华为NPU 910B与NVIDIA GPU A100性能对比,从AICore到TensorCore,展现各自计算核心优势。
AI 2.0浪潮汹涌而来,若仍将其与区块链等量齐观,视作炒作泡沫,则将错失新时代的巨大机遇。现在,就是把握AI时代的关键时刻。
AI芯片作为AI热潮中的"掘金利器",备受瞩目。Gartner预测,至2027年,其市场规模将飙升至1194亿美元,前景广阔。
英伟达,以80%的市场占有率雄踞算力之巅,其强势地位带来丰厚盈利。财报亮眼,市值更是一夜飙升2770亿美元,彰显其无可匹敌的市场影响力。
然而,美国实施的出口管制政策对英伟达在华业务造成了冲击,致其一季度H20芯片出口增长未达预期。但华为910B芯片订单成绩亮眼,呈现出强劲的市场需求。
英伟达CEO黄仁勋罕见发声,称华为为最大劲敌,其拥有丰富资源并自主设计软硬件提升AI算力。出口限制下,华为昇腾910系列AI芯片成为英伟达A100在中国市场的热门替代,自国企、通信商至互联网,昇腾芯片受到广泛采购,展现其卓越的市场影响力。
展望未来,随着Sora、GPT-4o等多模态大模型的普及,计算资源需求将持续攀升。芯片设计需精准适配这些计算场景,并研发专用硬件加速器,以高效支持复杂模型的训练与应用,满足日益增长的计算需求。
揭秘AI芯片巨头对决!华为昇腾910B与NVIDIA A100硬件参数解析,一探华为NPU与NVIDIA GPU在设计与应用中的实力较量,洞察各自优势与短板,为您的“淘金”之旅提供关键指引。
1. AI芯片硬件概述
昇腾910B,华为顶尖AI处理器,专为推理与训练而生。搭载创新达芬奇架构与高效NPU设计,昇腾910B展现卓越计算性能与能效比,为人工智能任务提供强大动力。
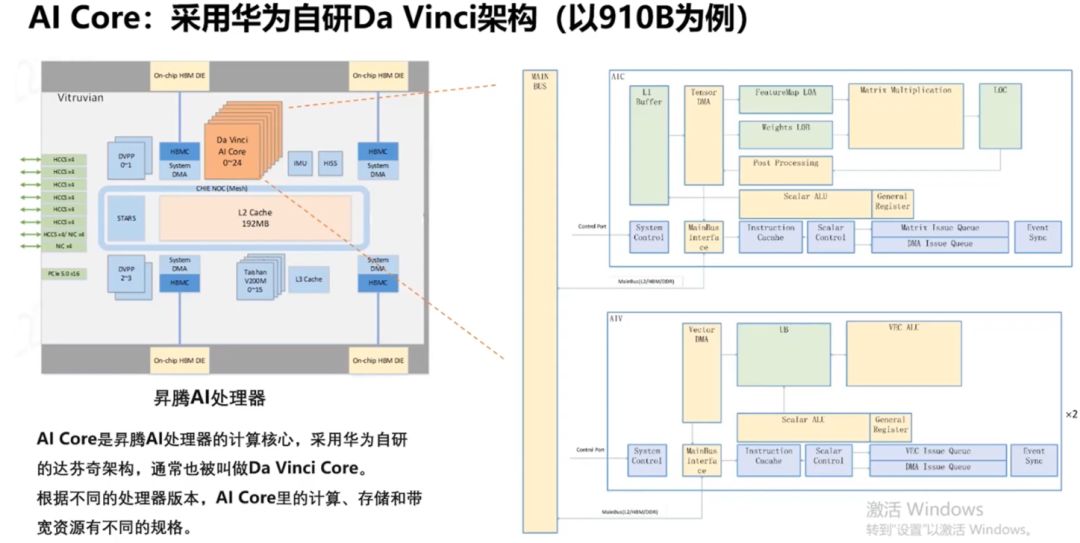
华为自研的910B AI处理器架构图亮相,集成25个AI Core、4个HBM 2.0内存及AI CPU、DVPP模块、HCCS链路等关键组件,配备先进缓存系统,展现强大AI处理能力。
910B的AI Core是专为深度学习设计的计算核心,自诞生起便针对高性能计算需求进行优化,为深度学习领域提供强大支持与高度灵活性。
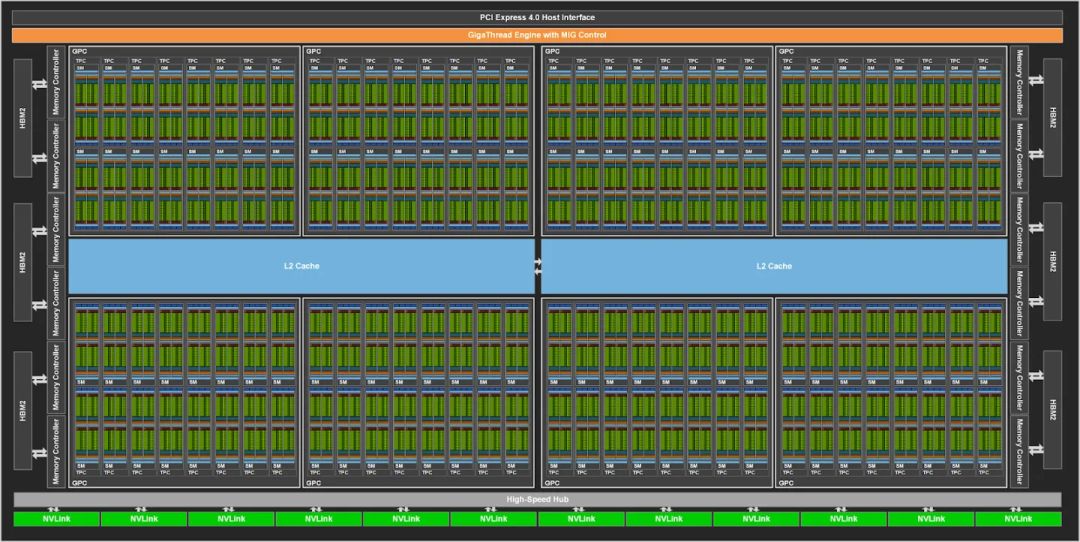
NVIDIA GPU起初深耕图形处理,后借Tesla芯片之力转型GPGPU,实现通用计算,并不断提升AI计算能力,与华为NPU发展轨迹迥异。
NVIDIA A100 GPU,Ampere架构的巅峰之作,引领技术革新,加速迈向人工通用智能(AGI)。这款GPU在图形处理、深度学习及高性能计算领域均展现卓越性能,成为AI研究与应用的关键动力,开启智能新时代。
A100全能应用版GPU内置128个SM,TensorCore版则拥有108个SM。每个SM配备丰富CUDA核心和Tensor核心,专为图形通用计算和AI张量计算设计,展现了出色的计算性能与效率。
A100 GPU搭载丰富的HBM2堆栈,结合第三代NVLink协议与第二代NvSwitch技术,实现GPU间高速数据交换。其性能卓越,FP32性能较V100提升10倍,混合精度训练效能更增20倍。这些显著优势使A100 GPU成为AI领域进步的强大驱动力,引领行业迈向新高度。
英伟达GPU与华为NPU,虽初衷各异,但在大模型时代,两者均为AI芯片翘楚,以其卓越的训练、推理计算性能与能效比,共同引领AI发展潮流。
如果你想了解华为910B和英伟达A100更详细的对比,可以参考这篇文章:
华为NPU vs 英伟达GPU 架构原理和编程范式深度对比
2. 计算性能比较
华为910B NPU的核心计算单元为AI Core,共计25个,与GPU中的SM相似,但NPU并行计算单元较GPU更为精简,展现其高效能、专业化的AI处理能力。
NVIDIA A100 TensorCore版GPU配备108个SM,而全功能版则高达128个,彰显GPU在并行计算单元领域的卓越性。更多SM赋予其强大并行计算能力,轻松应对复杂计算挑战,展现技术领先实力。
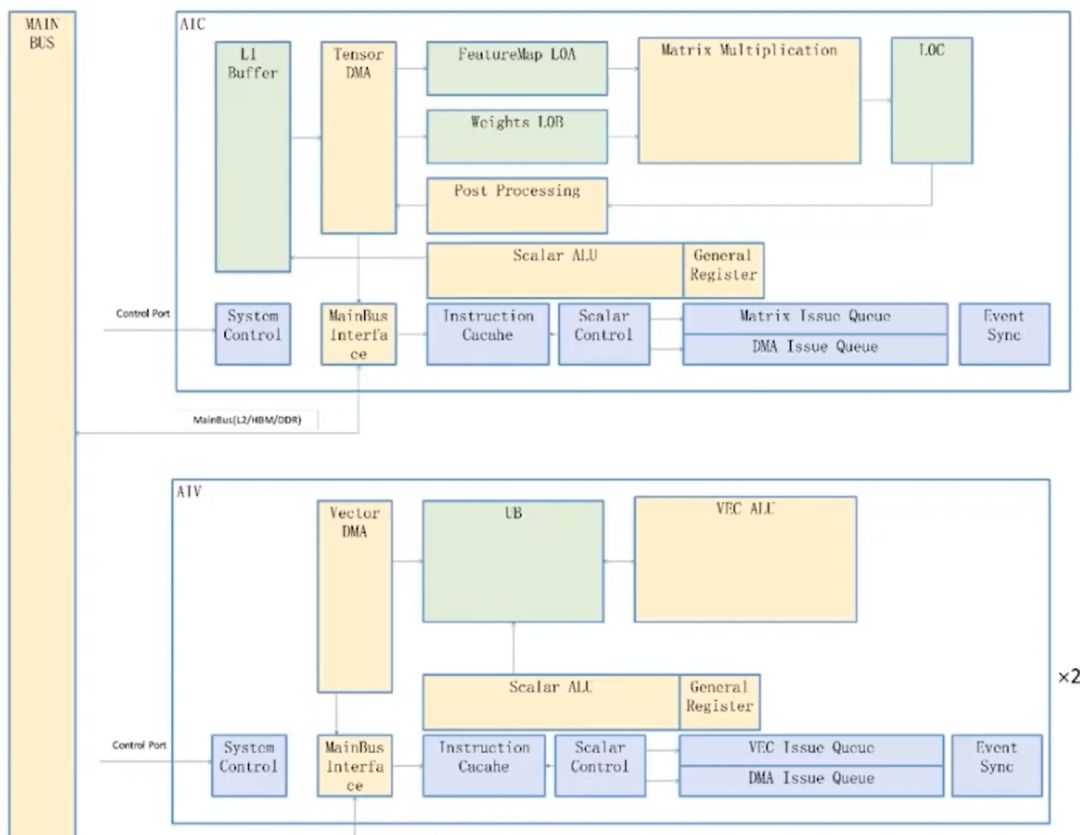
910B NPU的每个AICore集成两大计算利器:2个AI Vector向量计算单元与1个AI Cube矩阵计算单元。前者媲美GPU中的CUDA Core,后者则与TensorCore相当,共同为高性能计算提供强大支撑。
910B NPU中,每AICore配备2个AI Vector,总计25个AICore拥有50个AI Vector,每AI Vector每时钟周期可完成128次FP16计算。相较之下,A100拥有108个SM,每SM包含64个FP32 CUDA Core,每CUDA Core每时钟周期执行一次FP32计算。这凸显了910B NPU在AI处理上的高效计算能力。
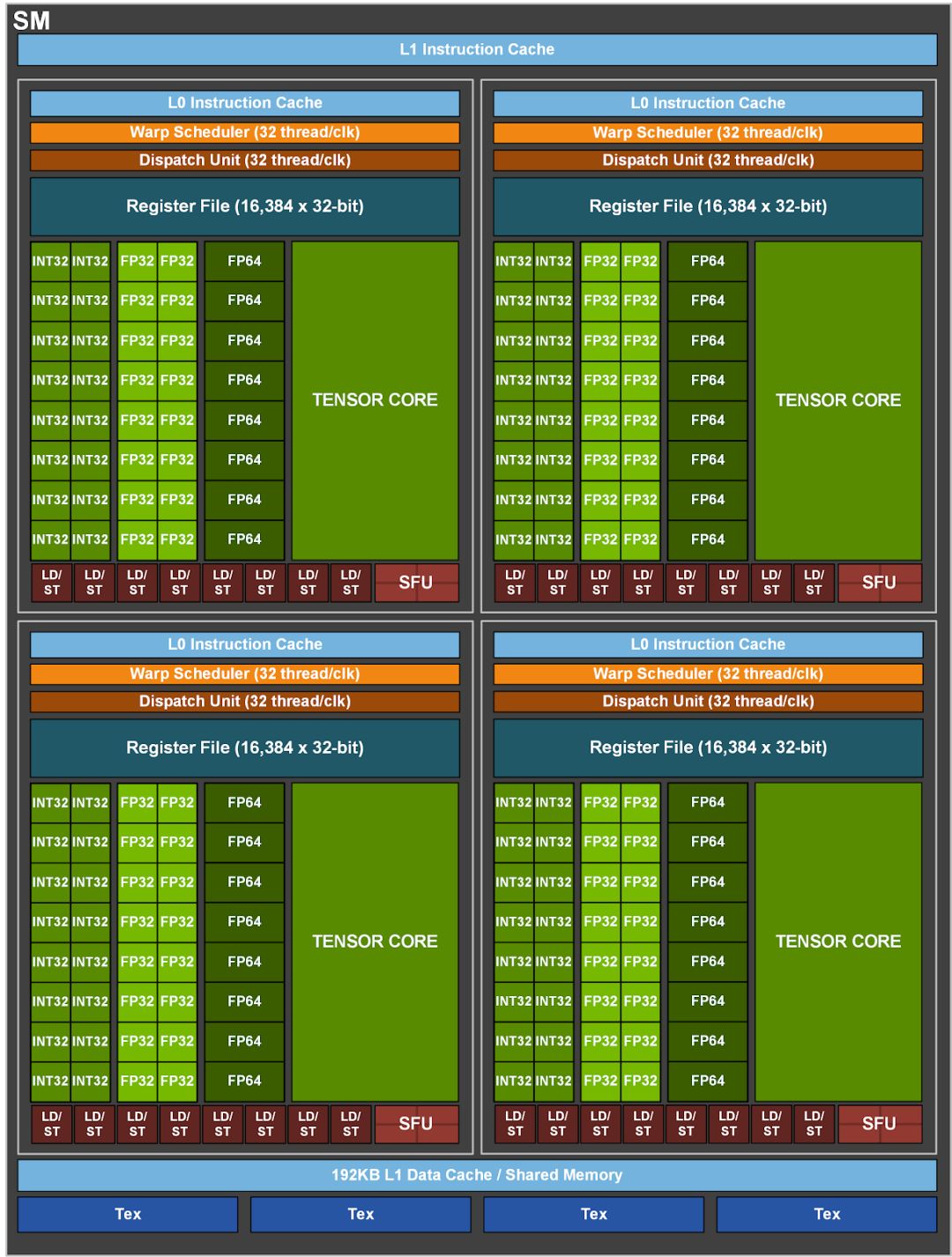
A100 GPU中,每SM搭载4个Tensor Core,每个Tensor Core每时钟周期可完成高达4x8x8的FP16/FP32 FMA计算,单SM即实现1024次密集FP16/FP32 FMA操作,整机配备108个SM,计算能力卓越。
910B NPU的每个AICore都配备一个Cube Core,其计算能力强大,单个时钟周期内可执行多达16x16x16次FP16/FP32 FMA运算。这意味着,每个AICore能高效完成4096次密集的FP16/FP32 FMA操作。而910B NPU总共配备了25个这样的AICore,计算能力惊人。
华为NPU芯片设计聚焦高效能,虽减少计算单元数量,但矩阵计算单元远超GPU,强调单元计算力与效率,专为处理大规模矩阵计算任务如深度学习推理而优化。
经过测试数据分析,在普通模式下,910B与A100算力旗鼓相当。但华为910B在单个时钟周期内可处理16x16x16的矩阵计算,远胜于A100的4x8x8,其单次矩阵计算能力高达A100的16倍,效能显著。
A100凭借Sparsity稀疏矩阵计算支持及丰富的TensorCore单元,在多数场景中显著超越910B。尽管910B在单一矩阵计算上表现出色,但A100在处理多元计算任务时依旧占据优势,尤其在稀疏矩阵计算领域,A100的性能尤为突出。
3. 内存架构比较
华为910B与英伟达A100在内存架构上大相径庭。910B凭借AI Vector与AI Cube的完全解耦设计,实现了两计算单元独立存储体系,展现了独特的技术优势。
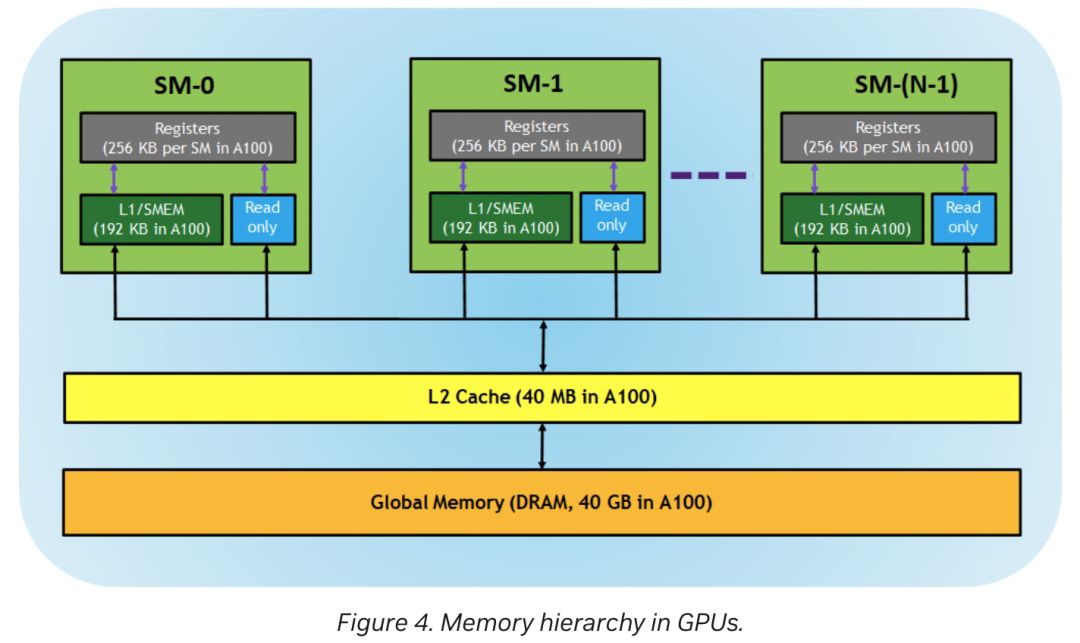
此外,在全局存储的L2缓存方面,A100配备40MB,而910B则大幅升级至192MB,显著超越A100,提供更强大的缓存能力。
在A100中,L1/共享内存统一为192KB的逻辑区域;而华为910B的L1缓存独立存在于Cube单元,达1MB,UB缓存则作为共享内存,位于Vec单元,容量为256KB,彰显不同设计思路。
A100的每个SM配备256KB寄存器或L0缓存,而910B的Cube拥有256KB输出寄存器及64KB输入寄存器,彰显其卓越的数据处理能力。
910B相较于A100,拥有更庞大的存储体系,显著提升了深度学习中大数据传输的支持能力,因此更适用于深度学习任务,展现卓越性能。
4. 通信性能比较
通信架构上的优势一直是英伟达强大的护城河之一。
A100架构汇集第三代Nvlink、第二代NvSwitch及第四代PCle,实现高效的GPU间互联。在摩尔定律渐失效、算力需求飙升的今天,这一创新设计尤显关键,为满足高性能计算需求提供了强大支持。
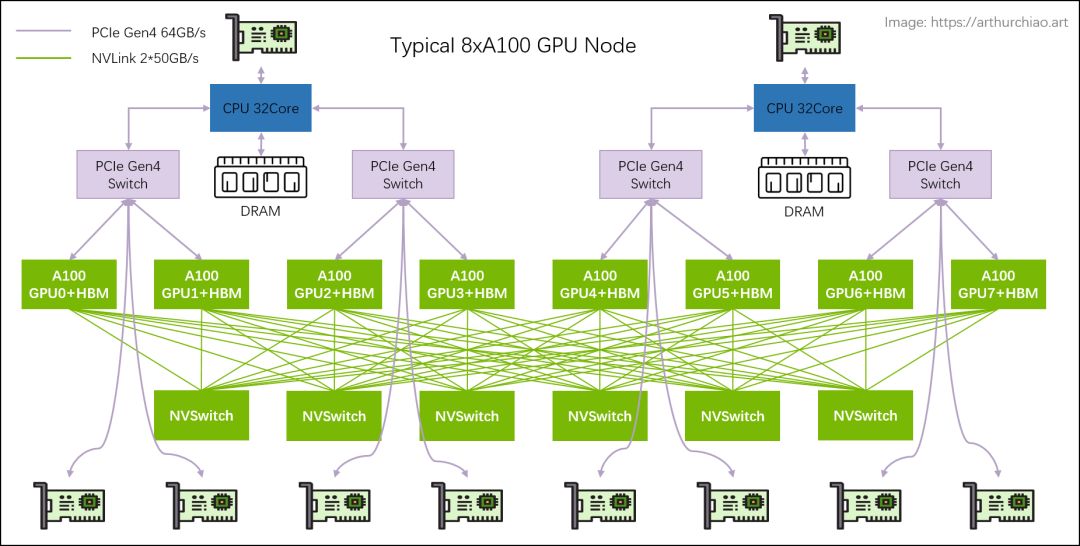
A100架构中,每张GPU卡依托12条NVLink链路和6个NVSwitch,实现全连接网络拓扑,性能卓越。
尽管标准DGX A100配置只配备8块GPU卡,未能充分发挥NVLink的硬件潜能,但该系统可扩展性强,支持增添更多A100 GPU卡与NVSwitch,轻松打造更强大的超级计算机,满足大规模运算需求。
A100通过NVLink与NvSwitch技术,实现了GPU间的全互联高速通信,总带宽高达600GB/s。得益于NvSwitch的互联功能,即便是单点对点的传输,也能达到惊人的600GB/s带宽,确保了机内GPU间通信的高效与稳定。
DGX A100搭载高性能InfiniBand适配器,支持RDMA技术,实现GPU间通信带宽高达200Gbps。然而,需注意InfiniBand需专用网卡及昂贵交换机,投入成本相对较高。尽管如此,其卓越的通信性能仍具强大吸引力。
机内CPU与GPU的通信经由PCIe Switch高效互联。每CPU与4个GPU通过PCIe Switch实现通信,宛如交换机运作,支持多插槽配置。GPU 0~3及GPU 4~7间,既可依赖NVLink直接沟通,亦可选择PCIe Switch进行数据传输。NVLink专为实现GPU间的高速通信而设计,确保数据处理流畅无阻。
相较于A100,华为910B因缺少NvSwitch,故采用类似GPU DGX-1的芯片直接互联方式进行机内通信,实现了高效的数据传输。
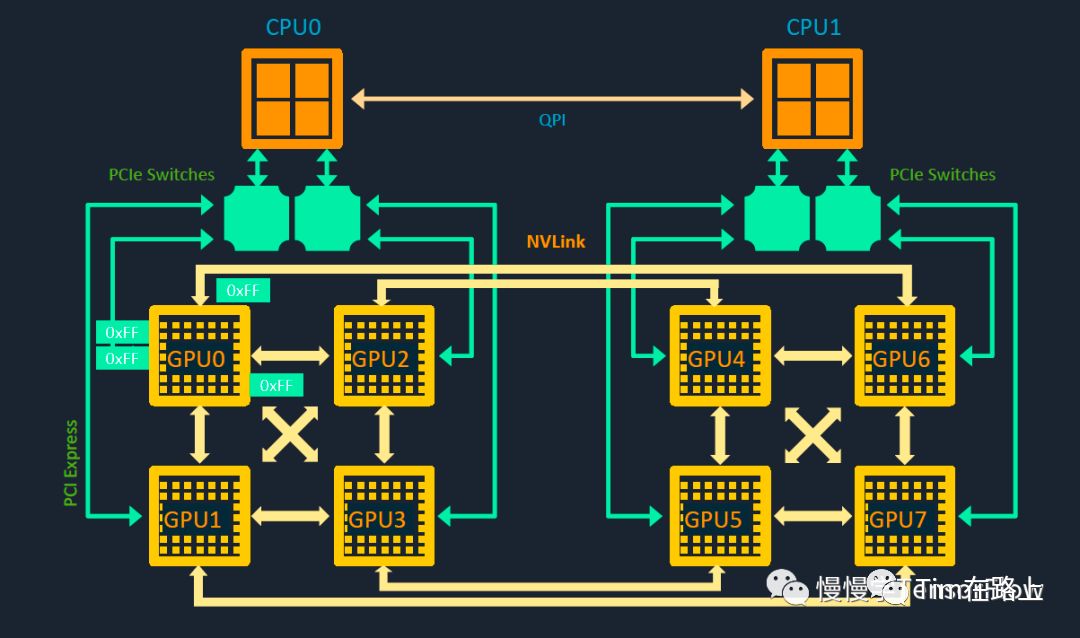
DGX-1的GPU架构图彰显其独特设计:每芯片配备4个NVLink链路,四芯片组合成cube mesh。GPU 0至3与GPU 4至7均通过NVLink和PCIe Switch实现互联。然而,GPU 0与GPU 4间无直接通路,需通过如GPU0-GPU2-GPU4的间接路径进行通信,这一创新设计确保数据处理的高效与灵活。
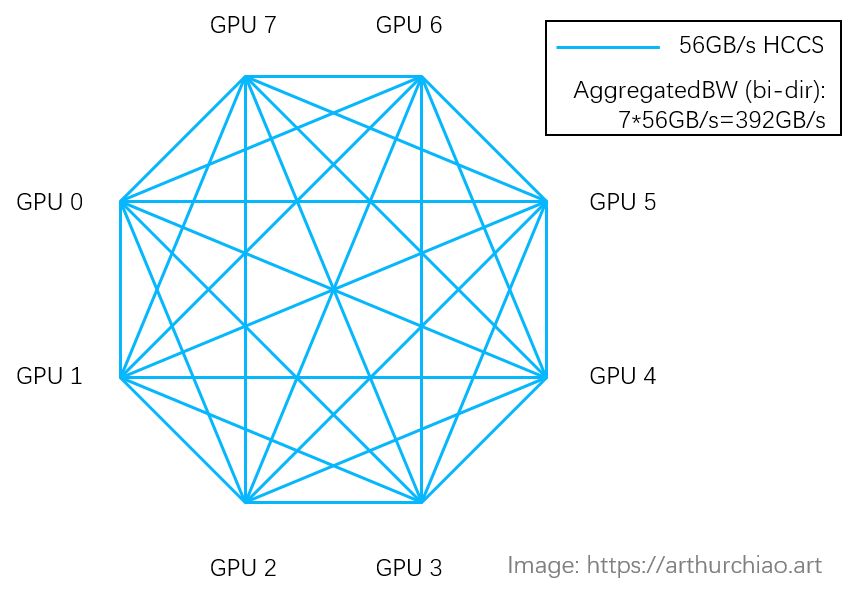
华为910B中,每芯片支持7个HCCS链路,8芯片组成cube mesh。与DGX-1的GPU跳通信不同,16卡910B机器间采用PCIe互联。如NPU0与NPU9间需跨PCIe通信,通信效率受限。这一设计虽独特,但在特定场景下可能面临通信效率挑战。
华为910B在机间GPU通信上未配置InfiniBand适配器,仅依赖PCIe通信,性能显著受限,通信速度相对较慢。
华为910B在CPU-GPU通信中凭借PCIe Gen5占据优势,但整体性能仍显著落后于A100。然而,华为据传已研发出类似“NVSwitch”的首代硬件,显著提升通信性能,前景可期。
5. 总结
英伟达A100芯片,承袭英伟达技术精髓,不仅深度学习AI性能出众,更在图像处理及通用计算领域展现卓越性能,全面领先行业。
英伟达H100架构革新设计,移除RT Core,以深度学习AI计算为重心,此举突破传统计算设计对深度学习性能的限制,精准切分深度学习领域的巨大市场潜力。
华为910B芯片,专为神经网络芯片NPU设计,具备超大矩阵与高带宽内存系统,矩阵运算与流水并行处理能力卓越。在深度学习场景中,尤其在GEMM计算上,其性能表现尤为突出。
华为芯片技术虽然取得了一些进步,但面临的挑战和短板同样不容忽视:
- 华为芯片设计卓越,但制程技术仍待提升。英伟达B架构芯片采用领先的4nm工艺,而华为910B芯片则基于7nm+技术。这一细微差距赋予英伟达芯片显著能效优势,性能卓越且能耗更低。华为需继续精进制程技术,以迎头赶上。
- 华为芯片设计优化亟待加强,以减少代际间的内部结构大幅变动,确保硬件兼容性与稳定性。同时,配套的API和开发工具亦需精进,以满足开发者需求,构建更为稳定、高效的开发环境。优化之路,持续进行,追求卓越。
- 华为NPU在机间通信能力上尚待提升,与英伟达存在明显差距。英伟达GPU凭借NVLink和NvSwitch技术,实现高速数据传输与高效并行计算,而华为NPU相关技术尚未成熟,可能在大规模计算中遭遇性能瓶颈。
- 华为NPU生态系统建设仍面临严峻挑战。构建强大生态需竞争力产品、丰富软件支持、广泛开发者基础及良好社区环境。华为应加大投入,吸引更多开发者和合作伙伴,共同推动NPU技术的创新与应用,共筑繁荣生态。
华为910C已迈入送测阶段,对标英伟达H100。华为自研Switch补足HCCS通信短板,更研发测试FP8精度,力推国产算力进入新时代。国产科技实力崭露头角,华为引领算力新篇章!
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-