一、开启WAL归档
1、创建归档目录
我们除了存储数据目录pgdata之外,还要创建backups,scripts,archive_wals文件
mkdir -p /home/mydba/pgdata/arch
mkdir -p /home/mydba/pgdata/scripts
mkdir -p /home/mydba/backups
chown -R mydba.mydba /home/mydba

其中pgdata是数据库的数据目录,backups目录是用来存放基础备份,scripts目录用来存放一些任务脚本。arch目录用来存放归档。
2、修改wal_level参数
- wal_level参数可选的值有minimal、replica和logical,从minimal到replica再到logical级别,WAL的级别依次增高,在WAL中包含的信息也越多。在minimal模式下无法开启归档,所以开启WAL归档wal_level至少设置为replica。设置方法如下:
ALTER SYSTEM SET wal_level = 'replica';

3、修改archive_mode参数
archive_mode参数可选的值有on、off和always,默认值为off,开启归档需要修改为on,修改方式如下:
ALTER SYSTEM SET archive_mode = 'on';

修改此参数需要重新启动数据库使之生效

4、修改archive_command参数
-
archive_command参数默认是个空字符串,它的值可以是一条shell命令或者是一个复杂的shell脚本。在archive_command的shell命令或者脚本可以使用“%p”表示将要归档的WAL文件的包含完整路径信息的文件名,用“%f”代表不包含路径信息的WAL文件的文件名。
-
修改wal_level和archive_mode参数都需要重启数据库才可以生效,修改archive_command不需要重启,只要reload即可。但是要注意,当开启了归档,应该注意archive_command设置的归档命令是否执行成功,如果归档命令未执行成功,它会周期性的重试,在此期间已有的WAL文件将不会被复用,新产生的WAL文件会不断张永pg_wal的磁盘空间,直到pg_wal所在的文件系统被占满后数据库关闭。
-
如果考虑到归档占用较多的磁盘空间,配置归档时可以将WAL压缩之后在归档,可以使用gzip、bzip2或lz4等压缩工具进行压缩。以下一lz为例子:
ALTER SYSTEM SET archive_command = '/usr/bin/lz4 -q -z %p /home/mydba/pgdata/arch/%f.lz4';
show archive_command;


二、物理备份
这里是使用pg_basebackup的备份与恢复
pg_basebackup 也算是物理方式,是可以使用流协议。并且是热备范畴,备份的时候不需要停数据库,但,恢复的时候需要停数据库。
备份:使用pg_basebackup命令来进行备份,这个命令可以将postgresql的数据文件备份为两个压缩文件:base.tar和 pg_wal.tar。本别是数据文件和归档文件,恢复的时候,需要设置按照归档文件来恢复。那么,此种方式的备份可以备份自定义表空间。
恢复:需要先把备份的压缩文件替换当前的数据文件,然后修改postgresql.conf,因为这个配置文件在data文件夹中,所以只能是在把base.tar解压到数据库当前数据位置,也就是我们默认初始化指定的数据保存位置data文件夹中,才能修改配置,在配置好归档设置以后,可以启动pgsql服务,进行启动恢复。
在恢复过程中,会拷贝归档文件,进行数据恢复。
恢复成功,也就是数据库服务启动成功。这个时候我们访问数据库,它是作为归档状态存在的,所以只能读,不能写操作。
为了恢复数据库写操作,我们需要在命令行下执行切换数据库状态的指令。切换成功之后,才可以进行读写操作。
pg_basebackup -Ft -Pv -z -Z5 -p 5432 -D /home/mydba/backups/
-z -Z 5是压缩等级,范围是0-9, -Ft是tar包格式备份。

停止数据库:
pg_ctl stop

删除原库的数据文件:
rm -rf /home/mydba/pgdata/*
解压备份文件到对应路径:
# 恢复基本数据文件
tar zxvf /home/mydba/backups/base.tar.gz -C /home/mydba/pgdata
# 恢复wal日志
tar zxvf /home/mydba/backups/pg_wal.tar.gz -C /home/mydba/pgdata/arch
修改postgresql.conf文件:
任选一种恢复方式:
- 立刻恢复
restore_command = 'cp /home/mydba/pgdata/arch/%f %p'
recovery_target = 'immediate'
- 可以按时间线恢复到最新
# 恢复到最新:
restore_command = 'cp /home/mydba/pgdata/arch/%f %p'
recovery_target_timeline = 'latest'
- 按时间点恢复
restore_command = 'cp /home/mydba/pgdata/arch/%f %p'
recovery_target_time = '2024-06-13 14:16:16.007657+08'
如果不想进入备份模式,直接数据库启动就可以用,那么就使用promote。
recovery_target_action #指定在达到恢复目标时服务器采取的动作。
pause #默认值,表示恢复将被暂停
promote #表示恢复结束且服务器将开始接受连接
shutdown #表示在达到恢复目标之后停止服务器。


启动数据库
pg_ctl -D /home/mydba/pgdata/ start

报错
创建恢复文件
touch recovery.signal
再次启动数据库
pg_ctl -D /home/mydba/pgdata/ start

启动成功,经过检验,数据恢复成功。

查询数据库状态:
pg_controldata

此时数据库的状态是备份模式,需要恢复一下
pg_ctl promote

再次查询

或者进入sql执行以下命令也可以解决。
select pg_wal_replay_resume();
三、逻辑备份
热备热恢复
首选当然是pg_dump啦,这个备份工具是和pg_restore配套的,也可以看成是一个组合。
该备份工具的特点是稳定,高效,冷热备份恢复都可以,可以选择数据库部分表备份,只备份表结构,因此,该工具的使用比较复杂,这点是相对物理备份来说的。
物理备份有一种暴力的美学感觉,简单的方法有时候更为高效。逻辑备份比较枯燥,复杂。
pg_dump常用参数
-h host,指定数据库主机名,或者IP
-p port,指定端口号
-U user,指定连接使用的用户名
-W,按提示输入密码
-F, --format=c|d|t|p output file format (备份文件的格式是自定义,目录,tar包,纯文本,不使用该参数,将会是纯文本默认)
-d 指定连接的数据库名称,实际上也是要备份的数据库名称。
-a,–data-only,只导出数据,不导出表结构,该选项只对纯文本格式有意义。
-c,–clean,是否生成清理该数据库对象的语句,比如drop table,该选项只对纯文本格式有意义。
-C,–create,是否输出一条创建数据库语句,该选项只对纯文本格式有意义。
-f file,–file=file,输出到指定文件中
-n schema,–schema=schema,只转存匹配schema的模式内容
-N schema,–exclude-schema=schema,不转存匹配schema的模式内容
-O,–no-owner,不设置导出对象的所有权
-s,–schema-only,只导致对象定义模式,不导出数据
-t table,–table=table,只转存匹配到的表,视图,序列,可以使用多个-t匹配多个表
-T table,–exclude-table=table,不转存匹配到的表。
–inserts,使用insert命令形式导出数据,这种方式比默认的copy方式慢很多,但是可用于将数据导入到非PostgreSQL数据库。
–column-inserts,导出的数据,有显式列名
备份前数据库mydb的表内容:


备份t1单表
备份命令
pg_dump -h localhost -U mydba --port=5432 -d mydb -t t1 -f /home/mydba/t1-bak1.sql

如果有迁移到其它数据库,比如oracle的计划,那么,最好还是添加参数–inserts,上面的命令修改为如下:
pg_dump -h localhost -U mydba --port=5432 -d mydb -t t1 -f /home/mydba/t1-bak2.sql --inserts

如果希望恢复的时候不需要切换数据库,那么,应该使用参数大C,命令如下:
pg_dump -h localhost -U mydba --port=5432 -d mydb -t t1 -C -f /home/mydba/t1-bak3.sql --inserts

pg_dump的恢复命令
进入pg命令行直接执行备份的SQL文件即可(执行SQL语句前需要切换数据库到mydb):
\i /home/mydba/t1-bak1.sql
归档文件分类
归档格式的备份文件又分为两种,最灵活的输出文件格式是“custom”自定义格式(使用命令项参数“-Fc”来指定),它允许对归档元素进行选取和重新排列,并且默认是压缩的;另一种是tar格式(使用命令项参数“-Ft”来指定),这种格式的文件不是压缩的,并且加载时不能重新排序,但是它也很灵活,可以用标准UNIX下的tar工具进行处理。custom自定义格式比较常用。
不带-F参数的时候,默认是纯文本模式(纯文本模式备份的文件可以使用记事本打开,里面都是SQL语句)
归档格式的备份文件必须与pg_restore一起使用来重建数据库,这种格式允许pg_restore选择恢复哪些数据,甚至可以在恢复之前对需要恢复的条目重新排序。
pg_dump可以将整个数据库备份到一个归档格式的备份文件中,而pg_restore则可以从这个归档格式的备份文件中选择性地恢复部分表或数据库对象,而不必恢复所有的数据。
归档模式的时候,必须使用pg_restore工具来进行恢复
以下仍然是单表的备份和恢复,备份文件名做了一个时间格式化,恢复的时候是使用pg_restore命令,使用psql将会报错。
pg_dump -h localhost -U mydba --port=5432 -d mydb -t t1 -Fc -f /home/mydba/$(date +'%Y-%m-%dT%H:%M:%S.%2N%z')-t1-bak1.sql
pg_restore -d mydb /home/mydba/2024-06-14T10:05:56.46+0800-t1-bak1.sql


pg_dump 热备单库热恢复(热恢复指的是不需要停止数据库服务)
pg_dump -h localhost -U mydba --port=5432 -d mydb -C -f /home/mydba/mydb-bak.sql --inserts



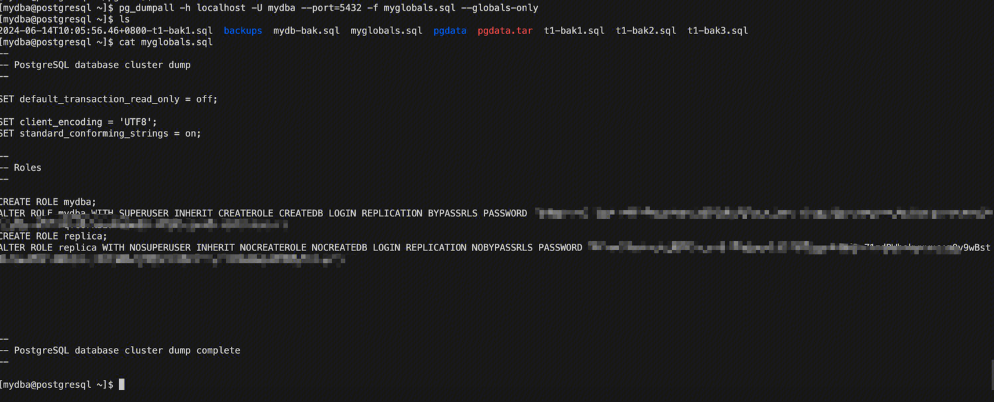
pg_dumpall
此工具是全库备份,但,一般是不使用这个的,因为,数据库有可能会很大,进而备份的时候出现问题,此工具可以备份用户信息,例如下面这个命令(全局对象里包括用户,因此,如果是仅备份用户信息,也可以使用参数r即可):
pg_dumpall -h localhost -U mydba --port=5432 -f myglobals.sql --globals-only



![[单机版架设]新天堂2-死亡骑士338|带AI机器人](https://img-blog.csdnimg.cn/img_convert/17d0000cbf3d9c3b1c36ce1ffa8fcfd8.webp?x-oss-process=image/format,png)