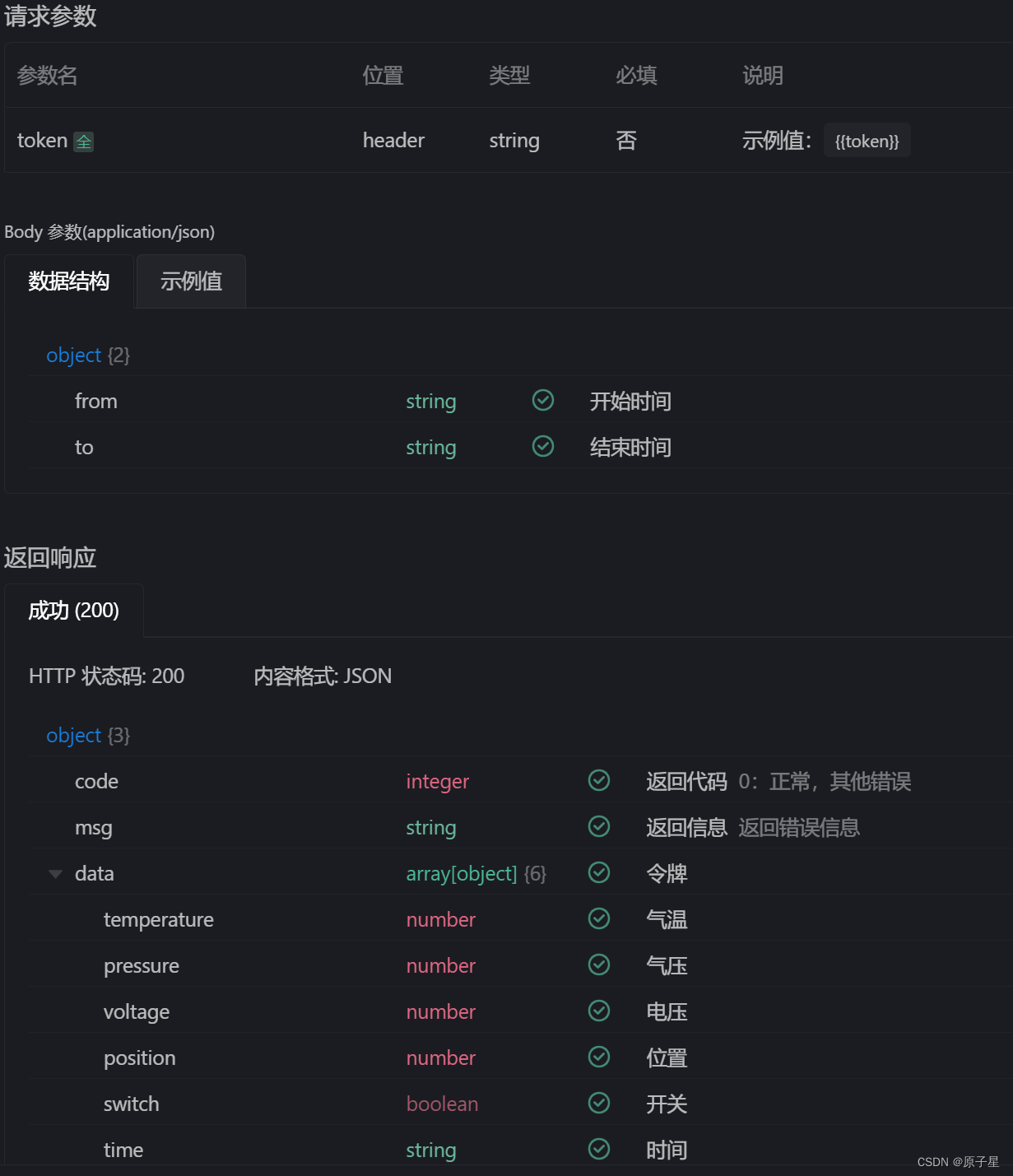
目录
01 「伪装」过程
02 实验结果
03 成绩如何?
调查显示,94%的AI生成内容完全不会被大学教授察觉。
而且在83.4%的情况下,「AI同学」的成绩显著高于人类学生。
看来,AI真的要攻陷人类的考试了。
其实,早在GPT-4发布时,OpenAI就声称,它能在SAT的阅读和数学考试中分别打败93%和89%的人类。
虽然这些数字令人震惊,但技术报告中并未披露这些数据的具体来源和实验设置。这大大削弱了数据的可信度。
之前虽然也有很多关于AI参与考试作弊的研究,但它们大多是在实验环境中得出数据,与真实情景还是有所差距。
没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952
但最近英国的研究人员在现实的大学考试中为AI做的这次「图灵测试」,已经将实验过程和数据以论文的形式发布了出来。

结果发现,虽然我们每天抱怨AI生成的文本「一眼假」,但实际上大学教授也很容易被蒙混过去,有94%的AI生成内容——完全没有被发现!
此外,AI生成内容的平均水平也显著高于人类同学,差距大概是半个等级。在83.4%的情况下,AI的成绩高于随机选择的学生。
这让人类感到真实的颤抖……
这也意味着,AI的「以假乱真」程度再次被证实,不仅在能力上可以替代打工人,还在认知任务上完全碾压了大学生。
01 「伪装」过程
描述这种在真实世界中进行的「图灵测试」,画面感强到像是真人秀现场。
团队选中了英国雷丁大学的心理学和临床语言科学学院,但完全没有告知考试评分员。
除了批准研究的参与者和负责帮助AI伪装成学生的行政人员,没有人知道这项研究正在进行。

在COVID之后,像许多英国大学一样,雷丁大学也更多地转向线上考试。
学生在规定时间内完成题目或论文,而且是完全的开卷模式,参考课程材料、论文、书籍、互联网材料都是被允许的。
这项考试共有两种题型,一是简答题(SAQ),2.5小时内完成,从6个问题中任选4题回答,答案不超过200词;二是论文题(Essay),从3~4个题目中任选其一,在8小时内完成一篇1500词的论文。
每个考试模块中都混入了约占总数5%的AI生成内容。这个比例不会造成额外的评分负担,也让两位作者能够在规定时间内确保提交的AI内容没有出现自相似情况,否则会很容易被判定为抄袭。
作者使用标准化的提示词让GPT-4生成每种类型考试的答案。
对于简答题(SAQ),提示词是:
包括对学术文献的引用,但不需要单独的参考文献部分,请用160词回答以下问题:XXX
对于论文题,提示词是:
包括对学术文献的引用,但不需要单独的参考文献部分,请写一篇2000词的文章回答以下问题:XXX
在与GPT-4打交道时,作者发现模型经常不遵循提示中关于字数的要求。简答题总是超字数,而论文又写不到规定长度,因此调整了提示词中的字数。
为了保证AI的「真实性」,GPT-4生成的内容被100%原汁原味地搬运到试卷上,作者没有添加过渡文字或用任何方式修改文本内容,最大的改动就是为论文添加必要格式,或者删去模型径自生成的免责声明和参考文献。
总而言之,原则是保证100%的AI书面答案,但要在其他地方「藏好尾巴」,防止评分人员看出破绽。
02 实验结果
多少被发现了?
在这项研究中,只要评分员将作业标记为「值得关注」,可能存在某种形式的不良学术行为或学术不端,都不需要特别提到AI,就算是被检测到了。
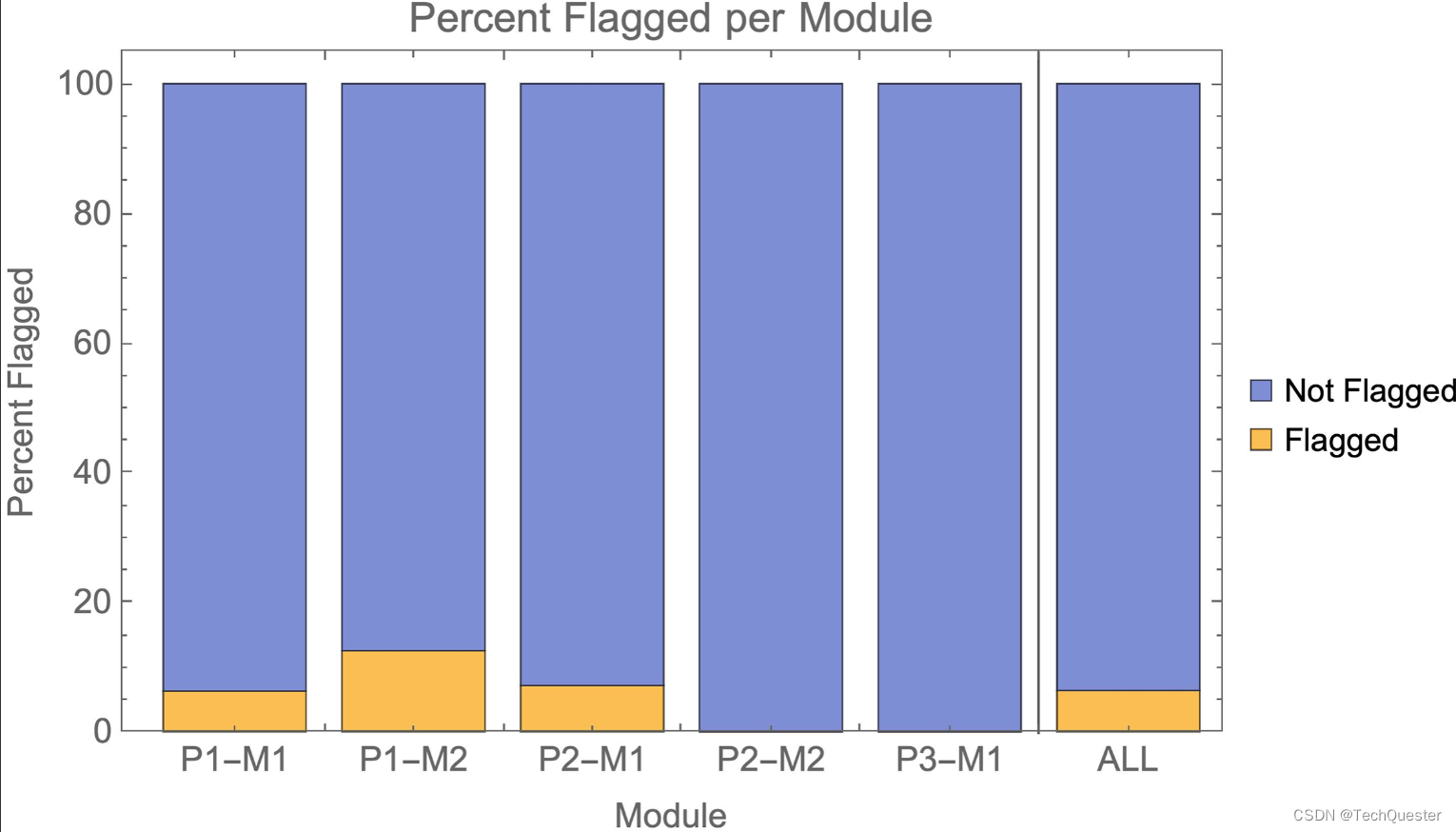
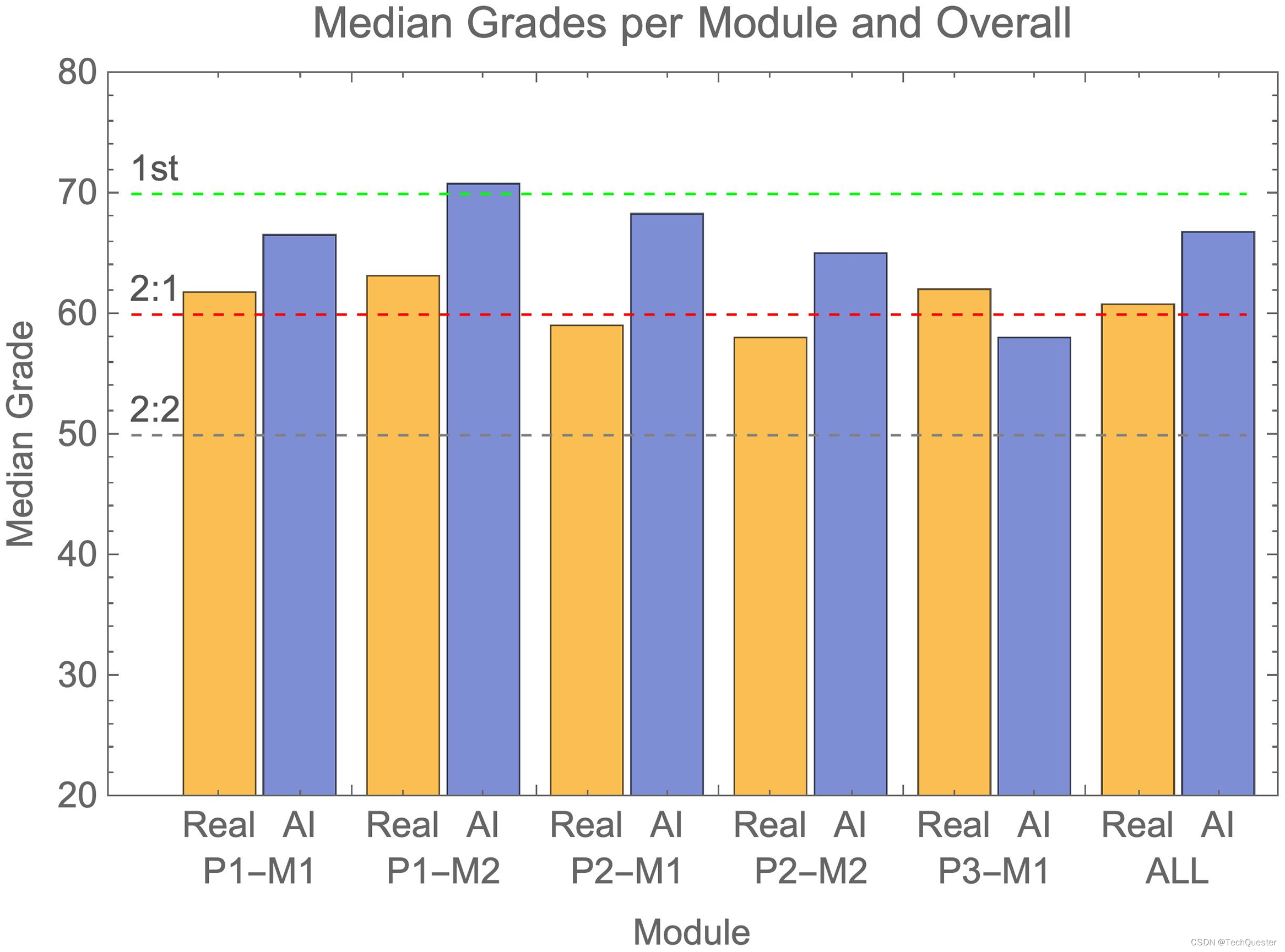
即使规则如此宽松,检测成功的百分比依旧少得可怜。如图1和表3所示,在P2-M2和P3-M1的两个论文题目中,检测准确率甚至为零。也就是说,作者分别混入的14篇和3篇AI文章完全没有引起评分员的警觉。

总体来看,AI提交的作业几乎无法检测,有94%的作业未被发现。
如果我们采用更严格的「检测」标准,要求标记时必须特别提到AI,那么97%的AI提交作业未被发现。
03 成绩如何?
将被检测出来的AI内容剔除后,作者比较了GPT-4和人类学生的分数分布情况。
可以看到,蓝色部分相比橙色部分整体右移,说明AI的成绩往往集中在真实成绩分布的高端,中位数对应First或者Upper Second等级。
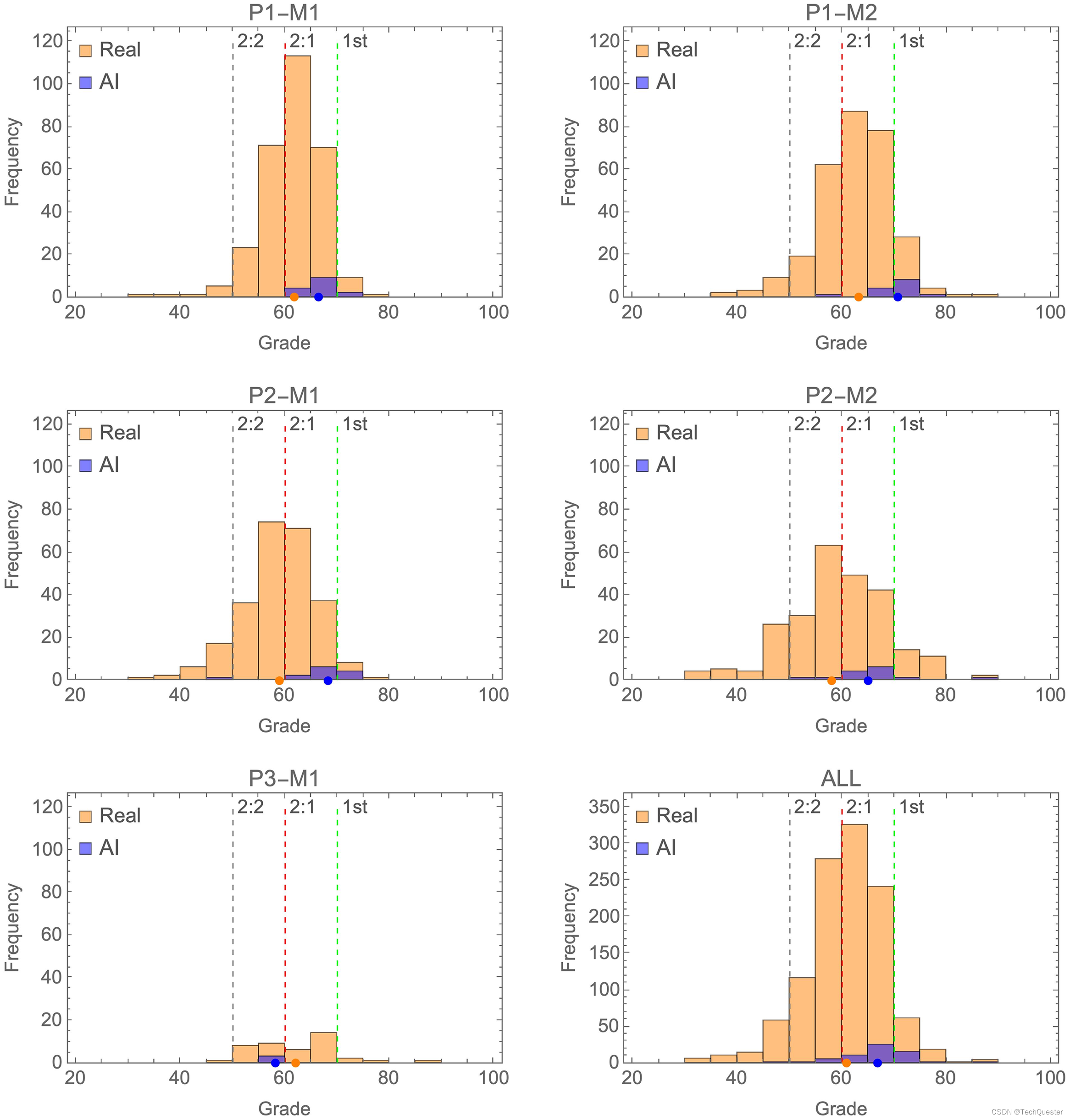
其中P3-M1模块是一个例外,AI的成绩集中在真实分数分布的低端。但考虑到这个模块只混入了4篇AI内容,远少于其他模块,因此可能是数据过少造成的偏误。
如何使用WildCard正确方式打开GPT-4o,目前 WildCard 支持的服务非常齐全,可以说是应有尽有!
官网有更详细介绍:WildCard
推荐阅读:
超越GPT-4o!新王Claude 3.5 Sonnet来啦!
GPT-4o首次引入!全新图像自动评估基准发布!




![[单机版架设]新天堂2-死亡骑士338|带AI机器人](https://img-blog.csdnimg.cn/img_convert/17d0000cbf3d9c3b1c36ce1ffa8fcfd8.webp?x-oss-process=image/format,png)