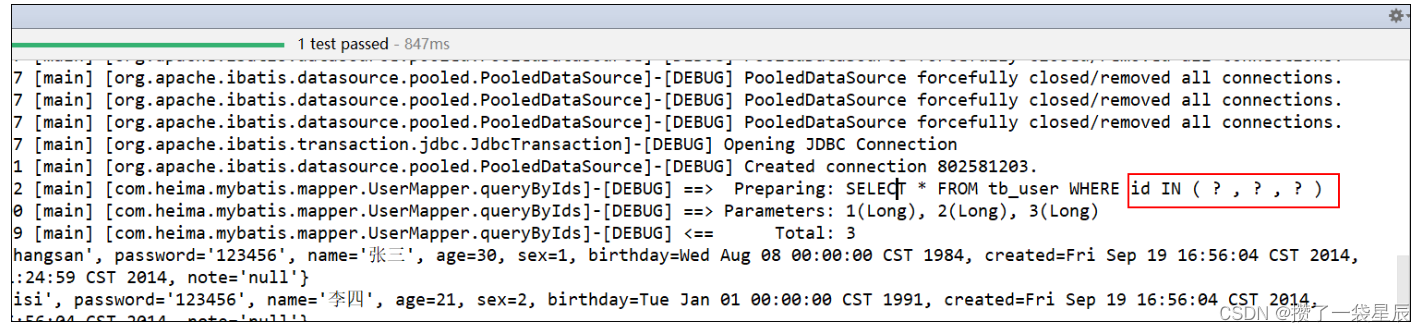
| 英文名称:Embedding-based Retrieval in Facebook Search 中文名称:基于嵌入式检索的Facebook搜索 时间:Wed, 29 Jul 2020 (v2) 地址:https://arxiv.org/abs/2006.11632 作者:Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, Linjun Yang 机构:Facebook & Microsoft 出处:会议论文,第26届 ACM SIGKDD 知识发现和数据挖掘会议论文集 正文:8 页 |
读后感
Facebook 社交中的搜索与其它搜索不同,它可以基于上下文得到更多信息。
这里研究的是如何将传统搜索与基于向量的搜索结合在一起的具体方法。比较有启发的是提出的“统一嵌入模型”,在编码时加入了用户、上下文、位置等文本以外的信息,以便更好地定位和匹配。
另外,还考虑到每月活跃用户、最近发生的事件、热门页面和群组。并不一定要对所有内容做嵌入索引,多数时候人们更关注高频数据,这样确实可以提升效果。使用新方法和旧方法结合,解决不同用户需求,同时平衡资源占用,是实用的方法。
摘要
目标: 将嵌入式检索(EBR)应用于 Facebook 搜索系统的技术,以改进搜索结果的相关性。
方法: 介绍了用于个性化搜索的统一嵌入框架和基于倒排索引的嵌入式检索系统,并分享了端到端优化整个系统的各种技巧和经验,包括 ANN 参数调整和全栈优化。
结果: 在 Facebook 搜索的垂直领域上评估 EBR,在在线 A/B 实验中观察到显著的指标提升。
1 引言
解决与查询文本不完全匹配但能满足用户搜索意图的预期结果是一个具有挑战性的问题。而嵌入是一种将稀疏的 ID 向量表示为密集特征向量的方法,也称为语义嵌入,因为它通常能够学习语义。一旦学习了嵌入,它就可以用作查询和文档的表示,并应用于搜索引擎的各个阶段。
一般搜索引擎包括一个召回层,以低延迟和计算成本检索一组相关文档,也称为检索;以及一个精确层,以更复杂的算法或模型将最需要的文档排在顶部,也称为排序。嵌入在检索中的应用称为基于嵌入的检索,或简称 EBR。检索层需要处理数十亿或数万亿个文档。搜索引擎通常需要将基于嵌入的检索和基于术语匹配的检索结合起来,才能在检索层对文档进行评分。
在 Facebook 社交网络中的搜索,需要完全理解文本、用户和上下文。文章提出了统一嵌入,这是一个双侧模型,也称为又塔结构。其中一侧是包含查询文本、搜索者和上下文的搜索请求,另一侧是文档。从搜索者、查询、上下文和文档中提取特征。例如,网络上有很多 John Smith,但用户搜索时,更可能是他认识的 John Smith。

2 模型
本文主要讨论对于检索的优化,可将召回率优化表述为一个基于查询和文档之间距离计算的排名问题。查询和文档通过神经网络模型编码为密集向量,并使用余弦相似度作为距离度量。
2.1 评价指标
作者设计了离线测试,对 10000 个搜索会话进行了采样,以收集用于评估的查询和目标结果集对。并报告了超过 10000 个会话的平均 recall@K。
2.2 损失函数
对于给定的三元组 ( ( ), +( ), −( )),其中 ( ) 是查询, +( ) 是关联的正文档, −( ) 是关联的负文档,三元组损失定义为:

2.3 统一嵌入模型
作者提出了统一嵌入,在生成嵌入时不仅考虑了文本,还考虑了用户和上下文信息。
模型包括三个主要组件:查询编码器用于产生查询嵌入,文档编码器用于产生文档嵌入,以及相似性函数用于计算查询和文档之间的分数。默认情况下,这两个编码器和是独立的网络,但也可以选择共享部分参数。并选择余弦相似性作为相似性函数。
统一嵌入对文本、社交和其他有意义的上下文特征进行编码,以分别表示查询和文档。例如,对于查询端,可以包括搜索者的位置和用户的社交关系。而对于文档,以群组搜索为例,可以包括关于 Facebook 群组的聚合位置和社交集群。不同类型特征与文本结合的嵌入方法,详见特征工程章节。

|400
2.4 训练数据挖掘
对于正负样本的选择,文中比较了几种基于模型召回率的策略。
负样本方面,测试了随机采样和未点击的展示结果。使用未点击的展示结果作为负样本时,模型召回率显著下降。这是因为这些负样本偏向于与查询匹配的难案例,而大多数文档是不匹配的简单案例。
正样本方面,点击结果和展示结果都被测试。发现两者效果相似,添加展示数据并未带来额外提升。
因此,使用点击作为正样本、随机作为负样本。
3 特征工程
统一嵌入模型的优点之一是它可以合并文本以外的各种功能来提高性能。实验证明,当事件搜索从文本切换到统一嵌入时,召回率提高了 18%,组搜索的召回率提高了 16%。
文本特征:使用字符 n-gram 表示文本有两个主要优点。首先,它使词汇量更小,从而嵌入查找表更小且更易于学习。其次,它对查询和文档中的词汇外问题(例如拼写变化或错误)更具鲁棒性。实验表明,字符 n-gram 比词 n-gram 能产生更好的性能,但结合两者能进一步提高表现(召回率提升 1.5%)。Facebook 实体的主要文本特征来源于人名或标题,相比布尔术语匹配技术,嵌入模型在处理模糊匹配和可选词匹配方面表现更佳。
位置特征:位置匹配在许多搜索方案中都是有利的,例如搜索本地商家、群组或活动。在查询和文档端都添加了位置功能。对于查询端,我们提取了搜索者的城市、地区、国家和语言信息。对于文档端,实验中添加了公开可用的信息,例如管理员标记的显式组位置。结合文本特征,该模型能够成功学习查询和结果之间的隐式位置匹配。
社会关系特征:训练了一个单独的嵌入模型来嵌入基于社交图谱的用户和实体。这有助于将全面的社交图谱合并到统一的嵌入模型中。
4 服务
4.1 ANN
在系统中部署了基于倒排表的 ANN(近似近邻)搜索算法。首先,对嵌入向量的量化,使存储成本较低。其次,更容易集成到现有的基于倒排索引的检索系统中。使用 Faiss 库来量化向量,然后在现有的倒排表扫描系统中实现高效的神经网络搜索。
嵌入量化有两个主要组成部分:一种是粗量化,通常通过 K-means 算法将嵌入向量量化为粗簇;另一种是乘积量化,用于细粒度地进行嵌入距离的有效计算。
4.2 系统实施
在 Unicorn(高性能的 HTTP 服务器)中,实现了对 NN(最近邻)搜索的优质支持。Unicorn 使用术语包表示每个文档,这些术语是文档二进制属性的任意字符串,通常会被转换为命名空间。例如,居住在西雅图的用户 John 将具有术语 text:john 和 location:seattle。查询可以是基于这些术语的任何布尔表达式。
为了支持 NN 搜索,作者扩展了文档表示形式,使其支持嵌入。每个嵌入都有一个特定的字符串键,并增加了一个 (nn <key>:radius <radius>) 查询运算符。该运算符匹配指定半径内查询嵌入的所有文档。
在索引阶段,每个文档嵌入被量化为一个术语(代表其粗集群)和一个有效负载(代表量化后的残差)。在查询阶段,通过最接近的术语匹配文档,并检索有效负载以验证约束。
(小编说:这是四年前的文章,现在有更多针对向量查询的优化技术,此方法就不再展开了)
4.2.1 混合检索
通过将 (nn) 运算符作为布尔查询语言的一部分,可以支持混合检索表达式,任意组合嵌入和术语,以实现模糊匹配等功能。
(小编说:非稠密向量也有很多模糊匹配的方法,这里主要说明 NN 的使用场景)
4.2.2 模型服务
在双侧嵌入模型训练完成后,将其分解为查询嵌入模型和文档嵌入模型,并分别提供服务。对于查询嵌入,将模型部署在在线推理服务中,以实现实时推理。对于文档嵌入,使用 Spark 进行离线批量推理,然后将生成的嵌入与其它元数据一起发布到正向索引中。此外,还进行了额外的嵌入量化,包括粗量化和 PQ,以将其发布到倒排索引中。
4.3 查询和索引选择
为了提高 EBR 的效率和质量,文中对查询和索引进行了优化。但并不是对所有用户数据和所有查询都应用上述技术,以减少资源占用。例如,只对每月活跃用户、最近发生的事件、热门页面和群组进行索引;过滤掉之前查询过的、简单的查询,或者不需要向量查询的内容。
5 优化
Facebook 的搜索排名是一个复杂的多阶段系统,包含检索和排序两个独立步骤。如果只针对检索进行优化,可能会与后续的排序阶段不匹配,从而无法生成最优结果。为改善这一问题,可以使用以下两种方法:
-
将嵌入作为排序特征:利用查询和结果嵌入之间的余弦相似度作为排序特征,从而提高排序器的表现。
-
训练数据反馈循环:记录基于嵌入检索得到的结果,并结合人工评分数据重新训练模型,以提升检索的精确度。
6 高级主题
这里主要讨论了难样本对模型效果的影响,相对小众,略……



![[AIGC] Shell脚本在工作中的常用用法](https://img-blog.csdnimg.cn/img_convert/2110cabb1a7f0a98c7edabb00b2b1ba3.jpeg)