C++进阶
- 一、细节
- 1.cout与输出缓冲区
- 2.constexpr
- 3.NULL和nullptr是不同的类型
- 4.关于inline
- 5.函数杂合用法
- 6.const char*、char const*、char * const
- 7.进程地址空间,所谓静态区常量区不准
- 8.位运算
- 9.多态
- 9.1 内存切片
- 9.2 转型
- 9.3 构造函数和析构函数里是静态绑定
- 9.4 dynamic_cast的跨类转换与向下转换,以及利用typeid调试多态
- 9.5 类的成员函数的函数指针语法
- 9.6 类中的虚函数表以及内存破坏
一、细节
1.cout与输出缓冲区
输出缓冲区是内存中的一块区域,用于临时存储将要输出的数据。这种缓冲机制有助于提高性能,因为直接进行I/O操作(如写入控制台)通常比操作内存慢得多。
缓冲区的刷新(flush)是将缓冲区中的内容实际写到输出设备(如控制台)上的过程。在以下情况下,缓冲区会被刷新:
- 缓冲区满了。
- 程序正常结束时。
- 调用特定的刷新函数(如
flush)。 - 输出流遇到某些特殊字符(如
\n和endl)。
\n 和 endl:
\n是换行符,用于在输出中插入一个换行。它不会立即刷新缓冲区,只是将换行符添加到缓冲区中。endl是一个操控符,它不仅会在输出中插入一个换行,还会强制刷新缓冲区。
2.constexpr
constexpr 是C++11引入的关键字,用于在编译时计算常量表达式(constant expressions)(避免运行时进行计算,提高程序性能)。它可以用于变量、函数和构造函数,帮助提高程序的性能和安全性。
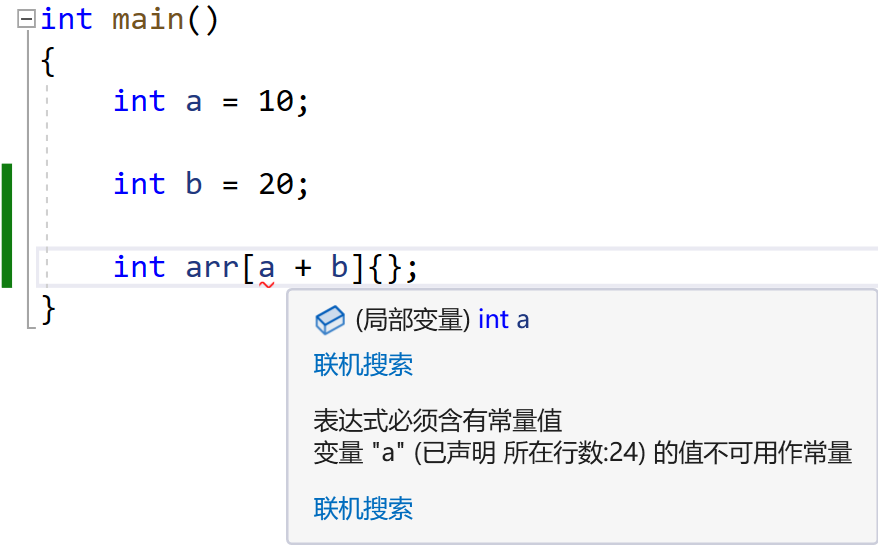

constexpr 函数是可以在编译时求值的函数,这要求函数的所有操作都必须是常量表达式,并且函数体内不能包含任何可能导致运行时执行的操作。constexpr 函数可以用于编译时和运行时计算。


constexpr 构造函数允许类对象在编译时创建。这要求类的所有成员变量都必须是常量表达式,且构造函数本身不能进行任何运行时操作。
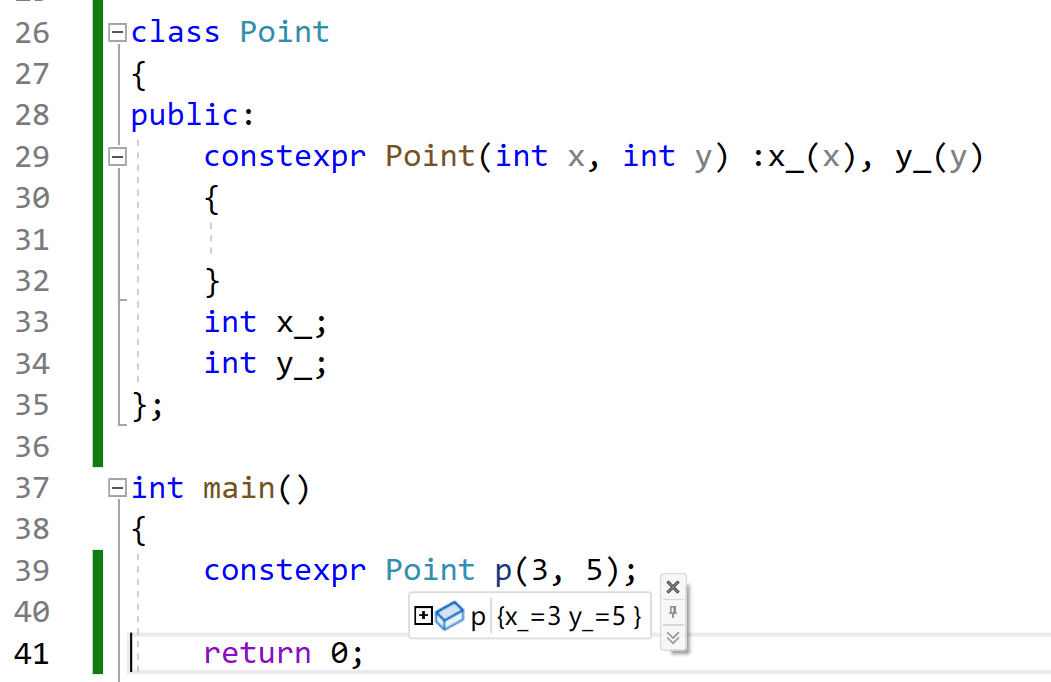
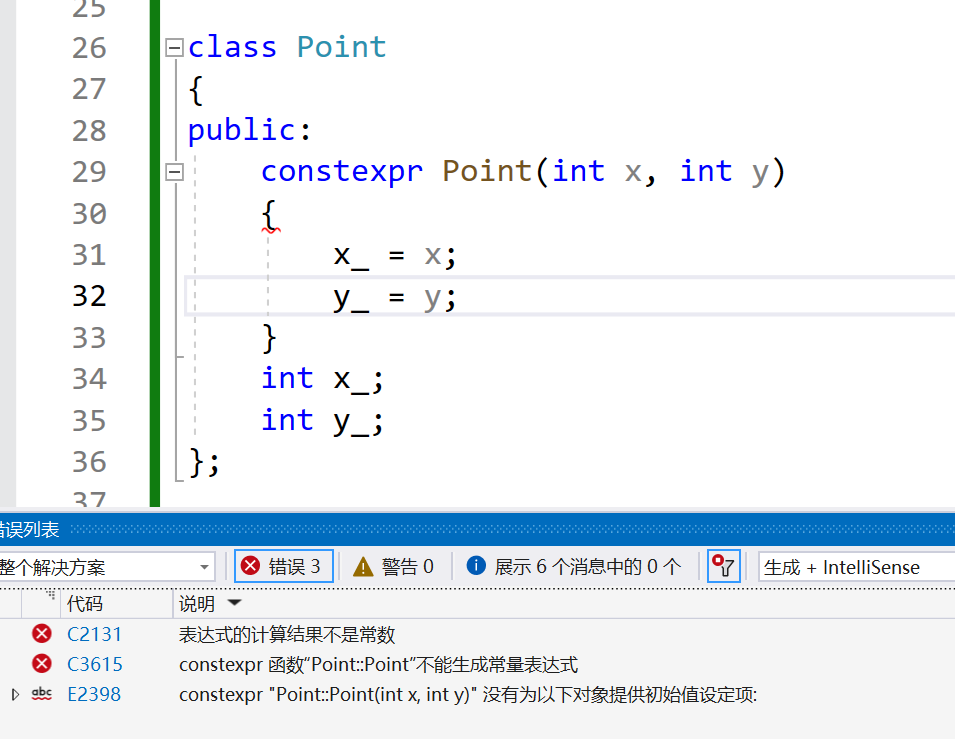
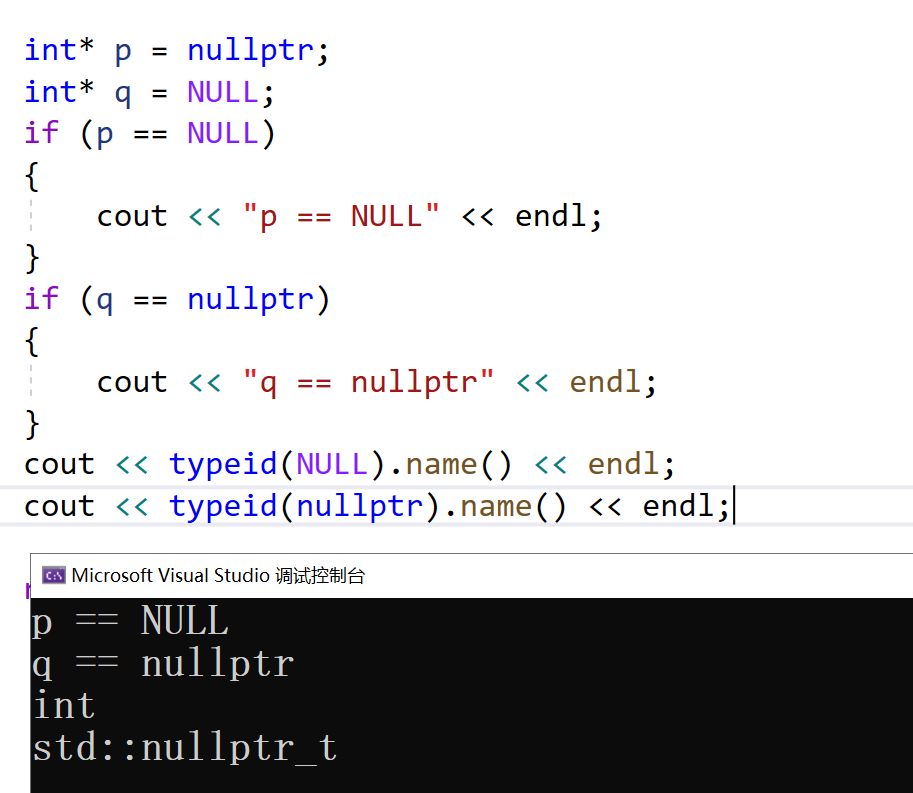
3.NULL和nullptr是不同的类型
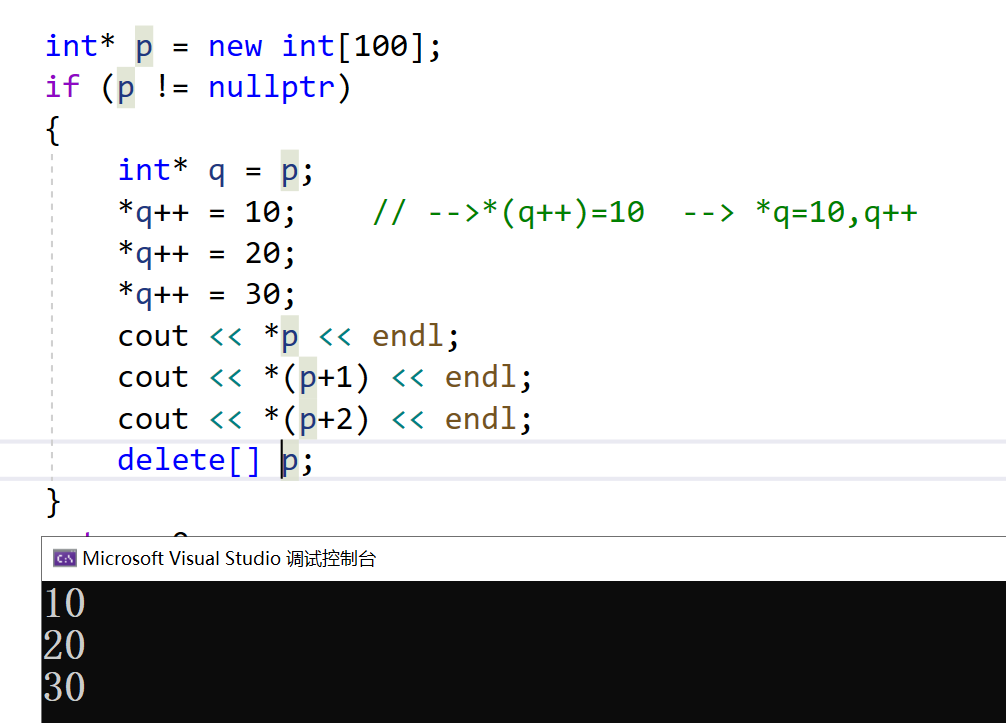
虽然用NULL和nullptr赋值的指针可以相互比较,但是他们是不同的类型,在C++中用nullptr来给指针赋初值,因为NULL实际是整型数0。
4.关于inline
首先看一个例子,假设有一个这样的头文件,有防卫式声明,被不同的源文件包含。
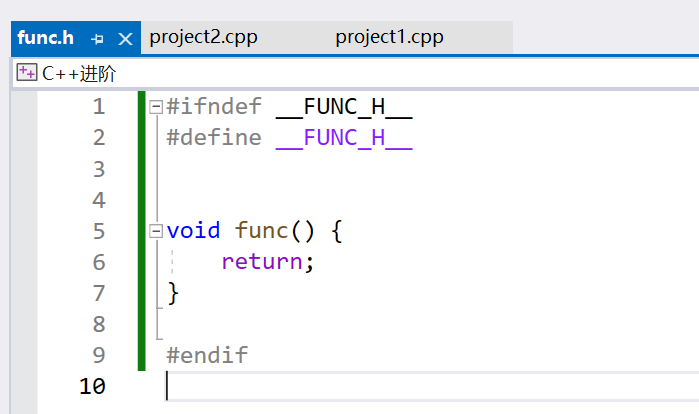
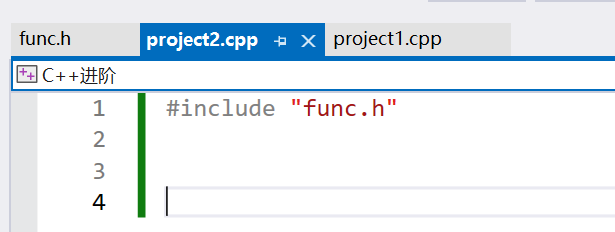
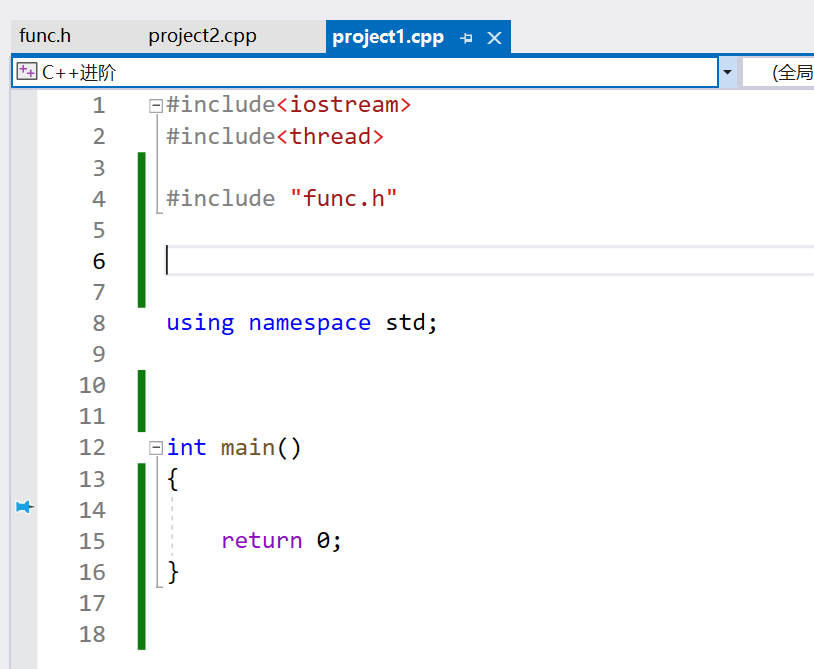
编译显示func重定义。
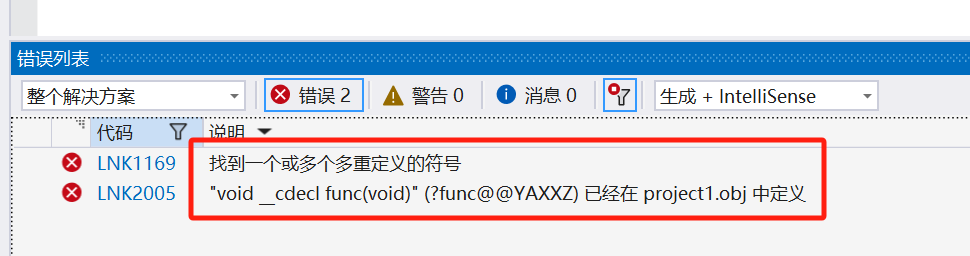
当 project1.cpp 和 project2.cpp 分别包含 func.h 时,每个编译单元(translation unit)都会包含 func 函数的定义。因此,在链接阶段(linking phase),链接器会发现有多个相同的 func 定义,从而导致重定义错误。因此,我们都是将函数的声明放在头文件中,定义放在源文件中。
如果在函数前加inline呢?
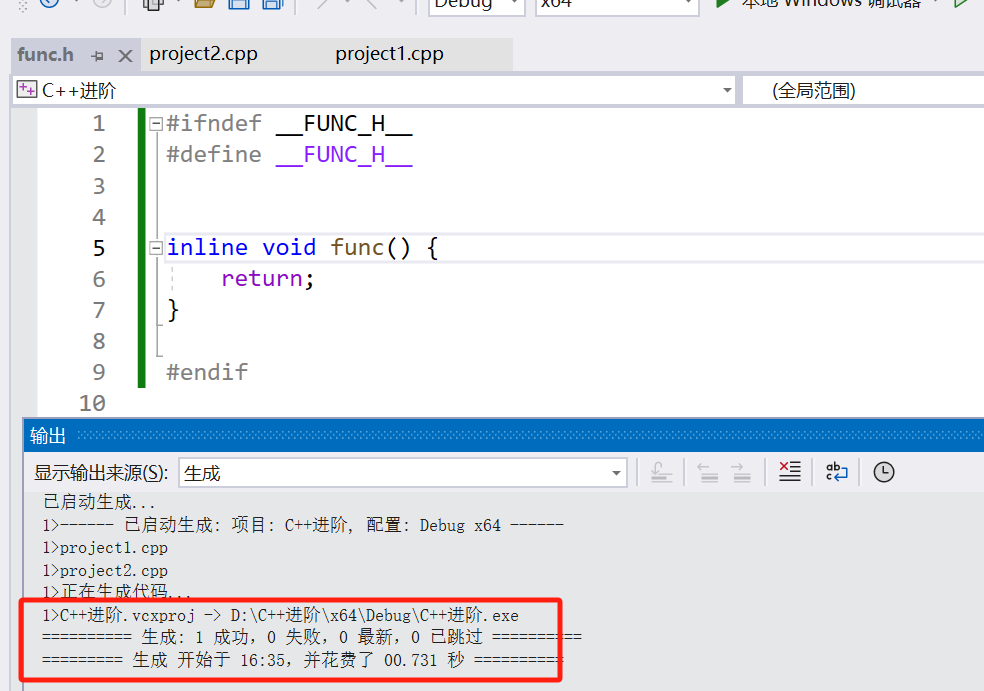
inline关键字提示编译器将函数的定义插入到调用点,而不是生成一个单独的函数调用。尽管如此,编译器并不总是会内联展开函数,它只是将其作为一个建议。- 更重要的是,
inline允许在多个编译单元中定义相同的函数,而不会引起重定义错误。这是因为 C++ 允许内联函数在多个编译单元中有相同的定义,并会在链接时进行特殊处理以避免重定义错误。 - **内联函数的定义必须放在头文件中。**这是因为内联函数需要在每个使用它的编译单元(translation unit)中可见,以便编译器能够在调用点进行展开或者至少知道该函数的定义。
5.函数杂合用法
- 函数返回类型是void,表示函数不返回任何类型。但是我们可以让一个返回类型是void的函数作为另一个返回类型是void的函数的返回值。

- 函数返回引用的情况。
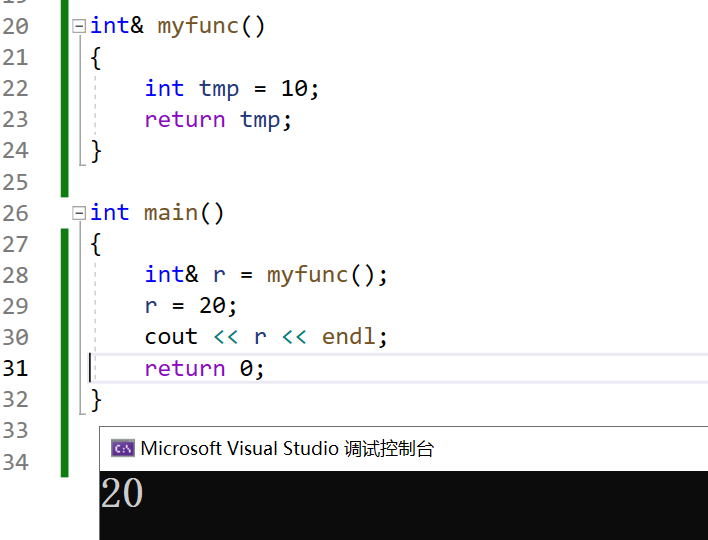
返回局部变量的引用,往一个不属于你的地址写了数据,虽然编译成功并且运行了,但是如果程序有地方用到这块内存空间,就会造成程序崩溃。
但是编译器对引用做了特殊处理,如果返回类型是引用,但是我们用普通类型去接受函数返回值,那么函数返回的就是值而不是引用。此时就相当于用10这个值赋给了变量a,然后a又将自身的值修改为20。
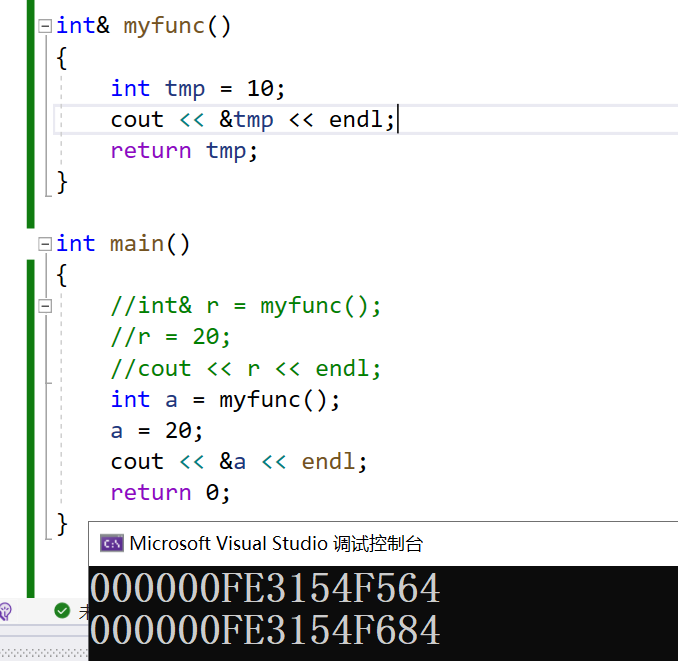
- 如果一个函数我们不调用的话,可以只有声明,不需要实现。
6.const char*、char const*、char * const

这也就引申出我们为什么会在某些函数形参中加入const修饰。

顶层 const 和底层 const:
- 顶层
const(Top-level const):- 修饰指针本身,使指针本身为常量,即指针的地址不能改变。
- 示例:
int* const p中的const是顶层const,表示p是一个常量指针。
- 底层
const(Low-level const):- 修饰指针指向的对象,使指针指向的对象为常量,即不能通过指针修改指向的数据。
- 示例:
const int* p中的const是底层const,表示*p是常量。
7.进程地址空间,所谓静态区常量区不准
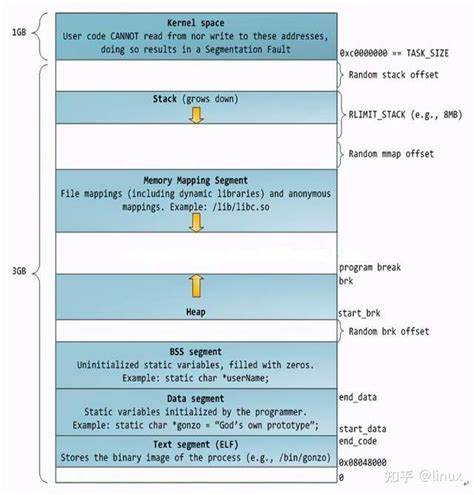
- Text Segment(文本段或代码段):这部分内存存放的是程序的机器代码,即编译后的程序。这部分是只读的,主要是为了防止程序代码被意外修改。
- Data Segment(数据段):存放初始化的全局变量和静态变量。这部分内存在程序开始执行时由编译器初始化,并在程序运行期间持续存在。
- BSS Segment(未初始化数据段):用于存放程序中未初始化的全局变量和静态变量。在程序启动时,操作系统会将此段内存初始化为零。
- Memory Mapping Segment(内存映射段):这部分内存通常用于映射外设的内存空间或实现文件映射。共享库。
- Stack(栈):用于存放函数的局部变量、函数参数和返回地址等。每当调用一个函数时,其相关信息就会被推送到栈上,函数返回时信息又会被弹出。栈具有后进先出的特性。
- Kernel Space(内核空间):这部分内存是操作系统保留的,用于运行内核代码和处理器内核模式下的操作。用户程序通常不能直接访问内核空间。
8.位运算
#include<bitset>
输出二进制内容:
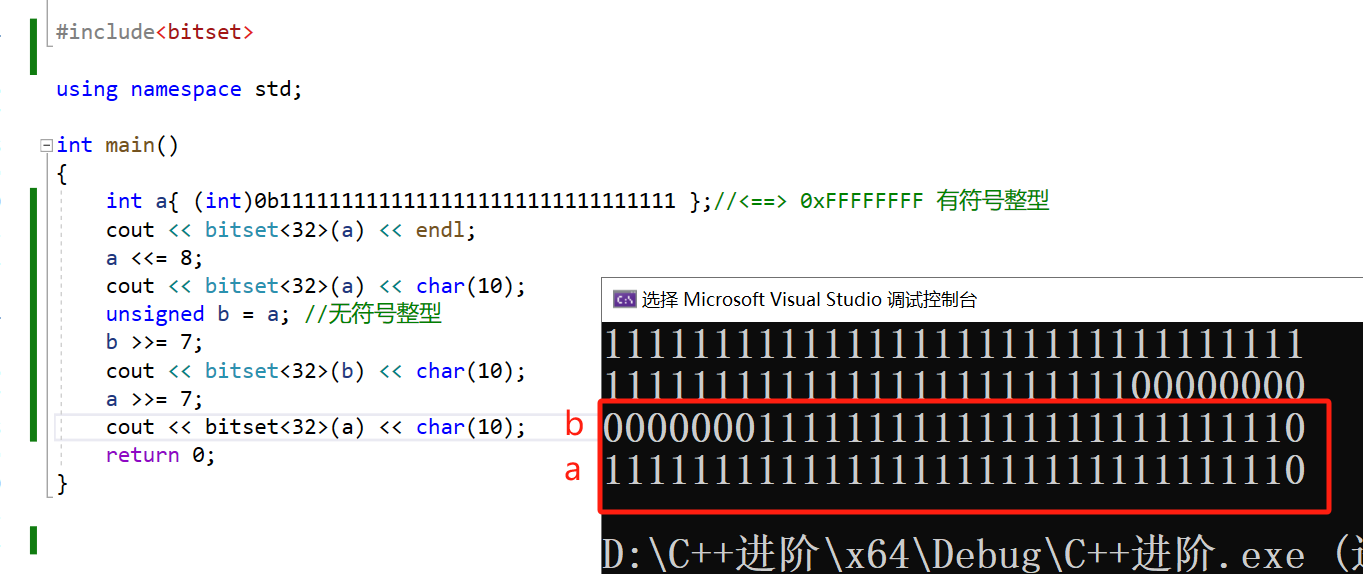


异或运算的特点:
异或运算(XOR),表示为 ^,有几个关键特性:
- 一个数与自身异或的结果是0,即
x ^ x = 0。 - 一个数与0异或的结果是数本身,即
x ^ 0 = x。 - 异或运算满足交换律和结合律,即
a ^ b = b ^ a和a ^ (b ^ c) = (a ^ b) ^ c。

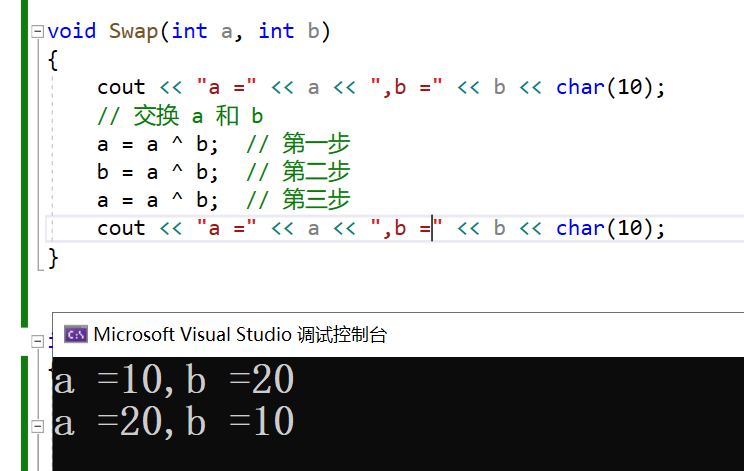
第一步: a = a ^ b; 这一步中,我们将 a 和 b 进行异或运算,并将结果存储在 a 中。现在 a 存储的是原始 a 和 b 异或的结果,我们可以称之为 a'。此时,a 是 a 和 b 的信息混合体。
第二步: b = a ^ b; 在这一步中,新的 a (即 a') 与原始的 b 进行异或运算。根据异或的性质,由于 a' 包含了原始 a 和 b 的信息,再与 b 异或相当于 b 与自己的信息抵消,留下了原始的 a。因此,这一步的结果是将原始的 a 值赋给了 b。
第三步: a = a ^ b; 最后一步,现在的 a (即 a') 与现在的 b(即原始的 a)进行异或运算。由于 a' 是原始的 a 和 b 的异或结果,与原始的 a 异或会抵消 a 的部分,留下原始的 b。因此,这一步的结果是将原始的 b 值赋给了 a。
9.多态
9.1 内存切片
在面向对象编程中,多态允许我们通过基类指针或引用来调用派生类的方法。内存切片(Object Slicing)是多态中的一个问题,它发生在一个派生类对象被赋值给一个基类对象时。
内存切片现象解释:
当派生类对象通过值(而非指针或引用)赋值给基类对象时,派生类对象的额外属性(即派生类特有的成员)会被“切掉”,只剩下基类部分的成员数据被复制到基类对象中。这种现象就称为“内存切片”。
为什么会发生内存切片:
这是因为当通过值赋值时,赋值操作符只能处理目标对象(基类对象)类型的数据大小。由于派生类可能包含额外的成员变量或方法,这些无法通过基类对象来存储,因此在赋值过程中这部分额外的信息就会丢失。
内存切片可能导致以下问题:
- 数据丢失:派生类特有的数据成员在赋值过程中丢失,这可能导致程序逻辑错误。
- 多态失效:由于派生类的特定行为(通过重写的方法实现)被切掉,使用基类对象调用方法时,不能表现出预期的多态行为。
假设有一个基类 Base 和一个从 Base 派生的类 Derived,Derived 类添加了一些新的成员变量和方法。
class Base {
public:
int base_var;
virtual void print() { cout << "Base class" << endl; }
};
class Derived : public Base {
public:
int derived_var;
void print() override { cout << "Derived class" << endl; }
};
如果我们创建一个 Derived 类的对象,并试图将其赋值给一个 Base 类的对象,就会发生内存切片:
Derived d;
d.derived_var = 10;
Base b = d; // 这里发生内存切片,derived_var 信息丢失
b.print(); // 输出 "Base class"
在这个例子中,derived_var 的值不会存在于 b 中,因为 b 只是一个 Base 类型的对象,不包含 Derived 类的任何额外信息。
如何避免内存切片?
- 使用指针或引用来维护多态行为,这样可以保证对象的完整性不被破坏。
- 避免将派生类对象赋值给基类对象。
9.2 转型
向上转型 (Upcasting):
向上转型是将派生类的指针或引用转换为基类的指针或引用。这种转换是安全的,因为每个派生类对象都是一个基类对象,所以基类的部分是派生类对象的一部分。这种转换通常在多态中自动进行。
向下转型 (Downcasting):
向下转型是将基类的指针或引用转换为派生类的指针或引用。这种转换是不安全的,因为不是所有基类对象都是派生类对象。向下转型常常需要程序员确保这种转换是合理的,并且通常需要使用强制类型转换,如 dynamic_cast。
9.3 构造函数和析构函数里是静态绑定

构造函数总是静态绑定的。这意味着构造函数的调用不是基于对象的运行时类型,而是基于对象声明时的类型。构造函数的静态绑定确保了在创建派生类对象时,可以从基类到派生类正确地、按顺序初始化对象的各部分。
析构函数默认是静态绑定的,但如果将析构函数声明为虚函数,则会变成动态绑定。声明析构函数为虚函数是管理继承关系中的对象时的一个重要实践,因为它确保了当通过基类指针删除派生类对象时,对象的资源可以被适当地释放。
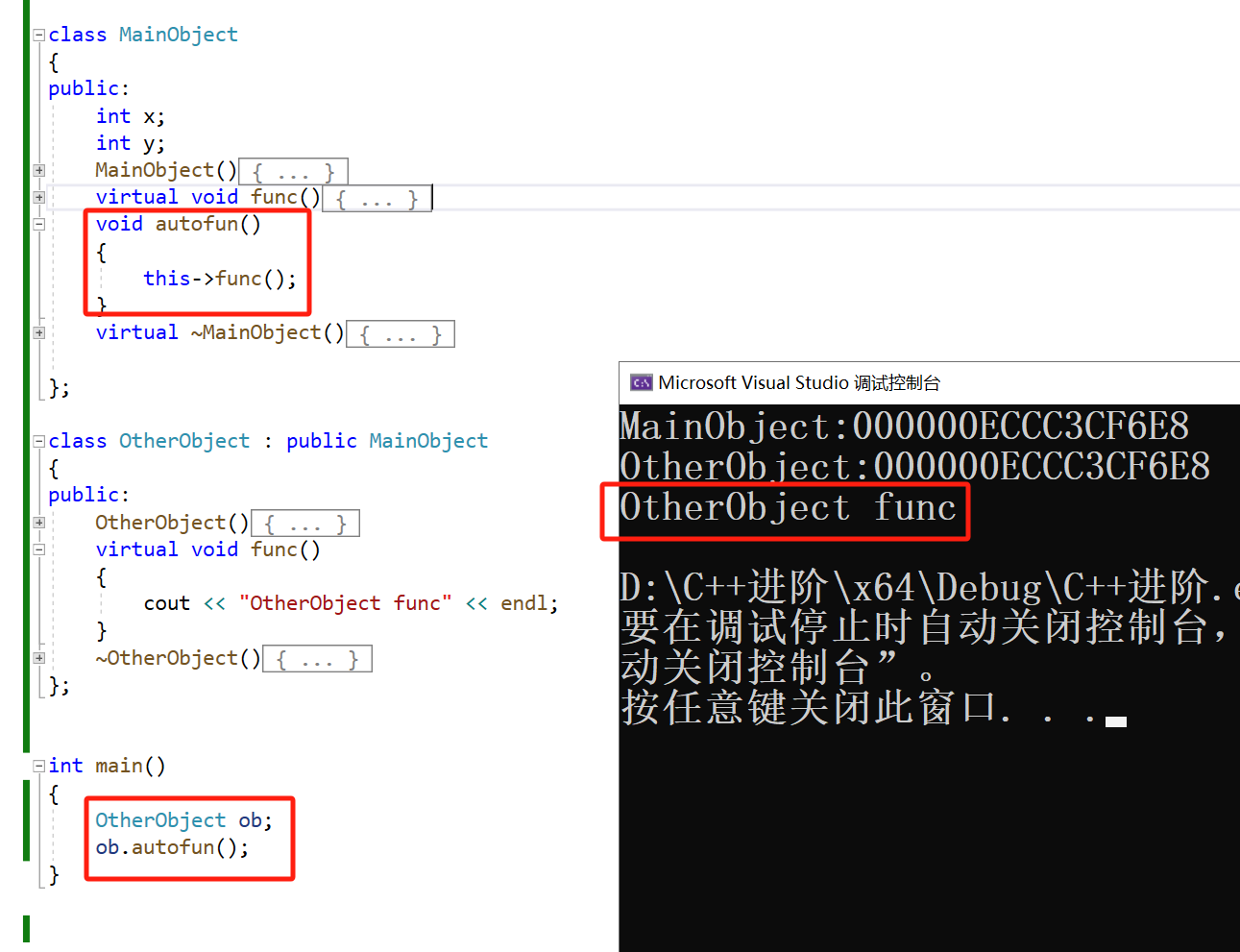
autofun 是 MainObject 类中的一个非虚成员函数,它内部调用了 func() 方法。
尽管 autofun() 定义在基类 MainObject 中,但是在它内部调用的 func() 方法是虚拟的(virtual)。这意味着调用的 func() 方法将会是对象 ob 运行时类型的版本,即 OtherObject 的 func()。
由于 func() 方法在 MainObject 类中被声明为虚函数,因此 C++ 的动态绑定机制确保了在通过 ob.autofun() 调用时,实际上运行的是 OtherObject 的 func() 方法。即使调用发生在基类 MainObject 的上下文中,多态性质保证了派生类方法的调用。
9.4 dynamic_cast的跨类转换与向下转换,以及利用typeid调试多态
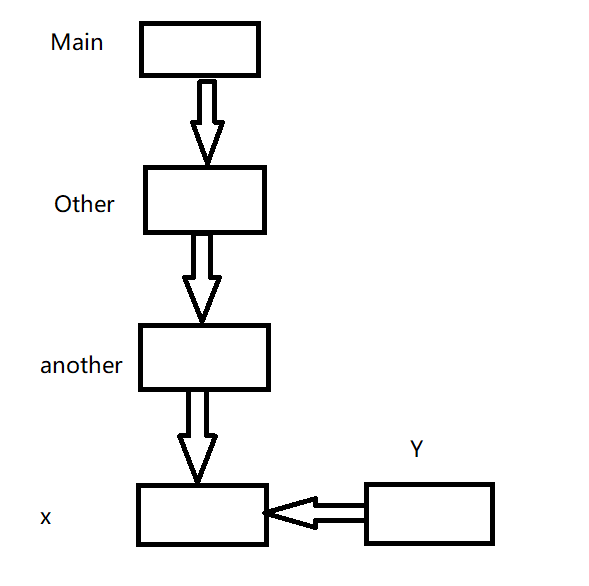
假设继承关系如下,我们想要从类Main转换到类Y。
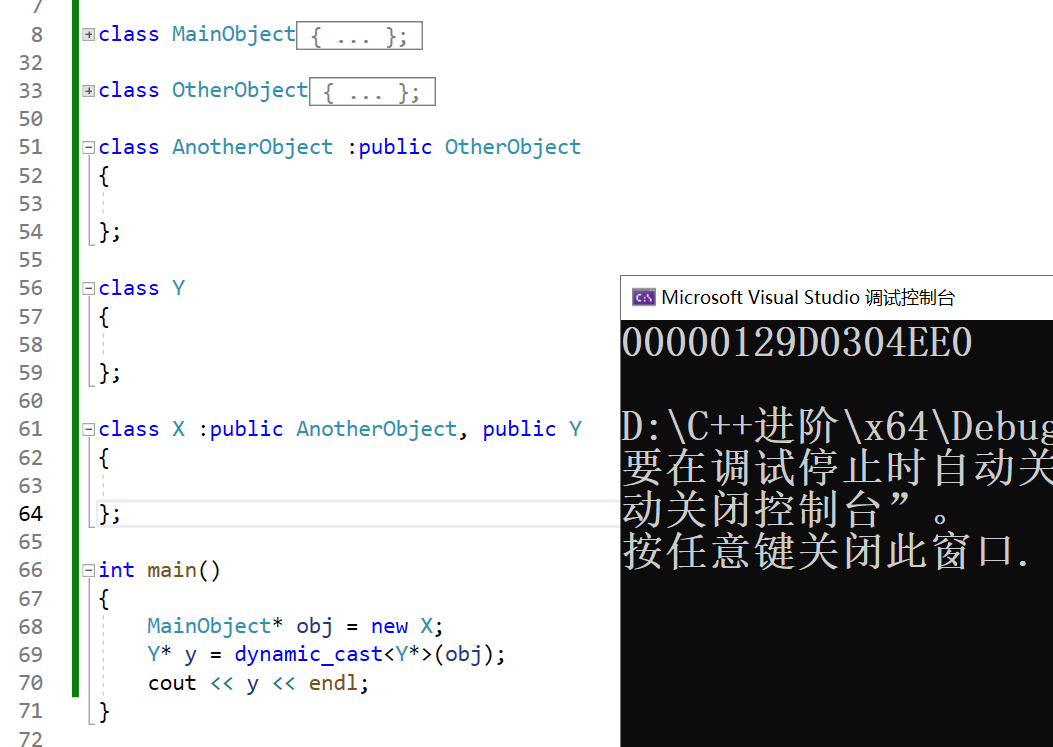
此时,跨类转换是成功的,因为y不是空指针。
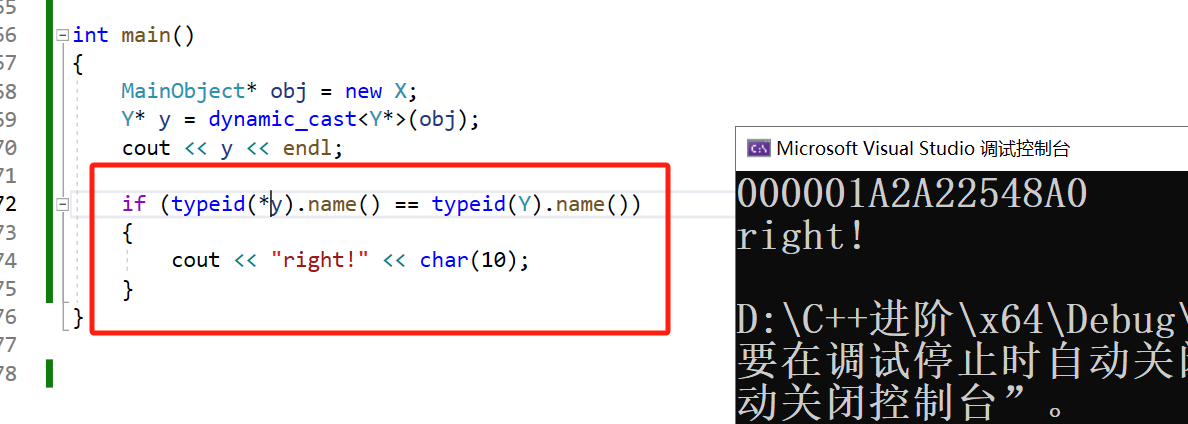
如果项目有很多的继承关系嵌套,那么我们跟踪调试的时候很难确定此时的指针究竟是哪一个类,因此可以用typeid打印类的信息,注意这时候指针需要解引用,否则等号右边需要比较Y*。
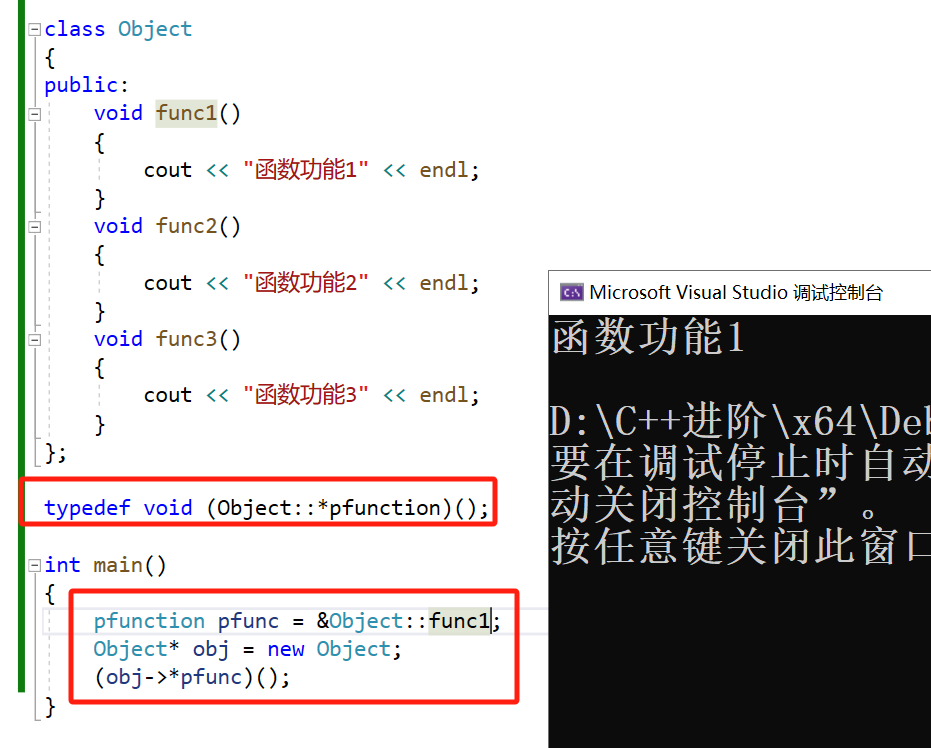
9.5 类的成员函数的函数指针语法
成员函数不同于普通函数,它需要一个对象上下文来访问成员变量和其他成员函数,这就是为什么需要使用特殊的语法来处理类成员函数指针(this指针)。
使用对象指针和成员函数指针调用。
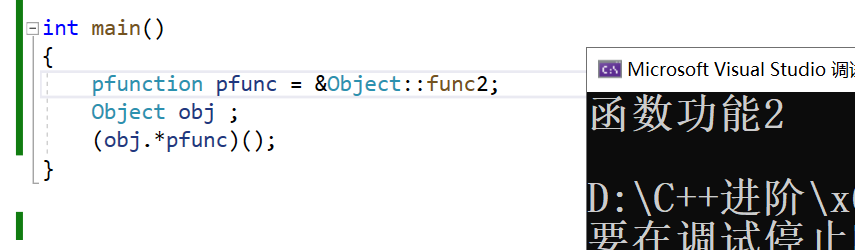
使用对象实例和成员函数指针调用。
9.6 类中的虚函数表以及内存破坏
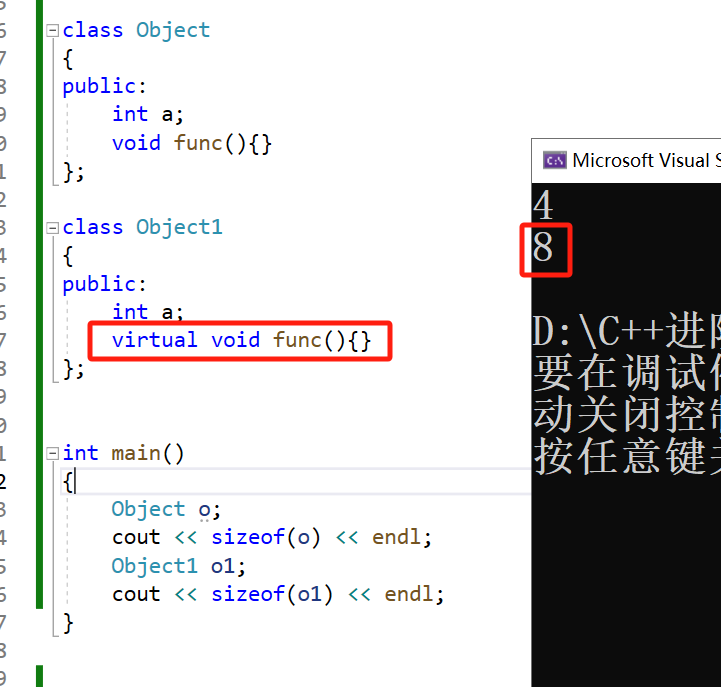
在C++中,虚函数是通过虚函数表(vtable)实现的,这是一个存储指向虚函数地址的指针数组。每个含有虚函数的类都有一个虚函数表。当类的对象被创建时,对象内部会包含一个指向其虚函数表的指针(通常称为vptr)。通过这种机制,当调用对象的虚函数时,实际上是通过虚函数表来动态确定要调用的函数。
我们可以看到,对于有虚函数的类,类的对象的大小多出了4个字节。
这里我们用多态的方式调用一下虚函数,查看一下反汇编。
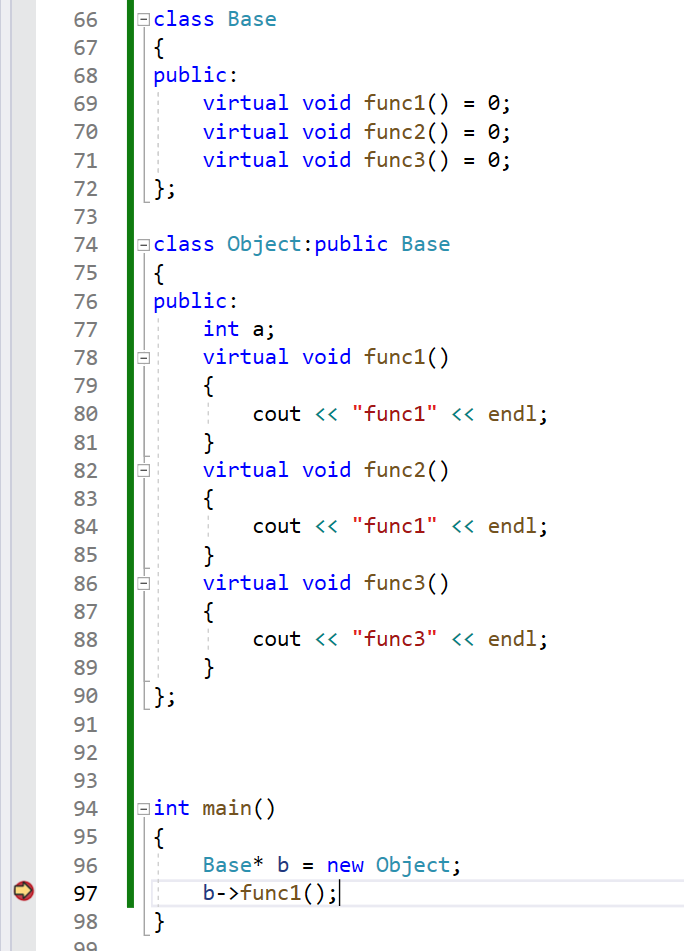
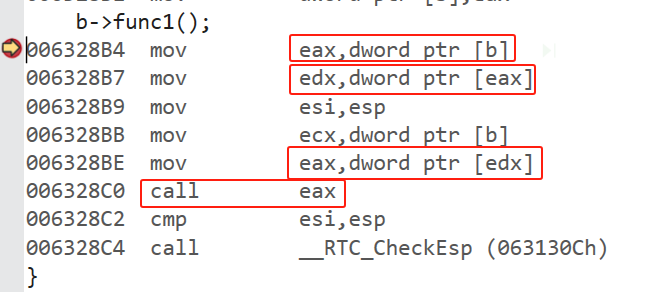
可以看见,对于第一个函数,这里用b指向的地址来进行函数调用。
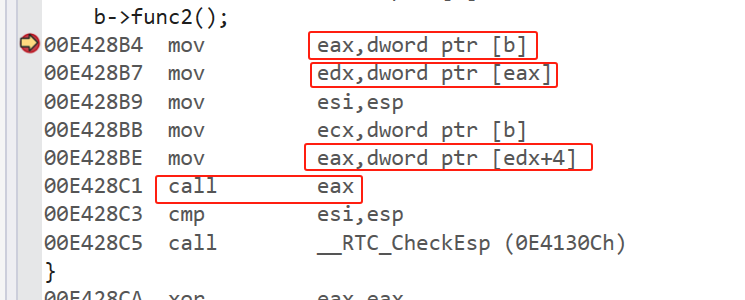
对于第二个函数,在第一个函数的地址上偏移了四位。
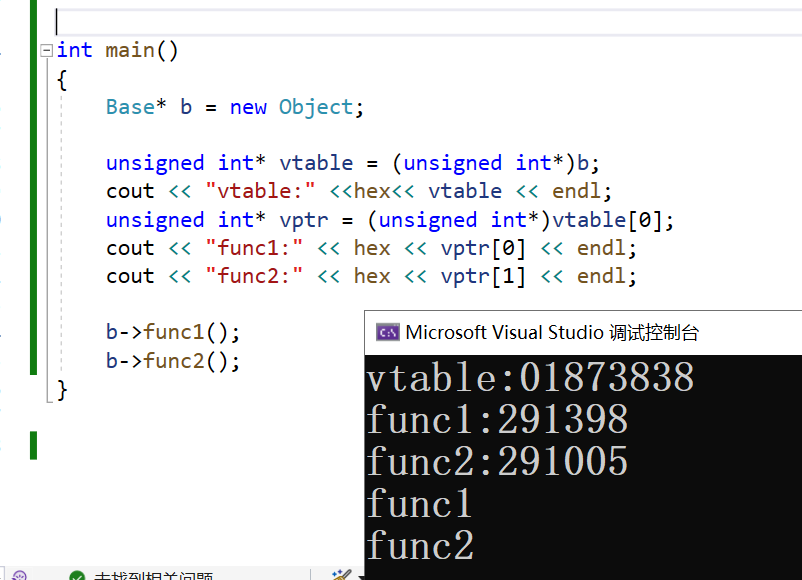
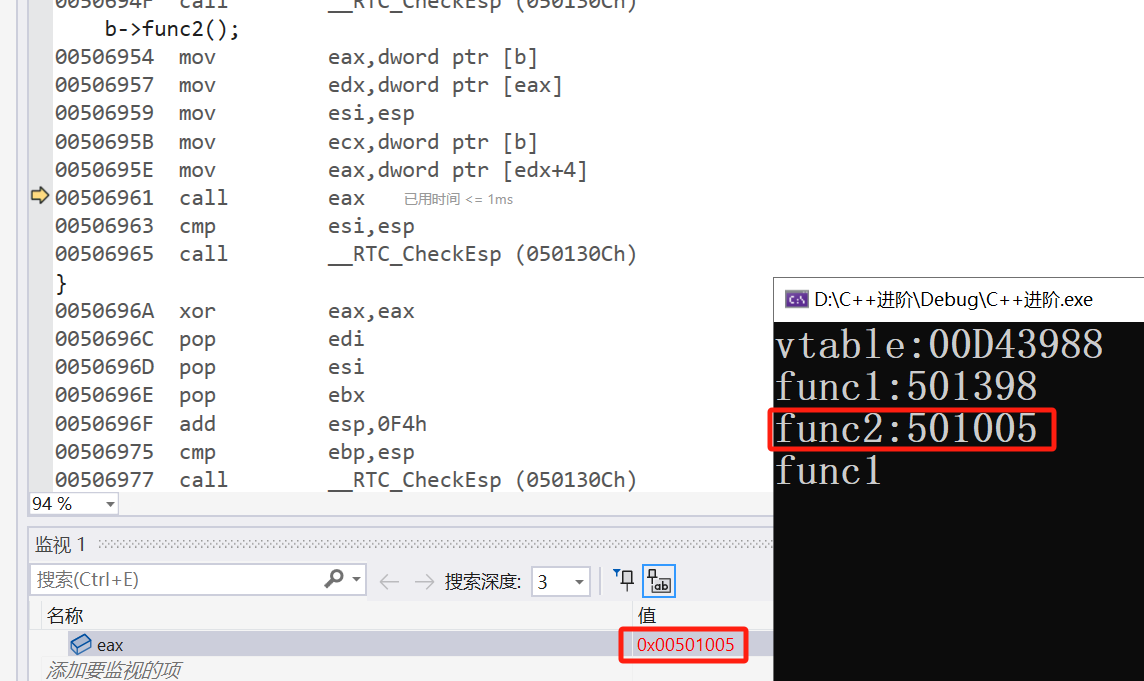
我们打印一下虚函数表的地址,以及表中前两个函数的地址。
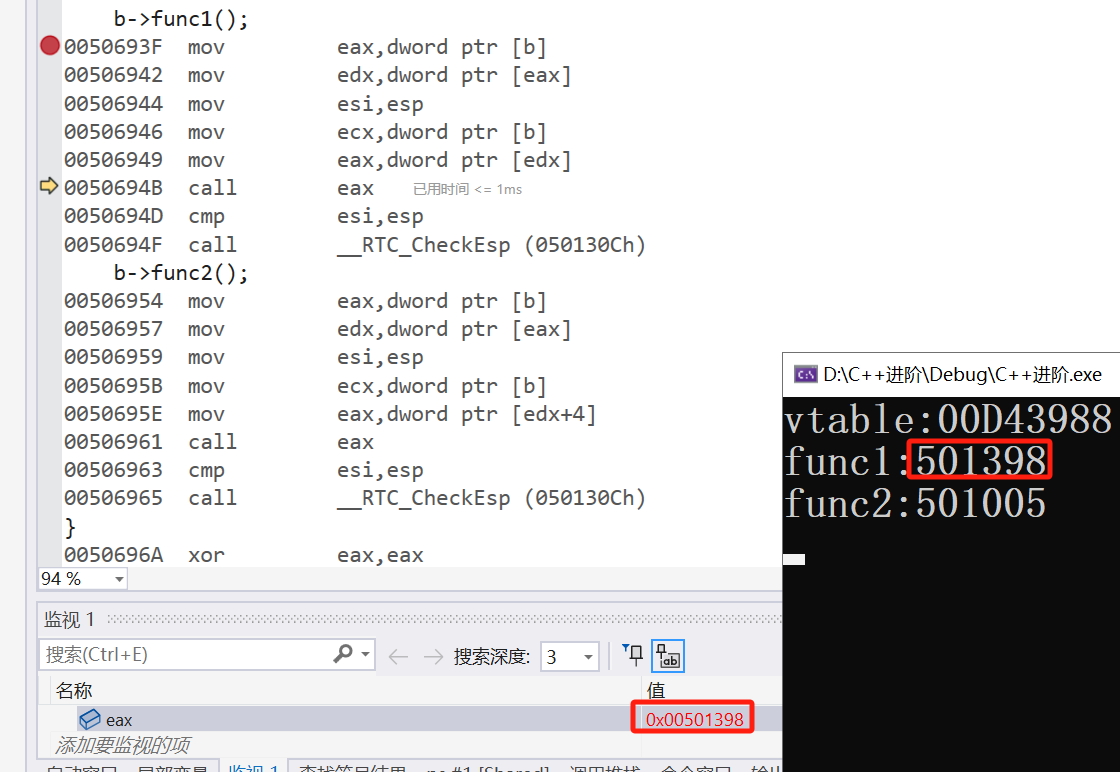
通过汇编查看一下地址是否正确。

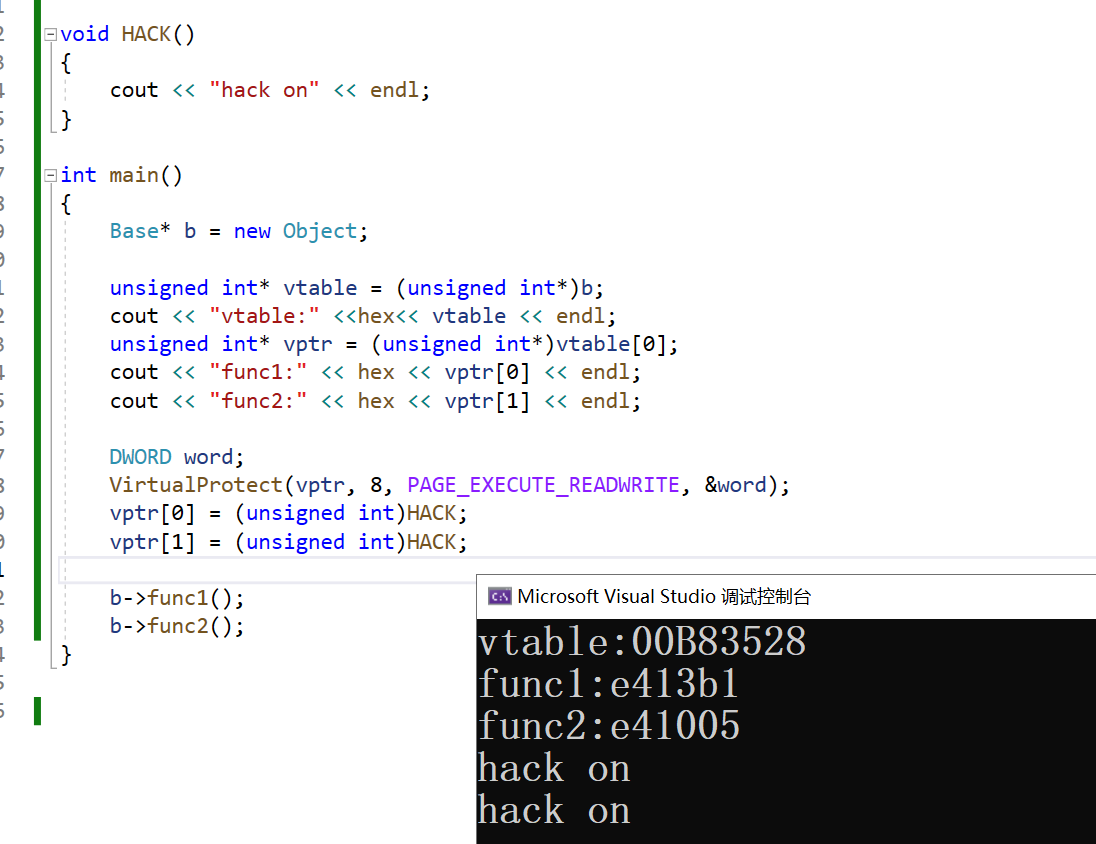
虚函数表的性质:
同一个类的多个实例都指向同一个虚函数表。
通过修改虚函数表的数据可以实现劫持。
只有通过指针访问函数才会调用虚函数表(多态的动态绑定)。
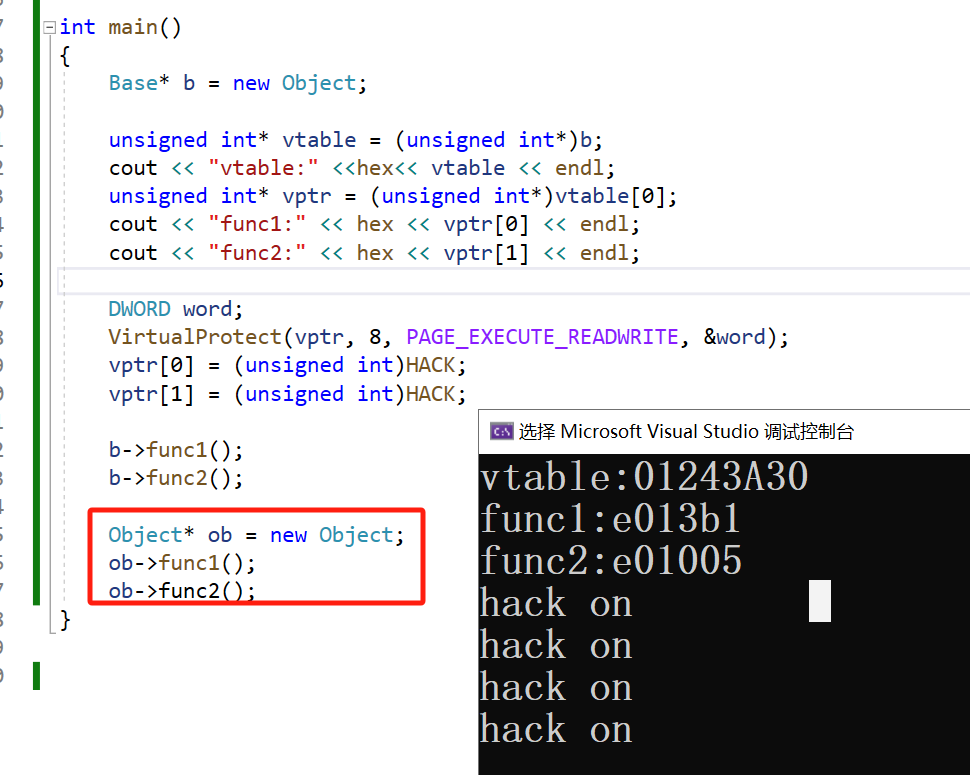
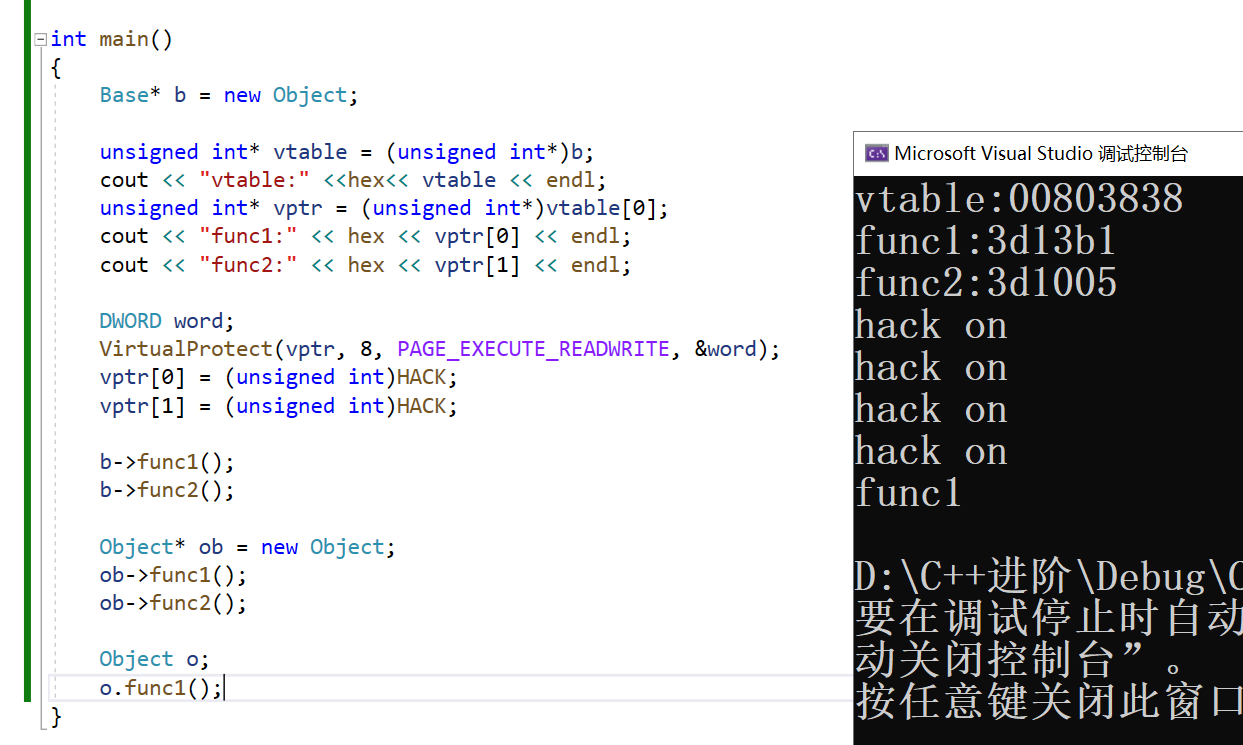
定义类的非指针对象,不涉及多态,没有虚函数表,因此调用是正常的。
…(img-3KUljj2O-1719664931428)]
[外链图片转存中…(img-XKAKTYTQ-1719664931428)]
虚函数表的性质:
同一个类的多个实例都指向同一个虚函数表。
通过修改虚函数表的数据可以实现劫持。
只有通过指针访问函数才会调用虚函数表(多态的动态绑定)。
[外链图片转存中…(img-q3WjviHA-1719664931428)]
[外链图片转存中…(img-sL7z2gm5-1719664931428)]
定义类的非指针对象,不涉及多态,没有虚函数表,因此调用是正常的。












![[知识点篇]《计算机组成原理》之计算机系统概述](https://img-blog.csdnimg.cn/direct/29dcb49998074fbdaec6cbfef7272d26.png)