Sharding-JDBC从入门到精通(3)- Sharding-JDBC 入门程序
一、Sharding-JDBC 入门程序(水平分表)-环境搭建
1、需求说明
使用 Sharding-JDBC 完成对订单表的水平分表,通过快速入门程序的开发,快速体验 Sharding-JDBc 的使用方法。
人工创建两张表,t order_1 和 t_order 2, 这两张表是订单表拆分后的表,通过 Sharding-Jdbc 向订单表插入数据,按照一定的分片规则,主键为偶数的进入 t_order_1, 另一部分数据进入 t_order_2,通过 Sharding-Jdbc 查询数据,根据 SQL 语句的内容从 t_order 1 或 t_order_2 查询数据。
2、环境说明
- 操作系统: Win10
- 数据库: MySQL-5.7.25
- JDK : 64位jdk1.8.0_201
- 应用框架: spring-boot-2.1.3.RELEASE, Mybatis3.5.0
- Sharding-jDBc:sharding-jdbc-spring-bootkstarter-4.0.0-Rc1
3、创建数据库
3.1 创建订单库 order_db
CREATE DATABASE `order_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
3.2 在 order_db 中创建 t_order_1 和 t_order_2 表
# 创建 t_order_1 表
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` BIGINT(20) NOT NULL COMMENT '订单id',
`price` DECIMAL(10,2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT(20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY(`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC;
# 创建 t_order_2 表
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` BIGINT(20) NOT NULL COMMENT '订单id',
`price` DECIMAL(10,2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT(20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY(`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC;
4、打开 idea 创建 artifactId 名为 dbsharding 的 maven 父工程。
--> idea --> File
--> New --> Project
--> Maven
Project SDK: ( 1.8(java version "1.8.0_131" )
--> Next
--> Groupld : ( djh.it )
Artifactld : ( dbsharding )
Version : 1.0-SNAPSHOT
--> Name: ( dbsharding )
Location: ( ...\dbsharding\ )
--> Finish
5、在 dbsharding 父工程的 pom.xml 文件中导入依赖坐标。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>djh.it</groupId>
<artifactId>dbsharding</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>sharding_jdbc_simple</module>
</modules>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.0</version>
</dependency>
<dependency>
<groupId>javax.interceptor</groupId>
<artifactId>javax.interceptor-api</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.16</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-typehandlers-jsr310</artifactId>
<version>1.0.2</version>
</dependency>
</dependencies>
</dependencyManagement>
</project>
<!-- ...\dbsharding\pom.xml -->
6、打开 idea 创建 artifactId 名为 sharding_jdbc_simple 的 maven 子工程(子模块)。
--> idea
--> 右键 dbsharding 父工程
--> New --> Module...
--> Maven
Project SDK: ( 1.8(java version "1.8.0_131" )
--> Next
--> Groupld : ( djh.it )
Artifactld : ( sharding_jdbc_simple )
Version : 1.0-SNAPSHOT
--> Module Name: ( sharding_jdbc_simple )
Content root: ( ...\dbsharding\sharding_jdbc_simple )
Module file location: ( ...\dbsharding\sharding_jdbc_simple )
--> Finish
7、在 sharding_jdbc_simple 子工程(子模块)的 pom.xml 文件中导入依赖坐标。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>dbsharding</artifactId>
<groupId>djh.it</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>sharding_jdbc_simple</artifactId>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
</dependency>
</dependencies>
</project>
<!-- ...\dbsharding\sharding_jdbc_simple\pom.xml -->
8、在 sharding_jdbc_simple 子工程(子模块)中,创建启动类 ShardingJdbcSimpleBootstrap.java。
/**
* D:\Java\java-test\idea\dbsharding\sharding_jdbc_simple\src\main\java\djh\it\dbsharding\simple\ShardingJdbcSimpleBootstrap.java
*
* 2024-6-28 创建启动类 ShardingJdbcSimpleBootstrap.java
*/
package djh.it.dbsharding.simple;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ShardingJdbcSimpleBootstrap {
public static void main(String[] args) {
SpringApplication.run(ShardingJdbcSimpleBootstrap.class, args);
}
}
二、Sharding-JDBC 入门程序(水平分表)-分片配置
1、分片规则配置
分片规则配置是 sharding-jdbc 进行对分库分表操作的重要依据,配置内容包括:数据源、主键生成策略、分片策略等。需要在工程的 application.properties 配置文件中配置。
- 1.首先定义数据源 m1,并对 m1 进行实际的参数配置。
- 2.指定 t_order 表的数据分布情况,他分布在 m1.t_order_1, m1.t_order_2
- 3.指定 t_order 表的主键生成策略为 SNOWFLAKE, SNOWFLAKE 是一种分布式自增算法,保证 id 全局唯一
- 4.定义 t_order 分片策略,order_id 为偶数的数据落在 t_order_1, 为奇数的落在 t_order_2, 分表策略的表达式为 t_order_$->{order_id % 2+ 1}
2、在 sharding_jdbc_simple 子工程(子模块)中,创建 application.properties 配置文件
# dbsharding\sharding_jdbc_simple\src\main\resources\application.properties
server.port = 56081
spring.application.name = sharding-jdbc-simple-demo
server.servlet.context-path = /sharding-jdbc-simple-demo
spring.http.encoding.enabled = true
spring.http.encoding.charset = utf-8
spring.http.encoding.force = true
spring.main.allow-bean-definition-overriding = true
mybatis.configuration.map-underscore-to-camel-case = true
# 配置 sharding-jdbc 分片规则
# 定义数据源(定义数据源名为 m1)
spring.shardingsphere.datasource.names = m1
spring.shardingsphere.datasource.m1.type = com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.m1.url = jdbc:mysql://localhost:3306/order_db?useUnicode=true
spring.shardingsphere.datasource.m1.username = root
spring.shardingsphere.datasource.m1.password = 12311
# 指定 t_order 表的数据分布情况,配置数据节点(t_order 映射到 t_order_1 或者 t_order_2)
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = m1.t_order_$->{1..2}
# 指定 t_order 表的主键生成策略为 SNOWFLAKE(雪花算法)
spring.shardingsphere.sharding.tables.t_order.key-generator.column = order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
# 指定 t_order 表的分片策略,分片策略包括分片键和分片算法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = order_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{order_id % 2 + 1}
# 打开 sql 输出日志
spring.shardingsphere.props.sql.show = true
swagger.enable = true
logging.level.root = info
logging.level.org.springframework.web = info
logging.level.djh.it.dbsharding = debug
logging.level.druid.sql = debug
三、Sharding-JDBC 入门程序(水平分表)-插入订单
1、在 sharding_jdbc_simple 子工程(子模块)中,创建 dao 接口类 OrderDao.java
/**
* D:\Java\java-test\idea\dbsharding\sharding_jdbc_simple\src\main\java\djh\it\dbsharding\simple\dao\OrderDao.java
*
* 2024-5-28 创建 dao 接口类 OrderDao.java
*/
package djh.it.dbsharding.simple.dao;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.springframework.stereotype.Component;
import java.math.BigDecimal;
@Mapper
@Component
public interface OrderDao {
@Insert("insert into t_order(price, user_id, status) values(#{price}, #{userId}, #{status})")
int insertOrder(@Param("price") BigDecimal price, @Param("userId")Long userId, @Param("status")String status);
}
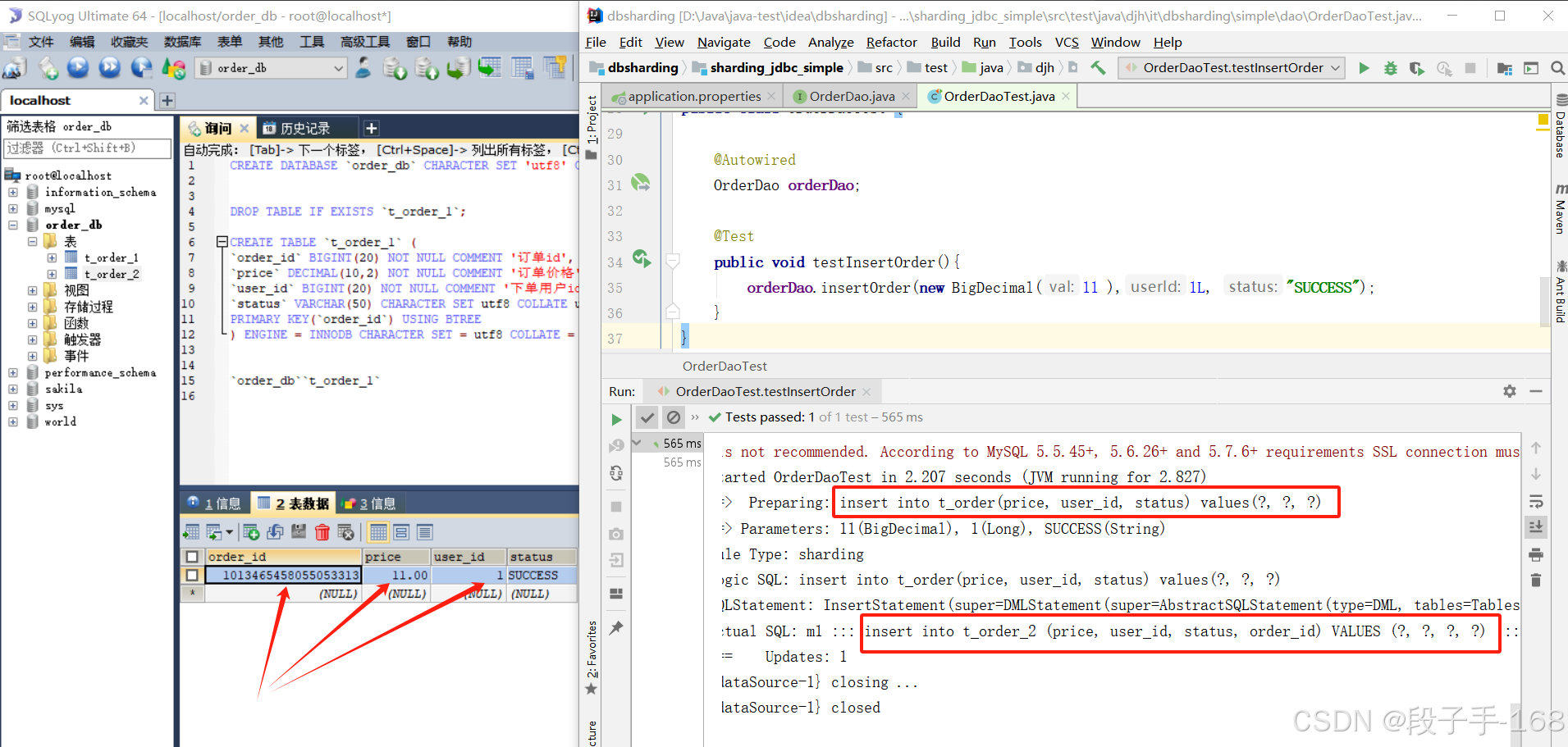
2、在 sharding_jdbc_simple 子工程(子模块)中,创建 接口 OrderDao 的测试类 testInsertOrder.java 进行测试
/**
* dbsharding\sharding_jdbc_simple\src\test\java\djh\it\dbsharding\simple\dao\OrderDaoTest.java
*
* 2024-6-28 创建 接口 OrderDao 的测试类 OrderDaoTest.java 进行测试
*
* 快速生成 接口 OrderDao 类的测试类:
* 1)右键 接口 OrderDao 选择 【Generate...】
* 2)选择【Test..】
* 3)Testing library : JUnit4
* Class name : OrderDaoTest
* SUPERCLASS : 空
* Destination package : djh.it.dbsharding.simple.dao
* 4)点击 OK。
*/
package djh.it.dbsharding.simple.dao;
import djh.it.dbsharding.simple.ShardingJdbcSimpleBootstrap;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.math.BigDecimal;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {ShardingJdbcSimpleBootstrap.class})
public class OrderDaoTest {
@Autowired
OrderDao orderDao;
@Test
public void testInsertOrder(){
//orderDao.insertOrder(new BigDecimal(11 ),1L, "SUCCESS");
for(int i=1; i<20; i++){
orderDao.insertOrder(new BigDecimal(i ),1L, "success2");
}
}
}
四、Sharding-JDBC 入门程序(水平分表)-查询订单
1、在 sharding_jdbc_simple 子工程(子模块)中,修改 dao 接口类 OrderDao.java 添加 查询订单的方法。
/**
* D:\Java\java-test\idea\dbsharding\sharding_jdbc_simple\src\main\java\djh\it\dbsharding\simple\dao\OrderDao.java
*
* 2024-5-28 创建 dao 接口类 OrderDao.java
*/
package djh.it.dbsharding.simple.dao;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.springframework.stereotype.Component;
import java.math.BigDecimal;
import java.util.List;
import java.util.Map;
@Mapper
@Component
public interface OrderDao {
//查询数据:根据订单ID ( SQL 语句:SELECT * FROM t_order_1 WHERE order_id IN (1013467489922711552, 1013467489960460288); )
@Select( "<script>" +
"select" +
" * " +
" from t_order t " +
" where t.order_id in " +
" <foreach collection=' orderIds' open='(' separator=',' close=')' item='id'>" +
" #{id} " +
" </foreach>" +
"</script>" )
List<Map> selectOrderByIds(@Param("orderIds") List<Long> orderIds);
//插入数据
@Insert("insert into t_order(price, user_id, status) values(#{price}, #{userId}, #{status})")
int insertOrder(@Param("price") BigDecimal price, @Param("userId")Long userId, @Param("status")String status);
}
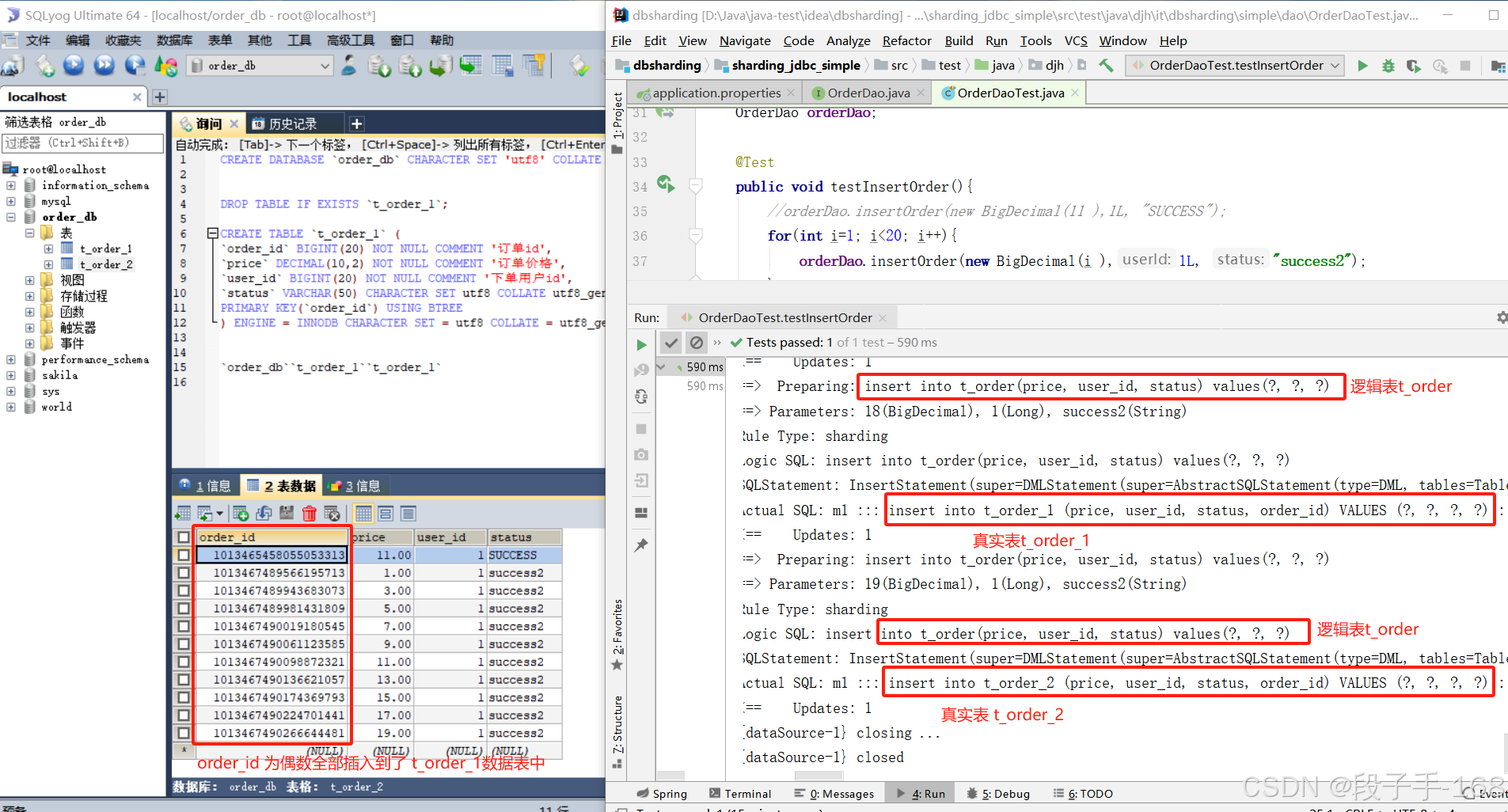
2、在 sharding_jdbc_simple 子工程(子模块)中,修改 接口 OrderDao 的测试类 testInsertOrder.java 添加 查询订单的方法。进行测试
/**
* dbsharding\sharding_jdbc_simple\src\test\java\djh\it\dbsharding\simple\dao\OrderDaoTest.java
*
* 2024-6-28 创建 接口 OrderDao 的测试类 OrderDaoTest.java 进行测试
*
* 快速生成 接口 OrderDao 类的测试类:
* 1)右键 接口 OrderDao 选择 【Generate...】
* 2)选择【Test..】
* 3)Testing library : JUnit4
* Class name : OrderDaoTest
* SUPERCLASS : 空
* Destination package : djh.it.dbsharding.simple.dao
* 4)点击 OK。
*/
package djh.it.dbsharding.simple.dao;
import djh.it.dbsharding.simple.ShardingJdbcSimpleBootstrap;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@RunWith(SpringRunner.class)
@SpringBootTest(classes = {ShardingJdbcSimpleBootstrap.class})
public class OrderDaoTest {
@Autowired
OrderDao orderDao;
@Test
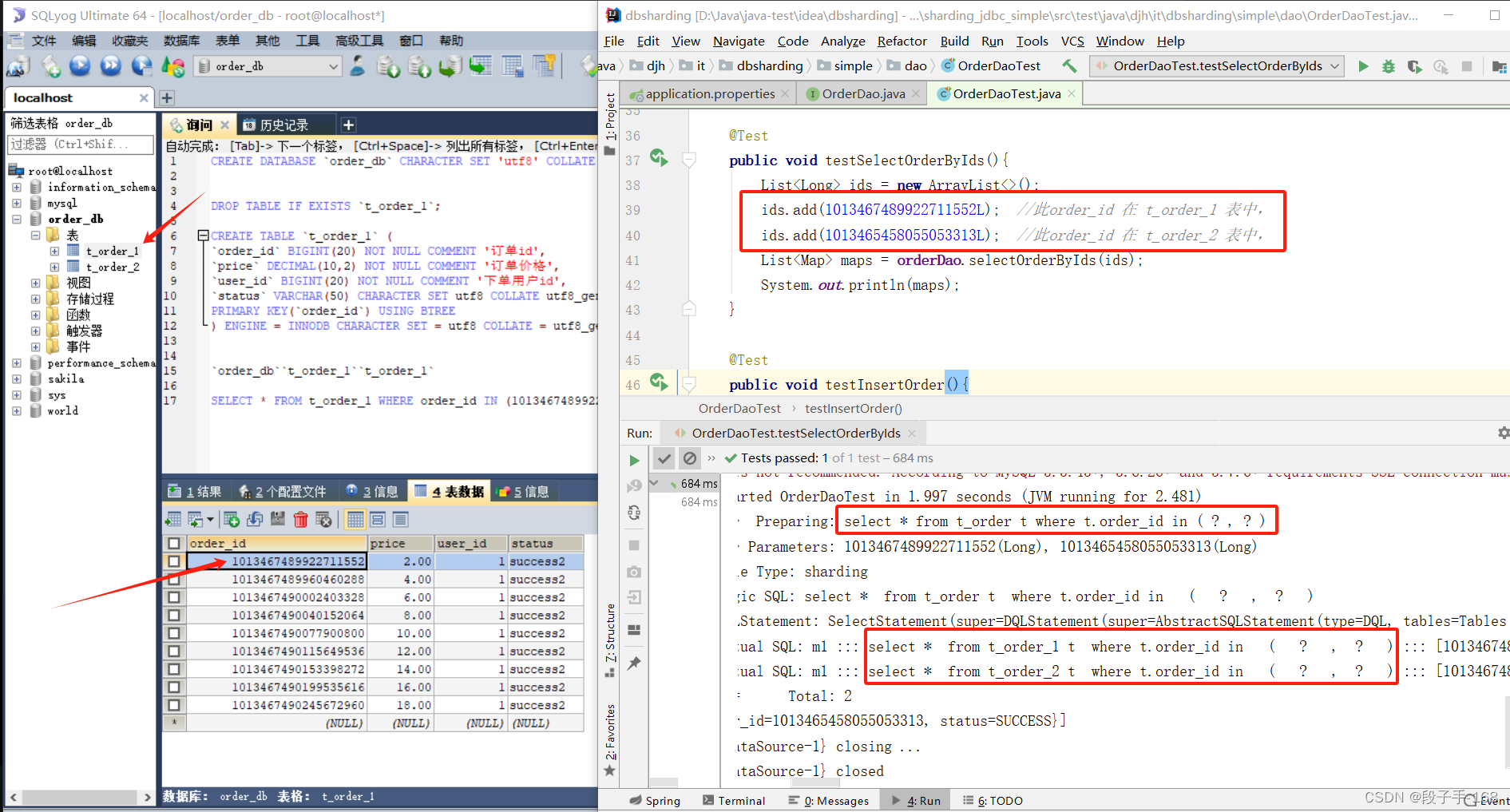
public void testSelectOrderByIds(){
List<Long> ids = new ArrayList<>();
ids.add(1013467489922711552L); //此order_id 在 t_order_1 表中,
ids.add(1013465458055053313L); //此order_id 在 t_order_2 表中,
List<Map> maps = orderDao.selectOrderByIds(ids);
System.out.println(maps);
}
@Test
public void testInsertOrder(){
//orderDao.insertOrder(new BigDecimal(11 ),1L, "SUCCESS");
for(int i=1; i<20; i++){
orderDao.insertOrder(new BigDecimal(i ),1L, "success2");
}
}
}
五、Sharding-JDBC 入门程序(水平分表)-执行流程分析
1、执行流程分析
通过日志分析,Sharding-JDBC 在拿到用户要执行的sql之后干了哪些事儿:
- (1) 解析 sql,获取片键值,在本例中是 order id。
- (2) sharding-JDBC 通过规则配置。 t_order_$->{order_id%2+1},知道了当 order_id 为偶数时,应该往 t_order_1 表插数据,为奇数时,往 t_order_2 插数据。
- (3) 于是 Sharding-JDBC 根据 order_id 的值改写 sql 语句,改写后的 SQL 语句是真实所要执行的SQL语句。
- (4) 执行改写后的真实 sql 语句
- (5) 将所有真正执行 sql 的结果进行汇总合并,返回。
2、总结:Sharding-JDBC 根据分片策略(分片键 + 分片算法),改写 SQL 语句,执行真实 SQL 语句。
上一节关联链接请点击
# Sharding-JDBC从入门到精通(2)- Sharding-JDBC 介绍