搭建知识库
- 一. 词向量和向量知识库
- 1. 词向量
- 1.词向量概念
- 2.词向量优势
- 3. 一般构建词向量的方法
- 2.向量数据库
- 二. 使用Embedding API
- 三. 数据处理
- 一.读取文档
- 1. PDF 文档
- 2.MD 文档
- 二.数据清洗
- 三.文档分割
- 四.搭建并使用向量数据库
- 一.前序工作
- 二. 构建Chroma向量库
- 三、向量检索
- 3.1 相似度检索
- 3.2 MMR检索
一. 词向量和向量知识库
1. 词向量
1.词向量概念
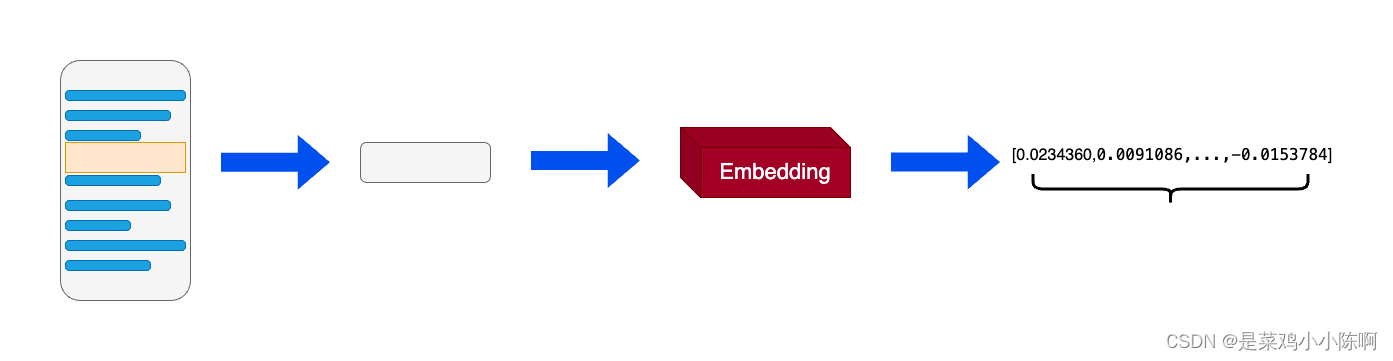
在机器学习和自然语言处理(NLP)中,词向量(Embeddings)是一种将非结构化数据,如单词、句子或者整个文档,转化为实数向量的技术。这些实数向量可以被计算机更好地理解和处理。
2.词向量优势
1.词向量比文字更适合检索。词向量中包含了原文本的语义信息,可以通过计算问题与数据库中数据的点积、余弦距离、欧几里得距离等指标,直接获取问题与数据在语义层面上的相似度;
2.词向量可以通过多种向量模型将多种数据映射成统一的向量形式。
3. 一般构建词向量的方法
- 使用各个公司的 Embedding API
- 在本地使用嵌入模型将数据构建为词向量
2.向量数据库
向量数据库是用于高效计算和管理大量向量数据的解决方案。向量数据库是一种专门用于存储和检索向量数据(embedding)的数据库系统。它与传统的基于关系模型的数据库不同,它主要关注的是向量数据的特性和相似性。
向量数据库的原理及核心优势
向量数据库中的数据以向量作为基本单位,对向量进行存储、处理及检索。
向量数据库通过计算与目标向量的余弦距离、点积等获取与目标向量的相似度。当处理大量甚至海量的向量数据时,向量数据库索引和查询算法的效率明显高于传统数据库。
主流的向量数据库
* Chroma
* Weaviate
* Qdrant
* [Milvus](Milvus的概述 (milvus-io.com))
二. 使用Embedding API
本文使用智谱API
from zhipuai import ZhipuAI
def zhipu_embedding(text: str):
api_key = os.environ['ZHIPUAI_API_KEY']
client = ZhipuAI(api_key=api_key)
response = client.embeddings.create(
model="embedding-2",
input=text,
)
return response
text = '要生成 embedding 的输入文本,字符串形式。'
response = zhipu_embedding(text=text)
response为zhipuai.types.embeddings.EmbeddingsResponded类型,可以调用object、data、model、usage来查看response的embedding类型、embedding、embedding model及使用情况。
print(f'response类型为:{type(response)}')
print(f'embedding类型为:{response.object}')
print(f'生成embedding的model为:{response.model}')
print(f'生成的embedding长度为:{len(response.data[0].embedding)}')
print(f'embedding(前10)为: {response.data[0].embedding[:10]}')
返回结果
response类型为:<class 'zhipuai.types.embeddings.EmbeddingsResponded'>
embedding类型为:list
生成embedding的model为:embedding-2
生成的embedding长度为:1024
embedding(前10)为: [0.017893229, 0.064432174, -0.009351327, 0.027082685, 0.0040648775, -0.05599671, -0.042226028, -0.030019397, -0.01632937, 0.067769825]
三. 数据处理
源文档:
* 《机器学习公式详解》PDF版本
* 《面向开发者的LLM入门教程、第一部分Prompt Engineering》md版本
一.读取文档
1. PDF 文档
安装对应包
pip install -U langchain-community
pip install pymupdf
from langchain.document_loaders.pdf import PyMuPDFLoader
# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径
loader = PyMuPDFLoader("../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf")
# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载
pdf_pages = loader.load()
文档加载后储存在 pages 变量中:
- page 的变量类型为 List
- 打印 pages 的长度可以看到 pdf 一共包含多少页
print(f"载入后的变量类型为:{type(pdf_pages)},", f"该 PDF 一共包含 {len(pdf_pages)} 页")
载入后的变量类型为:<class 'list'>, 该 PDF 一共包含 196 页
page 中的每一元素为一个文档,变量类型为 langchain_core.documents.base.Document, 文档变量类型包含两个属性
- page_content 包含该文档的内容。
- meta_data 为文档相关的描述性数据。
pdf_page = pdf_pages[1]
print(f"每一个元素的类型:{type(pdf_page)}.",
f"该文档的描述性数据:{pdf_page.metadata}",
f"查看该文档的内容:\n{pdf_page.page_content}",
sep="\n------\n")
2.MD 文档
安装对应包
pip install markdown
from langchain.document_loaders.markdown import UnstructuredMarkdownLoader
loader = UnstructuredMarkdownLoader("../../data_base/knowledge_db/prompt_engineering/1. 简介 Introduction.md")
md_pages = loader.load()
print(f"载入后的变量类型为:{type(md_pages)},", f"该 Markdown 一共包含 {len(md_pages)} 页")
md_page = md_pages[0]
print(f"每一个元素的类型:{type(md_page)}.",
f"该文档的描述性数据:{md_page.metadata}",
f"查看该文档的内容:\n{md_page.page_content[0:][:200]}",
sep="\n------\n")
二.数据清洗
-
上文中读取的pdf文件不仅将一句话按照原文的分行添加了换行符
\n,也在原本两个符号中间插入了\n,可以使用正则表达式匹配并删除掉\n。import re pattern = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL) pdf_page.page_content = re.sub(pattern, lambda match: match.group(0).replace('\n', ''), pdf_page.page_content) print(pdf_page.page_content) -
数据中还有不少的
•和空格,使用replace方法即可pdf_page.page_content = pdf_page.page_content.replace('•', '') pdf_page.page_content = pdf_page.page_content.replace(' ', '') print(pdf_page.page_content) -
上文中读取的md文件每一段中间隔了一个换行符,同样可以使用replace方法去除
md_page.page_content = md_page.page_content.replace('\n\n', '\n') print(md_page.page_content)
三.文档分割
由于单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力。
因此,在构建向量知识库的过程中,往往需要对文档进行分割,将单个文档按长度或者按固定的规则分割成若干个 chunk,然后将每个 chunk 转化为词向量,存储到向量数据库中。
在检索时,我们会以 chunk 作为检索的元单位,也就是每一次检索到 k 个 chunk 作为模型可以参考来回答用户问题的知识,这个 k 是我们可以自由设定的。
Langchain 中文本分割器都根据 chunk_size (块大小)和 chunk_overlap (块与块之间的重叠大小)进行分割。

-
chunk_size 指每个块包含的字符或 Token (如单词、句子等)的数量
-
chunk_overlap 指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息
Langchain 提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符/token组成、以及如何测量块大小
- RecursiveCharacterTextSplitter(): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
- CharacterTextSplitter(): 按字符来分割文本。
- MarkdownHeaderTextSplitter(): 基于指定的标题来分割markdown 文件。
- TokenTextSplitter(): 按token来分割文本。
- SentenceTransformersTokenTextSplitter(): 按token来分割文本
- Language(): 用于 CPP、Python、Ruby、Markdown 等。
- NLTKTextSplitter(): 使用 NLTK(自然语言工具包)按句子分割文本。
- SpacyTextSplitter(): 使用 Spacy按句子的切割文本。
'''
* RecursiveCharacterTextSplitter 递归字符文本分割
RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]),
这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置
RecursiveCharacterTextSplitter需要关注的是4个参数:
* separators - 分隔符字符串数组
* chunk_size - 每个文档的字符数量限制
* chunk_overlap - 两份文档重叠区域的长度
* length_function - 长度计算函数
'''
#导入文本分割器
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 知识库中单段文本长度
CHUNK_SIZE = 500
# 知识库中相邻文本重合长度
OVERLAP_SIZE = 50
# 使用递归字符文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=OVERLAP_SIZE
)
text_splitter.split_text(pdf_page.page_content[0:1000])
split_docs = text_splitter.split_documents(pdf_pages)
print(f"切分后的文件数量:{len(split_docs)}")
print(f"切分后的字符数(可以用来大致评估 token 数):{sum([len(doc.page_content) for doc in split_docs])}")
切分后的文件数量:720
切分后的字符数(可以用来大致评估 token 数):308931
四.搭建并使用向量数据库
一.前序工作
1.加载api
2.加载数据
3.数据清洗、数据分割
import os
from dotenv import load_dotenv, find_dotenv
# 读取本地/项目的环境变量。
# find_dotenv()寻找并定位.env文件的路径
# load_dotenv()读取该.env文件,并将其中的环境变量加载到当前的运行环境中
# 如果你设置的是全局的环境变量,这行代码则没有任何作用。
_ = load_dotenv(find_dotenv())
# 如果你需要通过代理端口访问,你需要如下配置
# os.environ['HTTPS_PROXY'] = 'http://127.0.0.1:7890'
# os.environ["HTTP_PROXY"] = 'http://127.0.0.1:7890'
# 获取folder_path下所有文件路径,储存在file_paths里
file_paths = []
folder_path = '../../data_base/knowledge_db'
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
file_paths.append(file_path)
print(file_paths[:3])
加载数据
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.document_loaders.markdown import UnstructuredMarkdownLoader
# 遍历文件路径并把实例化的loader存放在loaders里
loaders = []
for file_path in file_paths:
file_type = file_path.split('.')[-1]
if file_type == 'pdf':
loaders.append(PyMuPDFLoader(file_path))
elif file_type == 'md':
loaders.append(UnstructuredMarkdownLoader(file_path))
# 下载文件并存储到text
texts = []
for loader in loaders: texts.extend(loader.load()
text = texts[1]
print(f"每一个元素的类型:{type(text)}.",
f"该文档的描述性数据:{text.metadata}",
f"查看该文档的内容:\n{text.page_content[0:]}",
sep="\n------\n")
载入后的变量类型为langchain_core.documents.base.Document, 文档变量类型同样包含两个属性
- page_content 包含该文档的内容。
- meta_data 为文档相关的描述性数据。
每一个元素的类型:<class 'langchain_core.documents.base.Document'>.
------
该文档的描述性数据:{'source': '../../data_base/knowledge_db/prompt_engineering/2. 提示原则 Guidelines.md'}
------
分割文档
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 切分文档
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=50)
split_docs = text_splitter.split_documents(texts)
二. 构建Chroma向量库
安装环境
pip install chroma
# 使用 OpenAI Embedding
# from langchain.embeddings.openai import OpenAIEmbeddings
# 使用百度千帆 Embedding
# from langchain.embeddings.baidu_qianfan_endpoint import QianfanEmbeddingsEndpoint
# 使用我们自己封装的智谱 Embedding,需要将封装代码下载到本地使用
from zhipuai_embedding import ZhipuAIEmbeddings
# 定义 Embeddings
# embedding = OpenAIEmbeddings()
embedding = ZhipuAIEmbeddings()
# embedding = QianfanEmbeddingsEndpoint()
# 定义持久化路径
persist_directory = '../data_base/vector_db/chroma'# '../../data_base/vector_db/chroma'
!rm -rf '../data_base/vector_db/chroma' # 删除旧的数据库文件(如果文件夹中有文件的话),windows电脑请手动删除
from langchain.vectorstores.chroma import Chroma
vectordb = Chroma.from_documents(
documents=split_docs[:20], # 为了速度,只选择前 20 个切分的 doc 进行生成;使用千帆时因QPS限制,建议选择前 5 个doc
embedding=embedding,
persist_directory=persist_directory # 允许我们将persist_directory目录保存到磁盘上
)
vectordb.persist 来持久化向量数据库,以便后续使用。
vectordb.persist()
三、向量检索
3.1 相似度检索
Chroma的相似度搜索使用的是余弦距离,即:
s
i
m
i
l
a
r
i
t
y
=
c
o
s
(
A
,
B
)
=
A
⋅
B
∥
A
∥
∥
B
∥
=
∑
1
n
a
i
b
i
∑
1
n
a
i
2
∑
1
n
b
i
2
similarity = cos(A, B) = \frac{A \cdot B}{\parallel A \parallel \parallel B \parallel} = \frac{\sum_1^n a_i b_i}{\sqrt{\sum_1^n a_i^2}\sqrt{\sum_1^n b_i^2}}
similarity=cos(A,B)=∥A∥∥B∥A⋅B=∑1nai2∑1nbi2∑1naibi
其中
a
i
a_i
ai、
b
i
b_i
bi分别是向量
A
A
A、
B
B
B的分量。
question="什么是大语言模型"
sim_docs = vectordb.similarity_search(question,k=3)
print(f"检索到的内容数:{len(sim_docs)}")
for i, sim_doc in enumerate(sim_docs):
print(f"检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")
检索到的内容数:3
检索到的第0个内容:
开发大模型相关应用时请务必铭记:
虚假知识:模型偶尔会生成一些看似真实实则编造的知识
在开发与应用语言模型时,需要注意它们可能生成虚假信息的风险。尽管模型经过大规模预训练,掌握了丰富知识,但它实际上并没有完全记住所见的信息,难以准确判断自己的知识边界,可能做出错误推断。若让语言模型描述一个不存在的产品,它可能会自行构造出似是而非的细节。这被称为“幻觉”(Hallucination),是语言模型
--------------
检索到的第1个内容:
与基础语言模型不同,指令微调 LLM 通过专门的训练,可以更好地理解并遵循指令。举个例子,当询问“法国的首都是什么?”时,这类模型很可能直接回答“法国的首都是巴黎”。指令微调 LLM 的训练通常基于预训练语言模型,先在大规模文本数据上进行预训练,掌握语言的基本规律。在此基础上进行进一步的训练与微调(finetune),输入是指令,输出是对这些指令的正确回复。有时还会采用RLHF(reinforce
--------------
检索到的第2个内容:
网络上有许多关于提示词(Prompt, 本教程中将保留该术语)设计的材料,例如《30 prompts everyone has to know》之类的文章,这些文章主要集中在 ChatGPT 的 Web 界面上,许多人在使用它执行特定的、通常是一次性的任务。但我们认为,对于开发人员,大语言模型(LLM) 的更强大功能是能通过 API 接口调用,从而快速构建软件应用程序。实际上,我们了解到 Deep
--------------
3.2 MMR检索
如果只考虑检索出内容的相关性会导致内容过于单一,可能丢失重要信息。
最大边际相关性 (MMR, Maximum marginal relevance) 可以帮助我们在保持相关性的同时,增加内容的丰富度。
question="什么是大语言模型"
mmr_docs = vectordb.max_marginal_relevance_search(question,k=3)
for i, sim_doc in enumerate(mmr_docs):
print(f"MMR 检索到的第{i}个内容: \n{sim_doc.page_content[:200]}", end="\n--------------\n")
MMR 检索到的第0个内容:
开发大模型相关应用时请务必铭记:
虚假知识:模型偶尔会生成一些看似真实实则编造的知识
在开发与应用语言模型时,需要注意它们可能生成虚假信息的风险。尽管模型经过大规模预训练,掌握了丰富知识,但它实际上并没有完全记住所见的信息,难以准确判断自己的知识边界,可能做出错误推断。若让语言模型描述一个不存在的产品,它可能会自行构造出似是而非的细节。这被称为“幻觉”(Hallucination),是语言模型
--------------
MMR 检索到的第1个内容:
与基础语言模型不同,指令微调 LLM 通过专门的训练,可以更好地理解并遵循指令。举个例子,当询问“法国的首都是什么?”时,这类模型很可能直接回答“法国的首都是巴黎”。指令微调 LLM 的训练通常基于预训练语言模型,先在大规模文本数据上进行预训练,掌握语言的基本规律。在此基础上进行进一步的训练与微调(finetune),输入是指令,输出是对这些指令的正确回复。有时还会采用RLHF(reinforce
--------------
MMR 检索到的第2个内容:
相反,我们应通过 Prompt 指引语言模型进行深入思考。可以要求其先列出对问题的各种看法,说明推理依据,然后再得出最终结论。在 Prompt 中添加逐步推理的要求,能让语言模型投入更多时间逻辑思维,输出结果也将更可靠准确。
综上所述,给予语言模型充足的推理时间,是 Prompt Engineering 中一个非常重要的设计原则。这将大大提高语言模型处理复杂问题的效果,也是构建高质量 Promp
--------------