mongodb基本常用命令(只要掌握所有实验内容就没问题)
上机必考,笔试试卷可能考:
1.1 数据库的操作
1.1.1 选择和创建数据库
(1)use dbname 如果数据库不存在则自动创建,例如,以下语句创建spitdb数据库:
(2)show dbs 或者 show databases #查看有权限查看的所有的数据库命令
(3)db #查看当前正在使用的数据库命令
show dbs 结果如下:
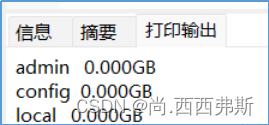
有默认的三个库(选填?)
admin:从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
创建数据库
use 数据库名—创建数据库名
说明如果没有数据库则创建,如果有则替换数据库。
当我们创建好数据库好后,使用show dbs发现无创建的数据库,原因跟mongodb的存储机制有关系,当我们创建数据库时,存放到内存中没有进行持久化存储,所以看不到,如果要看到,需要创建数据库中的集合。
数据库命名的规则,不能是关键字,特色字符,<64字节
1.1.2 数据库的删除
db.dropDatabase()
1.2 集合操作
1.2.1 集合显式创建
db.createCollection(name) #创建集合
show collections /show tables查询集合

1.2.2 集合的隐式创建
当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合。
详见下面文档的插入章节。
通常我们使用隐式创建文档即可
db.集合名.insert({id:1,name:forlan});

【注意集合的命名规范】(选择?)
不能是空字符串
不能含有 \0字符(空字符),这个字符表示集合名的结尾
不能以 "system."开头,这是为系统集合保留的前缀
不能含有保留字符。另外千万不要在名字里出现$
5.在test01数据库中隐式创建集合
集合名 键值对
stu1 Id:202201090,name:李四,depart:大数据
scho1 name:复旦大学,address:上海
dog1 breed:牧羊犬,color:白色
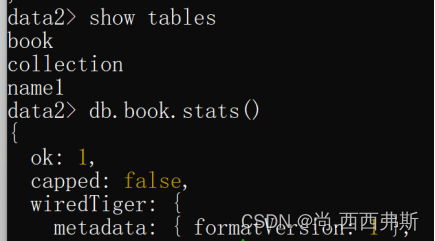
1.2.3查看集合
show tables 或 show collections
db.collections.stats()
1.2.3 集合的删除
db.集合.drop()

返回true表示删除成功
1.3 文档的CRUD
文档(document)的数据结构和 JSON 基本一样。
所有存储在集合中的数据都是 BSON 格式。
BSON是一种二进制序列化文档格式,它基于 JSON 并进行了扩展,以支持更多的数据类型。
mongo _id的生成规则: 时间戳+机器码+PID+计数器(选择?)
1.3.1 文档的插入
语法:
db.collection.insert():单文档插入
db.collection.insertMany():多文档插入
db.collection.insert():单、多文档插入
变量插入文档 db.collection.insertMany(变量)
(1)单个文档插入
使用insert() 方法向集合中插入文档
document document or array 要插入到集合中的文档或文档数组。((json格式)
writeConcern document 选择的性能和可靠性级别(了解)
ordered boolean 可选。如果为真,则按顺序插入数组中的文档,如果其中一个文档出现错误,MongoDB将返回而不处理数组中的其余文档。如果为假,则执行无序插入,如果其中一个文档出现错误,则继续处理数组中的主文档。在版本2.6+中默认为true
示例:
代码:
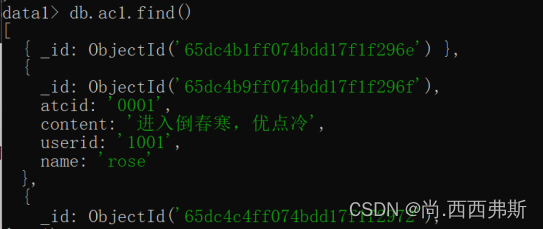
db.ac1.insert(
{“atcid”:“0001”,“content”:“进入倒春寒,优点冷”,“userid”:“1001”,“name”:“rose”}
)
插入ac1的集合,如果该集合不存在则创建它
//结果如下

//查询集合
db.ac1.find()
查看表中的哪些集合 show collections
(2)多个文档的插入
db.collection.insertMany(
[
{k1:v1,k2:v2},
{k1:v1,k2:v2}
]
)
集合 文档值
data1 “_id”:“1”,“articleid”:“100001”,“content”:“我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。”
“userid”:“1002”,“nickname”:“相忘于江湖”,“createdatetime”:new Date(“2019-08-05T22:08:15.522Z”),“likenum”:NumberInt(1000),“state”:“1”
“_id”:“2”,“articleid”:“100001”,“content”:“我夏天空腹喝凉开水,冬天喝温开水”,“userid”:“1005”,“nickname”:“伊人憔悴”,“createdatetime”:new Date(“2019-08-05T23:58:51.485Z”),“likenum”:NumberInt(888),“state”:“1”
“_id”:“3”,“articleid”:“100001”,“content”:“我一直喝凉开水,冬天夏天都喝。”,“userid”:“1004”,“nickname”:“杰克船长”,“createdatetime”:new Date(“2019-08-06T01:05:06.321Z”),“likenum”:NumberInt(666),“state”:“1”
db.data1.insertMany([
{“_id”:“1”,“articleid”:“100001”,“content”:“我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我他。”,“userid”:“1002”,“nickname”:“相忘于江湖”,“createdatetime”:new Date(“2019-08-05T22:08:15.522Z”),“likenum”:NumberInt(1000),“state”:“1”},
{“_id”:“2”,“articleid”:“100001”,“content”:“我夏天空腹喝凉开水,冬天喝温开水”,“userid”:“1005”,“nickname”:“伊人憔悴”,“createdatetime”:new Date(“2019-08-05T23:58:51.485Z”),“likenum”:NumberInt(888),“state”:“1”},
{“_id”:“3”,“articleid”:“100001”,“content”:“我一直喝凉开水,冬天夏天都喝。”,“userid”:“1004”,“nickname”:“杰克船长”,“createdatetime”:new Date(“2019-08-06T01:05:06.321Z”),“likenum”:NumberInt(666),“state”:“1”},
{“_id”:“4”,“articleid”:“100001”,“content”:“专家说不能空腹吃饭,影响健康。”,“userid”:“1003”,“nickname”:“凯撒”,“createdatetime”:new Date(“2019-08-06T08:18:35.288Z”),“likenum”:NumberInt(2000),“state”:“1”},
{“_id”:“5”,“articleid”:“100001”,“content”:“研究表明,刚烧开的水千万不能喝,因为烫嘴。”,“userid”:“1003”,“nickname”:“凯撒”,“createdatetime”:new Date(“2019-08-06T11:01:02.521Z”),“likenum”:NumberInt(3000),“state”:“1”}
])
(3)单、多个文档的插入
db.collection.insert([{k1:v1,k2:v2}…])
【课堂练习】5分钟
1.单行插入文本
集合名 数据
city cityname:重庆,population:3213万
School name:厦门大学,area:9700多亩
2.多个文档的插入
集合名 数据
city “_id”:“1”,“cityname”:“重庆”,“population”:3213
“_id”:“2”,“cityname”:“上海”,“population”:2475
“_id”:“3”,“cityname”:“北京”,“population”:2184
“_id”:“4”,“cityname”:“成都”,“population”:2126
“_id”:“5”,“cityname”:“广州”,“population”:1873
“_id”:“6”,“cityname”:“深圳”,“population”:1756
“_id”:“7”,“cityname”:“武汉”,“population”:1373
“_id”:“8”,“cityname”:“天津”,“population”:1363
“_id”:“9”,“cityname”:“西安”,“population”:1299
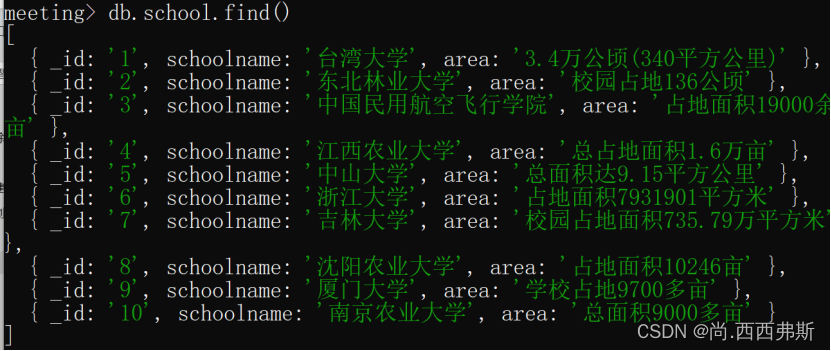
School 占地校园排行榜
“_id”:“1”,“schoolname”:“台湾大学”,“area”:“3.4万公顷(340平方公里)”
“_id”:“2”,“schoolname”:“东北林业大学”,“area”:“校园占地136公顷”
“_id”:“3”,“schoolname”:“中国民用航空飞行学院”,“area”:“占地面积19000余亩”
“_id”:“4”,“schoolname”:“江西农业大学”,“area”:“总占地面积1.6万亩”
“_id”:“5”,“schoolname”:“中山大学”,“area”:“总面积达9.15平方公里”
“_id”:“6”,“schoolname”:“浙江大学”,“area”:“占地面积7931901平方米”
“_id”:“7”,“schoolname”:“吉林大学”,“area”:“校园占地面积735.79万平方米”
“_id”:“8”,“schoolname”:“沈阳农业大学”,“area”:“占地面积10246亩”
“_id”:“9”,“schoolname”:“厦门大学”,“area”:“学校占地9700多亩”
“_id”:“10”,“schoolname”:“南京农业大学”,“area”:“总面积9000多亩”
(4)使用变量插入文档
准备文档文件如1.txt
citydata=([
{“_id”:“1”,“cityname”:“重庆”,“population”:3213},
{“_id”:“2”,“cityname”:“上海”,“population”:2475},
{“_id”:“3”,“cityname”:“北京”,“population”:2184},
{“_id”:“4”,“cityname”:“成都”,“population”:2126},
{“_id”:“5”,“cityname”:“广州”,“population”:1873},
{“_id”:“6”,“cityname”:“深圳”,“population”:1756},
{“_id”:“7”,“cityname”:“武汉”,“population”:1373},
{“_id”:“8”,“cityname”:“天津”,“population”:1363},
{“_id”:“9”,“cityname”:“西安”,“population”:1299}
])
doc=([
{“_id”:“1”,“schoolname”:“台湾大学”,“area”:“3.4万公顷(340平方公里)”},
{“_id”:“2”,“schoolname”:“东北林业大学”,“area”:“校园占地136公顷”},
{“_id”:“3”,“schoolname”:“中国民用航空飞行学院”,“area”:“占地面积19000余亩”},
])
ca=([{“_id”:“4”,“schoolname”:“江西农业大学”,“area”:“总占地面积1.6万亩”},
{“_id”:“5”,“schoolname”:“中山大学”,“area”:“总面积达9.15平方公里”},
{“_id”:“6”,“schoolname”:“浙江大学”,“area”:“占地面积7931901平方米”},
{“_id”:“7”,“schoolname”:“吉林大学”,“area”:“校园占地面积735.79万平方米”},
{“_id”:“8”,“schoolname”:“沈阳农业大学”,“area”:“占地面积10246亩”},
{“_id”:“9”,“schoolname”:“厦门大学”,“area”:“学校占地9700多亩”},
{“_id”:“10”,“schoolname”:“南京农业大学”,“area”:“总面积9000多亩”}
])
db.school.insertMany(doc)
1.3.2 文档的查询
1.3.2 文档的基本查询
db.comment.find() 或 db.comment.find({})
(1)查询集合的所有文档
db.comment.find()
(2)查询集合第一条文档
findOne()

这里你会发现每条文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,MongoDB会自动创建,其类型是ObjectID类型。(选择?)
如果我们在插入文档记录时指定该字段也可以,其类型可以是ObjectID类型,也可以是MongoDB支持的任意类型
(3)按条件的查询
如果我想按一定条件来查询,比如我想查询userid为1003的记录,怎么办?很简单!只 要在find()中添加参数即可,参数也是json格式,如下:
db.comment.find({userid:‘1003’})

如果你只需要返回符合条件的第一条数据,我们可以使用findOne命令来实现,语法和find一样。如:查询用户编号是1003的记录,但只最多返回符合条件的第一条记录:
(4)投影查询
db.comment.find({userid:“1003”},{userid:1,nickname:1})
如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段)。如:查询结果只显示 _id、userid、nickname :
db.comment.find({userid:“1003”},{userid:1,nickname:1})
(B)投影查询
db.collections.find({},{“name”:1}) //“_id”始终会被获取
db.collections.find({},{“name”:1,”_id”:0})//”_id”不会被获取

注:在_id字段为0的时候,其他字段可以写1;
在_id字段为1的时候,其他字段必须写1;
如果是除了_id字段以外的其他字段,必须同为1或者同为0
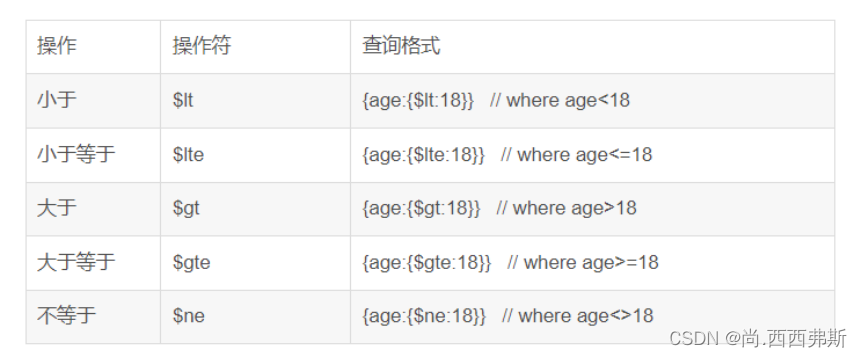
(5)比较查询
db.user.find({age:{$lt:30}})
//等同于 select * from user where age<30;
实例:创建集合
集合名 数据
city “_id”:“1”,“cityname”:“重庆”,“population”:3213
“_id”:“2”,“cityname”:“上海”,“population”:2475
“_id”:“3”,“cityname”:“北京”,“population”:2184
“_id”:“4”,“cityname”:“成都”,“population”:2126
“_id”:“5”,“cityname”:“广州”,“population”:1873
“_id”:“6”,“cityname”:“深圳”,“population”:1756
“_id”:“7”,“cityname”:“武汉”,“population”:1373
“_id”:“8”,“cityname”:“天津”,“population”:1363
“_id”:“9”,“cityname”:“西安”,“population”:1299
ci=([
{“_id”:“1”,“cityname”:“重庆”,“population”:3213},
{“_id”:“2”,“cityname”:“上海”,“population”:2475},
{“_id”:“3”,“cityname”:“北京”,“population”:2184},
{“_id”:“4”,“cityname”:“成都”,“population”:2126},
{“_id”:“5”,“cityname”:“广州”,“population”:1873},
{“_id”:“6”,“cityname”:“深圳”,“population”:1756},
{“_id”:“7”,“cityname”:“武汉”,“population”:1373},
{“_id”:“8”,“cityname”:“天津”,“population”:1363},
{“_id”:“9”,“cityname”:“西安”,“population”:1299}
])
①查询人口数大于3000万的城市
②查询人口数大于2000万的城市
③查询人数小于2000万的城市
④查询人口数在1500-2000万的城市
或者
(6)逻辑查询
and查询
db.user.find(
{$and:
[
{age:20,sex:0}
]
}
);
// 等同于 select * from user where age=20 and sex=0
或者缺省$and
db.user.find({age:20,sex:0})
(选择?填空?)
(7)or查询
db.user.find({
$ or:[
{age:{$lt:24}},
{sex:1}
]});
//等同于 select * from user where age<24 or sex=1
查mongo
查询school中吉林大学和台湾大学的信息
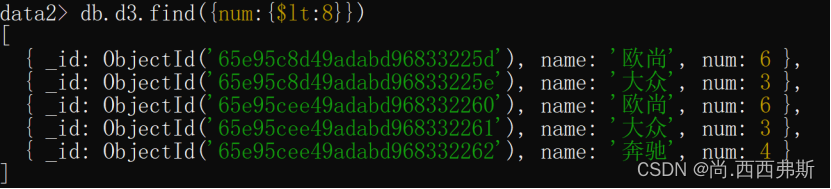
(8) in 和nin 查询
db.user.find({age:{$in:[18,19,20]}})
//等同于 select * from user where age in (18,19,20)
查询台湾大学,吉林大学,厦门大学
查询北京 南京 珠海的城市信息
(9)为空查询
db.user.find({name:{$exists:1}});不为空查询
db.school.find({area:{$exists:0}})查询为空的数据
(10)查询排序
db.collectins.find().sort({“age”:-1})
注:-1为逆序,1为顺序
按人口数量的升序排序
db.citys.find().sort({population:1})
按人口的降序排序
(12)分页查询
使用函数limit()和skip()来实现分页查询
db.collections.find().limit().skip() //跳过多少行查询多少行
①如查询前三条数据 limit(3)
db.citys.find().limit(3)
②查询从第3条到第6条的数据 skip(2).limit(4)
db.citys.find().limit(4).skip(2)
③查询人口数最多排名第3名的城市
db.citys.find().limit(1).skip(2).sort({population:-1})
查询人口数从高到低排名第3名-第8名的城市
db.city2.find().limit(6).skip(2).sort({population:-1})
(13)正则匹配
正则表达式用于模式匹配,基本上是用于在文档中搜索字符串中的模式。它是一种将模式与字符序列匹配的通用方法。$regex运算符用作正则表达式,用于在字符串中查找模式。
集合的数据为:
①某文档包含某字段的模糊查询:{ $regex:/xxx/ }
使用 sql 的写法select * from member where name like ‘%XXX%’
在mongodb中db.member.find({“name”:{ KaTeX parse error: Expected 'EOF', got '}' at position 13: regex:/XXX/ }̲}) 实例:查询城市名有京的城…regex:/^xxx/}
查询“上”开头的城市
db.citys.find({cityname:{$regex:/^上/}})
③查询以某字段为结尾的文档 {
r
e
g
e
x
:
/
X
X
X
regex:/XXX
regex:/XXX/}
db.member.find({“name”:{
r
e
g
e
x
:
/
X
X
X
regex:/XXX
regex:/XXX/}})
查询城市名最后一个字为“海”的城市
db.citys.find( { cityname: {
r
e
g
e
x
:
/
海
regex: /海
regex:/海/ } } )
④查询忽略大小写 {$regex:/XXX/i}
查询含有a的数据
db.citys.find( { cityname: { $regex: /a/i } } )
1.3.3 文档的更新
基本语法
db.collection.update(query, update, options)
//或
db.collection.update(
,
,
{
upsert: ,
multi: ,
writeConcern: ,
collation: ,
arrayFilters: [ , … ],
hint: <document|string> // Available starting in MongoDB 4.2
}
)
(1)局部修改
s
e
t
/
/
为了解决这个问题,我们需要使用修改器
set //为了解决这个问题,我们需要使用修改器
set//为了解决这个问题,我们需要使用修改器set来实现,
db.comment.update({_id:“2”},{$set:{likenum:NumberInt(889)}})
(2)批量的修改{multi:true}
//更新所有用户为 1003 的用户的昵称为 凯撒大帝
//默认只修改第一条数据
db.comment.update({userid:“1003”},{KaTeX parse error: Expected 'EOF', got '}' at position 21: …nickname:"凯撒2"}}̲) //修改所有符合条件的数据…set:{nickname:“凯撒大帝”}},{multi:true})
实例:修改所有石家庄城市为廊坊
db.citys.update({ cityname: “石家庄” }, { $set: { cityname: “廊坊” } }, { multi: true } )
实例:将城市名中包含 a (不区分大小写),修改为你好
db.citys.update({ cityname: { $regex: /a/i } }, { $set: { cityname: “你好” } }, { multi: true })
(3)列值增长的修改
i
n
c
(增加运算)
inc (增加运算)
inc(增加运算)mul(乘法运算)
//如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用 KaTeX parse error: Expected '}', got 'EOF' at end of input: …ate({_id:"3"},{inc:{likenum:NumberInt(1)}})
如:修改北京人口,在之前的数据上增加 500万
实例:重庆人口增加一倍$mul
实例:重庆人口减少3000万
(4)修改健名{KaTeX parse error: Expected 'EOF', got '}' at position 23: …{cityname:”重庆”}}̲ 实例:修改万州中cityna…rename:{cityname:“citynames”}})
(5)删除某个健名KaTeX parse error: Expected '}', got 'EOF' at end of input: …me:"舟山"}, ... {unset:{add:“”}
… )
db.citys.update( {cityname:“舟山”}, {$unset:{add:“”}} )
(6)采用 $ min,$max,修改当前值为给定的最小值或者最大值
如:修改重庆人口为给定的最小值
db.citys.update({ cityname: “重庆” }, { $min: { population: 1000 } } )
db.citys.update({ cityname: “重庆” }, { KaTeX parse error: Expected 'EOF', got '}' at position 27: …lation: 4000 } }̲ ) (7)ISODate()…set:{time:ISODate(“2021-01-01 10:10:10”)}})
1.3.4 文档的删除
(1)全部删除文档
db.comment.remove({})
(2)删除集合
db.集合名.drop()
删除整个集合,这个方法的效率更高
(3)删除_id=1的记录
db.comment.remove({_id:“1”})
如删除万州的城市
db.citys.remove({cityname:“万州”})
后面的应该不是上机考的内容(闭卷笔试选择、手写命令、和简答题)
2.1MongoDB索引
MongoDB是基于集合建立索引的,索引的目的是提高查询效率。
如果没有建立索引,当MongoDB读取数据时候,是要扫描集合中的所有文档,这种扫描的效率分层的低,尤其在处理大数据时,查询可能需要几十秒到几分钟时间,这种效率对互联网的应用来说是示范可怕的。
2.1.1索引的分类
按照索引包含的字段数量,可以分为单键索引和组合索引(或复合索引)。
按照索引字段的类型,可以分为主键索引和非主键索引。
按照索引节点与物理记录的对应方式来分,可以分为聚簇索引和非聚簇索引,其
中聚簇索引是指索引节点上直接包含了数据记录,而后者则仅仅包含一个指向数据记
录的指针。
2.1.2索引分类
按照索引包含的字段数量,可以分为单键索引和组合索引(或复合索引)。
按照索引字段的类型,可以分为主键索引和非主键索引。
按照索引节点与物理记录的对应方式来分,可以分为聚簇索引和非聚簇索引,其中聚簇索引是指索引节点上直接包含了数据记录,而后者则仅仅包含一个指向数据记
录的指针。
2.1.3索引设计原则
1、每个查询原则上都需要创建对应索引
2、单个索引设计应考虑满足尽量多的查询
3、索引字段选择及顺序需要考虑查询覆盖率及选择性
4、对于更新及其频繁的字段上创建索引需慎重
5、对于数组索引需要慎重考虑未来元素个数
6、对于超长字符串类型字段上慎用索引
7、并发更新较高的单个集合上不宜创建过多索引
2.1.4索引操作
(1)默认自动创建_id建立唯一索引
避免重复插入_id值相同的文档
(2)单一健索引
db.集合名.createIndex({key:})
db.books.createIndex({name:-1})
key为健名,n为1或者-1 代表升序和降序
实例:集合数据 中国古典十大名曲
集合名 文档
books
{name:“高山流水”,content:“中国古琴曲,属于中国十大古曲之一。传说先秦的琴师伯牙一次在荒山野地弹琴,樵夫钟子期竟能领会这是描绘峨峨兮若泰山和洋洋兮若江河。伯牙惊道:善哉,子之心而与吾心同。钟子期死后,伯牙痛失知音,摔琴绝弦,终生不弹,故有高山流水之曲。”}
{name:”梅花三弄”,content:”《梅花三弄 [8] [11]》,又名《梅花引》《梅花曲》《玉妃引》,根据《太音补遗》和《蕉庵琴谱》所载,相传原本是晋朝桓伊所作的一首笛曲,后来改编为古琴曲。”}
{name:”汉宫秋月”,content:”《汉宫秋月》现流传的演奏形式有二胡曲、琵琶曲、筝曲、江南丝竹等。主要表达的是古代宫女哀怨悲愁的情绪及一种无可奈何、寂寥清冷的生命意境。”}
{name:”阳春白雪”,content:”《阳春白雪》 [2-3]是古典名曲,为中国著名十大古曲之一。表现的是冬去春来,大地复苏,万物欣欣向荣的初春美景。”}
{name:”渔樵问答”,content:”《渔樵问答》是一首中国古琴名曲,为中国十大古曲之一。此曲在历代传谱中,有30多种版本,有的还附有歌词。”}
{name:”广陵散”,content:”又名《广陵止息》。它是中国古代一首大型琴曲,中国音乐史上非常著名的古琴曲,著名十大古琴曲之一。”}
{name:”平沙落雁”,content:”又名《雁落平沙》,是一首中国古琴名曲,有多种流派传谱,其意在借大雁之远志,写逸士之心胸。”}
{name:”十面埋伏”,content:”乐曲整体可分为三部分,由十三段带有小标题的段落构成,分别是:列营、吹打、点将、排阵、走队、埋伏、鸡鸣山小战、九里山大战、项王败阵、乌江自刎、众军奏凯、诸将争功和得胜回营。该曲以公元前202年刘邦与项羽垓下之战的史实为内容,用标题音乐的形式描绘了激烈的战争场面,虽为史实,却也不乏丰富的感情色彩”}
db=([{name:“高山流水”,content:“中国古琴曲,属于中国十大古曲之一。传说先秦的 琴师伯牙一次在荒山野地弹琴,樵夫钟子期竟能领会这是描绘峨峨兮若泰山和洋洋兮若江河。 伯牙惊道:善哉,子之心而与吾心同。钟子期死后,伯牙痛失知音,摔琴绝弦,终生不弹,故 有高山流水之曲。”},{name:“梅花三弄”,content:“名梅花引、梅花曲、玉妃引,根据太音补遗和蕉庵琴谱所载,相传原本是晋朝桓伊所作的一首笛曲,后来改编为古琴曲”},
{name:“阳春白雪”,content:“阳春白雪》 [2-3]是古典名曲,为中国著名十大古曲之一。表现的是冬去春来,大地复苏,万物欣欣向荣的初春美景。”}])
案例2:学生信息表
集合 文档记录
Student {_id:”20090101”,name:”王庆”,depart:”计算机科学与技术”}
{_id:”20090102”,name:”周三”,depart:”计算机科学与技术”}
{_id:”20090101”,name:”刘明明”,depart:”计算机科学与技术”}
{_id:”20090101”,name:”王青云”,depart:”计算机科学与技术”}
(3)唯一索引
db.book.createIndex({name:1},{unique:true})
Name的值时唯一的,测试
(4)复合索引
db.book.createIndex({key:n,key:n})
(5)文本索引
db.book.createIndex({name:text})
建立文档索引
(6)查看索引
#查看索引信息
db.books.getIndexes()
#查看索引键
db.books.getIndexKeys()
(7)查看索引占用空间
db.collection.totalIndexSize([is_detail])
(8)删除索引
#删除集合指定索引
db.col.dropIndex(“索引名称”)
[备注]删除索引,索引名要与查询的索引名一样
#删除集合所有索引 不能删除主键索引
db.col.dropIndexes()
(9)地理空间索引
在移动互联网时代,基于地理位置的检索(LBS)功能几乎是所有应用系统的标配。 MongoDB为地理空间检索提供了非常方便的功能。 地理空间索引(2dsphereindex)就是 专门用于实现位置检索的一种特殊索引。
实例:创建集合
db.res.insert({
restaurantId: 0,
restaurantName: “兰州牛肉面”,
location: {
type: “Point”,
coordinates: [73.97, 40.77]
}
})
创建一个2dsphere索引
db.restaurant.createIndex({location : “2dsphere”})
MongoDB搭建集群
一、认识MongDB的复制集
二、运用MongoDB复制集搭建主从架构集群
1.创建数据目录
2.参考配置Mongod.conf文件
【注意事项】前面是4个空格
3.分别启动3个MOngoDB的节点( 启动 MongoDB 进程)
mongod -f D:\mongodb\data\db1\mongod.conf
mongod -f D:\mongodb\data\db2\mongod.conf
mongod -f D:\mongodb\data\db3\mongod.conf
如图所示:
【注意】以上命令需要在3个不同的窗口执行,执行后不可关闭窗口否则进程将直接结束。
4.配置复制集
(1)进入MongoDb主节点mongo shell
Mongosh --port=28017
(2)创建复制集
rs.initiate({
_id: “rs0”,
members:
[
{_id: 0,host: “localhost:28017”},
{_id: 1,host: “localhost:28018”},
{_id: 2,host: “localhost:28019”}
]
})
(3)观察节点信息发生变化
rs.status() —集群的基本信息
主节点
(3)测试集群
A.主节点测试登录
#连接primary节点 mongo --host 127.0.0.1 --port=28017 db.users.insert({“name”:“liyong”,“age”:11});
db.users.find();
可以看到集群搭建成功以后连接
测试主节点读数据
b.users.find(); #在从节点进行查询数据
我们可以看到这也一个错误,需要执行rs.slaveOk();
rs.slaveOk(); #执行此命令以后我们就可以进行查询数据了
B.从节点测试:
secondary节点
mongo --host 127.0.0.1 --port=28018
插入文档,返回失败,从节点不能写入数据
db.users.insert({“name”:“liyong”,“age”:11});
插入数据的时候提示我们了,不是主节点,这也验证了前面提到的再从节点是只读的,主节点可读可写
C.测试从节点读取数据
默认的情况下从节点是没有读写的权限的
设置允许从节点读数据
rs.secondaryOk()
然后从节点就可以写数据
测试关闭primary节点,演示主节点重新选取
三、MongoDB分片搭建集群
(5)mongodb分片集群的使用
A.连接路由服务器
Mongosh --port=27017
sh.status() ##查看分片集群的状态,关注shards和databases分组
B、分片集群添加数据角色,数据角色为副本集的方式
sh.addShard(“rs10/127.0.0.1:29020,127.0.0.1:29021,127.0.0.1:29022”)
sh.addShard(“rs11/127.0.0.1:29023,127.0.0.1:29024,127.0.0.1:29025”)
C.查看分片集群信息 sh.status()
1.分片集群介绍
高数据量和吞吐量的数据库应用会对单机的性能造成较大压力,大的查询量会将单机的CPU耗尽,大的数据量对单机的存储压力较大,最终会耗尽系统的内存而将压力转移到磁盘IO上。
为了解决这些问题,有两个基本的方法: 垂直扩展和水平扩展。
垂直扩展:增加更多的CPU和存储资源来扩展容量。
水平扩展:将数据集分布在多个服务器上。水平扩展即分片。
2.MongoDB分片集群简介
(1)分片介绍
分片是指将数据拆分并分散存放在不同机器上的过程,有时也用分区来表示这个概念。将数据分散到不同的机器上,不需要功能强大的计算机就可以存储更多的数据,处理更大的负载。MongoDB支持自动分片,可以使数据库架构对应用程序不可见,简化系统管理。对应用程序而言,就如同始终在使用一个单机的MongoDB服务器一样。
(2)MongoDB分片
分片集群组件介绍
构建一个MongoDB的分片集群,需要三个重要组件,分别是分片服务器(Shard Server)、配置服务器(Config Server)、路由服务器(Router Server)。
Shard Server
每个分片服务器都是一个mongod数据库实例,用于存储实际的数据块,整个数据库集合分成多个存储在不同的分片服务器中。在实际生产中,一个Shard Server可以由多台机器组成一个副本集来承担,防止因主节点单点故障导致整个系统崩溃。
Config Server
这是独立的一个mongod进程,存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。
mongos第一次启动或者关掉重启就会从config server加载配置信息,以后如果配置服务器信息变化会通知到所有的mongos更新自己的状态,这样mongos就能继续准确路由。在生产环境通常设置多个config server,因为它存储了分片路由的元数据,防止单点数据丢失!
Router Server
这是独立的一个mongod进程,Router Server在集群中可作为路由使用,客户端由此
接入,让整个集群看起来像是一个单一的数据库,提供客户端应用程序和分片集群之间的接口。
Router Server本身不保存数据,启动时从Config Server加载集群信息到缓存中,并将客户端的请求路由给每个Shard Server,在各Shard Server返回结果后进行聚合并返回给客户端。
在实际生产环境中,副本集和分片是结合起来使用的,可满足实际应用场景中高可用性和高可扩展性的需求。
3.MongoDB分片集群的部署通常涉及以下几个步骤
(1)配置分片(shard)服务器
(2)配置配置服务器(config servers)
(3)设置mongos路由实例
(4)启动集群
(5)分片数据
4.MongoDB分片集群部署实战演练
(1)分片集群的搭建说明
使用同一份mongodb二进制文件,即mongod.conf
修改对应的配置就能实现分片集群的搭建
Config Server:使用28017、28018、28019三个端口来搭建(3台)–也是采用复制集这种搭建
Router Server:使用27017、27018两个端口来搭建(2台)—也是采用复制集这种搭建
Shard Server: 使用29020、29021、29022,29023,29024,29025六个端口来搭建,三个一组,模拟(两个分片)两个数据的集群,每个分片采用3个节点搭建复制集集群
(2)Config Server搭建
【备注】假设Config server3台数据库的数据目录为
A.配置mongod.conf
mongodb配置角色的搭建,配置文件路径/usr/local/mongodb/28017/mongod.conf
文件内容参考如下文件:
mongod.conf
c:\data\db1\mongod.conf
systemLog:
destination: file
path: D:\mongodb\fenpian\config1\mongod.log #日志文件路径
logAppend: true
storage:
dbPath: D:\mongodb\fenpian\config1 # 数据目录
net:
bindIp: 0.0.0.0
port: 28017 # 端口
replication:
replSetName: rs1
##配置分片角色
sharding:
clusterRole: configsvr
B.启动mongodb configsvr实例
mongod.exe -f D:\mongodb\fenpian\config1\mongod.conf
mongod.exe -f D:\mongodb\fenpian\config2\mongod.conf
mongod.exe -f D:\mongodb\fenpian\config3\mongod.conf
C.Windows操作系统下 侦听端口
使用PowerShell
打开PowerShell(可以在开始菜单中搜索“PowerShell”)。
输入命令 Get-NetTCPConnection,然后按回车。
这将显示所有TCP连接的详细信息,包括状态为“Listen”的端口。
D.分片集群的配置角色副本集搭建
(1)进入MongoDb主节点mongo shell
mongosh --port=28017
(2)创建复制集
ca={_id:“rs1”,
configsvr: true,
members:[{_id:0,host:“127.0.0.1:28017”},{_id:1,host:“127.0.0.1:28018”},{_id:2,host:“127.0.0.1:28019”}]
}
cmd【备注】_id的值与配置文件 “replSetName: rs1” 是一样的
rs.initiate(ca)
(3)#查看副本集状态
rs.status()
(3)Shard Server搭建
A.数据角色:分片集群的数据角色里存储着真正的数据,所以数据角色一定得使用副本集
29020、29021、29022一个集群,数据角色rs10
29023、29024、29025一个集群,数据角色rs11
设计分片服务器
备注:线上生产环境一个集群中应至少启用三个mongodb实例
B.在配置文件中设置角色为 shardsvr
注意有两个分片集群,其中复制集的名字分别设置为rs10 和rs11
C.Shard Server启动所有实例
mongod.exe -f D:\mongodb\fenpian\shard-29020\mongod.conf
mongod.exe -f D:\mongodb\fenpian\shard-29021\mongod.conf
mongod.exe -f D:\mongodb\fenpian\shard-29022\mongod.conf
mongod.exe -f D:\mongodb\fenpian\shard-29023\mongod.conf
mongod.exe -f D:\mongodb\fenpian\shard-29024\mongod.conf
mongod.exe -f D:\mongodb\fenpian\shard-29025\mongod.conf
D.数据角色的副本集搭建
①数据角色rs10
(1)进入MongoDb主节点mongo shell
mongosh --port=29020
(2)创建复制集
config={_id:“rs10”, members:[{_id:0,host:“127.0.0.1:29020”},{_id:1,host:“127.0.0.1:29021”},{_id:2,host:“127.0.0.1:29022”}]}
rs.initiate(config)
(3)查看分片集群装填
rs.status()
②数据角色rs11
(1)进入MongoDb主节点mongo shell
mongosh --port=29023
(2)创建复制集
config={_id:“rs11”, members:[{_id:0,host:“127.0.0.1:29023”},{_id:1,host:“127.0.0.1:29024”},{_id:2,host:“127.0.0.1:29025”}]}
rs.initiate(config)
(3)查看分片集群装填
rs.status()
(4)Router Server搭建
mongodb中的router角色只负责提供一个入口,不存储任何的数据。
A.配置mongodb.conf
Router配置文件路径27017/mongodb.conf
【注意事项】#不需要配置副本集名称
Router最重要的配置是:
(1)指定configsvr的地址,使用副本集id+ip端口的方式指定
(2)配置多个Router,任何一个都能正常的获取数据
(3)##不参与数据存储,所以不需要配置存储数据的目录
配置文件:
systemLog:
destination: file
path: D:\mongodb\fenpian\27017\mongod.log #日志文件路径
logAppend: true
##不参与数据存储,所以不需要配置存储数据的目录
#storage:
dbPath: D:\mongodb\fenpian\27017 # 数据目录
net:
bindIp: 0.0.0.0
port: 27018 # 端口
#replication:
replSetName: rs1
##配置分片角色 #配置configsvr副本集和IP端口
sharding:
configDB: rs1/127.0.0.1:28017,127.0.0.1:28018,127.0.0.1:28019
B、启动mongodb Routersvr实例
mongos -f D:\mongodb\fenpian\27017\mongod.conf
mongos -f D:\mongodb\fenpian\27018\mongod.conf
(5)mongodb分片集群的使用
A.连接路由服务器
Mongosh --port=27017
sh.status() ##查看分片集群的状态,关注shards和databases分组
B、分片集群添加数据角色,数据角色为副本集的方式
sh.addShard(“rs10/127.0.0.1:29020,127.0.0.1:29021,127.0.0.1:29022”)
sh.addShard(“rs12/127.0.0.1:29023,127.0.0.1:29024,127.0.0.1:29025”)
C.查看分片集群信息 sh.status()
(6)测试分片集群
A.实际操作演练
默认添加数据是没有使用分片存储的,操作都是在路由服务器中,如:
#插入500条数据做实验
use data1
for (i=1; i<=500; i++){db.users.insert({name:‘test’ + i, id:i})}
sh.status() ##查看分片集状态,可以看到500条数据全部插入到了其中一个rs11副本集群中,并没有分片
B.配置hash分片存储
针对某个数据库的某个集合使用hash分片存储,这样就能实现同一个集合分配两个数据角色
【备注】当某个数据库要开启分片存放数据时,这个数据库必须要创建索引
(1)设置data1数据库中users集合的索引
use data1
db.users.createIndex({id:1})
(2)切换到admin数据库中对 data1中集合users设置分片存储数据
use admim
db.runCommand({ enablesharding : “data1”})
#使用此命令开启data1数据库的分片存储
db.runCommand({ shardcollection : “data1.users”, key : {id:“hashed”}})
##根据data1数据库中users集合的默认_id字段开启hash分片存储
(3)测试数据2:插入数据校验,数据被均匀分配到两个数据库中
use data1
for (i=1; i<=800; i++){db.users.insert({name:‘test’ + i, id:i})}
(4)查看分片集群的状态 sh.status()
(5)路由服务器:进入到data1数据库中
查看users集合有多少数据
db.users.count() #有多少条数据
(7)进入分片服务器rs10
mongosh --port=29020
show dbs
use data1
show tables
db.users.count()
(8)进入分片服务器rs11
以上步骤就实现了MongoDB的分片集群的搭建

![[OtterCTF 2018]Name Game](https://img-blog.csdnimg.cn/img_convert/03a980ee574bf77b4820474ccf280107.png)