作者:来自 Elastic Joe McElroy, Serena Chou

什么是 Playground(实验场)?
我们很高兴发布我们的 Playground 体验 —- 一个低代码界面,开发人员可以在几分钟内使用自己的私人数据探索他们选择的 LLM。
在对对话式搜索进行原型设计时,快速迭代和试验 RAG 工作流的关键组件(例如:混合搜索或添加重新排名)的能力非常重要 —- 以便从 LLMs 获得准确且无幻觉的响应。
Elasticsearch 向量数据库和 Search AI 平台为开发人员提供了广泛的功能,例如全面的混合搜索,以及使用来自越来越多的 LLM 提供商的创新。我们在 Playground 体验中的方法允许你使用这些功能的强大功能,而不会增加复杂性。
A/B 测试 LLMs 并选择不同的推理提供商
Playground 的直观界面允许你对来自模型提供商(如 OpenAI 和 Anthropic)的不同 LLM 进行 A/B 测试并改进你的检索机制,以便使用你自己的数据(索引到一个或多个 Elasticsearch 索引中)来获得答案。Playground 体验可以直接在 Elasticsearch 中利用转换器模型,但也可以通过 Elasticsearch Open Inference API 进行扩展,该 API 与越来越多的推理提供商集成,包括 Cohere 和 Azure AI Studio。
带有检索器(retrievers)和混合搜索的最佳上下文窗口
正如 Elasticsearch 开发人员已经知道的那样,最佳上下文窗口是使用混合搜索构建的。你为实现此结果而构建的策略需要访问多种形式的向量化和纯文本数据,这些数据可以分块并分布在多个索引中。
我们正在帮助你使用新引入的 query retrievers 简化查询构建以搜索所有内容!借助三个关键检索器(现已在 8.14 和 Elastic Cloud Serverless 中提供),使用 RRF 规范化分数的混合搜索只需一个统一查询即可完成。使用检索器,playground 可以了解所选数据的形状,并会自动为你生成统一查询。存储向量化数据并探索 kNN 检索器,或者通过选择数据添加元数据和上下文以生成混合搜索查询。即将推出的语义重新排名可以轻松合并到你生成的查询中,以实现更高质量的召回率。
一旦你根据生产标准调整和配置了语义搜索,你就可以导出代码,并使用 Python Elasticsearch 语言客户端或 LangChain Python 集成完成应用程序中的体验。
Playground 现已在 Elastic Cloud Serverless 上可用,并且现已在 Elastic Cloud 8.14 中可用。
使用 Playground
可以从 Kibana(Elasticsearch UI)中访问 Playground,方法是从侧面导航栏导航到 “Playground”。
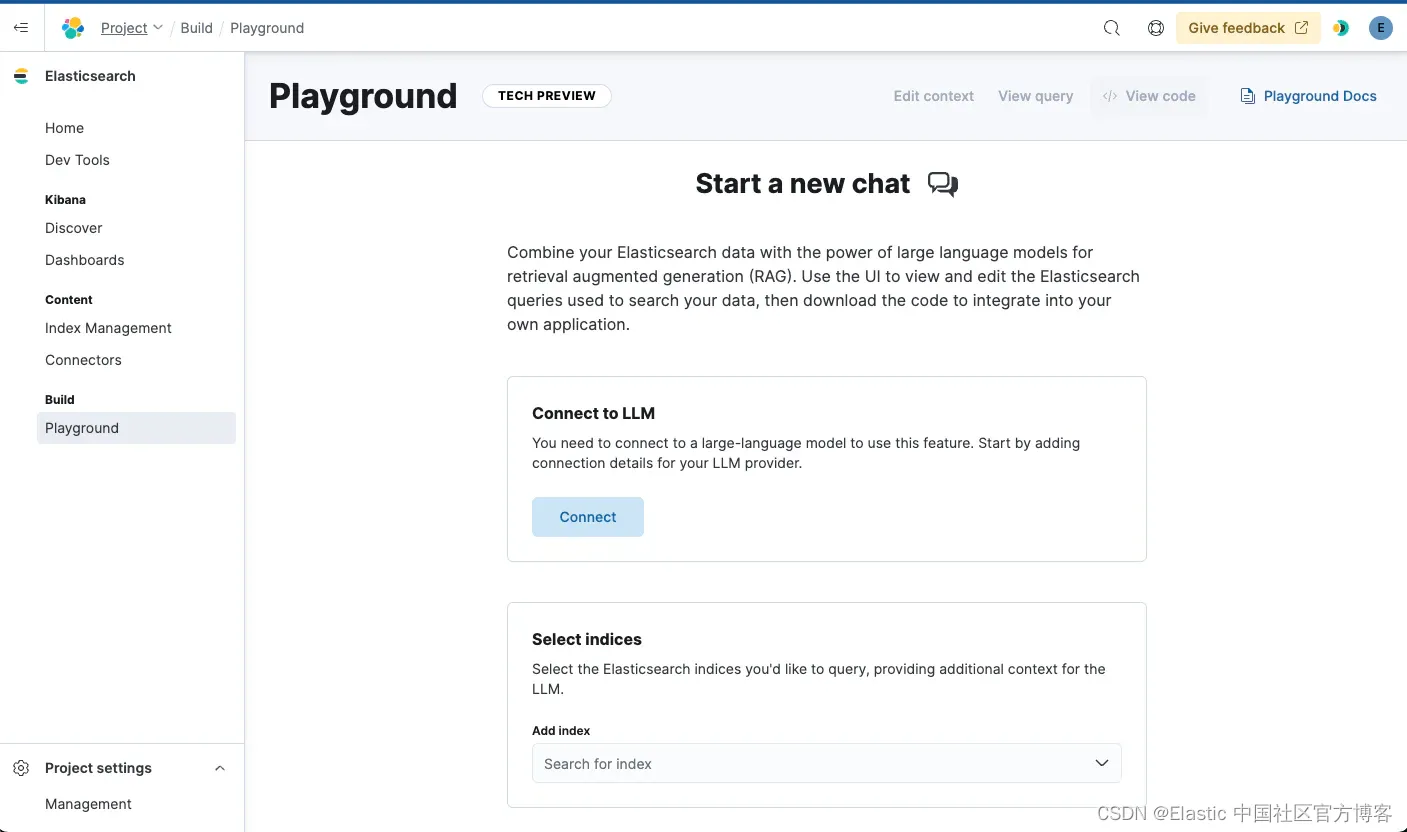
连接到你的 LLM
Playground 支持聊天完成模型,例如来自 OpenAI、Azure OpenAI 或通过 Amazon Bedrock 的 Anthropic 的 GPT-4o。首先,你需要连接到其中一个模型提供商,以获取你选择的 LLM。
与你的数据聊天
可以使用任何数据,甚至基于 BM25 的索引。你可以选择使用文本嵌入模型(如我们的零样本语义搜索模型 ELSER)转换你的数据字段,但这不是必需的。入门非常简单 - 只需选择你想要用来作为答案依据的索引并开始提问即可。在此示例中,我们将使用 PDF 并从使用 BM25 开始,每个文档代表 PDF 的一页。
使用 Python 使用 BM25 索引 PDF 文档
首先,我们安装依赖项。我们使用 pypdf 库读取 PDF 并请求检索它们。
!pip install -qU pypdf requests elasticsearch然后我们读取文件,创建一个包含文本的页面数组。
import PyPDF2
import requests
from io import BytesIO
def download_pdf(url):
response = requests.get(url)
if response.status_code == 200:
return BytesIO(response.content)
else:
print("Failed to download PDF")
return None
def get_pdf_pages(pdf_file):
pages = []
pdf_reader = PyPDF2.PdfReader(pdf_file)
for page in pdf_reader.pages:
text = page.extract_text()
pages.append(text)
return pages
pdf_file = download_pdf("https://arxiv.org/pdf/2103.15348.pdf")
if pdf_file:
pages = get_pdf_pages(pdf_file)
然后我们将其导入 elasticsearch 的 my_pdf_index_bm25 索引下。
from elasticsearch import helpers
client = Elasticsearch(
"<my-cloud-url>",
api_key=ELASTIC_API_KEY,
)
helpers.bulk(
client,
[
{
"_index": "my_pdf_index_bm25",
"_source": {
"text": page,
"page_number": i,
},
}
for i, page in enumerate(pages)
],
request_timeout=60,
)
使用 Playground 与你的数据进行对话
一旦我们将 LLM 与连接器连接并选择索引,我们就可以开始询问有关 PDF 的问题。LLM 现在将轻松为你的数据提供答案。
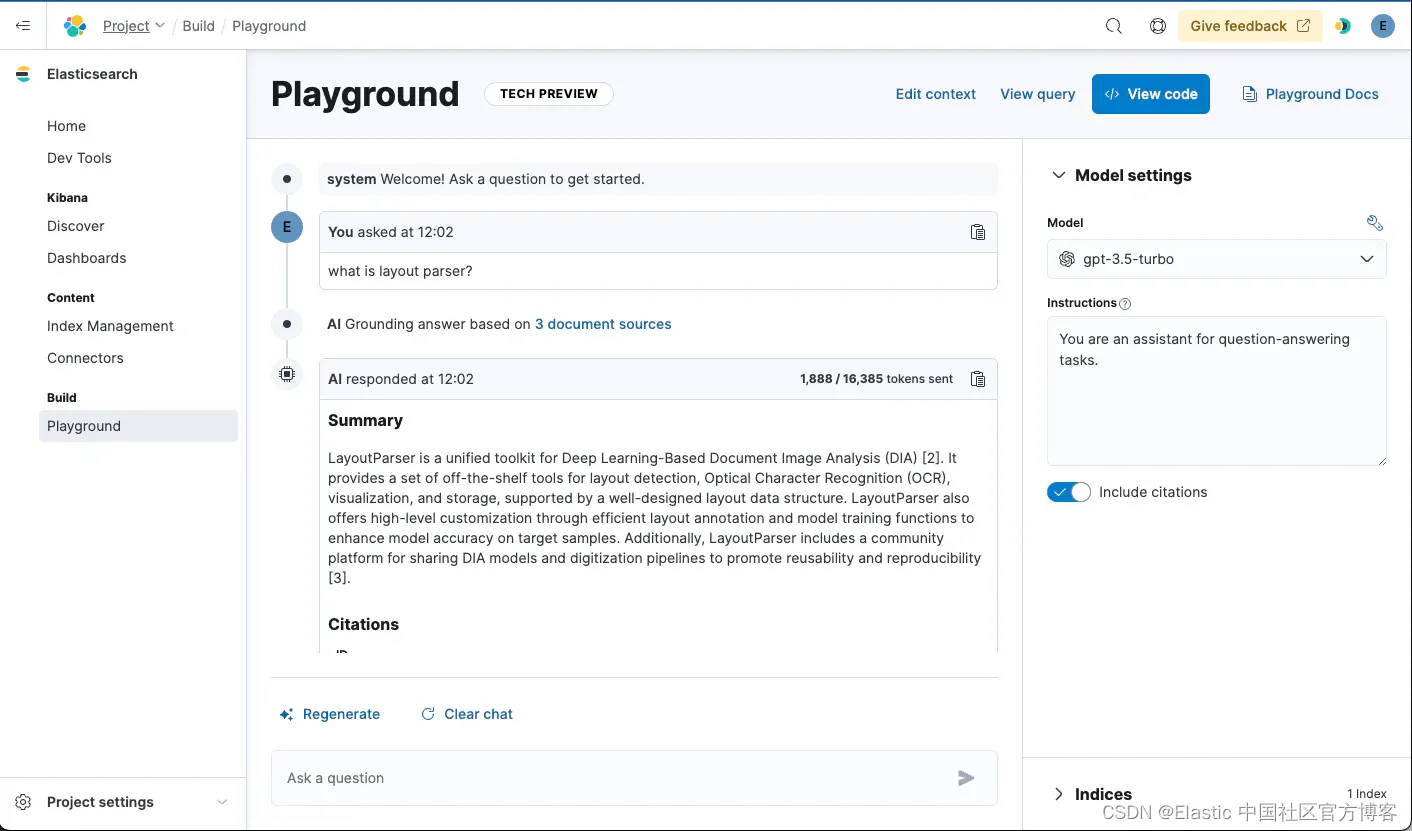
幕后发生了什么?
当我们选择索引时,我们会自动确定最佳检索方法。在这种情况下,仅提供 BM25 关键字搜索,因此我们生成多匹配类型查询来执行检索。

由于我们只有一个字段,因此我们默认搜索该字段。如果你有多个字段,你可以选择要搜索的字段,以改进相关文档的检索。
提出问题
当你提出问题时,Playground 将使用查询执行检索,以查找与你的问题匹配的相关文档。然后,它将以此为上下文并提供提示,为你选择的 LLM 模型返回的答案打下基础。
我们使用文档中的特定字段作为上下文。在此示例中,Playground 选择了名为 “text” 的字段,但可以在 “edit context” 操作中更改此字段。
默认情况下,我们最多检索 3 个文档作为上下文,但你也可以在编辑上下文弹出窗口中调整该数字。
提出后续问题
通常,后续问题与之前的对话有关。考虑到这一点,我们要求 LLM 使用对话将后续问题重写为独立问题,然后将其用于检索。这使我们能够检索更好的文档,以用作帮助回答问题的上下文。
上下文
当根据你的问题找到文档时,我们会将这些文档作为上下文提供给 LLM,以便 LLM 在回答时巩固其知识。我们会自动选择一个我们认为最好的索引字段,但你可以通过编辑上下文弹出窗口来更改此字段。
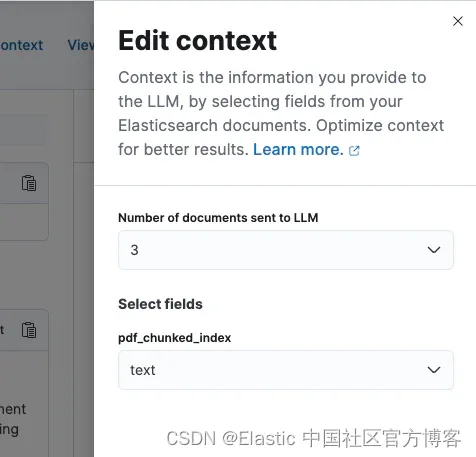
使用语义搜索和分块改进检索
由于我们的查询是问题形式,因此检索能够根据语义进行匹配非常重要。使用 BM25,我们只能匹配词汇上符合我们问题的文档,因此我们还需要添加语义搜索。
使用 ELSER 进行稀疏向量语义搜索
开始语义搜索的一个简单方法是将 Elastic 的 ELSER 稀疏嵌入模型用于我们的数据。与许多这种规模和架构的模型一样,ELSER 具有典型的 512 个 token 限制,并且需要选择适当的分块策略来适应它。在即将推出的 Elasticsearch 版本中,我们将默认分块作为向量化过程的一部分,但在此版本中,我们将遵循按段落分块的策略作为起点。你的数据形状可能会受益于其他分块策略,我们鼓励进行实验以改进检索。
使用 pyPDF 和 LangChain 对 PDF 进行分块和提取
为了简化示例,我们将使用 LangChain 工具加载页面并将其拆分为段落。LangChain 是一种流行的 RAG 开发工具,可以与我们更新的集成集成,并与 Elasticsearch 向量数据库和语义重新排名功能一起使用。
创建 ELSER 推理端点
可以执行以下 REST API 调用来下载、部署和检查模型的运行状态。你可以使用 Kibana 中的开发工具执行这些操作。
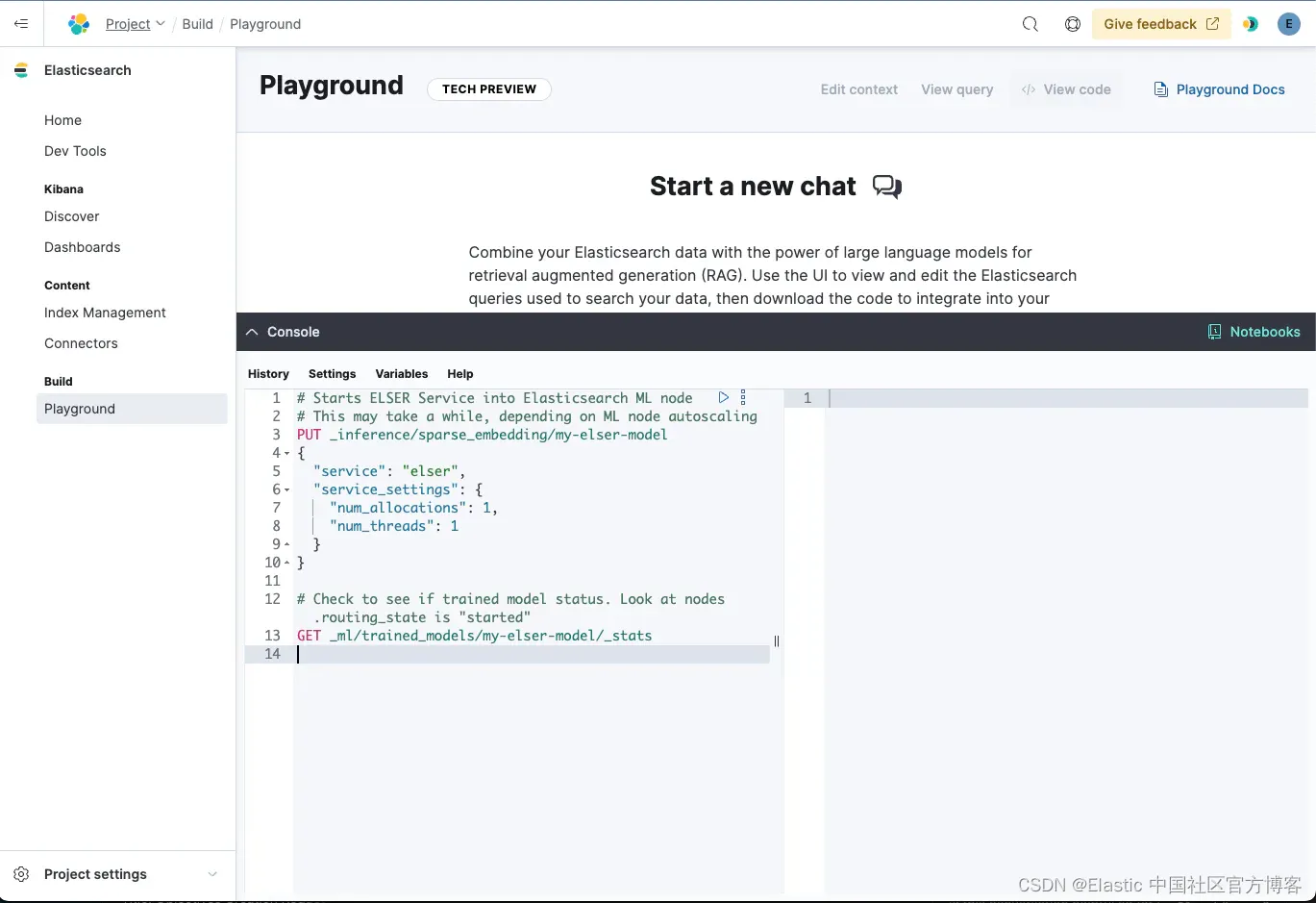
# Starts ELSER Service into Elasticsearch ML node
# This may take a while, depending on ML node autoscaling
PUT _inference/sparse_embedding/my-elser-model
{
"service": "elser",
"service_settings": {
"num_allocations": 1,
"num_threads": 1
}
}
# Check to see if trained model status. Look at nodes.routing_state is "started"
GET _ml/trained_models/my-elser-model/_stats导入 Elasticsearch
接下来,我们将设置一个索引并附加一个管道来为我们处理推理。
# Setup an elser pipeline to embed the contents in text field
# using ELSER into the text_embedding field
PUT /_ingest/pipeline/my-elser-pipeline
{
"processors": [
{
"inference": {
"model_id": "my-elser-model",
"input_output": [
{
"input_field": "text",
"output_field": "text_embedding"
}
]
}
}
]
}
# Setup an index which uses the embedding pipeline
# ready for our documents to be stored in
PUT /elser_index
{
"mappings": {
"properties": {
"text": {
"type": "text"
},
"text_embedding": {
"type": "sparse_vector"
}
}
},
"settings": {
"index": {
"default_pipeline": "my-elser-pipeline"
}
}
}将页面拆分成段落并导入 Elasticsearch
现在 ELSER 模型已经部署完毕,我们可以开始将 PDF 页面拆分成段落并导入 Elasticsearch。
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from elasticsearch import helpers
loader = PyPDFLoader("https://arxiv.org/pdf/2103.15348.pdf")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=256
)
docs = loader.load_and_split(text_splitter=text_splitter)
helpers.bulk(
client,
[
{
"_index": "elser_index",
"_source": {
"text": doc.page_content,
"page_number": i,
},
}
for i, doc in enumerate(docs)
],
request_timeout=60,
)就这样!我们应该将嵌入 ELSER 的段落导入 Elasticsearch。
在 Playground 上查看实际操作
现在,在选择索引时,我们使用 deployment_id 生成基于 ELSER 的查询来嵌入查询字符串。
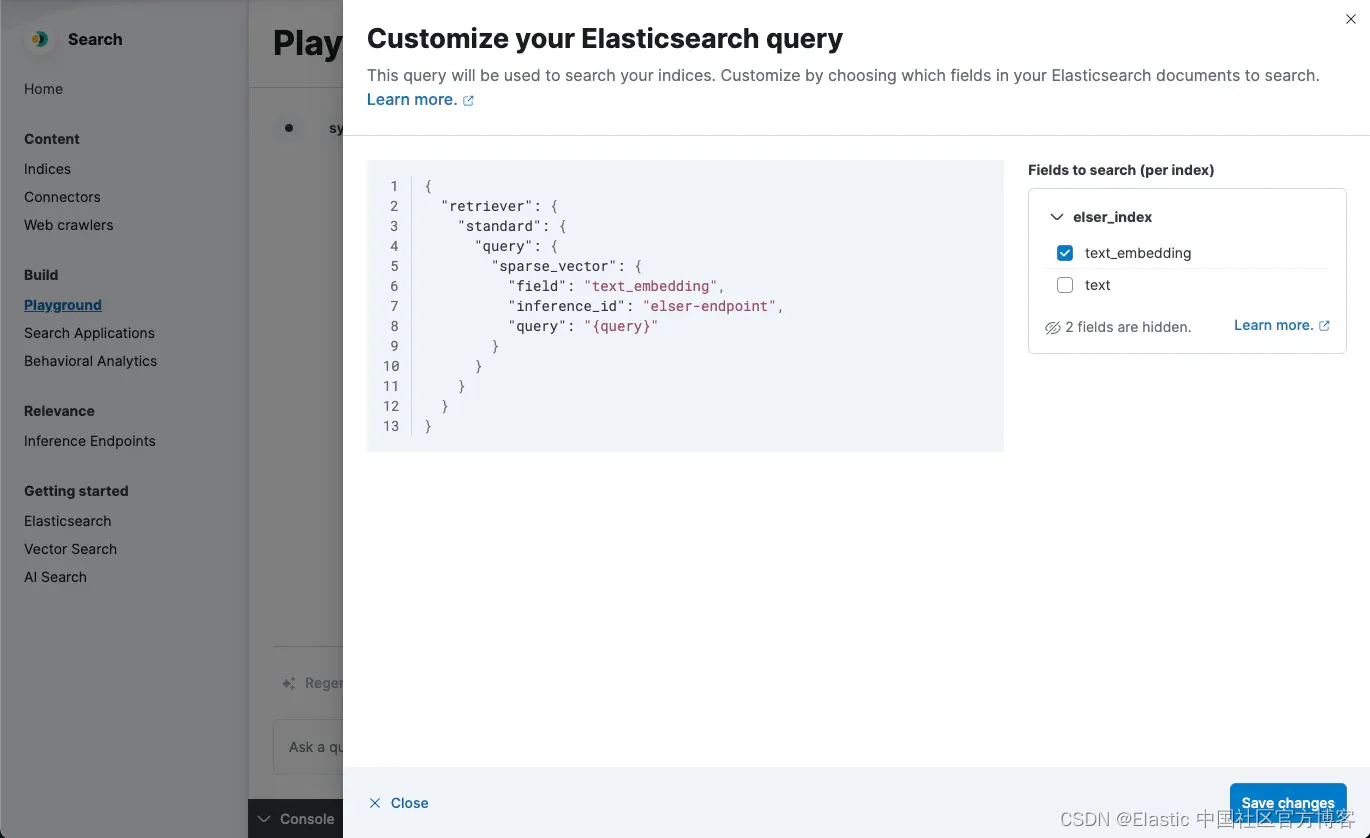
当提出问题时,我们现在有一个语义搜索查询,用于检索与问题语义相匹配的文档。
混合搜索变得简单
启用文本字段也可以启用混合搜索。当我们检索文档时,我们现在会搜索关键字匹配和语义含义,并使用 RRF 算法对两个结果集进行排序。
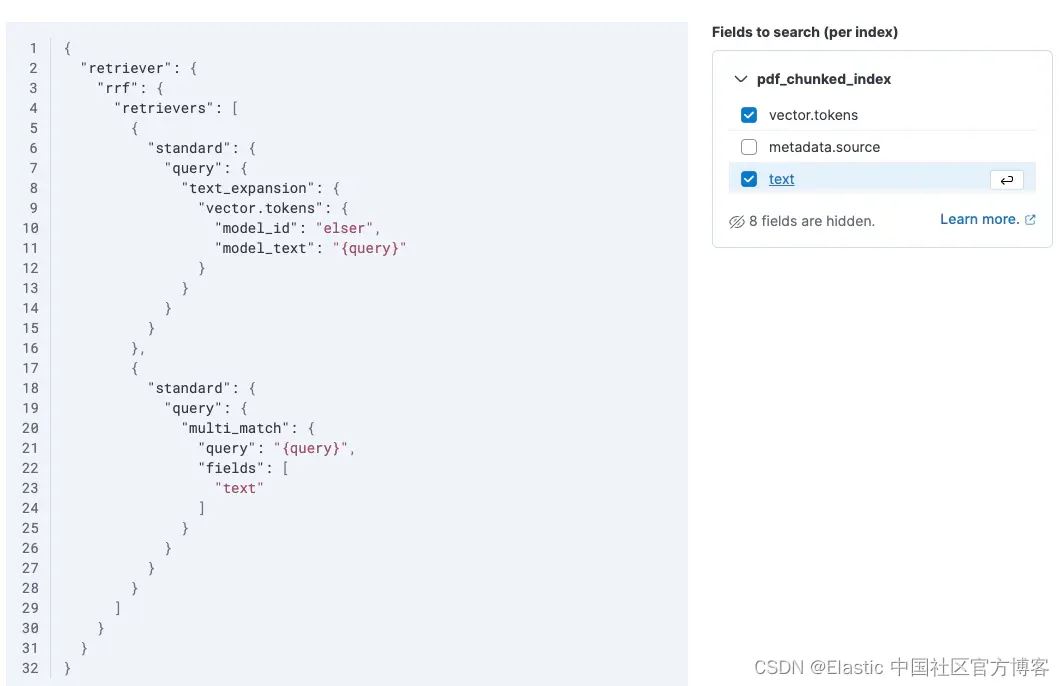
改进 LLM 的答案
使用 Playground,你可以调整提示、调整检索并创建多个索引(分块策略和嵌入模型)以改进和比较你的答案。
将来,我们将提供有关如何充分利用索引的提示,并建议优化检索策略的方法。
System Prompt
默认情况下,我们提供一个简单的系统提示,你可以在模型设置中更改它。它与更广泛的系统提示一起使用。你只需编辑它即可更改简单的系统提示。
优化上下文
良好的响应依赖于良好的上下文。使用诸如对内容进行分块和优化数据分块策略等方法非常重要。除了对数据进行分块外,你还可以尝试不同的文本嵌入模型来改进检索,看看哪种模型能给你带来最佳结果。在上面的例子中,我们使用了 Elastic 自己的 ELSER 模型,但推理服务支持大量嵌入模型,这些模型可能更适合你的需求。
优化上下文的其他好处包括更好的成本效率和速度:成本是根据标记(输入和输出)计算的。在分块和 Elasticsearch 强大的检索功能的帮助下,我们提供的相关文档越多,你的用户的成本就越低,延迟就越快。
如果你注意到,我们在 BM25 示例中使用的输入 token 比 ELSER 示例中的要大。这是因为我们有效地对文档进行了分块,并且只向 LLM 提供了页面上最相关的段落。
最后一步!将 RAG 集成到你的应用程序中
一旦你对响应感到满意,你就可以将此体验集成到你的应用程序中。查看代码提供了如何在你自己的 API 中执行此操作的示例应用程序代码。
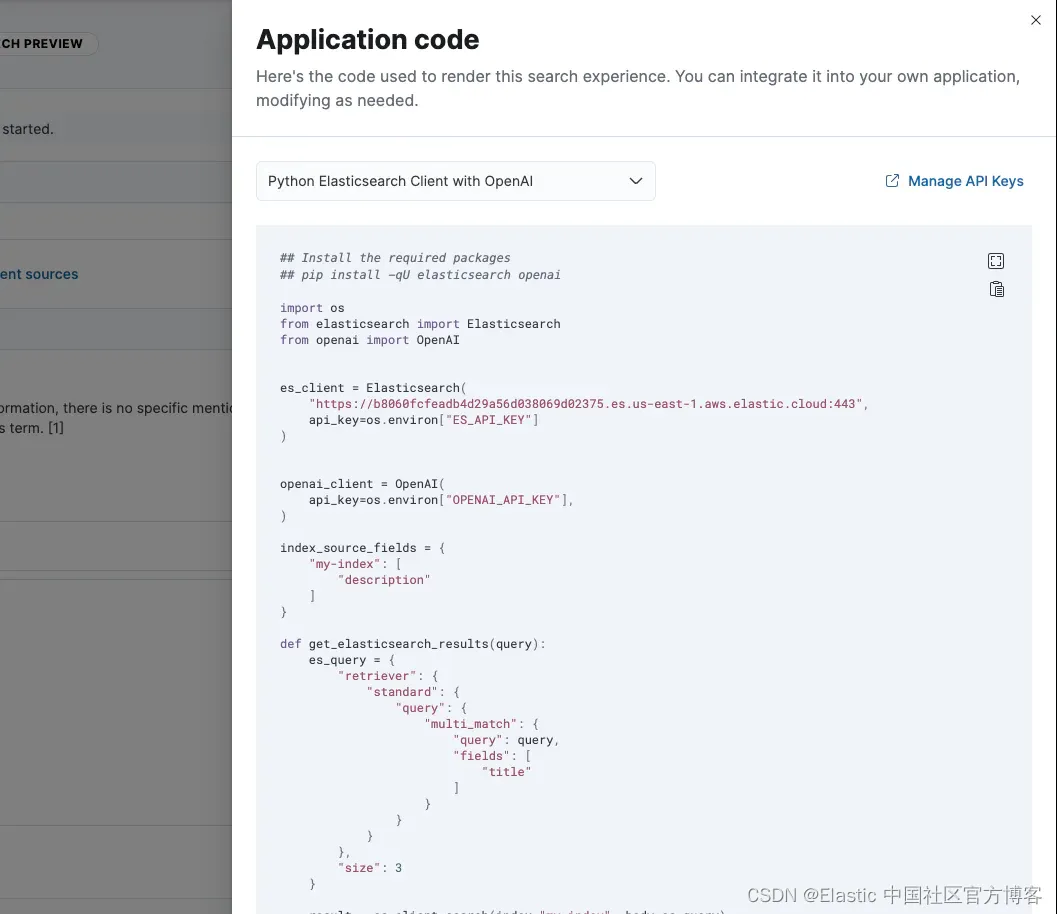
目前,我们提供了使用 OpenAI 或 LangChain 的示例,但 Elasticsearch 查询、系统提示以及模型与 Elasticsearch 之间的一般交互相对简单,可供你自行调整使用。
结论
对话式搜索体验的构建可以考虑多种方法,而选择可能会让人不知所措,尤其是随着新的重新排名和检索技术的创新步伐,这两种技术都适用于 RAG 应用程序。
使用我们的 Playground,即使开发人员可以使用多种功能,这些选择也会变得简单直观。我们的方法独特之处在于,可以立即将混合搜索作为构建的主要支柱,直观地了解所选和分块数据的形状,并扩大 LLMs 的多个外部提供商的访问范围。
使用 Playground 构建、测试、享受乐趣
立即前往 Playground 文档开始吧!探索 GitHub 上的搜索实验室,了解 Cohere、Anthropic、Azure OpenAI 等提供商的新手册和集成。
准备好自己尝试一下了吗?开始免费试用。
Elasticsearch 集成了 LangChain、Cohere 等工具。加入我们的高级语义搜索网络研讨会,构建你的下一个 GenAI 应用程序!
原文:Playground: Experiment with RAG applications with Elasticsearch in minutes — Elastic Search Labs