文|CV酱
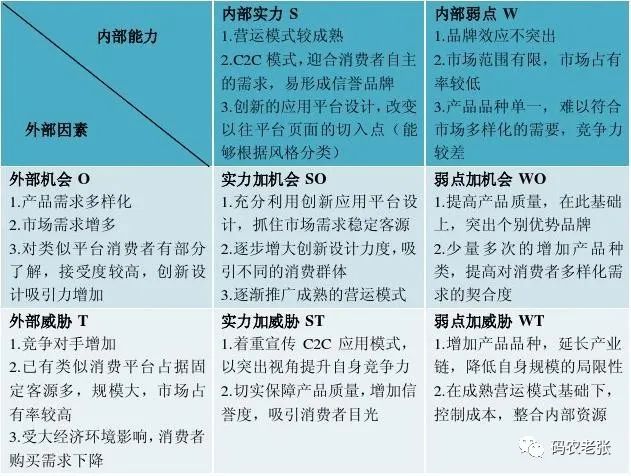
计算机视觉中,有两种常见的从图像中进行自我监督学习的方法:基于不变性的方法和生成方法。
基于不变性的预训练方法优化编码器,使其产生相似的嵌入,用于同一图像的两个或多个视图,其中图像视图通常使用一组手工数据增强构建,如随机缩放、裁剪和色彩抖动等。这些预训练方法可以产生高语义水平的表示,但它们也引入了强烈的偏差,可能对某些下游任务甚至具有不同数据分布的预训练任务有害。
通常我们不清楚如何将这些偏差推广到不同抽象层次的任务。例如,图像分类和实例分割不需要相同的不变性。此外,将这些特定于图像的增强推广到其他模态(如音频)也不能直接进行。
认知学习理论提出,生物系统中表示学习的驱动机制是内部模型对感官输入响应的适应。这个想法是自监督生成方法的核心——它们移除或打乱输入的部分内容,并学习预测损坏的内容。
尤其是,我们熟知的mask denoising方法就是通过从输入中重建随机掩蔽的补丁来学习表示。该任务比视图不变性方法需要更少的先验知识,并且很容易推广到图像模态之外。然而,由此产生的表示通常处于较低的语义级别,并且在当前的基准和有监督的语义分类任务中表现不佳。因此,需要更复杂的适应机制(例如端到端的微调)才能充分利用这些方法。
本文则探讨了如何改善从图像中进行自监督学习的语义水平,而无需使用通过图像变换编码的额外先验知识。
论文标题:
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
论文链接:
https://arxiv.org/pdf/2301.08243.pdf
为此,作者引入了一种图像联合嵌入预测架构(I-JEPA)[1]。I-JEPA的思想是在抽象表示空间中预测缺失的信息;例如,给定单个上下文块,预测图像中各个目标块的表示,其中目标表示由学习的目标编码器网络计算。与预测像素/令牌空间的生成方法相比,I-JEPA使用抽象的预测目标,可以消除不必要的像素级细节,从而使模型学习更多的语义特征。另一个核心设计选择是提出的多块掩模策略,具体而言,作者证明了使用信息丰富(空间分布)的上下文块预测图像中的多个目标块(具有足够大的尺度)的重要性。
通过广泛的实证评估,作者证明:
I-JEPA可以学习强大的现成语义表示,而无需使用手工制作的视图增强;I-JEPA在ImageNet-1K线性探测,半监督1%ImageNet-1K和语义转移任务中优于像素重建方法(如MAE);I-JEPA在语义任务上与视图不变预训练方法相比具有竞争力,并且在低级视觉任务(如物体计数和深度预测)上取得更好的性能(第5和6节);通过使用更简单的模型,具有更少的刚性归纳偏见,I-JEPA可以应用于更广泛的任务。此外,I-JEPA还具有可扩展性和效率。
在ImageNet上训练本文ViT-H/14模型大约需要2400个GPU小时,比使用iBOT训练的ViTB/16快50%,比使用MAE训练的ViT-L/16高效140%。在表示空间中预测显着减少了自监督预训练所需的总计算量。
方法
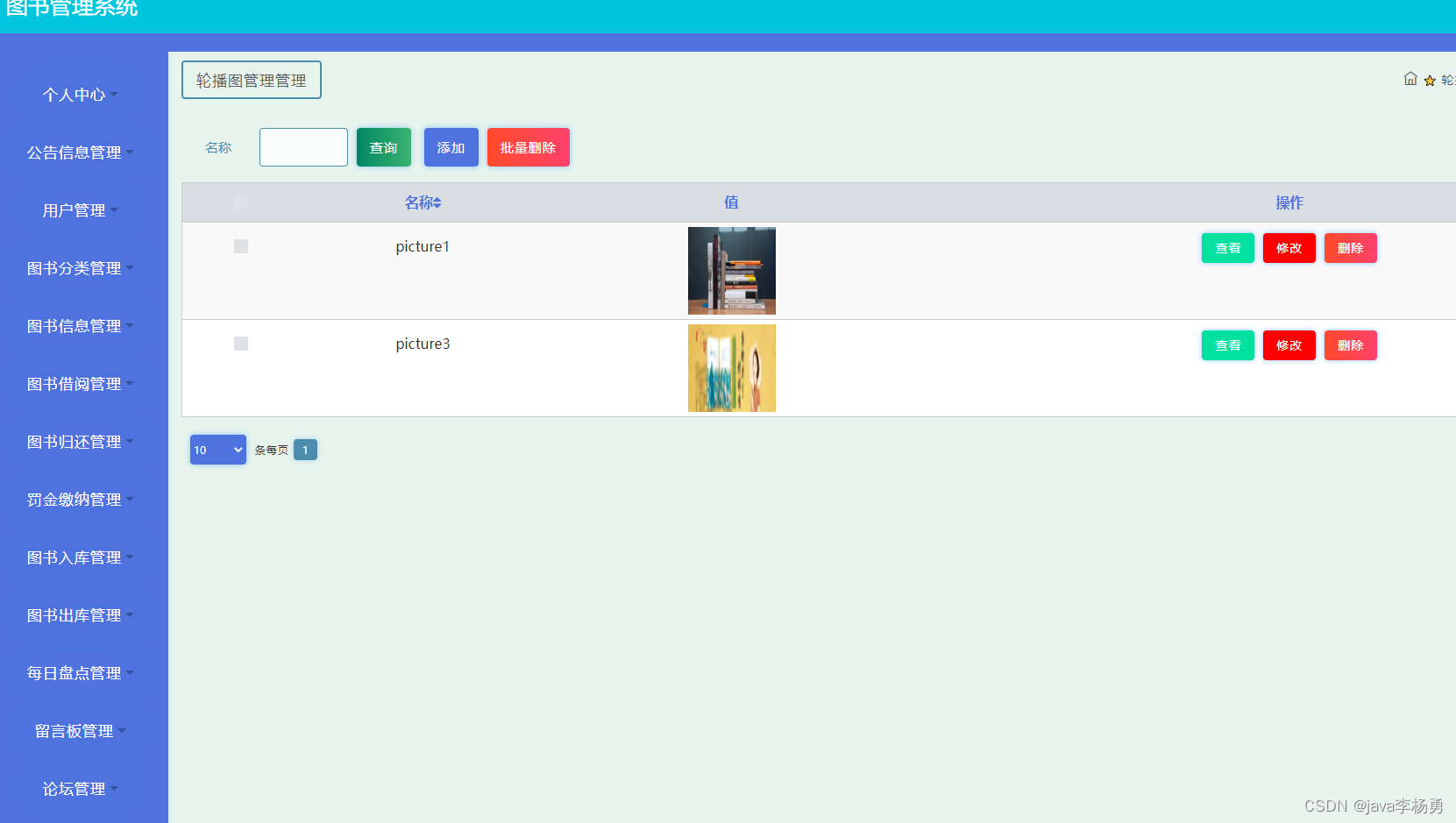
所提出的基于图像的联合嵌入预测架构(I-JEPA)如图所示。
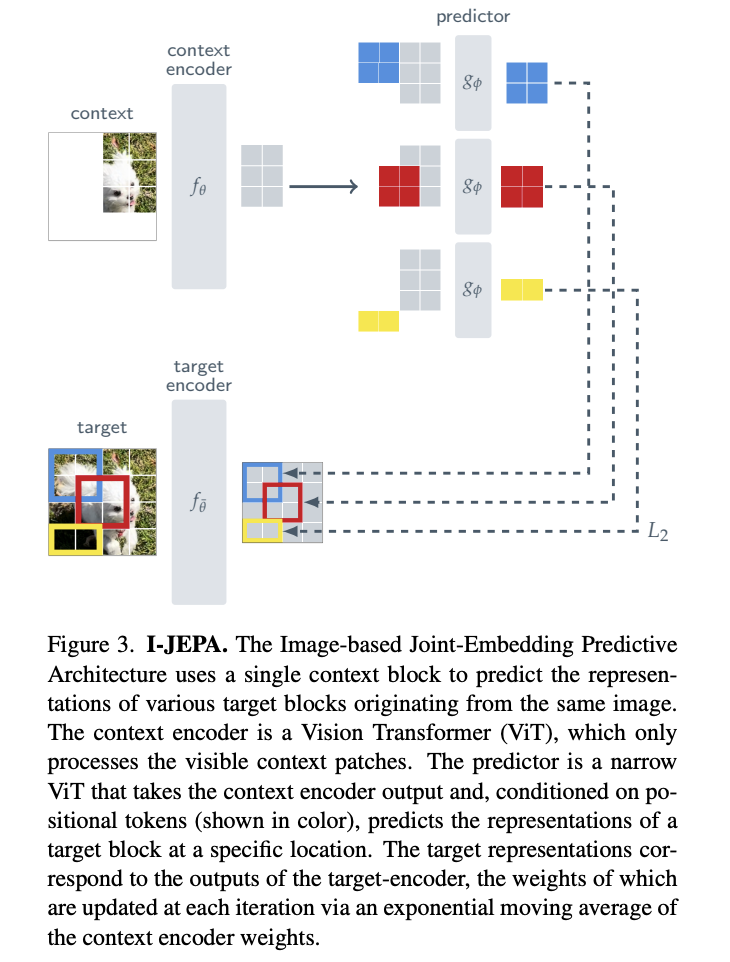
I-JEPA是一种预测目标块表示的方法。在I-JEPA中,目标对应于图像块的表示。
它首先从图像中随机采样一个上下文块x,并去除与目标块重叠的部分,然后将x通过上下文编码器fθ获得对应的patch-level表示sx,最后通过预测器gφ,将sx作为输入,以及每个patch的mask token,输出M个目标块表示sˆy(1), ..., sˆy(M),并计算预测值与目标值之间的L2距离,以此作为损失函数,最后通过梯度下降优化参数φ和θ,并使用指数移动平均更新目标编码器¯θ的参数。
此外,我们使用ViT架构作为上下文编码器、目标编码器和预测器的backbone。
编码器/预测器架构类似于生成式MAE方法。然而,一个关键的不同之处在于I-JEPA方法是非生成的,预测是在表示空间中进行的。需要注意的是,目标块是通过掩码目标编码器的输出而不是输入来获得的。这个细节至关重要。

实验结果
图像分类

I-JEPA在ImageNet-1K线性评估基准测试中显著提高了线性探测性能,同时使用更少的计算资源。
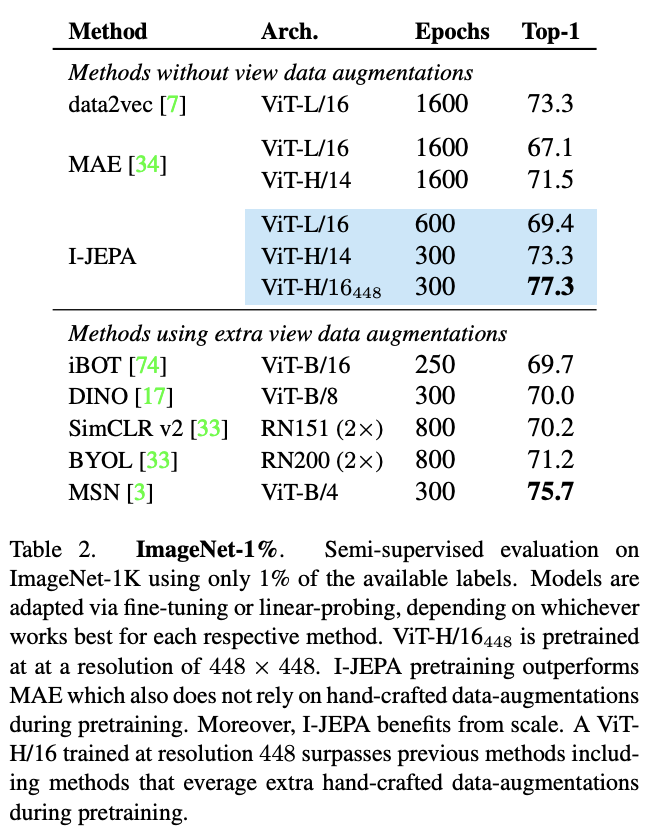
此外,I-JEPA在low shot ImageNet-1K测试中也表现出色,使用ViT-H/14架构时,I-JEPA的性能与ViT-L/16预训练的data2vec相当,而且使用的计算资源更少。随着图像输入分辨率的提高,I-JEPA的性能也超过了以前的方法,包括利用预训练期间额外手工数据增强的联合嵌入方法,如MSN、DINO和iBOT。
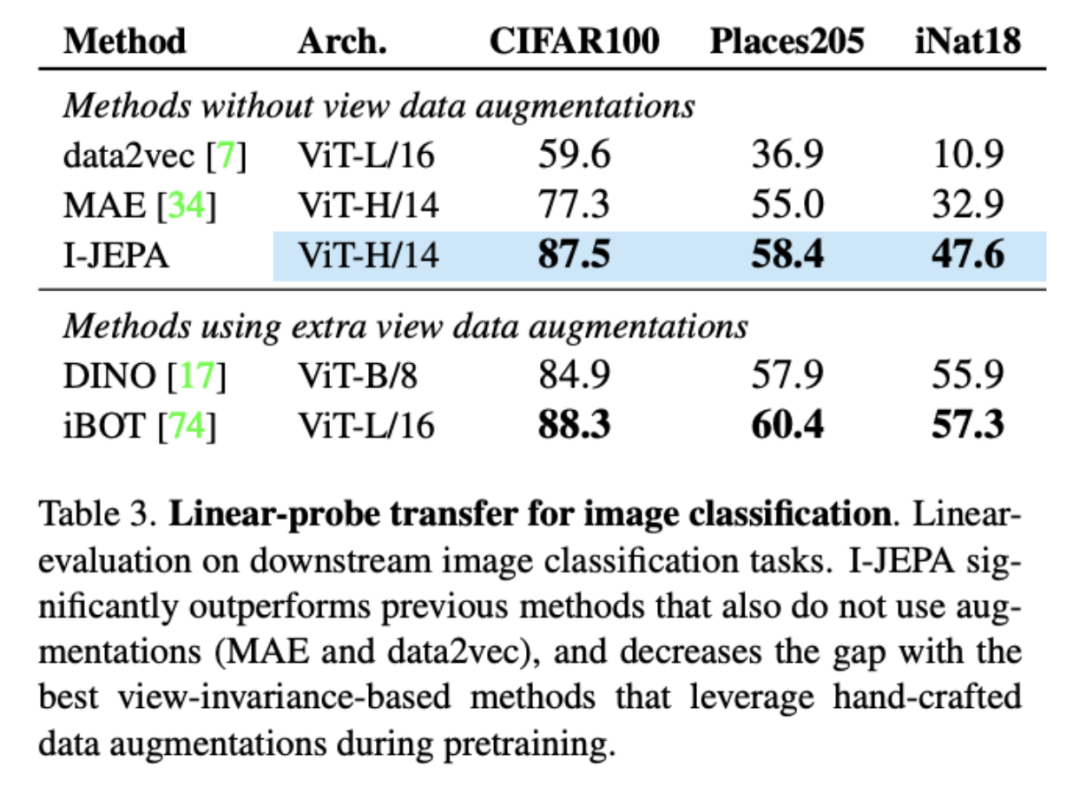
在迁移学习实验中,I-JEPA显著优于不使用增强的先前方法(MAE和data2vec),并且缩小了与最佳视图不变性基于方法的差距,甚至超过了流行的DINO在CIFAR100和Place205上的线性探测。
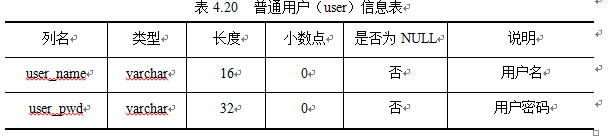
Local Prediction Tasks
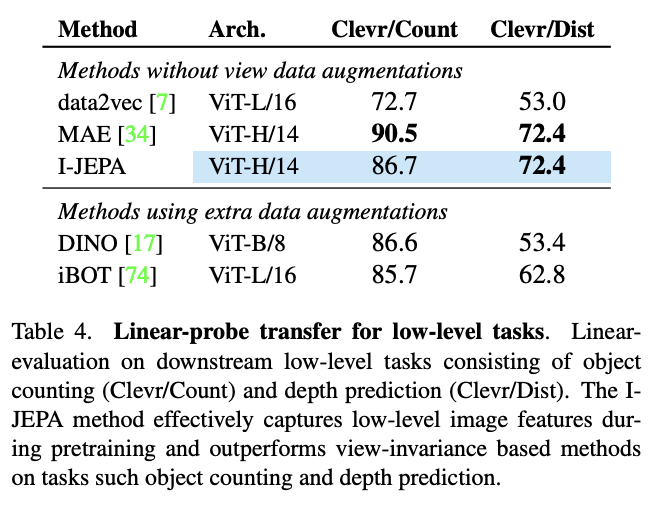
I-JEPA学习到的语义图像表示显著提高了以前方法(如MAE和data2vec)的下游图像分类性能,并且可以弥补,甚至超越利用额外手工数据增强的视图不变性方法。
此外,I-JEPA还学习到了局部图像特征,在低级和密集预测任务(如物体计数和深度预测)上超越了视图不变性方法。表4显示了使用线性探测器的各种低级任务的性能。特别是,在预训练之后,模型权重被冻结,并且在Clevr数据集上训练一个线性模型来执行物体计数和深度预测。与DINO和iBOT等视图不变性方法相比,I-JEPA方法在预训练期间有效地捕获低级图像特征,并在物体计数(Clevr/Count)和深度预测(Clevr/Dist)方面取得了超越它们的成绩。
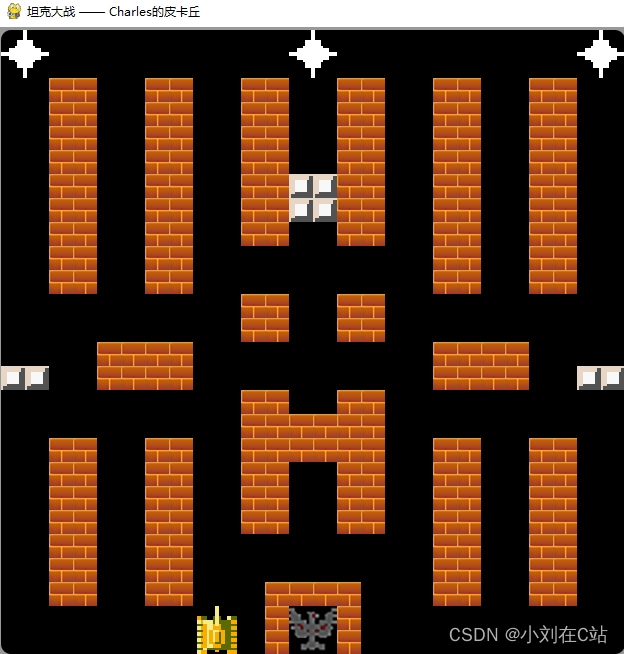
扩展性
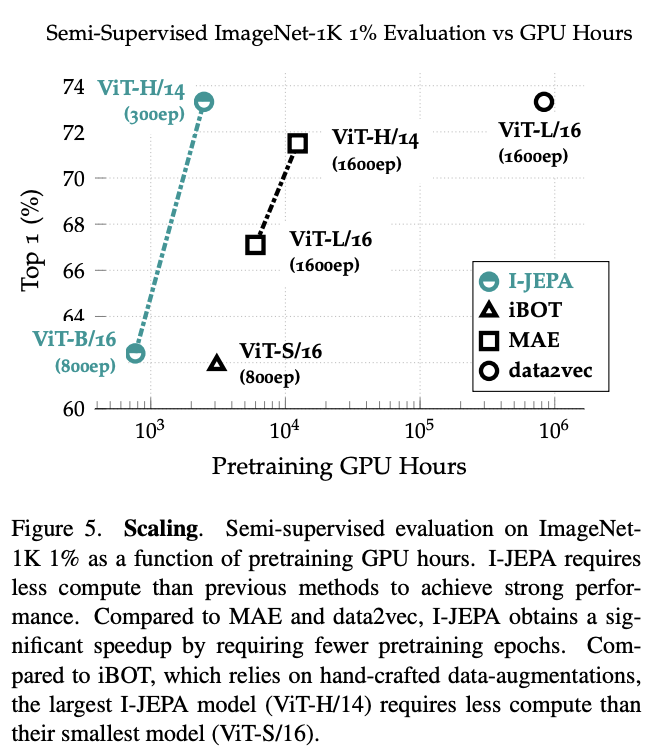
I-JEPA还比以往的方法具有更高的可扩展性。
从图5可以看出,I-JEPA在1%的ImageNet-1K上的半监督评估所需的GPU小时数比以前的方法要少,而且在不依赖手工数据增强的情况下也能取得良好的性能。
与直接将像素作为目标的重建方法(如MAE)相比,I-JEPA在表示空间中计算目标时会带来额外的开销(每次迭代约慢7%)。但是,由于I-JEPA仅需要大约5倍的迭代次数就可以收敛,因此实际上仍然可以节省大量的计算量。
与依赖手工数据增强来创建和处理每个图像的多个视图的视图不变性方法(如iBOT)相比,I-JEPA的运行速度也明显更快。特别是,最大的I-JEPA模型(ViT-H/14)所需的计算量比最小的iBOT模型(ViT-S/16)要少。
此外,结果还表明,I-JEPA可以从使用更大的数据集进行预训练中受益。当增加预训练数据集(IN1K与IN22K)的大小时,语义和低级任务的转移学习性能也会得到提高。表5还显示,在IN22K上预训练时,I-JEPA也可以从更大的模型大小中受益。与ViT-H/14模型相比,预训练ViT-G/16模型可以显著提高Place205和INat18等图像分类任务的下游性能。但是,ViT-G/16模型对低级下游任务没有改善。ViT-G/16使用更大的输入补丁大小,这可能会对局部预测任务造成不利影响。
总之,I-JEPA具有较高的可扩展性,可以从使用更大的数据集进行预训练和更大的模型大小中受益。它可以在不依赖手工数据增强的情况下取得良好的性能,并且比以前的方法更加高效。
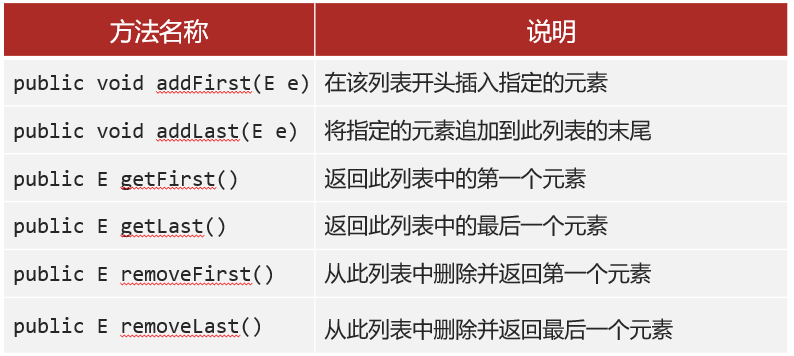
预测器可视化

通过以上可视化结果,可以看到,I-JEPA预测器能够正确捕捉位置不确定性,并产生具有正确姿势的高级物体部件(例如鸟的背部和汽车的顶部)。但是,美中不足的是,它抛弃了精确的low-level图像细节以及背景信息。
总结
I-JEPA是一种简单有效的学习语义图像表示的方法,不依赖于手工数据增强。通过在表示空间中预测,I-JEPA比像素重建方法收敛更快,并学习到高语义水平的表示。与基于视图不变性的方法相比,I-JEPA提出了一种学习通用表示的联合嵌入架构的方法,而不依赖于手工制作的视图增强。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1]https://arxiv.org/pdf/2301.08243.pdf