深度学习模型尤其是Transformers架构,已经在诸如自然语言处理、计算机视觉和时间序列预测等多个领域取得了显著成就。然而,随着模型输入序列长度的增加,传统的Transformers模型面临着显著的扩展性问题。其核心问题在于,Transformers中的注意力机制在处理长序列数据时,计算复杂度和内存需求随着输入大小呈二次方增长,这不仅限制了模型处理大规模数据的能力,也增加了训练和推理的时间成本。
本文介绍的“MambaMixer: Efficient Selective State Space Models with Dual Token and Channel Selection”正是针对这一挑战提出的解决方案。MambaMixer是一种新型的深度学习架构,它通过引入高效的选择性状态空间模型(SSMs),在保持数据依赖性的同时,显著降低了长序列建模的时间和空间复杂度。这一创新不仅推动了深度学习模型在处理大规模数据时的效率,也为长序列建模提供了新的可能性,特别是在需要捕捉长期依赖关系的复杂任务中。
方法
MambaMixer是一种结合了选择性令牌混合器(Selective Token Mixer)和选择性通道混合器(Selective Channel Mixer)的架构。这种设计旨在通过数据依赖的权重,沿着序列和模型维度有效地混合信息。选择性令牌混合器负责在序列维度上融合信息,而选择性通道混合器则关注于在模型维度上的信息融合。
选择性令牌混合器的设计灵感来源于Mamba模型,它在输入的投影之后和S6块之前使用一维卷积。这种设计不仅提供了更通用的形式和更具表现力的表示,还允许模型在不同分辨率级别上更专注或过滤信息,这在视觉和时间序列预测任务中尤为重要。
选择性通道混合器使用SSM作为通道混合块,可以为每个令牌选择性地过滤不相关的通道,并沿着模型维度轴融合信息。这种方法避免了在大型网络中训练时的不稳定性,并且由于其数据依赖性,可以更有效地选择信息丰富的通道。
为了克服数据依赖通道混合的挑战,作者提出了一种新的启发式方法,使用准分离矩阵来近似传统的前向和后向SSMs。这种方法不仅节省了大约一半的参数,还利用了硬件友好型和可并行化的实现,从而加快了训练速度。
QSMixer是MambaMixer的一个变体,它进一步简化了架构,使用准分离矩阵进行信息混合。这种方法不仅提高了效率,还保持了模型的表现力。QSMixer是首个大规模模型,展示了准分离矩阵在序列建模中的强大能力。
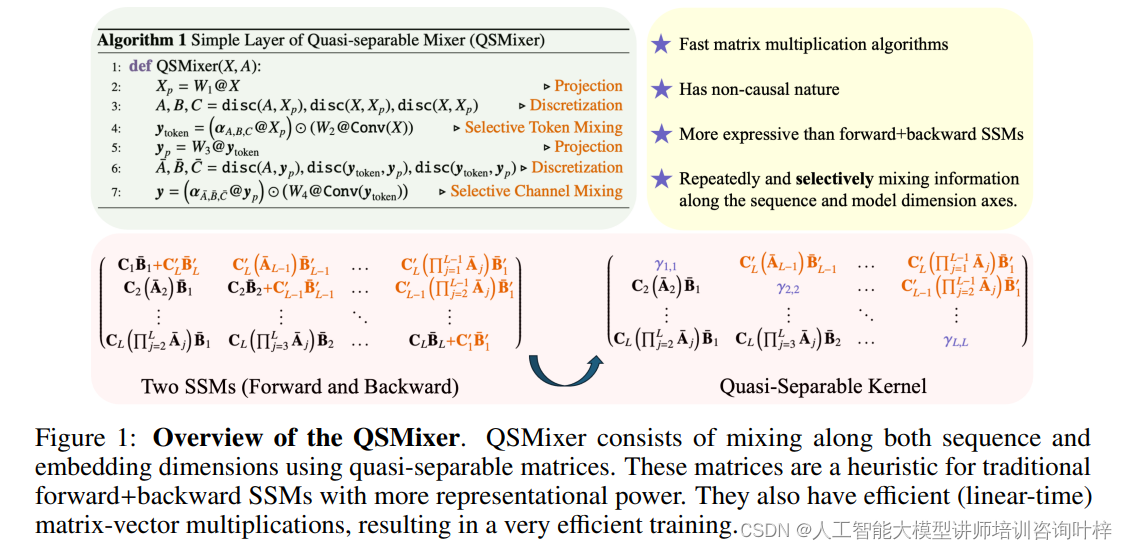
QSMixer是MambaMixer架构中的一个关键组件,它负责在序列和嵌入维度上进行信息混合。这种混合对于捕捉序列数据中的长距离依赖关系至关重要,尤其是在处理图像、视频和时间序列等多维数据时。
准分离矩阵
QSMixer 使用的准分离矩阵是一种具有特定结构的矩阵,它允许更高效的计算。这种结构化的特性使得矩阵的存储和操作更加经济,同时保持了模型的表达能力。
启发式改进
与传统的 SSMs 相比,QSMixer 的准分离矩阵提供了更多的表示能力。这种启发式改进使得模型能够以更少的参数捕捉更复杂的数据动态。
高效的计算
QSMixer 的核心优势之一是其高效的矩阵-向量乘法运算。由于准分离矩阵的结构特性,相关的乘法运算可以在线性时间内完成,这大大加快了模型的训练速度,降低了计算成本。
训练效率
得益于高效的矩阵运算,QSMixer 在训练过程中表现出了高效率。这使得模型即使在大规模数据集上也能快速收敛,同时保持了较低的内存和计算资源消耗。
视觉 MambaMixer 和视觉 QSMixer
为了适应视觉任务,作者对MambaMixer和QSMixer的门控机制进行了修改,使用一组卷积来提取输入图像的多分辨率特征。这种设计通过深度可分离卷积在不同分辨率上操作,增强了模型对图像特征的捕捉能力。
视觉任务,如图像分类、目标检测和语义分割,要求模型能够捕捉图像中的空间依赖性,包括垂直和水平方向。传统的序列编码器在处理这类任务时受限于其有限的感受野,即它们难以同时捕捉到图像在多个方向上的空间关系。为了解决这一挑战,研究者提出了多种图像扫描方法,但这些方法会增加参数数量并降低训练效率。
为了提高使用不同图像扫描方法的有效性和效率,研究者引入了Switch of Scans(SoS)模块。SoS模块使用一种路由器机制,动态选择每张图像最有效的扫描集合。这种设计灵感来源于混合专家技术,能够根据图像的高级特征来决定哪些扫描方法更为有用。
ViM2和ViQS模型进一步改进了MambaMixer和QSMixer的门控机制,采用多分辨率卷积来提取输入图像的多尺度特征。这些特征通过深度可分离卷积处理,以增强模型对不同尺度图像特征的捕捉能力,这对于密集图像和密集预测任务尤为重要。
ViM2模型采用了MambaMixer块,而ViQS模型则采用了QSMixer块。这两种模型都利用了选择性令牌混合器和选择性通道混合器,但ViQS在两者上都使用了基于准分离矩阵的简化和快速版本。这些混合器的设计允许模型在处理视觉数据时,能够选择性地过滤掉不相关的信息,同时保留有用的特征。

ViM2和ViQS的设计不仅关注于单一任务的性能,还强调了模型的泛化能力。通过使用数据依赖的权重和准分离矩阵,这些模型能够适应不同的视觉任务,捕捉长距离依赖关系,并有效地处理多维数据。
实验
研究者设定了实验的主要目标,包括评估MambaMixer和QSMixer作为序列编码器背骨在捕捉长序列依赖性方面的有效性,并将它们与现有的最先进序列编码器进行比较。他们还比较了ViM2和ViQS与基于卷积的视觉模型、基于混合器的方法、基于Transformer的方法以及双注意力模型等在ImageNet-1K数据集上的性能。
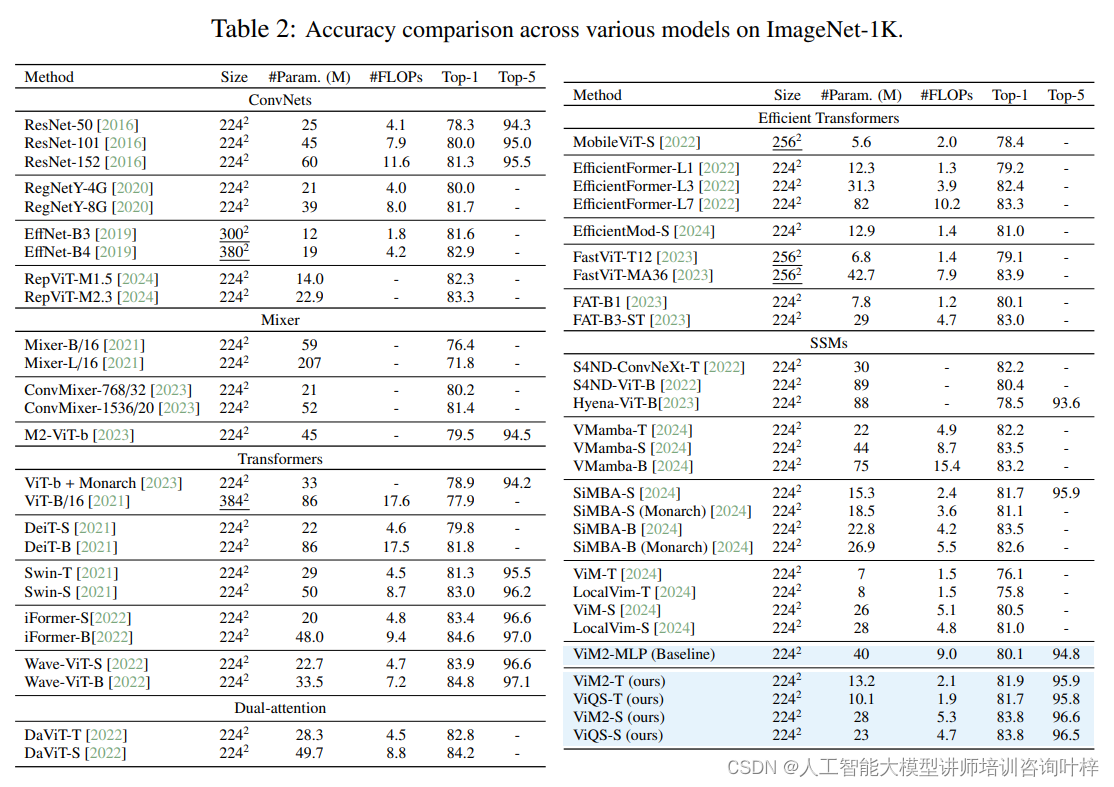
在图像分类任务中,研究者在sCIFAR和ImageNet-1K数据集上测试了MambaMixer和QSMixer的性能。实验结果显示,这些模型在像素级分类任务中能够有效捕捉长距离依赖性,并且在sCIFAR数据集上的表现优于Transformers和其他基线模型。
为了证明选择性通道混合的重要性,研究者在ImageNet-1K数据集上测试了S4、Mamba以及他们提出的选择性令牌混合器的性能。实验结果表明,使用选择性通道混合可以显著提高模型性能,因为它能够为每个令牌过滤不相关的通道。
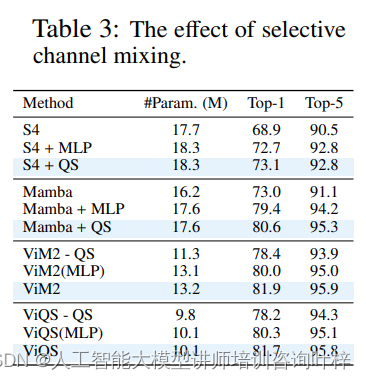
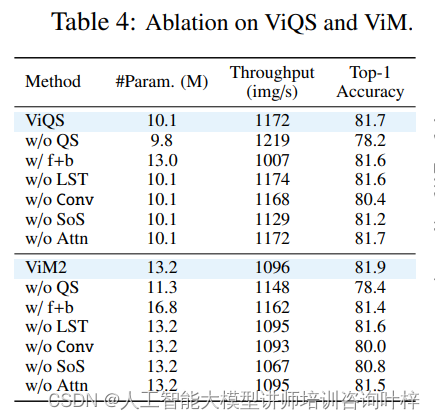
消融研究中,研究者逐一移除了架构中的某些组件,以评估每个组件对整体性能的贡献。消融研究结果表明,准分离矩阵的实现和通道混合器对性能提升有显著贡献,缺乏通道混合会导致平均性能下降。
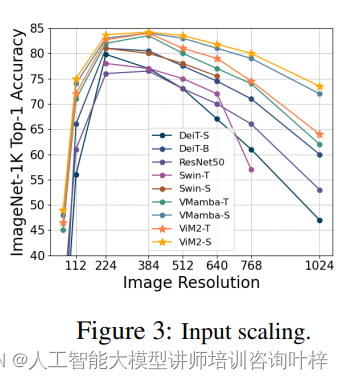
研究者评估了ViM2在不同分辨率图像上的性能,以测试模型对长距离依赖性的捕捉能力。实验结果表明,ViM2在处理高分辨率图像以及不同分辨率输入时表现出更好的鲁棒性。
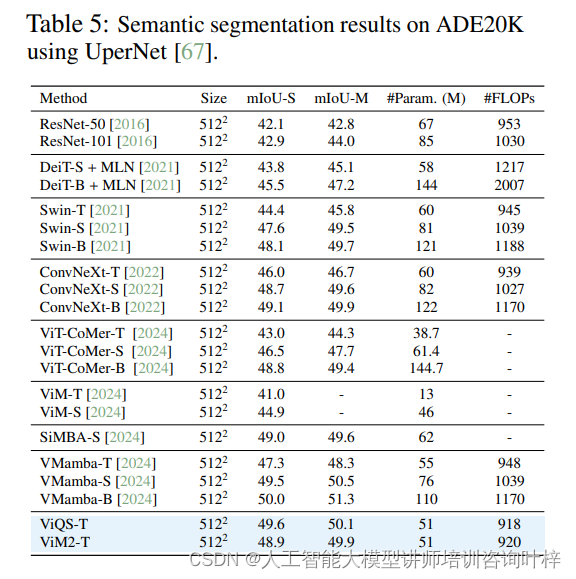
除了图像分类任务外,研究者还在ADE20K数据集上进行了语义分割任务的评估,并在COCO数据集上进行了目标检测任务的测试。ViM2和ViQS在这些下游任务上的表现进一步证明了它们的适用性和多样性。
通过一系列实验,我们得出结论,MambaMixer和QSMixer在视觉任务中展现出了与现有模型相媲美甚至更优的性能,同时具有更少的计算资源消耗。这些结果强调了选择性地跨令牌和通道混合信息的重要性,并证明了所提出模型在多维数据建模中的潜力。
MambaMixer 和 QSMixer 展示了数据依赖 SSM 在序列建模中的潜力,它们通过递归和选择性地混合序列和模型维度上的信息,实现了硬件友好和高效的训练。ViM2 和 ViQS 模型的成功表明,MambaMixer 和 QSMixer 在多维数据建模中具有广泛的应用前景。
论文链接:https://arxiv.org/abs/2403.19888