自动资源管理。(推荐)
示例代码如下
f_name = "a.txt"
try:
f = open("a.txt")
except OSError as e:
print('打开文件失败')
else:
print('打开文件成功')
try:
content = f.read()
print(content)
except OSError as e:
print('处理OS异常')
finally:
f.close()该段代码中使用了两个try语句,其中 finally 没有与第一个 try 语句匹配,是因为如果文件打开失败,则 f =None,此时再关闭文件会引发异常。
代码运行结果
打开文件成功
Hello World
Process finished with exit code 0文本文件读写
文本文件读写的单位是字符,需要考虑编码问题
| 方法名 | 说明 |
|---|---|
| read(size=-1) | 从文件中读取字符串,size 限制最多读取的字符数,size=-1表示没有限制,读取全部内容 |
| readline(size=-1) | 读取到换行符或文件末尾并返回单行字符串,如果已经到文件尾,则返回一个空字符串,size 限制最多读取的字符数,size=-1表示没有限制 |
| readlines() | 读取文件数据到一个字符串列表中,每个行数据是列表的一个元素 |
| write(s) | 将字符串 s 写入文件,并返回写入的字符数 |
| writelines(lines) | 向文件中写入一个列表,不添加行分隔符,因此通常为每一行末尾提供分隔符 |
| flush() | 刷新写缓冲区,数据会写入文件中 |
首先在项目中新建一个“text.txt”文件,并写入相关内容
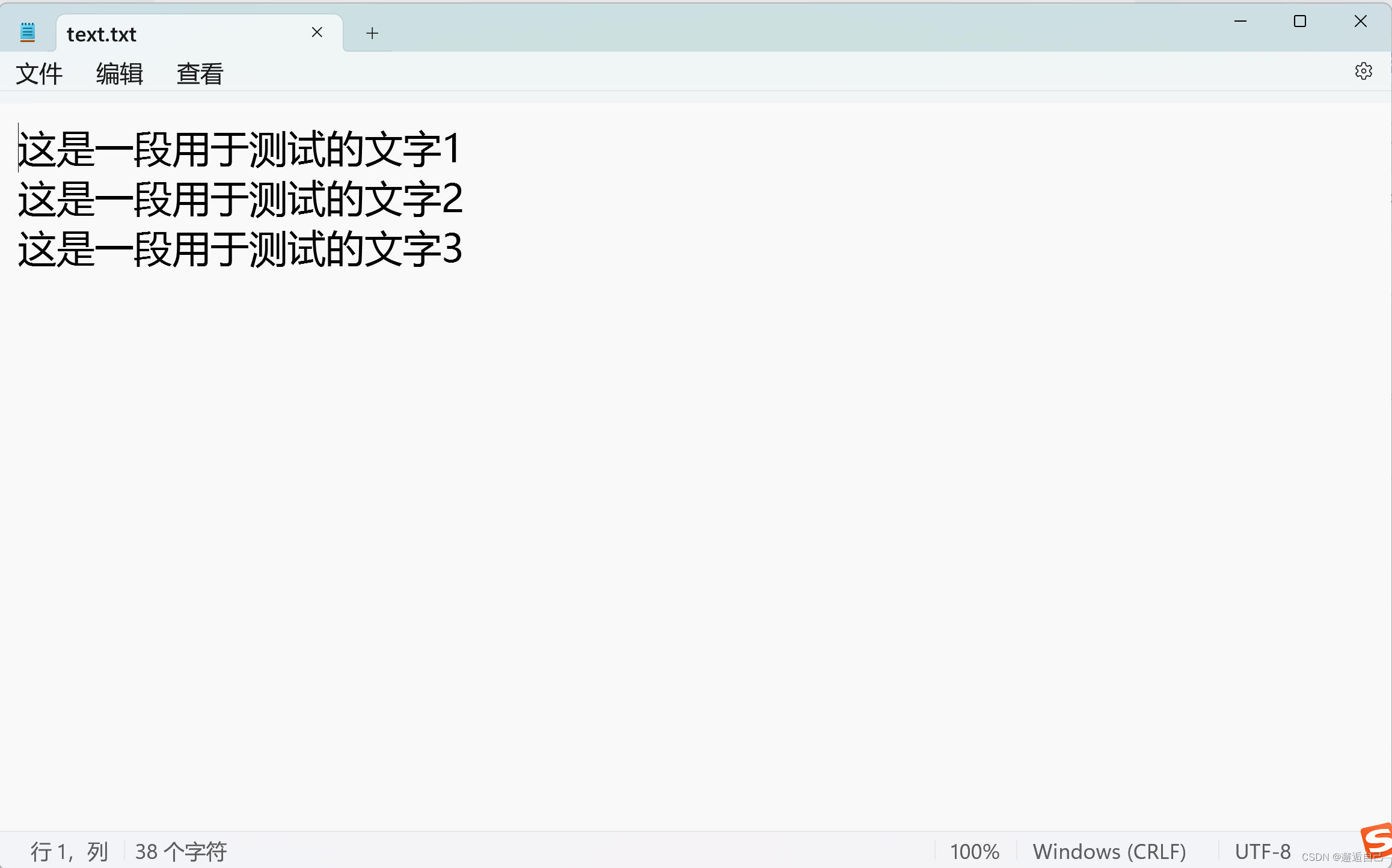
示例代码如下
with open("text.txt",'r',encoding="utf-8") as f:
'''
使用 f.readlines(),它将返回一个包含每一行作为元素的列表
lines 是一个列表,其中包含了文件的每一行
使用 for 循环遍历这个列表,并打印每一行
print(line, end='') 确保在打印时不会添加额外的换行符
'''
lines = f.readlines()
for line in lines:
print(line,end="")
# 复制文件内容到copy_name文件中
with open("copy.txt","w",encoding="utf-8") as file:
file.writelines(lines)
print()
print('文件复制成功')
print("接下来文查看文件内容")
# 打印复制的文件内容
with open("copy.txt","r",encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
print(line,end="")代码运行结果
这是一段用于测试的文字1
这是一段用于测试的文字2
这是一段用于测试的文字3
文件复制成功
接下来文查看文件内容
这是一段用于测试的文字1
这是一段用于测试的文字2
这是一段用于测试的文字3
Process finished with exit code 0二进制文件读写
二进制文件读写的单位是字节,不需要考虑编码问题
示例代码如下
with open("CSDN.png",'rb') as f:
b = f.read()
with open("copy.png",'wb') as copy_f:
copy_f.write(b)
print("文件复制成功")代码运行结果
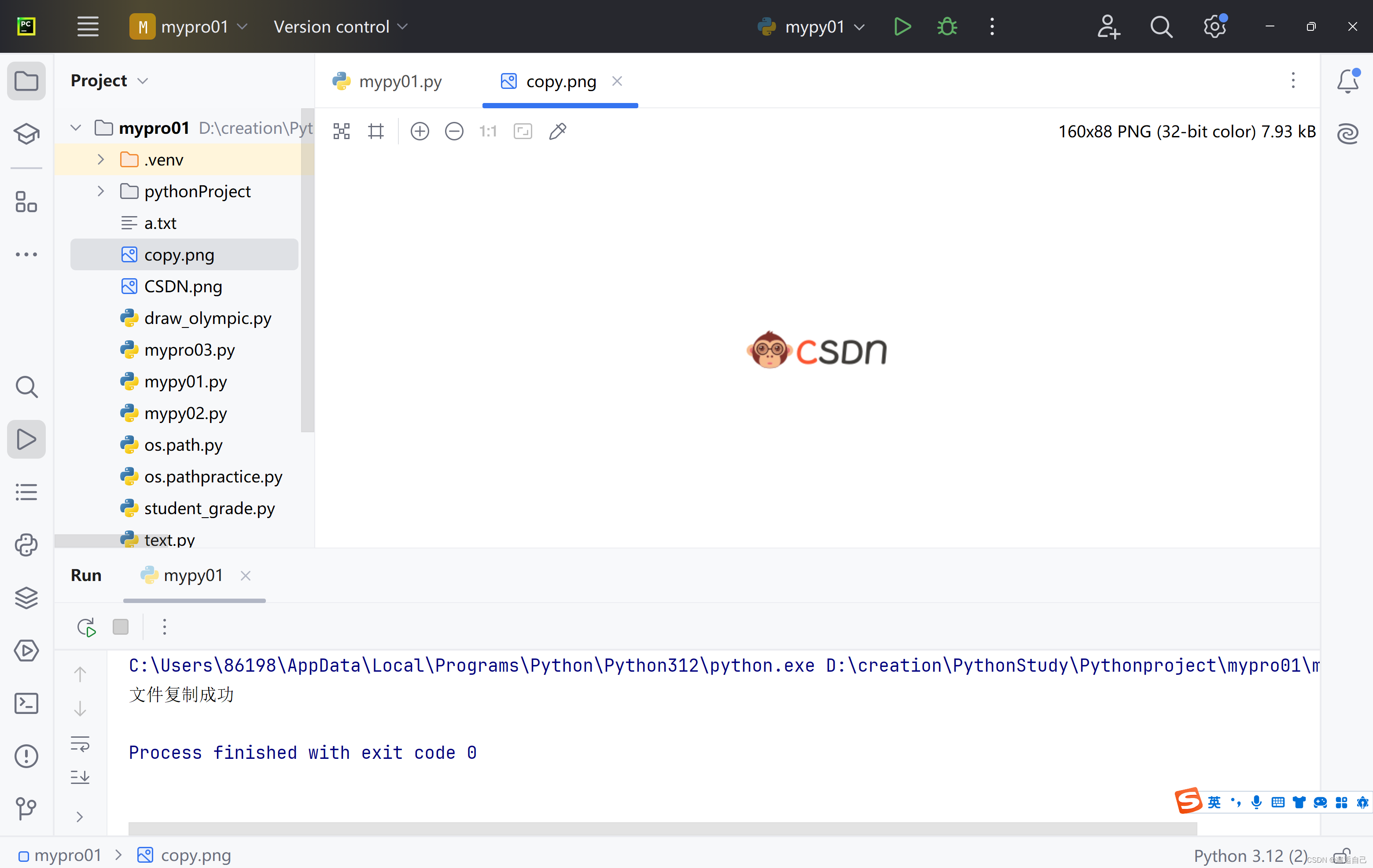
os模块
Python对文件的操作是通过文件对象实现的,文件对象属于 Python 的 io 模块。如果想要通过Python程序管理文件或目录,如删除文件、修改文件名、创建目录、删除目录和遍历目录等,可以通过Python的 os 模块实现。
os 模块提供了使用操作系统功能的一些函数,如文件与目录管理。
| 函数、属性名 | 说明 |
|---|---|
| os.rename(src,dst) | 修改文件名,src为源文件,dst为目标文件,他们都可以是相对当前路径或绝对路径表示的文件 |
| os.remove(path) | 删除path所指的文件,如果path是目录,则会引发OSError |
| os.mkdir(path) | 创建path所指的目录,如果目录已存在,则会引发FileExistsError |
| os.rmdir(path) | 删除path所指的目录,如果目录非空,则会引发OSError |
| os.walk(top) | 遍历top所指的目录树,自顶向下遍历目录树,返回值是一个有三个元素的元组(目录路径,目录名列表,文件名列表) |
| os.listdir(dir) | 列出指定目录中的文件和子目录 |
| os.curdir属性 | 获得当前目录 |
| os.pardir属性 | 获得当前父目录 |
示例代码如下
import os
# 读取text.txt中的全部内容并复制给copy.txt
with open("text.txt",'r',encoding="utf-8") as f:
b = f.read()
with open("copy.txt",'w',encoding="utf-8") as copyfile:
copyfile.write(b)
# 修改copy.txt文件名为 copy2.txt
try:
os.rename("copy.txt","copy2.txt")
except OSError:
os.remove("copy2.txt")
# 创建目录
try:
os.mkdir('subdir')
except OSError:
os.rmdir('subdir')
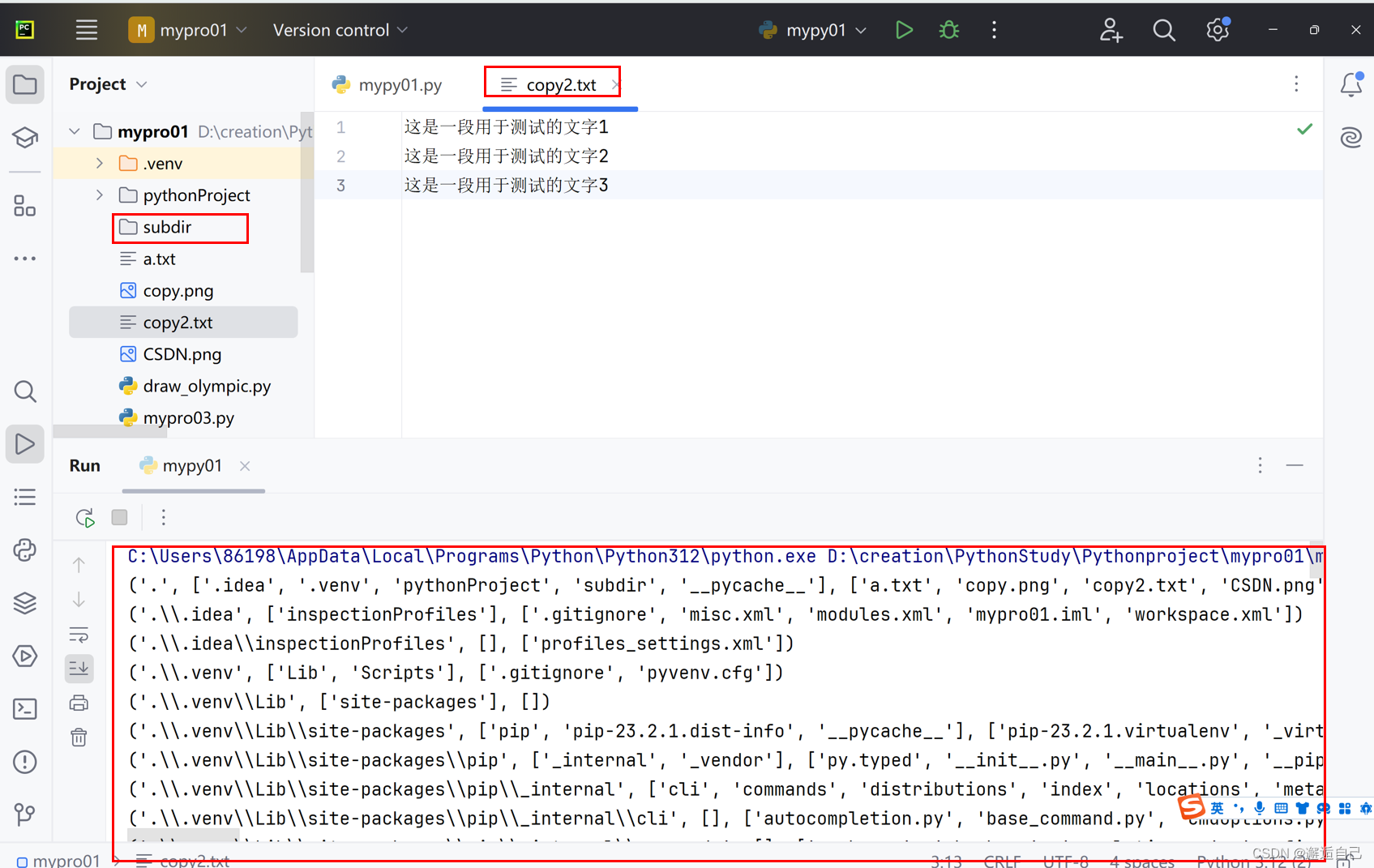
#遍历目录
for item in os.walk('.'):
print(item)代码运行结果
os.path模块
对于文件和目录的操作往往需要路径,Python提供的 os.path模块提供对路径、目录和文件等进行管理的函数。
| 函数名 | 说明 |
|---|---|
| os.path.abspath(path) | 返回 path 的绝对路径 |
| os.path.basename(path) | 返回 path路径的基础名部分,如果path指向的是一个文件,则返回文件名;如果path指向的是一个目录,则返回最后目录名 |
| os.path.dirname(path) | 返回path路径中目录部分 |
| os.path.exists(path) | 判断path文件是否存在 |
| os.path.isfile(path) | 如果path是文件,则返回True |
| os.path.isdir(path) | 如果path是目录,则返回True |
| os.path.getatime(path) | 返回最后一次的访问时间,返回值是一个UNIX时间戳(1970年1月1日00:00:00以来至现在的总秒数),如果文件不存在则无法访问,会引发OSError |
| os.path.getctime(path) | 返回创建时间,返回值是一个UNIX时间戳,如果文件不存在或无法访问,则引发OSError |
| os.path.getsize(path) | 返回文件大小,以字节为单位,如果文件不存在则无法访问,会引发OSError |
示例代码如下
import os.path
from datetime import datetime
f_name = 'text.txt'
af_name = r'D:\creation\PythonStudy\Pythonproject\mypro01\text.txt'
# 返回路径中基础名部分
basename = os.path.basename(af_name)
print(basename)
# 返回路径中目录部分
dirname = os.path.dirname(af_name)
print(dirname)
#返回文件的绝对路径
print(os.path.abspath(f_name))
#返回文件大小
print(os.path.getsize(f_name))
#返回最近访问时间
atime = datetime.fromtimestamp(os.path.getatime(f_name))
print(atime)
#返回创建时间
ctime = datetime.fromtimestamp(os.path.getctime(f_name))
print(ctime)
#返回修改时间
mtime = datetime.fromtimestamp(os.path.getmtime(f_name))
print(mtime)代码运行结果
text.txt
D:\creation\PythonStudy\Pythonproject\mypro01
D:\creation\PythonStudy\Pythonproject\mypro01\text.txt
106
2024-06-30 11:01:22.267132
2024-06-25 10:06:21.804224
2024-06-25 15:44:00.648589
Process finished with exit code 0参考书籍:《python从小白到大牛》(第2版)关东升 编著
文章创作不易,本文接近6000字,为了大家能理解,写的很详细,这也让我花了很多时间。最后,如果觉得本文对大家有帮助的话,还请给我点个赞和关注,谢谢大家!!!