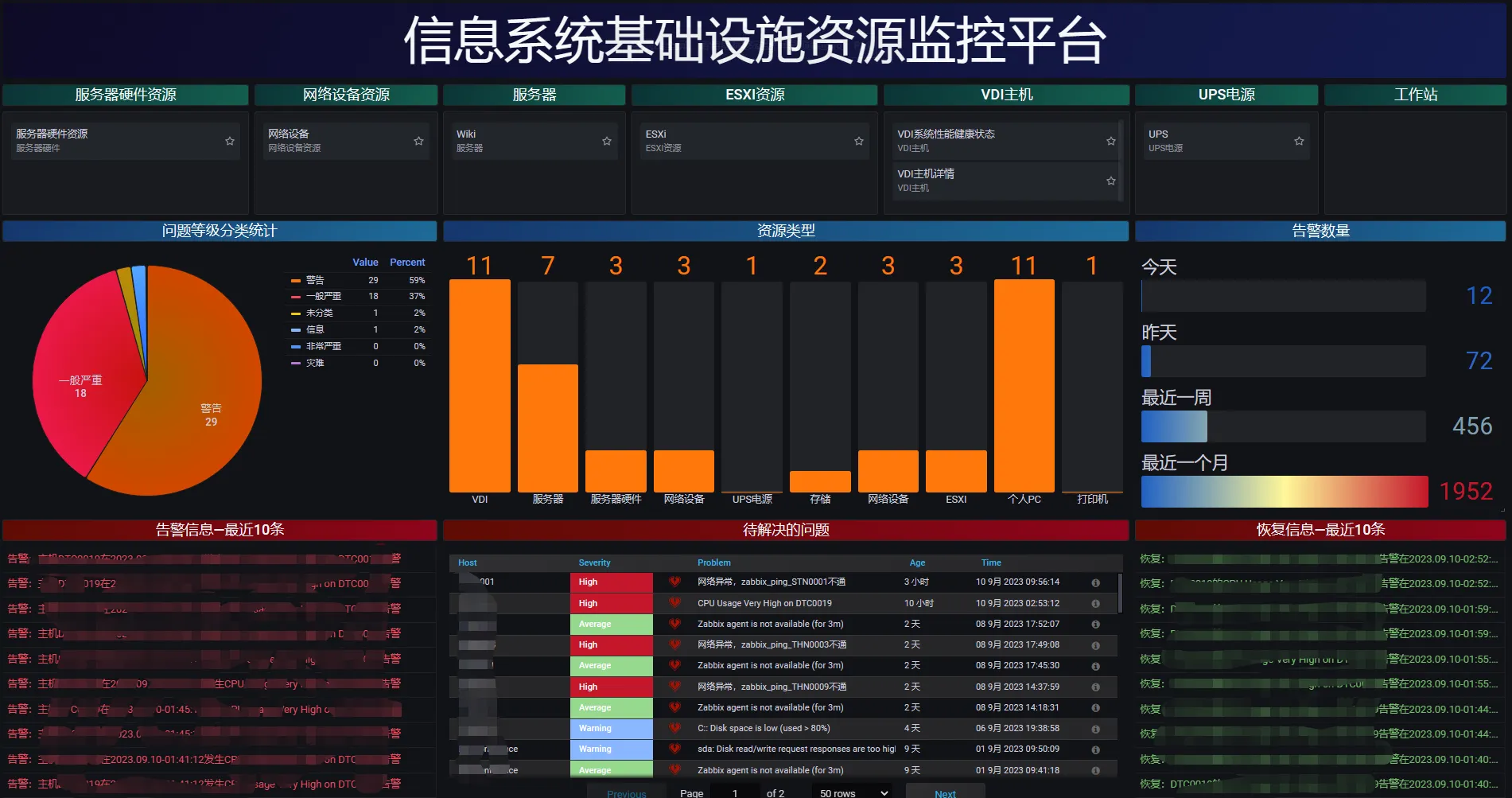
案例背景
房价影响因素也是人们一直关注的问题,本次案例也适合各种学科的同学,无论你是经济管理类还是数学统计,还是电商物流类,都可以使用回归分析。通过数据分析回归分析分组聚合可视化等方法进行研究房价影响因素。
数据介绍
本次案例数据如上,小区名称可以没什么用,当然要做特征工程也是可以用nlp的技术抽取特征的。总价=面积*单价,但是我们这次分析的因变量y就用单价好了,毕竟看房价都是看单价。
需要本次演示案例数据和全部代码文件的同学可以参考:二手房数据
代码实现
还是先导入数据分析常用的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import OneHotEncoder
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号读取数据,查看前五行
df=pd.read_csv('house.csv').drop('Unnamed: 0',axis=1).dropna().reset_index(drop=True)
df.head()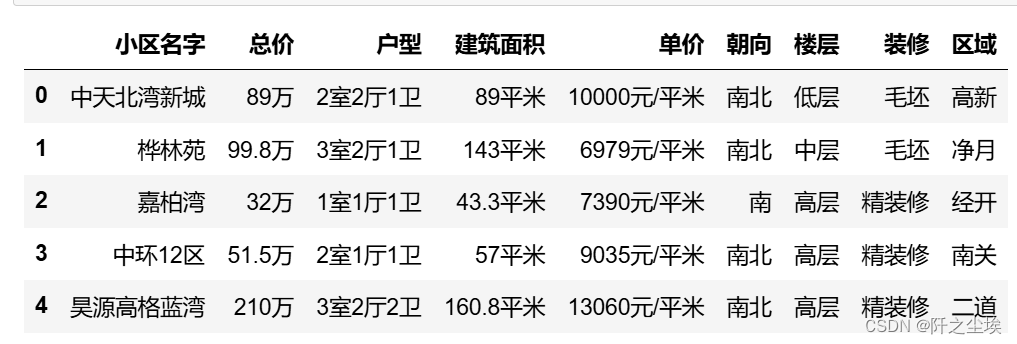
查看数据基础信息
df.info()
9列变量,2551个样本,没有缺失值。
简单描述性统计
df.describe()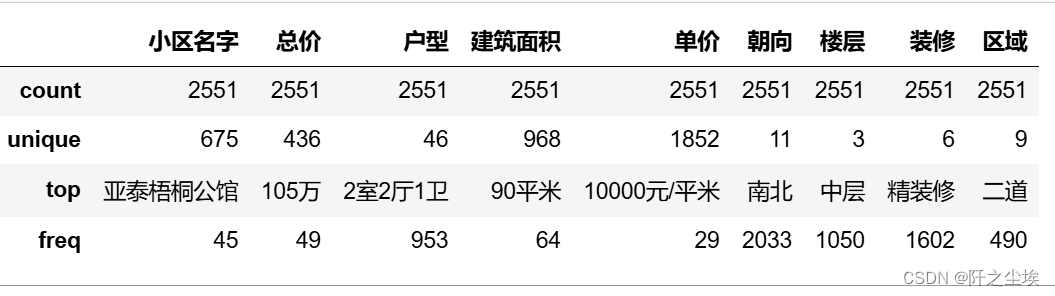
根据提供的描述性统计数据,我们可以进一步分析各列数据的特征和分布:
小区名字:数据共有2551行,其中有675个唯一的小区名字。
频率最高的小区名字是“亚泰梧桐公馆”,出现了45次。
总价:总价列有2551个值,没有缺失数据。
数据范围可能涵盖了105万至其他值,需要进一步检查可能的异常值。
户型:共有436种不同的户型。
最常见的户型是“2室2厅1卫”,出现了49次。
建筑面积:建筑面积列包含46个不同的数值。
最常见的建筑面积是90平方米,出现了953次。
单价:单价列有968个不同的数值。
频率最高的单价为10000元/平米,出现了64次。
朝向:朝向列有1852个不同的取值。
南北朝向出现频率最高,出现了29次。
楼层:楼层列有11个不同的分类。
中层是最常见的楼层,出现了2033次。
装修:装修类型列有3种不同的取值。
精装修是最常见的装修类型,出现了1050次。
区域:区域列有9个不同的区域。
“二道”是最常见的区域,出现了490次。
基于以上描述性统计数据,可以看出各列数据的分布情况。进一步的分析可以包括绘制直方图、箱线图等可视化工具,以更全面地了解数据的特征和可能存在的异常情况。
数据清洗
由于上面的数据基本都是文本型的,需要变成数值型数据,要进行一定的清洗,例如价格后面的“万”,面积后面的“平米”都要去掉。
我把['室', '厅', '卫']分为了三个变量
df_or=df.copy()
df_or[['室', '厅', '卫']] = df_or['户型'].str.extract(r'(\d+)室(\d+)厅(\d+)卫')
df_or[['室', '厅', '卫']] = df_or[['室', '厅', '卫']].fillna(0).astype(int)
df_or.drop(columns=['户型'], inplace=True)
# 2. 将“建筑面积”去掉“平米”并转为数值型
df_or['建筑面积'] = df_or['建筑面积'].str.replace('平米', '').astype(float)
# 3. 将“单价”去掉“元/平米”并转为数值型
df_or['单价'] = df_or['单价'].str.replace('元/平米', '').astype(int)
df_or['总价'] = df_or['总价'].str.replace('万', '').astype(float)继续清洗
# 1. 拆分户型为三个变量(室、厅、卫)
# 1. 拆分户型为三个变量(室、厅、卫)
df[['室', '厅', '卫']] = df['户型'].str.extract(r'(\d+)室(\d+)厅(\d+)卫')
df[['室', '厅', '卫']] = df[['室', '厅', '卫']].fillna(0).astype(int)
df.drop(columns=['户型'], inplace=True)
# 2. 将“建筑面积”去掉“平米”并转为数值型
df['建筑面积'] = df['建筑面积'].str.replace('平米', '').astype(float)
# 3. 将“单价”去掉“元/平米”并转为数值型
df['单价'] = df['单价'].str.replace('元/平米', '').astype(int)
df['总价'] = df['总价'].str.replace('万', '').astype(float)
# 4. 对“朝向”、“楼层”、“装修”、“区域”列进行独热编码
df['朝向'], 朝向_unique = pd.factorize(df['朝向'])
df['楼层'], 楼层_unique = pd.factorize(df['楼层'])
df['装修'], 装修_unique = pd.factorize(df['装修'])
df['区域'], 区域_unique = pd.factorize(df['区域'])
df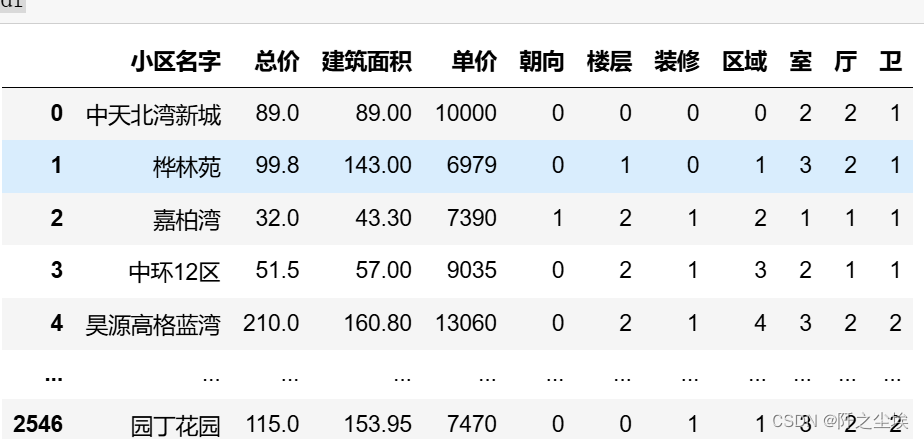
可以看到除了小区名字,基本都是数值型的数据了。查看一下数据的信息
df.info()
下面可以进行分析了。
数据分析
描述性统计
df.describe()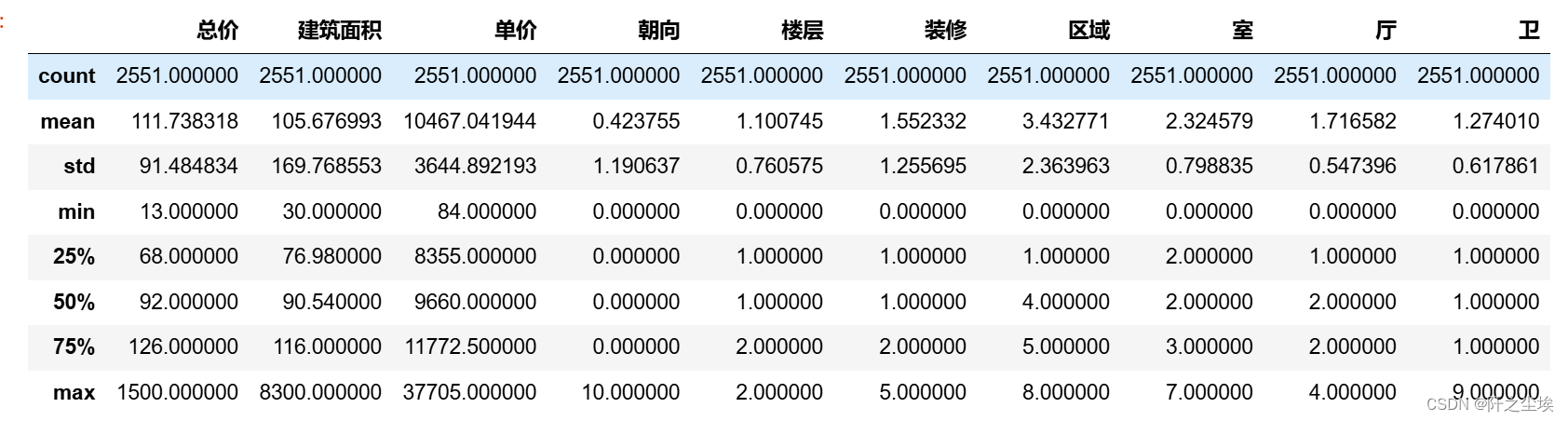
都是常见的统计量,就不多说了。
类别变量画图
对['朝向','楼层','装修','区域']这几个变量的类别数量进行可视化
# Select non-numeric columns
non_numeric_columns = df_or[['朝向','楼层','装修','区域']].columns
f, axes = plt.subplots(2, 2, figsize=(8,6),dpi=128)
# Flatten axes for easy iterating
axes_flat = axes.flatten()
for i, column in enumerate(non_numeric_columns):
if i < 8:
sns.countplot(x=column, data=df_or, ax=axes_flat[i])
axes_flat[i].set_title(f'{column}')
for label in axes_flat[i].get_xticklabels():
label.set_rotation(90) #类别标签旋转一下,免得多了堆叠看不清
# Hide any unused subplots
for j in range(i + 1, 4):
f.delaxes(axes_flat[j])
plt.tight_layout()
plt.show()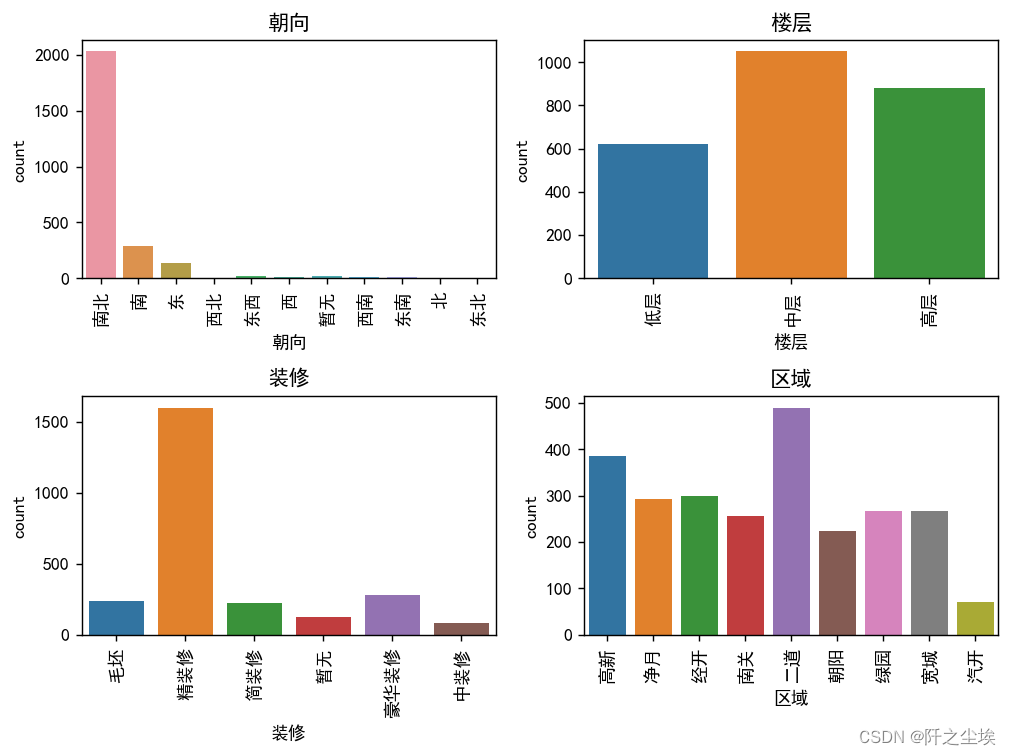
数值型变量画图
对['建筑面积','单价','总价','室','厅','卫']这几个数值型变量画核密度图观察分布
#画密度图,
num_columns = df[['建筑面积','单价','总价','室','厅','卫']].columns.tolist() # 列表头
dis_cols = 3 #一行几个
dis_rows = len(num_columns)
plt.figure(figsize=(3 * dis_cols, 2 * dis_rows),dpi=256)
for i in range(len(num_columns)):
ax = plt.subplot(dis_rows, dis_cols, i+1)
ax = sns.kdeplot(df[num_columns[i]], color="skyblue" ,fill=True)
ax.set_xlabel(num_columns[i],fontsize = 14)
plt.tight_layout()
#plt.savefig('训练测试特征变量核密度图',formate='png',dpi=500)
plt.show()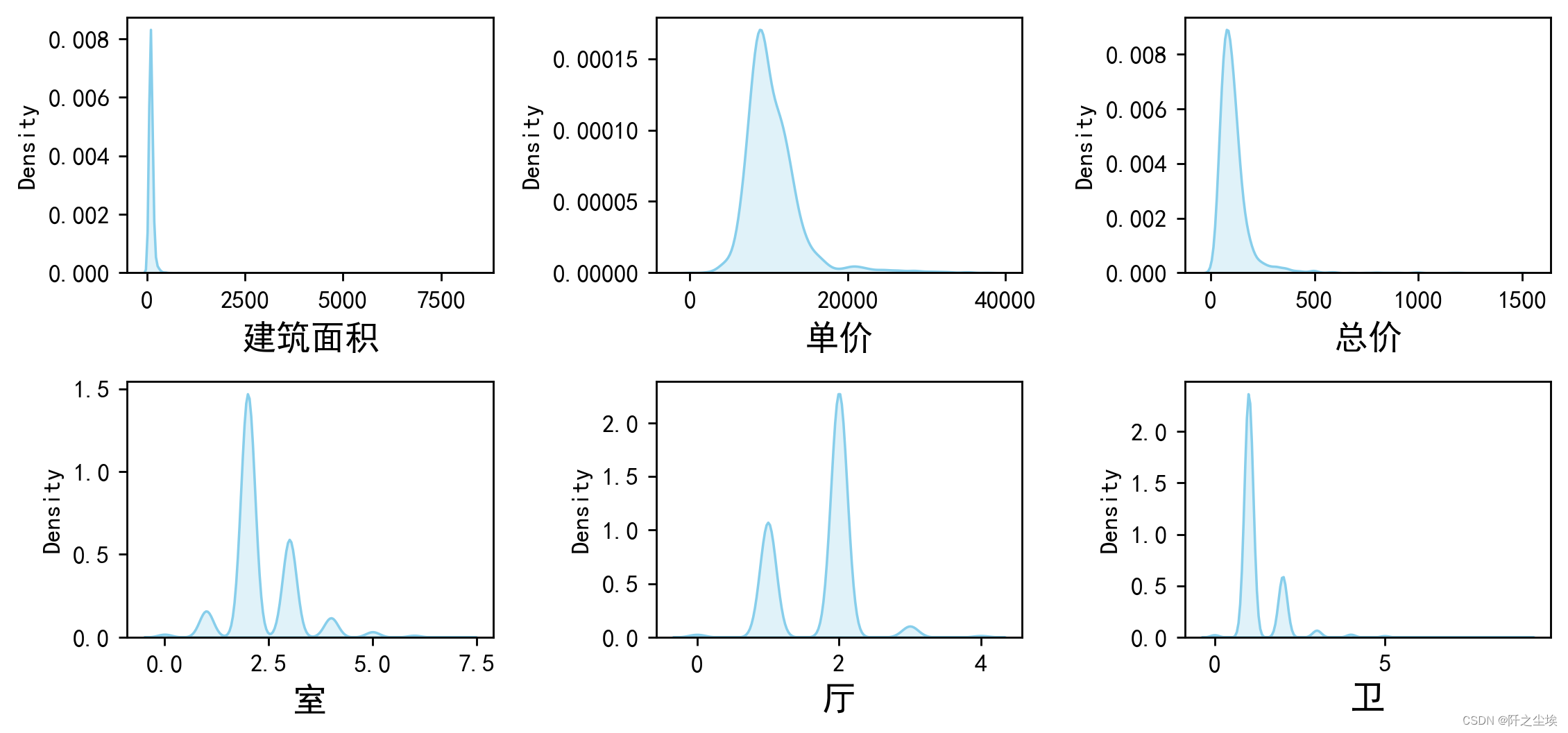
不同变量之间的分组聚合
研究不同的 装修,楼层,区域的单价的均值和分布
df_or.groupby(['装修'])['单价'].mean()
df_or.groupby(['楼层'])['单价'].mean()
df_or.groupby(['区域'])['单价'].mean()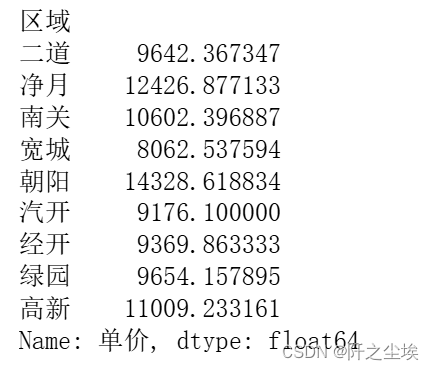
对不同维度下(装修、楼层、区域)房屋单价的均值进行分析
-
按装修程度分类的房屋单价均值 装修程度 单价(元/平方米) 中装修 10494.13 暂无装修 11903.98 毛坯 9989.28 简装修 10996.11 精装修 10145.40 豪华装修 11634.47
-
分析: 最高单价:暂无装修的房屋单价最高,为11903.98元/平方米。这可能是因为这些房屋可能处于特殊情况,比如未完工的高端项目。 次高单价:豪华装修的房屋单价为11634.47元/平方米,显著高于其他装修程度的房屋。 最低单价:毛坯房的单价最低,为9989.28元/平方米,这符合预期,因为毛坯房没有任何装修。 其他装修程度:中装修、简装修和精装修的房屋单价分别为10494.13、10996.11和10145.40元/平方米,表明装修水平对房屋单价有一定的影响,但幅度不如豪华装修和毛坯房显著。
-
按楼层分类的房屋单价均值 楼层 单价(元/平方米) 中层 10001.36 低层 11519.83 高层 10278.34
-
分析: 最高单价:低层房屋的单价最高,为11519.83元/平方米。这可能表明低层房屋在某些情况下更受市场欢迎,或其周围环境和便利设施更好。 次高单价:高层房屋的单价为10278.34元/平方米,略高于中层房屋。 最低单价:中层房屋的单价最低,为10001.36元/平方米。 楼层对单价的影响:尽管中层和高层房屋的单价相差不大,但低层房屋明显更高,这可能与市场需求或特定区域的开发方式有关。
-
按区域分类的房屋单价均值 区域 单价(元/平方米) 二道 9642.37 净月 12426.88 南关 10602.40 宽城 8062.54 朝阳 14328.62 汽开 9176.10 经开 9369.86 绿园 9654.16 高新 11009.23
-
分析: 最高单价:朝阳区域的房屋单价最高,为14328.62元/平方米,表明该区域可能是一个高端住宅区或商业繁荣区。 次高单价:净月区域的房屋单价次高,为12426.88元/平方米,也显示出较高的市场价值。 最低单价:宽城区域的房屋单价最低,为8062.54元/平方米,可能是因为该区域的经济发展较慢或配套设施较少。 其他区域:高新、南关和绿园的房屋单价分别为11009.23、10602.40和9654.16元/平方米,显示出中等市场价值。 区域对单价的影响:房屋单价在不同区域差异显著,这可能与区域的经济发展水平、配套设施、交通便利性等因素密切相关。
-
总结 装修程度:装修对房屋单价有显著影响,其中豪华装修和暂无装修(可能是未完工项目)房屋的单价最高,毛坯房的单价最低。 楼层:低层房屋的单价最高,可能与市场偏好有关。中层房屋的单价最低,但与高层房屋差距不大。 区域:房屋单价在不同区域有显著差异,朝阳和净月区域的房屋单价最高,宽城区域单价最低。区域的经济发展水平和配套设施可能是主要影响因素。
上面这些只是计算了均值,下面查看上面这些变量的总体的分布的可视化,
小提琴图不仅可以看到变量的均值方差,还可以看到数据的分布:
##画小提琴图查看分布
fig, axes = plt.subplots(3, 1, figsize=(7, 8),dpi=128)
# 绘制装修的小提琴图
sns.violinplot(ax=axes[0], x='装修', y='单价', data=df_or)
axes[0].set_title('不同装修的单价分布')
axes[0].set_xlabel('装修')
axes[0].set_ylabel('单价')
# 绘制楼层的小提琴图
sns.violinplot(ax=axes[1], x='楼层', y='单价', data=df_or)
axes[1].set_title('不同楼层的单价分布')
axes[1].set_xlabel('楼层')
axes[1].set_ylabel('单价')
# 绘制区域的小提琴图
sns.violinplot(ax=axes[2], x='区域', y='单价', data=df_or)
axes[2].set_title('不同区域的单价分布')
axes[2].set_xlabel('区域')
axes[2].set_ylabel('单价')
# 调整子图之间的间距
plt.tight_layout()
# 显示图形
plt.show()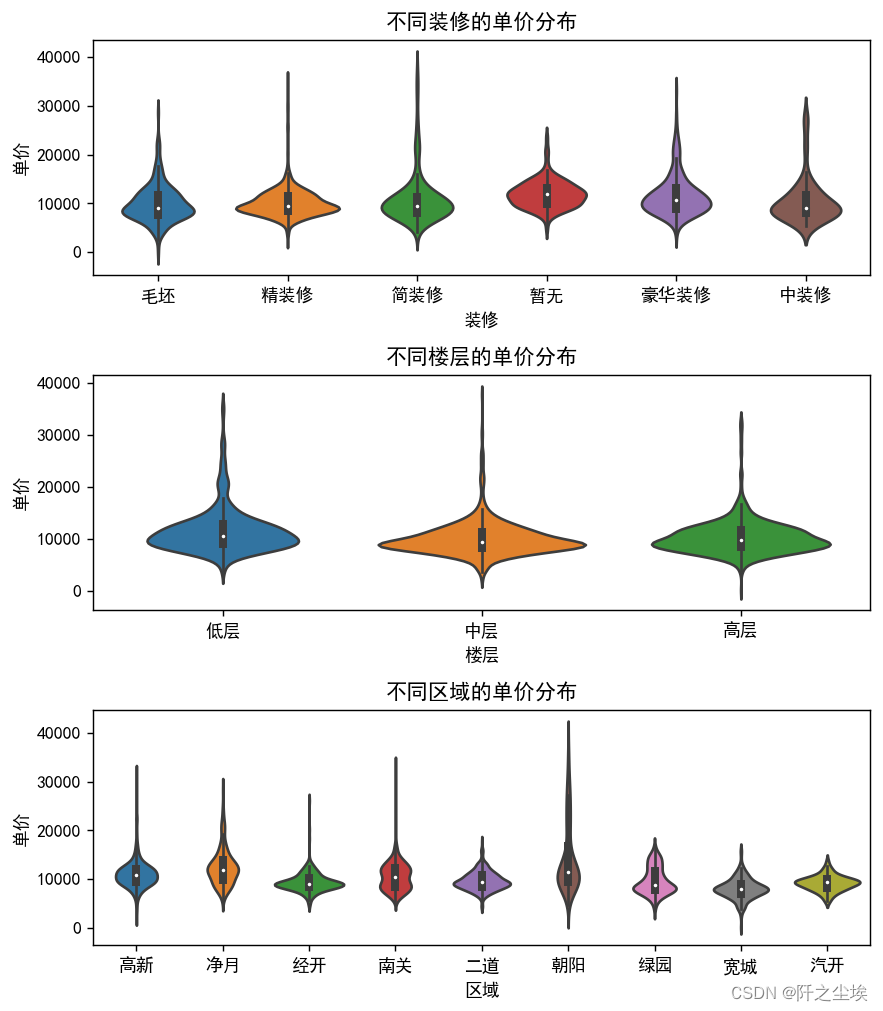
对于不同的装修风格来说,没有装修的价格分布比较集中,其他的简装修,豪华装修的价格分布较为分散,他们的不同房子价格差异很大。
不同楼层分布来说,中层楼房价格便宜,分布集中,低层楼房较贵,分布较为分散
对于不同地区来说,经开二道和气开三个地区的房子单价分布较为集中,说明他们的价格变化差异不大,南关,朝阳等地区的房子价格分布较为分散,说明这几个地区的房子的价格差异较大。
研究室厅卫和总价的关系
直接把室厅卫的不同取值下的总价画图
fig, axes = plt.subplots(1, 3, figsize=(12, 5),dpi=128)
# 绘制室与单价的散点图
sns.scatterplot(ax=axes[0], x='室', y='总价', data=df_or,c=df_or['室'])
axes[0].set_title('室与总价的关系')
axes[0].set_xlabel('室')
axes[0].set_ylabel('总价')
# 绘制厅与单价的散点图
sns.scatterplot(ax=axes[1], x='厅', y='总价', data=df_or,c=df_or['厅'],cmap='plasma')
axes[1].set_title('厅与总价的关系')
axes[1].set_xlabel('厅')
axes[1].set_ylabel('总价')
# 绘制卫与单价的散点图
sns.scatterplot(ax=axes[2], x='卫', y='总价', data=df_or,c=df_or['卫'],cmap='brg_r')
axes[2].set_title('卫与总价的关系')
axes[2].set_xlabel('卫')
axes[2].set_ylabel('总价')
# 调整子图之间的间距
plt.tight_layout()
很明显正相关,即房子的室厅卫越多越贵
相关系数分析
画出变量之间的相关性系数热力图
corr = plt.subplots(figsize = (10,8),dpi=128)
corr= sns.heatmap(df.corr(),annot=True,square=True)
#plt.savefig('训练集特征热力图.png',dpi=512)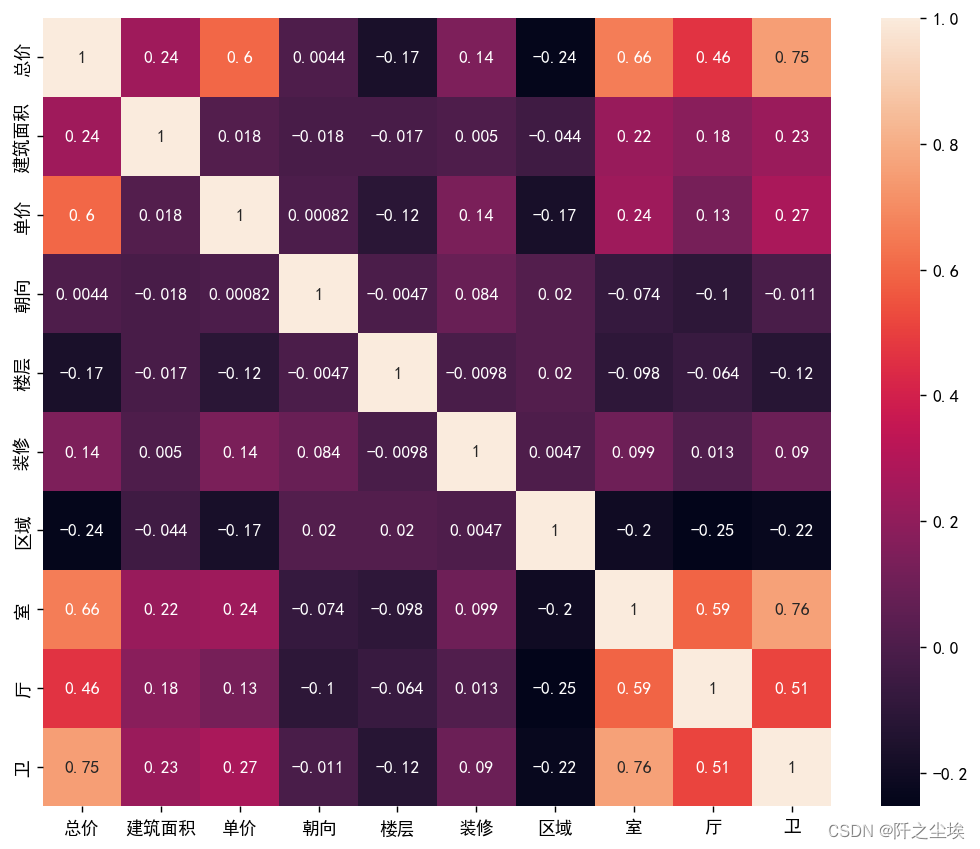
总价与单价之间的相关性较强(0.600),这表明房屋总价与其每平方米的价格有显著的正相关关系。 总价与房间数、厅数和卫生间数的相关性也较强(分别为0.661、0.463和0.751),这意味着房屋的总价在很大程度上受到这些因素的影响。
详细分析:
总价与其他变量: 建筑面积(0.245):总价与建筑面积有弱正相关性,意味着房屋总价随着建筑面积的增加而增加,但相关性不是特别强。 单价(0.600):单价与总价有较强的正相关性,表明房屋单价提高,总价也会相应提高。 朝向(0.004):总价与朝向几乎没有相关性,表明朝向对房屋总价影响很小。 楼层(-0.166):总价与楼层有负相关性,表明楼层越高,总价可能越低,但这种关系相对较弱。 装修(0.145):总价与装修有弱正相关性,表明装修水平较高的房屋总价也相对较高。 区域(-0.242):总价与区域有负相关性,表明某些区域的房屋总价相对较低。 室(0.662)、厅(0.463)、卫(0.751):这些变量与总价有较强的正相关性,房间数、厅数和卫生间数越多,总价越高。
单价与其他变量: 建筑面积(0.018):单价与建筑面积几乎没有相关性,表明建筑面积对单价的影响不显著。 朝向(0.001):单价与朝向几乎没有相关性。 楼层(-0.116):单价与楼层有弱负相关性,表明楼层较高的房屋单价略低。 装修(0.136):单价与装修有弱正相关性,表明装修较好的房屋单价略高。 区域(-0.172):单价与区域有弱负相关性,表明某些区域的房屋单价较低。 室(0.239):单价与房间数有弱正相关性。 厅(0.126):单价与厅数有弱正相关性。 卫(0.275):单价与卫生间数有弱正相关性。
自变量之间的相关性: 建筑面积与室(0.223)、厅(0.180)和卫(0.229):建筑面积与房间数、厅数和卫生间数有弱正相关性,表明面积较大的房屋通常会有更多的房间、厅和卫生间。 室与厅(0.592)、卫(0.762):房间数与厅数、卫生间数之间有中到强的正相关性,表明房间数多的房屋通常也有更多的厅和卫生间。 厅与卫(0.511):厅数与卫生间数之间有中等强度的正相关性。
结论: 房屋总价的主要影响因素: 房屋总价主要受到单价、房间数、厅数和卫生间数的影响,这些变量之间的相关性较强。
单价的影响因素: 单价的影响因素包括装修、区域、房间数和卫生间数,但相关性相对较弱。
区域的影响: 区域与总价和单价都有负相关性,表明某些区域的房屋价格较低,这可能与区域的地理位置、经济发展水平等因素有关。
装修的影响: 装修对单价和总价都有正向影响,但相关性较弱,说明较高的装修水平可以提升房屋价格。
需要进一步研究的方面: 尽管某些变量之间的相关性较弱,但它们可能仍对房价有重要影响。此外,可能存在潜在的交互效应,需要更复杂的模型进行进一步分析。
回归分析
下面对房价的这些变量进行线性回归的分析,
线性模型解释性强,所以很多同学无论是哪个专业或者背景都是可以使用的。
下面取出X和y,然后使用skleran库的线性回归器进行模型训练,简单看一下模型的性能。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
y = df['单价'] # 目标变量
X = df.drop(columns=['小区名字', '总价','单价']) # 特征变量
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型性能
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
print(f'R^2 Score: {r2}')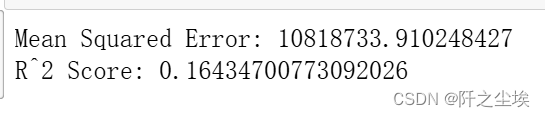
拟合的误差较大,毕竟是划分了训练集和测试集的。
# 打印模型系数
coefficients = pd.DataFrame(model.coef_, X.columns, columns=['Coefficient'])
print(coefficients)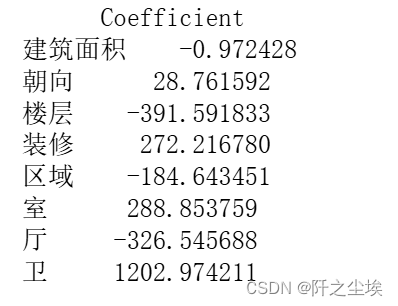
查看推断统计的结果和情况
import statsmodels.api as sm
# 添加常数项
X = sm.add_constant(X)
# 训练线性回归模型
model = sm.OLS(y, X).fit()
# 展示详细的回归结果
print(model.summary())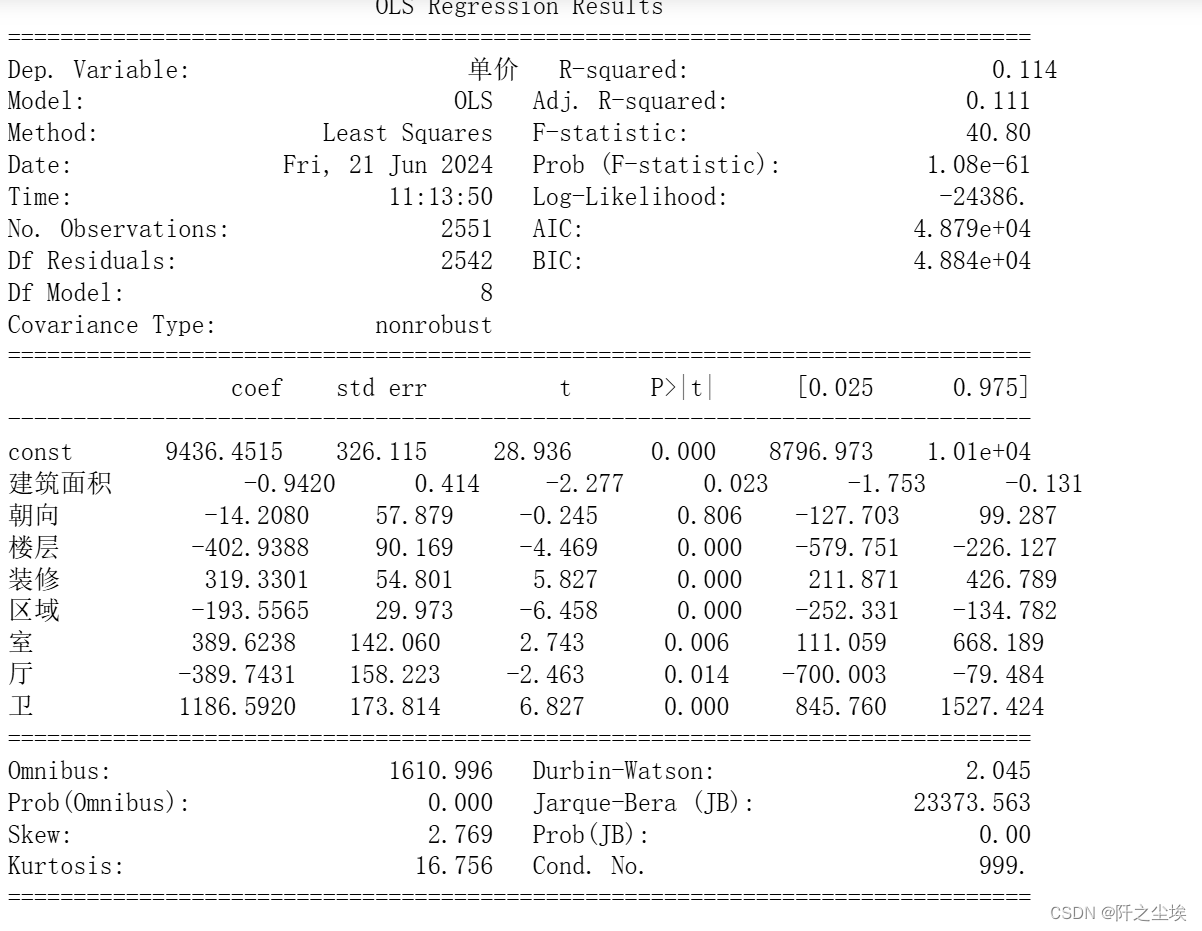
回归结果概要 因变量:单价 R-squared(R²):0.114,表示模型能够解释11.4%的因变量(单价)变异。 Adj. R-squared(调整后的R²):0.111,考虑了模型复杂度后的解释力。 F-statistic:40.80,表示模型整体显著性,P值为1.08e-61,显著性水平极高。 样本数量:2551 AIC/BIC:AIC和BIC值用于模型选择,数值越低越好。
回归系数与解释 常数项(const): 系数:9436.4515 解释:当所有自变量取值为0时,单价的基准值为9436.45。 建筑面积(建筑面积): 系数:-0.9420 解释:建筑面积每增加一单位,单价平均减少0.94。 显著性:0.023,显著。 朝向(朝向): 系数:-14.2080 解释:朝向每变化一个单位,单价平均减少14.21。 显著性:0.806,不显著。 楼层(楼层): 系数:-402.9388 解释:楼层每增加一个单位,单价平均减少402.94。 显著性:0.000,显著。 装修(装修): 系数:319.3301 解释:装修每提高一个单位,单价平均增加319.33。 显著性:0.000,显著。 区域(区域): 系数:-193.5565 解释:区域每变化一个单位,单价平均减少193.56。 显著性:0.000,显著。 室(室): 系数:389.6238 解释:房间数每增加一个单位,单价平均增加389.62。 显著性:0.006,显著。 厅(厅): 系数:-389.7431 解释:厅数每增加一个单位,单价平均减少389.74。 显著性:0.014,显著。 卫(卫): 系数:1186.5920 解释:卫数每增加一个单位,单价平均增加1186.59。 显著性:0.000,显著。
模型整体检验 R-squared与Adj. R-squared:
模型的R²值为0.114,调整后的R²值为0.111,表明自变量只能解释11.4%的因变量变异,模型解释力有限。 F-statistic与Prob(F-statistic):
F统计量值为40.80,对应的P值远小于0.05,说明整体模型显著。
Durbin-Watson: Durbin-Watson统计量值为2.045,接近2,表明模型残差不存在显著的自相关性。 Omnibus与Jarque-Bera:
Omnibus值和Jarque-Bera值表明该模型的残差分布偏离正态性(高偏度和峰度)。 系数显著性分析
显著性显著的变量: 建筑面积、楼层、装修、区域、室、厅、卫在0.05显著性水平下显著。
不显著变量: 朝向在0.05显著性水平下不显著。
结论 :显著变量的影响: 建筑面积:建筑面积增加对单价有微弱的负面影响。 楼层:楼层增加显著降低单价。 装修:装修水平提高显著增加单价。 区域:所处区域显著影响单价,不同区域单价差异明显。 室:房间数量增加显著提高单价。 厅:厅数增加显著降低单价。 卫:卫生间数量增加显著提高单价。 模型的解释力有限:
模型的解释力较低(R²值仅为0.114),说明还有很多未包含在模型中的重要因素影响单价。 需要进一步探索的方面:
可以尝试引入更多可能影响单价的变量,如交通便利性、周边配套设施、学区等,以提高模型的解释力。 重新编码不显著的变量(如朝向),或者探索其与其他变量的交互效应。
最后再把测试集的预测值和真实值画个个对比图
##实际值 vs 预测值对比
plt.figure(figsize=(10, 6))
plt.scatter(range(len(y_test)), y_test, color='skyblue', label='实际值')
plt.scatter(range(len(y_pred)), y_pred, color='tomato', label='预测值')
#plt.xlabel('序列号')
plt.ylabel('单价')
plt.title('实际值 vs 预测值')
plt.legend()
plt.show()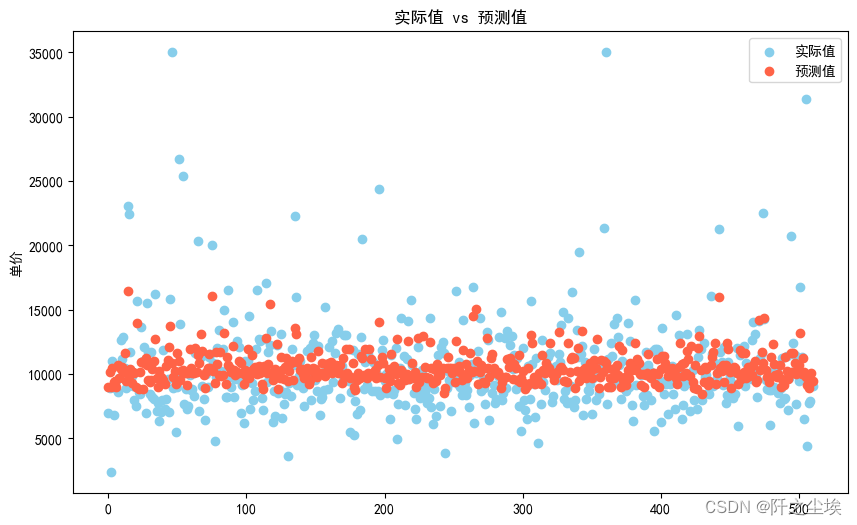
可以看到预测值还是分布集中一点,真实值较为分散,方差较大,异常值较多,可能也是为什么线性模型预测能力一般的原因。
如果追求预测效果的话就应该用随机森林,梯度提升等模型。线性模型主要是解释性强。可以明显得到那些变量相关哪些不相关。
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似的代码可私信)