目录
一、什么是布隆过滤器?
二、布隆过滤器的原理
三、布隆过滤器的特点
一、什么是布隆过滤器?
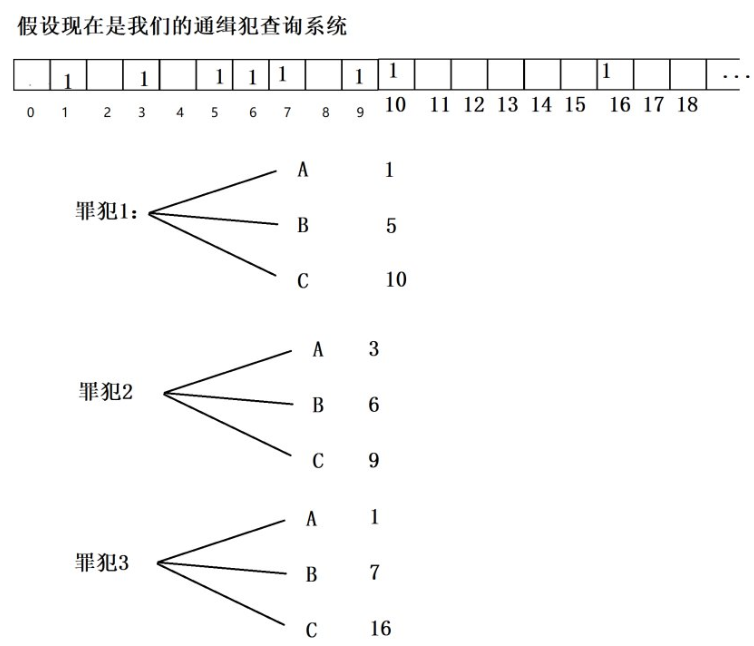
布隆过滤器是一种空间效率高、适合快速检索的数据结构,用于判断一个元素是否可能存在于一个集合中。它通过使用多个哈希函数和一个位数组来表示集合中的元素。当一个元素被加入到布隆过滤器中时,会通过多个哈希函数计算出多个哈希值,并在对应的位上标记为1;当判断一个元素是否在集合中时,同样会通过多个哈希函数计算出多个哈希值,并检查对应位的值,只有当所有哈希值对应的位都为1时,才会判断可能存在于集合中。
布隆过滤器具有较高的空间效率和查询速度,但也存在一定的误判率,即可能将不在集合中的元素误判为存在于集合中。因此,布隆过滤器通常在需要快速判断元素是否可能存在于一个大型集合中,而可以容忍一定误判率的场景下使用。
简而言之,布隆过滤器 == 一个非常的二进制矢量数组 + 一组哈希函数
二、布隆过滤器的原理
布隆过滤器是一种空间效率高、时间复杂度低的数据结构,用于快速判断一个元素是否可能存在于一个集合中。
其原理如下:
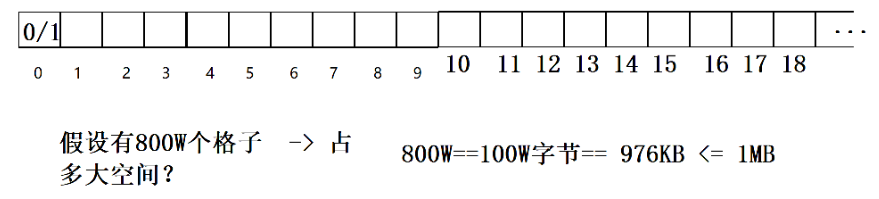
- 布隆过滤器由一个位数组(Bit Array)和多个哈希函数组成。
- 初始化时将位数组的所有位都设为0。
- 当需要将一个元素加入集合时,通过多个哈希函数将该元素映射到位数组中的位置,并将这些位置的位设为1。
- 当需要判断一个元素是否存在于集合中时,同样通过多个哈希函数将该元素映射到位数组中的位置,若其中任意一位为0,则该元素一定不存在于集合中;若所有位均为1,则该元素可能存在于集合中(有一定的误判率)。
- 布隆过滤器不支持删除操作,因为删除一个元素会影响到其他元素的映射结果。
需要注意的是,由于存在一定的误判率(即可能存在虚假正例),在实际应用中需要根据误判率的可接受范围和数据规模选择合适的位数组大小和哈希函数数量。
三、布隆过滤器的特点
布隆过滤器是一种空间效率高,适合大规模数据去重应用的数据结构。其主要特点包括:
-
高效的数据查找:布隆过滤器通过哈希函数将元素映射到一个位数组中,并且可以在 O(1) 的时间复杂度内判断一个元素是否存在于集合中,因此查找效率非常高。
-
空间效率高:布隆过滤器只需要较小的位数组和若干个哈希函数来实现数据去重的功能,相比于传统的数据结构,布隆过滤器占用的空间通常更少。
-
可能出现误判:由于多个元素可能会映射到同一个位上,所以在判断某个元素是否存在于布隆过滤器中时,可能会出现误判(即布隆过滤器判断元素存在但实际上不存在),但不存在漏判(即布隆过滤器判断元素不存在但实际上存在)。
-
不支持删除操作:由于设计初衷是用于数据去重,布隆过滤器在添加元素后,一旦位被置为1,就无法再将其改回0,因此不支持元素的删除操作。
-
可以在大规模数据集合中快速判断元素是否存在:由于其高效的查找速度和较小的空间占用,布隆过滤器在处理大规模数据去重问题时具有明显的优势。