一、核主成分
1.1 和PCA的区别
PCA (主成分分析)对应一个线性高斯模型(参考书的第二章),其基本假设是数据由一个符合正态分布的隐变量通过一个线性映射得到,因此可很好描述符合高斯分布的数据。然而在很多实际应用中数据的正态性不能保证,这时用PCA建模通常会产生较大偏差。这时可以设计一个合理的非线性映射,将原始数据映射到特征空间,使数据在该空间的映射具有高斯性,在这个基础可进行有效的PCA建模。即通过核函数间接映射到特征空间再间接进行建模,所以称为核主成分分析;
1.2 推导过程
定义原始数据空间样本为,非线性映射为
,且在原始空间和特征空间满足如下归一化条件。
1------(1)
在映射空间的协方差矩阵可写作:
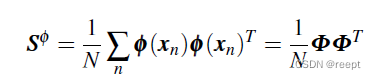 1----(2)
1----(2)
上式中,假设有m维,则
有m*m维。其中
![]() ,在特征空间中求主成分v等价于求
,在特征空间中求主成分v等价于求的特征向量:
1----(3)
整理以上两式可得:
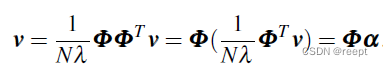 1-----(4)
1-----(4)
其中: , 是一个N维向量,其中每一维对应一个数据点与特征向量v的内积,同时,上式说明在特征空间的特征向量v由所有数据样本的向量加权平均得到,权重为
,转化为对偶问题。将
代回式 1 ----(4) :
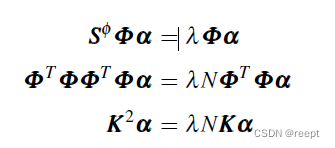 1----(5)、1-----(6)、1----(7)
1----(5)、1-----(6)、1----(7)
其中 K为gram阵,![]() 上式1—(7)右项左移,可以看出K选择合适的核函数,会使K不等于空矩阵,因而可以推出:
上式1—(7)右项左移,可以看出K选择合适的核函数,会使K不等于空矩阵,因而可以推出:
1——(8) 为1——(7)式的必要条件
考虑特征向量v应满足 =1 ,而 v=
,有:
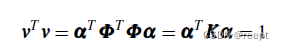 1-----(9)
1-----(9)
将1---(8)式左乘并代入上式,有:
1----(10)
可以通过下式求解:
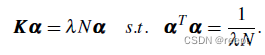 1------(11)
1------(11)
上式求解特征向量的方法是,求解左式的特征向量,再取 =
就可以求得满足约束的特征向量。解出
后,即可基于1—(4)式得到在特征空间的主成分向量。和标准PCA类似,我们可以求得多个主成分,组成主成分向量集{
}。
基于{}可对任意测试样本
降维,且等价于在特征空间中计算
在各个主成分
上的投影,计算如下:
![]() 1———(12)
1———(12)
上式 表示特征向量
对应的权重的第n维(n=1.....N)。
虽然我们的目的是在特征空间进行主成分提取并给予得到的主成分对数据进行降为,但不需要在特征空间进行操作,所有计算都在原始空间中以核函数方式进行,计算得到的结果等价于在特征空间中进行。这使得可以在非常复杂的特征空间中对数据进行PCA建模,从而解决了原始数据的非高斯化问题,使PCA具有灵活性和可扩展性。
二、总结
本文是学习《机器学习导论》(清华大学出版社,中文版,王东,2021年)的摘录总结或笔记。