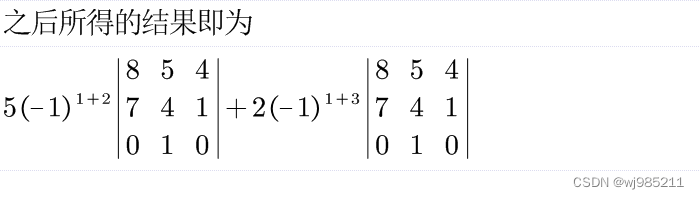1、网络构建
神经网络模型是由神经网络层和Tensor操作构成的,mindspore.nn提供了常见神经网络层的实现,在MindSpore中,Cell类是构建所有网络的基类,也是网络的基本单元。一个神经网络模型表示为一个Cell,它由不同的子Cell构成。使用这 样的嵌套结构,可以简单地使用面向对象编程的思维,对神经网络结构进行构建和管理。
mindspore.nn.Cell类——mindspore.nn.Cell(auto_prefix=True, flags=None)
MindSpore中神经网络的基本构成单元。模型或神经网络层应当继承该基类。
mindspore.nn 中神经网络层也是Cell的子类,如 mindspore.nn.Conv2d 、 mindspore.nn.ReLU 等。Cell在GRAPH_MODE(静态图模式)下将编译为一张计算图,在PYNATIVE_MODE(动态图模式)下作为神经网络的基础模块。
【参数】
-
auto_prefix (bool,可选) - 是否自动为Cell及其子Cell生成NameSpace。该参数同时会影响 Cell 中权重参数的名称。如果设置为
True,则自动给权重参数的名称添加前缀,否则不添加前缀。通常情况下,骨干网络应设置为True,否则会产生重名问题。用于训练骨干网络的优化器、 mindspore.nn.TrainOneStepCell 等,应设置为False,否则骨干网络的权重参数名会被误改。默认值:True。 -
flags (dict,可选) - Cell的配置信息,目前用于绑定Cell和数据集。用户也通过该参数自定义Cell属性。默认值:
None。
下面构建一个用于Mnist数据集分类的神经网络模型 。
2、定义模型
当我们定义神经网络时,可以继承nn.Cell类,在__init__方法中进行子Cell的实例化和状态管理,在construct方法中实现Tensor操作。
import mindspore
from mindspore import nn, opsconstruct意为神经网络(计算图)构建。
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512, weight_init="normal", bias_init="zeros"),
nn.ReLU(),
nn.Dense(512, 512, weight_init="normal", bias_init="zeros"),
nn.ReLU(),
nn.Dense(512, 10, weight_init="normal", bias_init="zeros")
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits 构建完成后,实例化Network对象,并查看其结构。
model = Network()
print(model)
构造一个输入数据,直接调用模型,可以获得一个十维的Tensor输出,其包含每个类别的原始预测值。
X = ops.ones((1, 28, 28), mindspore.float32)
logits = model(X)
# print logits
logits
通过一个nn.Softmax层实例来获得预测概率。
pred_probab = nn.Softmax(axis=1)(logits)
y_pred = pred_probab.argmax(1)
print(f"Predicted class: {y_pred}")![]()
3、模型层
分解上节构造的神经网络模型中的每一层。首先我们构造一个shape为(3, 28, 28)的随机数据(3个28x28的图像),依次通过每一个神经网络层来观察其效果。
input_image = ops.ones((3, 28, 28), mindspore.float32)
print(input_image.shape)![]()
3.1 nn.Flatten层
mindspore.nn.Flatten(start_dim=1, end_dim=- 1)
沿着从 start_dim 到 end_dim 的维度,对输入Tensor进行展平。
【参数】
-
start_dim (int, 可选) - 要展平的第一个维度。默认值:
1。 -
end_dim (int, 可选) - 要展平的最后一个维度。默认值:
-1。
输入——>x (Tensor) - 要展平的输入Tensor,输出——>Tensor。如果没有维度被展平,返回原始的输入 input,否则返回展平后的Tensor。如果 input 是零维Tensor,将会返回一个一维Tensor。
将28x28的2D张量转换为784大小的连续数组。
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.shape)![]()
3.2 nn.Dense层
mindspore.nn.Dense(in_channels, out_channels, weight_init=None, bias_init=None, has_bias=True, activation=None, dtype=mstype.float32)
全连接层。使用权重和偏差对输入进行线性变换。
适用于输入的密集连接层。公式如下:
outputs=activation(X∗kernel+bias)
其中 𝑋 是输入Tensor, activation 是激活函数, kernel 是一个权重矩阵,其数据类型与 𝑋 相同, bias 是一个偏置向量,其数据类型与 𝑋 相同(仅当has_bias为True时)。
【参数】
-
in_channels (int) - Dense层输入Tensor的空间维度。
-
out_channels (int) - Dense层输出Tensor的空间维度。
-
weight_init (Union[Tensor, str, Initializer, numbers.Number]) - 权重参数的初始化方法。数据类型与 x 相同。str的值引用自函数 initializer。默认值:
None,权重使用HeUniform初始化。 -
bias_init (Union[Tensor, str, Initializer, numbers.Number]) - 偏置参数的初始化方法。数据类型与 x 相同。str的值引用自函数 initializer。默认值:
None,偏差使用Uniform初始化。 -
has_bias (bool) - 是否使用偏置向量 bias 。默认值:
True。 -
activation (Union[str, Cell, Primitive, None]) - 应用于全连接层输出的激活函数。可指定激活函数名,如’relu’,或具体激活函数,如 mindspore.nn.ReLU 。默认值:
None。 -
dtype (mindspore.dtype) - Parameter的数据类型。默认值:
mstype.float32。
输入——>x (Tensor) - shape为 (∗,𝑖𝑛_𝑐ℎ𝑎𝑛𝑛𝑒𝑙𝑠) 的Tensor。参数中的 in_channels 应等于输入中的 𝑖𝑛_𝑐ℎ𝑎𝑛𝑛𝑒𝑙𝑠
输出——>shape为 (∗,𝑜𝑢𝑡_𝑐ℎ𝑎𝑛𝑛𝑒𝑙𝑠) 的Tensor。
layer1 = nn.Dense(in_channels=28*28, out_channels=20)
hidden1 = layer1(flat_image)
print(hidden1.shape)![]()
3.3 nn.ReLU
mindspore.nn.ReLU
逐元素计算ReLU(Rectified Linear Unit activation function)修正线性单元激活函数。
ReLU(𝑖𝑛𝑝𝑢𝑡)=(𝑖𝑛𝑝𝑢𝑡)+=max(0,𝑖𝑛𝑝𝑢𝑡),
逐元素求 max(0,𝑖𝑛𝑝𝑢𝑡) 。
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")
3.4 nn.SequentialCell
mindspore.nn.SequentialCell(*args)
构造Cell顺序容器。关于Cell的介绍,可参考 Cell。
SequentialCell将按照传入List的顺序依次将Cell添加。此外,也支持OrderedDict作为构造器传入。
【参数】
-
args (list, OrderedDict) - 仅包含Cell子类的列表或有序字典。
seq_modules = nn.SequentialCell(
flatten,
layer1,
nn.ReLU(),
nn.Dense(20, 10)
)
logits = seq_modules(input_image)
print(logits.shape)![]()
3.5 nn.Softmax
mindspore.nn.Softmax(axis=- 1)
逐元素计算Softmax激活函数,它是二分类函数 mindspore.nn.Sigmoid 在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
对输入Tensor在轴 axis 上的元素计算其指数函数值,然后归一化到[0, 1]范围,总和为1。
Softmax定义为:

其中, 𝑖𝑛𝑝𝑢𝑡𝑖 是输入Tensor在轴 axis 上的第 𝑖 个元素。
【参数】
-
axis (int,可选) - 指定Softmax运算的轴axis,假设输入 input 的维度为input.ndim,则 axis 的范围为 [-input.ndim, input.ndim) ,-1表示最后一个维度。默认值:
-1。
最后使用nn.Softmax将神经网络最后一个全连接层返回的logits的值缩放为[0, 1],表示每个类别的预测概率。axis指定的维度数值和为1。
softmax = nn.Softmax(axis=1)
pred_probab = softmax(logits)4、模型参数
网络内部神经网络层具有权重参数和偏置参数(如nn.Dense),这些参数会在训练过程中不断进行优化,可通过 model.parameters_and_names() 来获取参数名及对应的参数详情。
print(f"Model structure: {model}\n\n")
for name, param in model.parameters_and_names():
print(f"Layer: {name}\nSize: {param.shape}\nValues : {param[:2]} \n")



![[OtterCTF 2018]Recovery](https://img-blog.csdnimg.cn/img_convert/870384e7da3fdcebffe88ebc58130266.png)