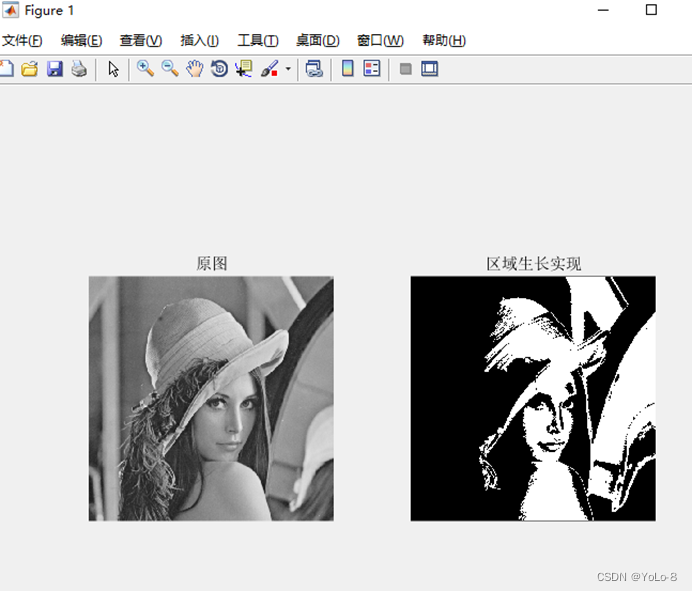
数据结构-期末复习题
一、选择题
1、在数据结构中,与所使用的计算机无关的是数据的( ) 结构。
- A. 存储
- B. 物理
- C. 逻辑
- D. 物理和存储
【答案】C
【解析】暂无解析
2、算法分析的两个主要方面是 ( )。
- A. 正确性和简单性
- B. 可读性和文档性
- C. 空间复杂度和时间复杂度
- D. 数据的复杂性和程序复杂性
【答案】D
【解析】暂无解析
3、线性表若采用链式存储结构时,要求内存中可用存储单元的地址 ( )。
- A. 必须是连续的
- B. 部分地址必须是连续的
- C. 一定是不连续的
- D. 连续或不连续都可以
【答案】D
【解析】
在链式存储结构中,存储数据结构的存储空间可以是连续的,也可以是不连续的,各数据结点的存储顺序与数据元素之间的逻辑关系可以不一致。
4、在线性表的下列存储结构中,读取元素耗费时间最少的是 ( )。
- A. 单链表
- B. 顺序表
- C. 循环链表
- D. 双链表
【答案】B
【解析】
顺序表(数组):顺序表在内存中连续存放,通过下标可以直接定位到元素,因此读取元素的时间复杂度为O(1)。
单链表:单链表中的元素在内存中不连续存放,需要通过指针依次遍历才能找到目标元素,因此读取元素的时间复杂度为O(n),其中n为链表长度。
循环链表:循环链表与单链表类似,只是将链表的尾指针指向头结点,形成循环。在读取元素时,也需要通过指针遍历链表,因此时间复杂度同样为O(n)。
双链表:双链表中的每个节点有两个指针,一个指向前一个节点,一个指向后一个节点。虽然双链表在查找前驱节点时比单链表方便,但在读取指定位置的元素时,仍然需要通过指针遍历链表,因此时间复杂度也为O(n)。
5、在一个长度为n的顺序表中,向顺序表的第i个位置(0<i<n+1)插入一个新元素时,需要向后移动 ( ) 个元素。
- A. n-i
- B. n-i+1
- C. n-i-1
- D. i+1
【答案】B
【解析】
在一个长度为n的顺序表中,向顺序表的第i个位置(注意这里的i是从0开始计数的,因为通常数组和顺序表的索引是从0开始的,但题目中给出的是从1开始的描述,所以我们需要做相应的调整)插入一个新元素时,需要将从第i个位置开始到第n-1个位置(共n-i个元素)的所有元素都向后移动一个位置。
由于题目中给出的是从1开始计数的i(0<i<n+1),我们需要将其转换为从0开始计数的索引,即i-1。因此,需要移动的元素个数是 n - (i-1) = n - i + 1。
所以答案是 B. n-i+1。
6、设一个栈的进栈序列是A、B、C、D(即元素A~D依次通过该栈),则借助该栈所得到的输出序列不可能是 ( )。
- A. A、B、C、D
- B. D、C、B、A
- C. A、C、D、B
- D. D、A、B、C
【答案】D
【解析】
栈是一种后进先出(LIFO)的数据结构。对于给定的进栈序列A、B、C、D,我们分析每个选项是否可能作为出栈序列。
A. A、B、C、D
这个序列是可能的,因为元素可以依次进栈并立即出栈,保持与进栈序列相同的顺序。
B. D、C、B、A
这个序列也是可能的。元素A、B、C、D依次进栈后,可以依次出栈D、C、B、A,这符合栈的后进先出特性。
C. A、C、D、B
这个序列也是可能的。元素A进栈后出栈,然后B进栈,C进栈后出栈(此时B仍在栈中),D进栈后出栈,最后B出栈。
D. D、A、B、C
这个序列是不可能的。因为D是最后一个进栈的元素,根据栈的后进先出特性,D不可能在A、B、C之前出栈。
因此,借助该栈所得到的输出序列不可能是D选项:D、A、B、C。
7、顺序循环队列SQ(队头指针 front 指向队首元素,队尾指针 rear 指向队尾元素的下一位置,队列的存诸空间为QUEUESIZE)的队满条件是 ( )。
- A. (SQ.front+1)%QUEUESIZE==(SQ.rear+1)%QUEUESIZE
- B. SQ.front+1 ==(SQ.rear+1)%QUEUESIZE
- C. SQ.front==(SQ.rear+1)%QUEUESIZE
- D. SQ.rear==SQ.front
【答案】C
【解析】
顺序循环队列SQ的队满条件通常不是直接比较front和rear的值,而是基于它们之间的关系和队列的最大长度QUEUESIZE来判断。
首先,我们知道在循环队列中,front指向队首元素,而rear指向队尾元素的下一个位置。当队列满时,下一个要入队的元素将没有空间,这意味着rear的下一个位置将是front。但是,由于我们是在循环队列中,所以我们不能直接比较rear和front,而是需要使用模运算%来确保它们在队列的边界内循环。
参考给出的选项,我们可以分析如下:
A. (SQ.front+1)%QUEUESIZE==(SQ.rear+1)%QUEUESIZE
这个条件实际上并不表示队列满。它比较的是front和rear的下一个位置,但这两个位置可能并不相邻,因此不能作为队满的条件。
B. SQ.front+1 ==(SQ.rear+1)%QUEUESIZE
这个条件同样不正确,因为它没有正确地使用模运算来处理边界情况。
C. SQ.front==(SQ.rear+1)%QUEUESIZE
这个条件是正确的。当rear的下一个位置是front时,队列就是满的。这可以确保即使front和rear在物理存储上不相邻(例如,front在队列的末尾而rear在队列的开始),我们也能正确地判断出队列是否满。
D. SQ.rear==SQ.front
这个条件通常表示队列为空,而不是满。当rear和front指向同一位置时,队列中没有元素。
综上所述,顺序循环队列SQ的队满条件是C:SQ.front==(SQ.rear+1)%QUEUESIZE。
8、假设完全二叉树中,编号为的结点的层次是()。
- A. i
- B. Llog2i」
- C. Llog2i」+1
- D. 1og2(i+1)
【答案】C
【解析】暂无解析
9、某二叉树的中序序列为ABCDEFG,后序序列为BDCAFGE,则其左子树中的结点数目为 ( )。
- A. 3
- B. 2
- C. 4
- D. 5
【答案】C
【解析】
为了确定二叉树的左子树中的结点数目,我们需要根据给定的中序序列和后序序列来构建二叉树。
首先,观察后序序列的最后一个元素,这是二叉树的根节点。在这里,后序序列的最后一个元素是E,所以E是根节点。
接下来,在中序序列中找到E的位置。中序序列是ABCDEFG,E位于中间偏右的位置,说明E左边的元素(A, B, C, D)都在左子树中,而E右边的元素(F, G)都在右子树中。
然后,我们观察后序序列中E左边的部分(BDCA),这部分是左子树的后序序列。由于后序序列是左子树-右子树-根节点的顺序,我们可以知道B是左子树的根节点。
继续在中序序列中找到B的位置,B左边没有元素,右边有C, D两个元素。这说明B的右子树包含C和D。
现在,我们来看后序序列中B右边的部分(DCA),由于后序序列是左子树-右子树-根节点的顺序,我们可以知道D是B的右子树的根节点。而C是D的左子树(因为C在后序序列中出现在D之前)。
现在我们已经确定了左子树的结构:B是根节点,它没有左子树,但有一个右子树,该右子树的根是D,D有一个左子树C(没有右子树)。
因此,左子树中的结点数目是:A(1个)+ B(1个)+ D(1个)+ C(1个)= 3个。
所以答案是 C. 4。
10、无向图的邻接矩阵是一个 ( )。
- A. 对称矩阵
- B. 零矩阵
- C. 上三角矩阵
- D. 对角矩阵
【答案】A
【解析】暂无解析
11、用Prim和Kruskal两种算法构造图的最小生成树,所得到的最小生成树( )。
- A. 是相同的
- B. 是不同的
- C. 可能相同,也可能不同
- D. 以上都不对
【答案】c
【解析】暂无解析
12、哈希表在查找成功时的平均查找长度()。
- A. 与处理冲突方法和装填因子α都有关
- B. 与处理冲突方法有关,而与装填因子无关
- C. 与处理冲突方法无关,而与装填因子α有关
- D. 与处理冲突方法无关,也与装填因子无关
【答案】A
【解析】暂无解析
13、在二叉排序树中,关键字最小的结点,它的 ( )。
- A. 左子树一定为空
- B. 右子树一定为空
- C. 左、右子树均为空
- D. 左、右子树均不为空
【答案】A
【解析】
在二叉排序树(也称为二叉搜索树)中,关键字最小的结点的特征如下:
在二叉搜索树中,左子树上的所有节点都比根节点小,右子树上的所有节点都比根节点大。
因此,关键字最小的节点一定是在最左边的节点。
由于没有更小的节点存在,最小节点的左子树一定为空。
因此,正确答案是:A. 左子树一定为空。
14、下列关键字序列中,( )是堆。
- A. 16,72,31,23,94,53
- B. 16,23,53,31,94,72
- C. 16,53,23,94,31,72
- D. 94,23,31,72,16,53
【答案】B
【解析】暂无解析
15、若有序表的关键字序列为(b,c,d,f,g,q,r,s,t),在折半查找关键字b的过程中,先后进行比较的关键字依次为( )。
- A. f、c、b
- B. f、d、b
- C. g、c、b
- D. g、d、b
【答案】A
【解析】
在折半查找(也称为二分查找)中,我们总是将中间位置上的元素与目标元素进行比较。如果目标元素小于中间元素,我们就在左半部分继续查找;如果目标元素大于中间元素,我们就在右半部分继续查找;如果它们相等,我们就找到了目标元素。
对于给定的有序表关键字序列 (b, c, d, f, g, q, r, s, t),当我们想要查找关键字b时,过程如下:
查找范围是整个序列,中间位置上的关键字是 f。
因为 b < f,所以我们在左半部分继续查找。
现在的查找范围是 (b, c, d),中间位置上的关键字是 c。
因为 b < c,我们继续在左半部分查找。
现在的查找范围是 (b),直接比较发现 b = b,查找成功。
在整个过程中,我们先后比较的关键字是 f、c、b。
因此,正确答案是 A. f、c、b
16、算法分析的目的是 ( )。
- A. 找出数据结构的合理性
- B. 研究算法中的输入和输出的关系
- C. 分析算法的效率以求改进
- D. 分析算法的易懂性和文档性
【答案】C
【解析】暂无解析
17、以下数据结构中哪一个是线性结构 ( ) 。
- A. 有向图
- B. 栈
- C. 二叉排序树
- D. 哈夫曼树
【答案】B
【解析】暂无解析
18、向一个有80个元素的顺序表中插入一个新元素并保持原来顶序不变,平均要移动 ( ) 个元素。
- A. 39.5
- B. 40
- C. 40.5
- D. 41
【答案】B
【解析】n/2
19、下面关于线性表的叙述正确的是( )。
- A. 线性表采用顺序存储不必占用一片连续的存储空间
- B. 线性表采用链式存储必须占用一片连续的存储空间
- C. 线性表采用链式存储便于插入和删除操作的实现
- D. 线性表采用顺序存储便于插入和删除操作的实现
【答案】C
【解析】暂无解析
20、设一条单链表的头指针变量为head且该链表没有头结点,则其判空条件是 ( ) 。
- A. head==null
- B. head.next==null
- C. head.next==head
- D. head==0
【答案】A
【解析】
在单链表中,头指针head通常指向链表的第一个节点。如果链表没有头结点(即头指针直接指向第一个数据节点),那么链表为空的条件就是头指针head本身为null或nullptr(在C++中)或None(在Python中)。
对于给出的选项:
A. head==null:这是正确的条件,表示头指针为空,即链表为空。
B. head.next==null:这个条件不能用来判断链表是否为空,因为当head为空时,尝试访问head.next会导致空指针异常。
C. head.next==head:这个条件通常用于判断链表是否形成了环,而不是用来判断链表是否为空。
D. head==0:这个条件在C或C++的上下文中是错误的,因为null是一个指针类型的常量,通常用来表示空指针,而不是整数0。但在某些语境下(如某些非标准的C或C++方言,或某些其他编程语言),0可能被用作空指针的等价物,但这并不是标准的做法。
因此,正确的选项是:
A. head==null
21、设指针变量 p 指向单链表结点 A,则删除结点 A 的后继结点 B 需要的操作为 ( )。
- A. p.next=p.next.next
- B. p=p.next
- C. p=p.next.next
- D. p.next=p
【答案】A
【解析】
在单链表中,如果指针变量 p 指向结点 A,并且我们想要删除结点 A 的后继结点 B,我们需要执行的操作是将 A 的 next 指针指向 B 的后继结点,从而“跳过”B。
现在我们来分析给出的选项:
A. p.next=p.next.next:这是正确的操作。它将 A 的 next 指针指向 B 的后继结点,从而删除了结点 B。
B. p=p.next:这个操作会让 p 指向 B,而不是删除 B。
C. p=p.next.next:这个操作会让 p 跳过 B 并指向 B 的后继结点,但它没有删除 B,而且改变了 p 的指向。
D. p.next=p:这个操作将 A 的 next 指针指向 A 自己,形成了一个环,但并没有删除 B。
因此,正确的选项是:
A. p.next=p.next.next
22、元素A、B、C、D顺序连续进入队列 qu 后,队尾元素是 ( )。
- A. A
- B. B
- C. C
- D. D
【答案】D
【解析】暂无解析
23、已知一棵完全二叉树的第6层(设根为第1层)有8个叶结点,则该完全二叉树的结点个数最少是 ( )。
- A. 39
- B. 52
- C. 111
- D. 119
【答案】A
【解析】暂无解析
24、设某二叉树中度数为 0 的结点数为 N0,度数为 1 的结点数为 N1,度数为 2 的结点数为N2,则下列等式成立的是 ( ) 。
- A. N0=N1+1
- B. N0=N2+1
- C. N0=N1+N2
- D. N0=2N1+1
【答案】B
【解析】
在二叉树中,每个结点都有一个度数,即该结点拥有的子结点数。对于二叉树,一个结点最多有两个子结点(左子结点和右子结点)。
设二叉树中度数为 0 的结点数为 N0,度数为 1 的结点数为 N1,度数为 2 的结点数为 N2。
根据二叉树的性质,我们有以下等式:
所有的结点(包括度为0、1、2的结点)的总数是 N0 + N1 + N2。
对于每一个度数为 1 的结点,它贡献 1 条边到其子结点;对于每一个度数为 2 的结点,它贡献 2 条边到其子结点。因此,边的总数是 N1 + 2N2。
在树中,边的数量总是比结点的数量少1(因为树是连通的,且没有环)。
所以,我们有:
N0 + N1 + N2 = (N1 + 2N2) + 1
整理上述等式,我们得到:
N0 = N2 + 1
这就是二叉树的性质之一,也被称为二叉树的结点性质。
因此,正确答案是:
B. N0 = N2 + 1
25、任何一个无向连通图的最小生成树( )。
- A. 只有一棵
- B. 一定有多棵
- C. 有一棵或多棵
- D. 可能不存在
【答案】C
【解析】
对于无向连通图的最小生成树,我们需要明确几个概念:
最小生成树:在一个无向连通图中,如果一棵子图是一棵树且包含了原图中的所有顶点,那么这棵子图被称为原图的一棵生成树。在所有生成树中,边的权值之和最小的那棵生成树被称为最小生成树。
唯一性:最小生成树并不总是唯一的。对于某些图,可能存在多棵最小生成树,它们的边权值之和都是最小的。
现在我们来分析选项:
A. 只有一棵:这是不正确的,因为存在多个最小生成树的情况。
B. 一定有多棵:这也是不正确的,因为有些图只有一棵最小生成树。
C. 有一棵或多棵:这是正确的。最小生成树可能只有一棵,也可能有多棵。
D. 可能不存在:这是不正确的,因为题目已经说明了是无向连通图,所以至少存在一棵生成树,进而也至少存在一棵最小生成树。
因此,正确答案是 C:有一棵或多棵。
26、关键路径是事件结点网络中( )。
- A. 从源点到汇点的最短路径
- B. 从源点到汇点的最长路径
- C. 最长的回路
- D. 最短的回路
【答案】B
【解析】
关键路径的定义:关键路径是事件结点网络(通常指AOE网,即边表示活动的网络)中从源点到汇点(即开始结点到完成结点)的路径,其路径长度(路径上各活动持续时间之和)是最长的。
选项分析:
A. 从源点到汇点的最短路径:这不是关键路径的定义,因为关键路径关注的是最长路径。
B. 从源点到汇点的最长路径:这是关键路径的正确定义。
C. 最长的回路:关键路径不是回路,而是从开始到结束的路径。
D. 最短的回路:同样,关键路径不是回路,且关注的是最长路径。
综上所述,关键路径是事件结点网络中从源点到汇点的最长路径。因此,正确答案是B:从源点到汇点的最长路径。
27、折半查找有序表(4,6,10,12,20,30,50,70,88,100) 。若查找表中元素58,则它将依次与表中 ( ) 比较大小,查找结果是失败。
- A. 20,70,30,50
- B. 30,88,70,50
- C. 20,50
- D. 30,88,50
【答案】A
【解析】暂无解析
28、对线性表进行折半查找时,要求线性表必须 ( )。
- A. 以顺序方式存储
- B. 以顺序方式存储,且结点按关键字有序排序
- C. 以链式方式存储
- D. 以链式方式存储,且结点按关键字有序排序
【答案】B
【解析】暂无解析
29、下列四种排序中( ) 的稳定性是稳定的。
- A. 快速排序
- B. 冒泡排序
- C. 希尔排序
- D. 堆排序
【答案】B
【解析】暂无解析
二、填空题
1、设一个栈的初始状态为空,元素a-f依次通过栈,若出栈的序列是:b、d、c、f、e、a。当元素d出栈时,栈内还有哪些元素 【 a、c 】。
2、在一个大顶堆中,堆顶结点的值是所有结点中的【 最大值 】。
3、解决哈希表冲突的主要方法有:【 开放定址法 】、再哈希法和链地址法。
4、一棵具有257个结点的完全二叉树,它的深度为 【 9 】。
5、一棵高度为6的满二叉树的结点数为【 63 】。
6、将一棵有100个结点的完全二叉树从根开始,逐层从左到右依次对结点进行编号。若根结点的编号为1,则编号为49的结点的右孩子编号为【 98 】。
7、设一组初始记录关键字为{22,73,71,16,94,23,50},则一趟冒泡排序后(升序,自右向左比较)的排序结果为【 16,22,73,71,23,94,50 】。
8、设一元多项式的链表存储结构为:
class PolyNode
{float coef; //系数
int expn; //指数
PolyNode next; //指向下一个结点的指针
PolyNode(float coef,int expn)
{
This.coef=coef;
This.expn=expn;
Next=null;
}
}
现有p(X)多项式的存储结构图如下图所示:

则p(X)多项式的数学表达式为:【P(x) = 26X^19 + 82X^2】。
9、在一个单链表中,若删除P所指向结点的后继结点,则执行的核心语句是【 p.next = p.next.next 】。
10、顺序循环队列SQ(队头指针 front 指向队首元素,队尾指针 rear 指向队尾元素的下一位置,队列的存储空间为QUEUESIZE),则循环队列的长度为【 (SQ.rear+QUEUESIZE-SQ.front)%QUEUSIZE 】。
11、从未排序的序列中,依次取出元素,与已排序序列的元素比较后,放入已排序序列中的恰当位置上,这是【 插入 】排序。从未排序的序列中,挑选出元素,放在已排序序列的某一端位置,这是【 选择 】排序。逐次将待排序的序列中的相邻元素两两比较,凡是逆序则进行交换,这是【 冒泡 】排序。
12、已知有向图G=(V,E),其中:V={1,2,3,4},E={<1,2>,<1,3>,<2,3>,<2,4>,❤️,4>} 则图的拓扑序列为【 {1,2,3,4} 】。
13.在一个单链表L中,在结点pre之后插入新结点p,如下图所示:

则插入p节点的操作(核心代码)为:【p.next = pre.naxt;pre.next = p】
先赞后看,养成习惯!!!^ _ ^ ❤️ ❤️ ❤️
码字不易,大家的支持就是我的坚持下去的动力。点赞后不要忘了关注我哦!