jdk线程池,是java后端处理异步任务的主要解决方案,使用广泛。jdk线程池相关的面经,网上很多,但是鱼龙混杂,很多瞎写的。要想真正了解原理,还是要看源码。所以,写一篇文章,深入的了解一下
文章目录
- 1、关于线程池的问题
- 2、线程池的使用及核心参数
- 3、前置知识
- 3.1、线程池的工作状态
- 3.2、ctl变量
- 3.3、线程池的线程数量获取
- 3.4、线程池运行状态获取
- 3.5、Worker线程
- 4、线程池的工作流程源码解析
- 4.1、核心线程未满,新来的请求都新建一个Worker执行任务
- 4.1.1、判断核心线程是否已满
- 4.1.2、增加一个Worker线程并启动
- 4.1.3、Worker线程的启动疑问及答案
- 4.1.4、Worker线程执行任务
- 4.2、核心线程已满,新来的请求缓存进队列
- 4.3、队列已满,继续创建线程至最大线程数
- 4.4、已达最大线程,执行拒绝策略
- 4.4.1、拒绝策略的分类
1、关于线程池的问题
先列几个关于线程池,被问到最多的问题
1)、线程池的线程是怎么被复用的?
2)、线程池的工作流程,反应到源码上,是怎么样的?
当然,你可能会有其他问题,那样就更好了,带着问题看文章,比无目的浏览文章,收获要大。这里说点题外话,相比于解决方案,一个好的问题,我认为要更难得。因为,问题往往意味着思考。
2、线程池的使用及核心参数
一般情况下,我都是使用不带返回值的API多一点,所以今天就以execute方法举例。先来一个demo,如下:
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
5,
10,
60L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10));
threadPoolExecutor.execute(() -> System.out.println("正在执行任务"));
我们使用的是ThreadPoolExecutor的构造器构建的线程池,我也推荐大家用这种方式构建线程池,相比于Executors的那些静态方法构建的线程池,要容易控制。
看一下ThreadPoolExecutor的构造器全参数有哪些,以及具体参数含义
ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
1)、corePoolSize:核心线程数。核心线程只是一个概念,并没有规定哪些线程就是核心线程。比如:我们规定核心线程数是5,最终线程池中留下来的线程就是核心线程,这些线程可能是先创建,也可以是后创建
2)、maximumPoolSize:最大线程数。如果队列放不下了,如果maximumPoolSize的值大于corePoolSize,此时就会继续创建线程至maximumPoolSize
3)、keepAliveTime:非核心线程存活时间。如果线程池的线程数超过了核心线程数,此时如果超过keepAliveTime时间后,还是没有获取到任务的话,就会开始减少线程数量,一直到核心线程数
4)、unit:keepAliveTime的时间单位
5)、workQueue:队列
6)、threadFactory:线程工厂。顾名思义,生产线程的工厂。这个线程工厂最好能自己定义一个和业务相关的,这样好排查问题
7)、handler:拒绝策略。当队列满了,已达最大线程时。就会执行拒绝策略
线程池的这几个参数,大家先了解下,随着下面的介绍,大家会对每一个参数的含义有更深的了解
3、前置知识
有一些知识,先提前说下。都是下面即将介绍的源码中多次遇到的,提前说清楚,后面看源码的时候,会更流畅
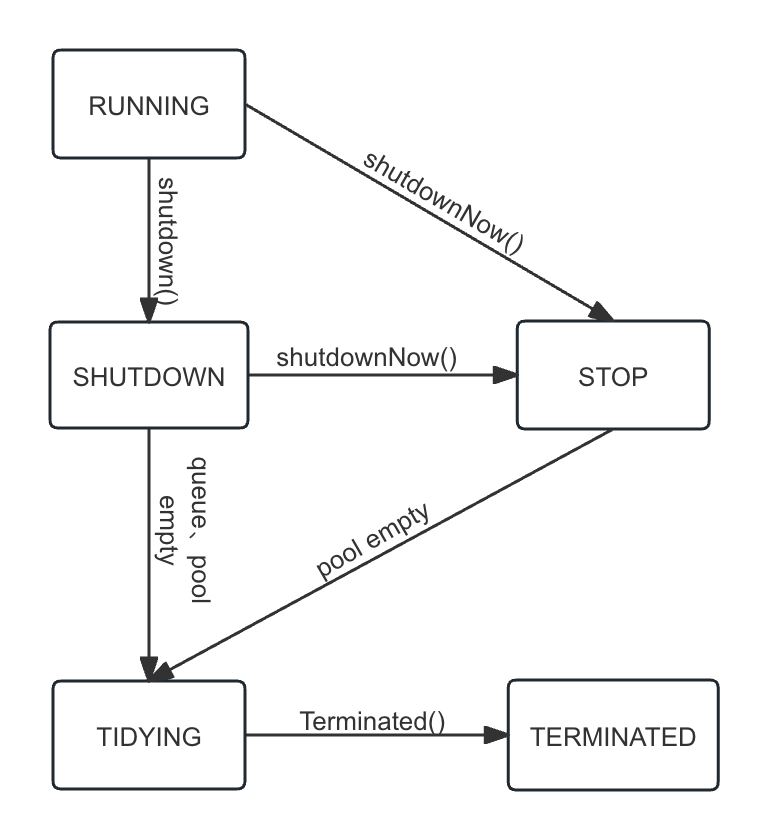
3.1、线程池的工作状态
线程池有5种状态
1)、RUNNING
2)、SHUTDOWN
3)、STOP
4)、TIDYING
5)、TERMINATED
这5种状态是5个int值。
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
这几个值,我们打印一下看看
-536870912
0
536870912
1073741824
1610612736
可以看到,从RUNNING到TERMINATED是逐渐增大的,这个特点需要记一下,源码中对于线程状态的判断,就是用这个int值进行比较实现的
5个状态流转的流程图
3.2、ctl变量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
ctl变量,存储了2个值,啥意思呢
我们知道int值是4个字节,反应到bit上,一共32个bit。每一位bit可以是0或1,这其实有很多组合方式。Doug lea大神就将这32个bit位拆分为了2部分。高位部分代表了线程池运行状态,低位部分代表线程池的线程数量。至于高位的多少位代表线程池运行状态以及低位的多少位代表线程池线程数量,下面会提到。这里,我们只要知道这个ctl代表了2部分含义即可。
3.3、线程池的线程数量获取
源码中获取线程池线程数量的逻辑如下:
private static int workerCountOf(int c) {
return c & CAPACITY;
}
c是当前ctl的值。
操作符是&符号,这是二进制操作符
CAPACITY的值,用二进制表示如下:
00011111111111111111111111111111
低29位都是1,高3位都是0。所以ctl和CAPACITY进行与操作,结果值的二级制位都会落在ctl二进制值的低29位
所以我们很容易得到低29位用来代表线程数量。相应的,高3位用来代表线程池运行状态
写到这里,如何从ctl中获取线程池的线程数量,应该说明白了
3.4、线程池运行状态获取
源码中获取线程池运行状态的逻辑如下:
private static int runStateOf(int c){
return c & ~CAPACITY;
}
~CAPACITY的二进制如下:
11100000000000000000000000000000
高3位都是1,低29位都是0
我们看一下线程池的5种状态值对应的二进制
1)、RUNNING:
11100000000000000000000000000000
2)、SHUTDOWN:
0
3)、STOP:
00100000000000000000000000000000
4)、TIDYING:
01000000000000000000000000000000
5)、TERMINATED:
01100000000000000000000000000000
可以看到,状态值的二进值bit位都集中在高3位。所以ctl和~CAPACITY进行与操作,结果都落在ctl值的高3位
写到这里,如何从ctl中获取线程池的运行状态,应该也说明白了
3.5、Worker线程
Worker线程是什么?和我们直接new的一个线程一样吗?
先看一下Worker类的源码(去掉了一些非主流程的代码)
private final class Worker extends AbstractQueuedSynchronizer implements Runnable{
//初始化任务。可能为空
Runnable firstTask;
Worker(Runnable firstTask) {
//直到runWorker执行前,抑制中断
setState(-1);
//初始化任务赋值
this.firstTask = firstTask;
//创建一个线程
this.thread = getThreadFactory().newThread(this);
}
//将run方法代理到外部的runWorker方法上
public void run() {
runWorker(this);
}
//加锁
public void lock(){
acquire(1);
}
//释放锁
public void unlock(){
release(1);
}
}
从Worker类的实现上可以看出,Worker类继承了AQS,说明Worker类是具备加锁、解锁功能的。另外一个,Worker类还实现了Runnable接口,这就使得Worker类变成了一个线程。从这里可以看出Worker类和我们平时使用的线程差别不大。
但是有2个点需要特别提下。
1)、firstTask变量。这个变量,大家先记一下,它和线程池工作流程的第一步有关系
2)、run方法
firstTask变量,字面意思上看,意为:第一个任务。其实意思就是:未达核心线程数之前,每一个任务都会创建一个线程来处理任务,这种情况是不需要复用的,每个任务一个线程。
run方法,run方法中有一个runWorker方法,入参是this对象,也就是Worker类对象本身。从这个方法名上推测,就是运行Worker
4、线程池的工作流程源码解析
先把八股贴一下
jdk线程池的工作流程分为4步
1)、核心线程未满,新来的请求都新建一个线程执行任务
2)、核心线程已满,新来的请求缓存进队列
3)、队列已满,继续创建线程至最大线程数
4)、最大线程数已满,拒绝任务
4.1、核心线程未满,新来的请求都新建一个Worker执行任务
4.1.1、判断核心线程是否已满
这个过程,在源码中是怎么体现的呢?
我们看一下execute方法的源码,这里去掉了与该流程无关的代码
public void execute(Runnable command) {
......
int c = ctl.get();
//判断线程池数量是否小于核心线程
if (workerCountOf(c) < corePoolSize) {
//小于核心线程时,增加核心线程,直接执行任务
if (addWorker(command, true))
return;
}
......
}
这段代码,有2个点。
1)、判断线程池数量是否小于核心线程
2)、小于核心线程时,增加核心线程,直接执行任务
第一点,我们上面已经聊过了,主要就是使用ctl变量提取线程池线程数量的一个过程。现在直接看第二点就行了,也就是addWorker方法的实现
4.1.2、增加一个Worker线程并启动
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
//死循环添加Worker线程
for (;;) {
......
for (;;) {
//获取线程池当前Worker数量
int wc = workerCountOf(c);
//判断Worker数量是否已超过限定值
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
//超过限定值,直接返回。这样就会进入线程池工作流程的第二步,进入缓存队列或者直接拒绝任务
return false;
if (compareAndIncrementWorkerCount(c))//CAS增加Worker数量
break retry;
......
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//新增Worker线程处理任务,这里可以看到,firstTask任务作为构造器的入参传给了Worker线程
w = new Worker(firstTask);
//获取Worker类中的线程变量
final Thread t = w.thread;
if (t != null) {
......
if (workerAdded) {
//启动线程,开始处理任务
t.start();
workerStarted = true;
}
}
}
return workerStarted;
}
4.1.3、Worker线程的启动疑问及答案
我读到Worker线程启动这一段源码的时候,就有点纳闷源码中直接启动的就是Worker类的中thread,和我们的Worker类并没有关系啊。我们平时启动一个Runnable任务,通常是下面这样的
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("执行异步任务");
}
});
thread.start();
但是在源码中,并没有看到类似的代码。
这个问题的答案就在于Worker类的这个thread变量,我们看看这个thread是怎么生成的。
thread的生成是在Worker类的构造器中,我们在上面已经看过Worker类构造器的实现,再拿出来看一下
Worker(Runnable firstTask) {
//直到runWorker执行前,抑制中断
setState(-1);
//初始化任务赋值
this.firstTask = firstTask;
//创建一个线程
this.thread = getThreadFactory().newThread(this);
}
可以看到thread是通过线程工厂的一个newThread方法创建的,入参是Worker对象本身。threadFactory,是ThreadPoolExecutor的一个入参。如果未指定的话,有一个默认的threadFactory,默认实现很简单,就不提了。我们直接看newThread方法
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
new Thread的时候,将Worker作为参数传递进了Thread的构造器中,最终被赋予给了Thread对象的一个target变量。好了,知道Worker被赋予给了Thread对象target变量就可以了。为什么呢?
我们上面讲到,在线程池中,只启动了Worker类中的thread。我们知道java的Thread启动后,会执行Thread中的run方法,我们看一下Thread中的run方法
@Override
public void run() {
if (target != null) {
target.run();
}
}
看到target应该就明白了吧。直接就执行了target的run方法,这样就间接启动了Worker类中的run方法。这就和Worker类关联上了。在Worker类中的run方法,又调用了runWorker方法
4.1.4、Worker线程执行任务
public void run() {
runWorker(this);
}
runWorker方法的实现如下:
final void runWorker(Worker w) {
......
Runnable task = w.firstTask;
w.firstTask = null;
......
try {
//线程池首个任务不为空。或者从队列中获取到的任务不为空
while (task != null || (task = getTask()) != null) {
//加锁
w.lock();
......
try {
//任务执行前,执行前置方法
beforeExecute(wt, task);
.....
try {
//执行任务
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//任务执行完成,执行后置方法
afterExecute(task, thrown);
}
}
}
......
}
}
从Worker类中取出需要执行的任务firstTask。
如果firstTask不为空,则执行firstTask的run方法,这就相当于把我们定义的任务给执行了。如果firstTask为空,则执行getTask方法。getTask方法的逻辑如下:
private Runnable getTask() {
//最后一次拉取是否超时
boolean timedOut = false;
for (;;) {
int c = ctl.get();
//获取当前线程的数量
int wc = workerCountOf(c);
//worker是否会被杀掉的判断条件
//允许核心线程关闭或者当前线程数已经超过了核心线程
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//(worker数量大于最大线程数 或者 超过keepAliveTime后,还是未从队列中获取到任务)并且(worker数量大于1 或者 工作队列为空)
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
//这个wc > 1的意思是:如果我们允许销毁核心线程,那核心线程就会一直减。但是我们不能减没,因为最少也得留一个线程来处理队列中的任务。除非,我们的队列是空的。
//降低worker数量
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//从队列获取任务。如果设置了keepAliveTime,等待keepAliveTime时间后还是未获取到任务,会将timedOut变量置为true,这就代表最后一次拉取超时,说明队列中已经没有任务。
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
//返回从队列中获取到的任务
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
getTask方法,就是从队列中获取任务执行,那队列中的任务是何时放入的呢?看下一节
4.2、核心线程已满,新来的请求缓存进队列
继续回到ThreadPoolExecutor的execute方法中。如果已达核心线程,此时会将请求放入队列中缓存
//判断条件。线程池正在运行 && 队列可以继续接受任务
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//线程池没有在运行并且从队列移除任务成功
if (! isRunning(recheck) && remove(command))
//拒绝任务,此时会按照拒绝策略执行
reject(command);
else if (workerCountOf(recheck) == 0)
//如果线程数量是0,此时再次增加线程,但这批线程不是核心线程
addWorker(null, false);
}
这段逻辑比较简单,核心逻辑就是将任务放入队列中,中间有一些对线程池运行状态以及线程池线程数量的校验逻辑。新增加到队列中的任务,会继续被3.1中的getTask方法处理,这样整个循环就转起来了
4.3、队列已满,继续创建线程至最大线程数
还是在ThreadPoolExecutor的execute方法中,如果线程池没有在运行或者队列已满,此时就会执行这一逻辑
//队列已满,再次尝试添加线程
else if (!addWorker(command, false))
//最大线程添加失败,此时会拒绝任务,执行拒绝策略
reject(command);
4.4、已达最大线程,执行拒绝策略
3.3里我们看到添加线程失败后会执行拒绝方法reject。看一下reject方法的逻辑
final void reject(Runnable command) {
//handler是RejectedExecutionHandler接口
handler.rejectedExecution(command, this);
}
4.4.1、拒绝策略的分类
handler是RejectedExecutionHandler接口,这个接口有4种实现。我们分别看一下
1)、直接抛出异常。这是默认实现
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
2)、丢弃较早进入队列的任务
较早进入听着有点别扭。这里稍微展开说下。比如:我们使用的是ArrayBlockingQueue。这个队列内部存储元素是用数组来实现的。
从下标为0的位置开始入队,从下标为0的位置开始出队,典型的FIFO。较早进入的元素,也就是索引下标较小的位置存储的元素,如果使用这个拒绝策略,下标越小的会被丢弃。这样说,大家应该能理解吧。
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
public DiscardOldestPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}
可以看到,如果线程池没有关闭。会执行两步操作。较老的任务出队,以及再次尝试执行任务。所以丢弃较老的任务,并不是直接丢弃。这个小知识点,不看源码的话,是不知道的。
3)、静默丢弃任务
这个拒绝策略实现的rejectedExecution方法中,啥也没有,一个空方法实现。这也就代表着,任务投递进来,并不会执行。相当于静默抛弃任务
public static class DiscardPolicy implements RejectedExecutionHandler {
public DiscardPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
4)、主线程执行
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}
这个拒绝策略,直接就执行了Runnable任务的run方法,执行这个方法的线程和执行threadPoolExecutor.execute的线程是同一个线程。也就是主线程执行任务,相当于不走异步。显而易见,任务量大的情况下,会直接影响主线程的性能。当然也有好处,如果一些控制端,对响应时间不敏感,并且不想让任务执行失败,就可以选择这种拒绝策略,确保每一个任务都执行成功
以上,我们就借着jdk线程池的两道面试题,把线程池的execute方法的主要流程过了一遍。当然,ThreadPoolExecutor还有其他的方法,我们没有说到,包括很多实现的细节也并没有说到。但是,主流程已经清晰了,细节自己看看,不行的话,再查查,基本就能弄明白