1、主要解决问题类型
1.1 预测分析(Prediction)
线性回归可以用来预测一个变量(通常称为因变量或响应变量)的值,基于一个或多个输入变量(自变量或预测变量)。例如,根据房屋的面积、位置等因素预测房价。
1.2 异常检测(Outlier Detection)
线性回归可以帮助识别数据中的异常值。异常值可能会影响回归模型的准确性,因此检测和处理异常值是线性回归分析的重要一环。
1.3 关联分析(Association)
线性回归可以帮助确定两个或多个变量之间的关系强度和方向。它可以显示自变量与因变量之间是正相关还是负相关,以及相关性的强度。
2、线性回归模型
2.1 什么是线性回归模型
模型表达式: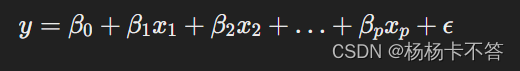
- y 是因变量(要预测的目标)
- x1,x2,…,xp 是自变量(特征或解释变量)
- β0,β1,…,βp 是模型的参数,表示因变量与自变量之间的影响关系
- ϵ 是误差项,表示模型无法解释的随机误差。
2.2 如何判断某个问题是否适合使用线性回归模型?
- 线性关系假设:线性回归模型假设因变量与自变量之间的关系是线性的。因此,首先需要检验自变量和因变量之间是否存在大致的线性关系。可以通过绘制散点图观察变量之间的关系来初步判断。
- 连续性和正态性假设:线性回归模型通常假设自变量和因变量是连续的,并且误差项 ϵ 是独立同分布的,并且服从正态分布。如果数据违反这些假设,可能需要考虑其他类型的模型。
- 数据量:通常来说,线性回归对数据量的要求并不高,但是如果数据量非常少或者变量之间的关系非常复杂,可能需要考虑更复杂的模型。
- 预测的需求:如果任务是预测一个连续的数值型目标变量,而且认为这些预测可以通过自变量的线性组合来实现,那么线性回归也是一个合适的选择。
2.3 NILM中的线性回归模型
2.3.1 负载识别问题
在NILM中,负载识别是一个核心问题,即通过总电力消耗数据来识别和分离出各个电器的能耗。线性回归模型可以应用于以下情况:
问题描述: 根据总电力消耗(因变量)和不同电器的特征(自变量,如电流波形、功率特征等),建立线性回归模型来预测每个电器的能耗。
实际案例: 假设我们有一个家庭的总电力消耗数据以及每个电器在不同时间段内的功率特征。我们可以利用线性回归模型来拟合这些数据,从而识别出在该家庭中运行的各种电器,比如冰箱、空调、洗衣机等。
求解过程如下
1. 数据的收集与准备
首先,我们需要收集如下数据:
- 总电力消耗数据: 在监测点(例如家庭电表)上采集的总电力消耗时间序列数据。
- 各个电器的特征数据: 这些特征数据可以包括电器的功率特性、波形数据(如电流波形)、电压特征等。这些数据通常是通过传感器或NILM系统采集的。
2. 模型设定
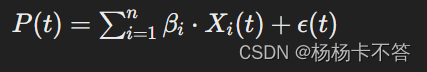
- P(t) 是在时刻 𝑡 的总电力消耗
- Xi(t) 是第 𝑖 个电器的特征数据,如功率特征
- βi 是模型的系数,表示第 𝑖 个电器的能耗
- ϵ(t) 是误差项,表示模型无法解释的随机误差。
3. 模型拟合
接下来的步骤是通过拟合模型来估计系数 𝛽𝑖,这里使用最小二乘法来优化模型参数。
假设我们有以下数据:

我们可以将数据集分为训练集和测试集,然后按照上述步骤建立线性回归模型。例如,可以使用Python中的Scikit-Learn库来实现:
from sklearn.linear_model import LinearRegression
import numpy as np
# 假设已经有了总电力消耗数据 P 和电器特征数据 X
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(X, P)
# 打印模型系数(电器的能耗)
print("Coefficients (beta):", model.coef_)
print("Intercept (beta_0):", model.intercept_)
4. 模型评估与验证
完成模型拟合后,需要对模型进行评估和验证:
- 评估模型拟合度: 通过比较模型预测的总电力消耗与实际观测值之间的差异来评估模型的拟合度。
- 验证识别准确性: 使用未见过的数据集来验证模型的负载识别能力,即模型是否能够准确识别和分离不同电器的能耗。
2.3.1.1 简单的负载识别(使用线性回归模型)
1. 数据准备
- P 是总电力消耗数据,假设是一个长度为 n 的 numpy 数组。
- X1 和 X2 是两个电器的功率特征数据,每个也是长度为 n 的 numpy 数组。
2. 特征矩阵X的构建
- 使用 np.vstack 将每个电器的特征数据堆叠为一个矩阵,每列对应一个电器的特征数据。
- 使用 .T 进行转置,以确保每行对应相同时间点的数据。
3. 模型拟合
- 创建 LinearRegression 对象,并使用 fit 方法拟合模型,将 X 作为自变量,P 作为因变量。
4.模型系数
- model.coef_ 返回每个电器的能耗系数(即模型的斜率)。
- model.intercept_ 返回模型的截距项(即 β0)。
代码实现如下:
import numpy as np
from sklearn.linear_model import LinearRegression
# 假设有以下数据:
# 总电力消耗数据 P,假设是一个长度为 n 的 numpy 数组
P = np.array([100, 150, 200, 180, 210])
# 电器特征数据 X,假设有两个电器,每个电器的特征数据也是长度为 n 的 numpy 数组
X1 = np.array([20, 30, 40, 35, 45]) # 电器1的功率特征
X2 = np.array([15, 25, 30, 20, 28]) # 电器2的功率特征
# 将电器特征数据整合成一个特征矩阵 X,每一列对应一个电器的特征数据
X = np.vstack([X1, X2]).T # 转置是为了确保每行对应同一个时间点的数据
# 创建并拟合线性回归模型
model &#