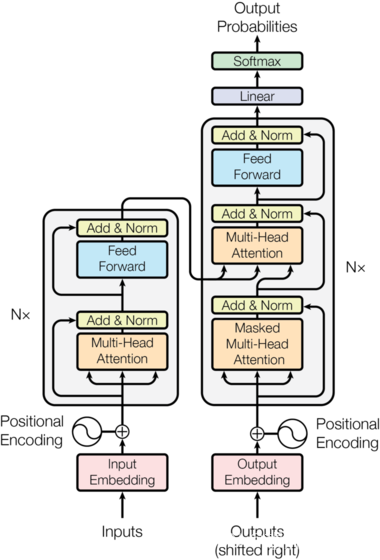
整体结构
1. 嵌入层(Embedding Layer)
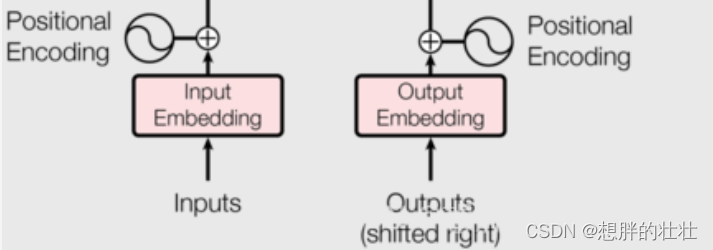
生活中的例子:字典查找
想象你在读一本书,你不认识某个单词,于是你查阅字典。字典为每个单词提供了一个解释,帮助你理解这个单词的意思。嵌入层就像这个字典,它将每个单词(或输入序列中的每个标记)映射到一个高维向量(解释),这个向量包含了单词的各种语义信息。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import math
class EmbeddingLayer(nn.Module):
def __init__(self, vocab_size, d_model, max_seq_length=512):
super(EmbeddingLayer, self).__init__()
# vocab_size: 词汇表的大小,即输入序列中可能的不同标记的总数。
# d_model: 每个嵌入向量的维度,即词嵌入向量的长度。
# max_seq_length: 序列的最大长度,用于位置嵌入。
self.embedding = nn.Embedding(vocab_size, d_model) # 词嵌入层
self.pos_embedding = nn.Embedding(max_seq_length, d_model) # 位置嵌入层
self.d_model = d_model
# 初始化位置编码
pe = torch.zeros(max_len, d_model)
# 生成词位置列表
position = torch.arange(0, max_len).unsqueeze(1)
# 根据公式计算词位置参数
div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))
# 生成词位置矩阵
my_matmulres = position * div_term
# 给位置编码矩阵奇数列,赋值sin曲线特征
pe[:, 0::2] = torch.sin(my_matmulres)
# 给位置编码矩阵偶数列,赋值cos曲线特征
pe[:, 1::2] = torch.cos(my_matmulres)
# 形状变化 [max_seq_length,d_model]-->[1,max_seq_length,d_model]
pe = pe.unsqueeze(0)
# 把pe位置编码矩阵 注册成模型的持久缓冲区buffer; 模型保存再加载时,可以根模型参数一样,一同被加载
# 什么是buffer: 对模型效果有帮助的,但是却不是模型结构中超参数或者参数,不参与模型训练
self.register_buffer('pe', pe)
def forward(self, x):
seq_length = x.size(1) # 序列长度
pos = torch.arange(0, seq_length, device=x.device).unsqueeze(0) # 生成位置索引
return self.embedding(x) * math.sqrt(self.d_model) + self.pe[:,:x.size()[-1], :] # 词嵌入和位置嵌入相加
2. 多头自注意力机制(Multi-Head Self-Attention)

生活中的例子:小组讨论
想象你在一个小组讨论中,每个人(每个位置上的单词)都提出自己的观点(Query),并听取其他人的意见(Key和Value)。每个人对所有其他人的观点进行加权平均,以形成自己的新观点。多头注意力机制类似于多个小组同时进行讨论,每个小组从不同的角度(头)讨论问题,然后将所有讨论结果合并在一起。
class MultiHeadSelfAttention(nn.Module):
def __init__(self, d_model, nhead):
super(MultiHeadSelfAttention, self).__init__()
# d_model: 输入和输出的维度,即每个位置的特征向量的长度。
# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。
self.nhead = nhead
self.d_model = d_model
# 定义线性变换层
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.out_linear = nn.Linear(d_model, d_model)
self.scale = (d_model // nhead) ** 0.5 # 缩放因子
def forward(self, x):
batch_size = x.size(0) # 获取批大小
# 线性变换并分成多头
q = self.q_linear(x).view(batch_size, -1, self.nhead, self.d_model // self.nhead).transpose(1, 2)
k = self.k_linear(x).view(batch_size, -1, self.nhead, self.d_model // self.nhead).transpose(1, 2)
v = self.v_linear(x).view(batch_size, -1, self.nhead, self.d_model // self.nhead).transpose(1, 2)
# 计算注意力得分
scores = torch.matmul(q, k.transpose(-2, -1)) / self.scale
attn = torch.nn.functional.softmax(scores, dim=-1) # 计算注意力权重
context = torch.matmul(attn, v).transpose(1, 2).contiguous().view(batch_size, -1, self.d_model) # 加权求和
out = self.out_linear(context) # 最后一层线性变换
return out
3. 前馈神经网络(Feed-Forward Network)

生活中的例子:信息过滤和处理
想象你在整理会议纪要,需要对会议地录音进行归纳、总结和补充。前馈神经网络类似于这个过程,它对输入的信息进行进一步处理和转换,以提取重要特征。
class FeedForwardNetwork(nn.Module):
def __init__(self, d_model, dim_feedforward, dropout=0.1):
super(FeedForwardNetwork, self).__init__()
# d_model: 输入和输出的维度,即每个位置的特征向量的长度。
# dim_feedforward: 前馈神经网络的隐藏层维度。
# dropout: 在前馈神经网络中使用的dropout比率,用于正则化。
self.linear1 = nn.Linear(d_model, dim_feedforward) # 第一个线性层
self.dropout = nn.Dropout(dropout) # dropout层
self.linear2 = nn.Linear(dim_feedforward, d_model) # 第二个线性层
def forward(self, x):
return self.linear2(self.dropout(torch.nn.functional.relu(self.linear1(x)))) # 激活函数ReLU和dropout
4. 层归一化(Layer Normalization)

生活中的例子:团队合作中的标准化
想象你在一个团队中工作,每个人都有不同的工作习惯和标准。为了更好地合作,团队决定采用统一的工作标准(如文档格式、命名规范等)。层归一化类似于这种标准化过程,它将输入归一化,使得每个特征的均值为0,标准差为1,以稳定和加速训练。
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-6):
super(LayerNorm, self).__init__()
# d_model: 输入和输出的维度,即每个位置的特征向量的长度。
# eps: 用于数值稳定的小值,防止除以零。
self.gamma = nn.Parameter(torch.ones(d_model)) # 缩放参数
self.beta = nn.Parameter(torch.zeros(d_model)) # 偏移参数
self.eps = eps # epsilon,用于数值稳定
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True) # 计算均值
std = x.std(dim=-1, keepdim=True) # 计算标准差
return self.gamma * (x - mean) / (std + self.eps) + self.beta # 归一化
5. 残差连接(Residual Connection)
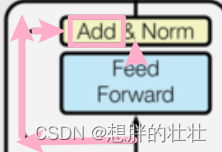
生活中的例子:备忘录
想象你在会议上记了很多笔记。为了确保不会遗漏任何重要信息,你在总结时会参照这些笔记。残差连接类似于这个过程,它将每层的输入直接加到输出上,确保信息不会在层与层之间丢失。
class ResidualConnection(nn.Module):
def __init__(self, d_model, dropout=0.1):
super(ResidualConnection, self).__init__()
# d_model: 输入和输出的维度,即每个位置的特征向量的长度。
# dropout: 在残差连接中使用的dropout比率,用于正则化。
self.norm = LayerNorm(d_model) # 层归一化
self.dropout = nn.Dropout(dropout) # dropout层
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x))) # 残差连接
6. 编码器层(Encoder Layer)
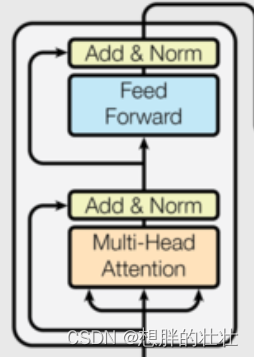
生活中的例子:多轮面试
想象你在参加多轮面试,每轮面试都有不同的考官,考察不同的方面(如专业知识、沟通能力等)。每轮面试都帮助你更全面地展示自己。编码器层类似于这种多轮面试的过程,每层处理输入序列的不同方面,逐层提取和增强特征。
class EncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward, dropout=0.1):
super(EncoderLayer, self).__init__()
# d_model: 输入和输出的维度,即每个位置的特征向量的长度。
# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。
# dim_feedforward: 前馈神经网络的隐藏层维度。
# dropout: 在各层中使用的dropout比率,用于正则化。
self.self_attn = MultiHeadSelfAttention(d_model, nhead) # 多头自注意力机制
self.feed_forward = FeedForwardNetwork(d_model, dim_feedforward, dropout) # 前馈神经网络
self.sublayers = nn.ModuleList([ResidualConnection(d_model, dropout) for _ in range(2)]) # 两个子层(注意力和前馈网络)
def forward(self, src):
src = self.sublayers[0](src, lambda x: self.self_attn(x)) # 应用自注意力机制
src = self.sublayers[1](src, self.feed_forward) # 应用前馈神经网络
return src
7. 解码器层(Decoder Layer)
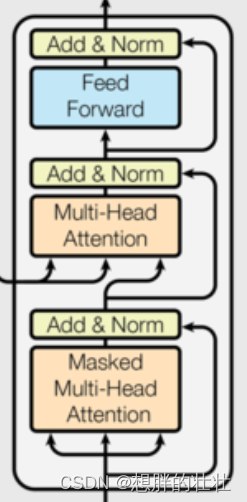
生活中的例子:逐步解谜
想象你在玩一个解谜游戏,每解决一个谜题(每层解码器),你都会得到新的线索,逐步解开整个谜题。解码器层类似于这种逐步解谜的过程,每层结合当前解码的结果和编码器的输出,逐步生成目标序列。
class DecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward, dropout=0.1):
super(DecoderLayer, self).__init__()
# d_model: 输入和输出的维度,即每个位置的特征向量的长度。
# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。
# dim_feedforward: 前馈神经网络的隐藏层维度。
# dropout: 在各层中使用的dropout比率,用于正则化。
self.self_attn = MultiHeadSelfAttention(d_model, nhead) # 多头自注意力机制
self.cross_attn = MultiHeadSelfAttention(d_model, nhead) # 编码器-解码器注意力
self.feed_forward = FeedForwardNetwork(d_model, dim_feedforward, dropout) # 前馈神经网络
self.sublayers = nn.ModuleList([ResidualConnection(d_model, dropout) for _ in range(3)]) # 三个子层(自注意力、交叉注意力、前馈网络)
def forward(self, tgt, memory):
tgt = self.sublayers[0](tgt, lambda x: self.self_attn(x)) # 应用自注意力机制
tgt = self.sublayers[1](tgt, lambda x: self.cross_attn(x, memory)) # 应用编码器-解码器注意力
tgt = self.sublayers[2](tgt, self.feed_forward) # 应用前馈神经网络
return tgt
8. 编码器(Encoder)
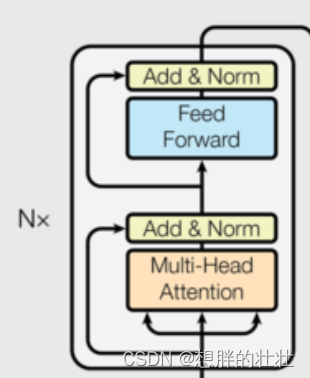
class Encoder(nn.Module):
def __init__(self, num_layers, d_model, nhead, dim_feedforward, dropout=0.1):
super(Encoder, self).__init__()
# num_layers: 编码器层的数量,即堆叠的编码器层数。
# d_model: 输入和输出的维度,即每个位置的特征向量的长度。
# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。
# dim_feedforward: 前馈神经网络的隐藏层维度。
# dropout: 在各层中使用的dropout比率,用于正则化。
self.layers = nn.ModuleList([EncoderLayer(d_model, nhead, dim_feedforward, dropout) for _ in range(num_layers)]) # 堆叠多个编码器层
def forward(self, src):
for layer in self.layers:
src = layer(src) # 依次通过每个编码器层
return src
9. 解码器(Decoder)
class Decoder(nn.Module):
def __init__(self, num_layers, d_model, nhead, dim_feedforward, dropout=0.1):
super(Decoder, self).__init__()
# num_layers: 解码器层的数量,即堆叠的解码器层数。
# d_model: 输入和输出的维度,即每个位置的特征向量的长度。
# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。
# dim_feedforward: 前馈神经网络的隐藏层维度。
# dropout: 在各层中使用的dropout比率,用于正则化。
self.layers = nn.ModuleList([DecoderLayer(d_model, nhead, dim_feedforward, dropout) for _ in range(num_layers)]) # 堆叠多个解码器层
def forward(self, tgt, memory):
for layer in self.layers:
tgt = layer(tgt, memory) # 依次通过每个解码器层
return tgt
10. Transformer模型
class TransformerModel(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout=0.1):
super(TransformerModel, self).__init__()
# vocab_size: 词汇表的大小,即输入序列中可能的不同标记的总数。
# d_model: 每个嵌入向量的维度,即词嵌入向量的长度。
# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。
# num_encoder_layers: 编码器层的数量,即堆叠的编码器层数。
# num_decoder_layers: 解码器层的数量,即堆叠的解码器层数。
# dim_feedforward: 前馈神经网络的隐藏层维度。
# dropout: 在各层中使用的dropout比率,用于正则化。
self.embedding = EmbeddingLayer(vocab_size, d_model) # 嵌入层
self.encoder = Encoder(num_encoder_layers, d_model, nhead, dim_feedforward, dropout) # 编码器
self.decoder = Decoder(num_decoder_layers, d_model, nhead, dim_feedforward, dropout) # 解码器
self.fc = nn.Linear(d_model, vocab_size) # 最后一层线性变换,将输出维度映射到
词汇表大小
def forward(self, src, tgt):
src = self.embedding(src) # 嵌入输入序列
tgt = self.embedding(tgt) # 嵌入目标序列
memory = self.encoder(src) # 编码器处理输入序列
output = self.decoder(tgt, memory) # 解码器处理目标序列
output = self.fc(output) # 映射到词汇表大小
return output
训练示例
# 参数
# vocab_size: 词汇表的大小,即输入序列中可能的不同标记的总数。
# d_model: 每个嵌入向量的维度,即词嵌入向量的长度。
# nhead: 注意力头的数量,多头注意力机制中并行的注意力计算数。
# num_encoder_layers: 编码器层的数量,即堆叠的编码器层数。
# num_decoder_layers: 解码器层的数量,即堆叠的解码器层数。
# dim_feedforward: 前馈神经网络的隐藏层维度。
# dropout: 在各层中使用的dropout比率,用于正则化。
# batch_size: 每个训练批次中的样本数量。
# seq_length: 输入序列的长度。
# num_epochs: 训练的轮数,即遍历整个训练集的次数。
vocab_size = 1000
d_model = 512
nhead = 8
num_encoder_layers = 6
num_decoder_layers = 6
dim_feedforward = 2048
dropout = 0.1
batch_size = 32
seq_length = 10
num_epochs = 10
# 数据集
src = torch.randint(0, vocab_size, (batch_size, seq_length))
tgt = torch.randint(0, vocab_size, (batch_size, seq_length))
dataset = TensorDataset(src, tgt)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 模型实例
model = TransformerModel(vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, dropout)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练
for epoch in range(num_epochs):
for src_batch, tgt_batch in dataloader:
tgt_input = tgt_batch[:, :-1] # 目标输入
tgt_output = tgt_batch[:, 1:] # 目标输出
optimizer.zero_grad()
output = model(src_batch, tgt_input) # 前向传播
output = output.permute(1, 2, 0) # 调整形状以匹配损失函数
loss = criterion(output, tgt_output) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {loss.item()}")
print("训练完成")
代码说明
- EmbeddingLayer:将输入序列和位置嵌入映射到高维空间。
- MultiHeadSelfAttention:实现多头自注意力机制,包括查询、键和值的线性变换和注意力计算。
- FeedForwardNetwork:前馈神经网络,用于进一步处理特征。
- LayerNorm:层归一化,用于稳定训练过程。
- ResidualConnection:残差连接,帮助训练更深的网络。
- EncoderLayer:将多头自注意力机制和前馈神经网络组合在一起,形成编码器层。
- DecoderLayer:包括多头自注意力机制、编码器-解码器注意力和前馈神经网络,形成解码器层。
- Encoder:由多个编码器层堆叠而成。
- Decoder:由多个解码器层堆叠而成。
- TransformerModel:将编码器和解码器组合在一起,形成完整的Transformer模型。