目录
一、SpringBoot3.X整合logback配置1.1 log4j、logback、self4j 之间关系
1.2 SpringBoot3.X整合logback配置
二、日志可视化分析ElasticStack
2.1为什么要有Elastic Stack
2.2 什么是Elastic Stack
三、ElasticSearch8.X源码部署
四、Kibana源码部署
五、LogStash8.X源码安装部署
5.1 LogStash宏观配置文件组成
5.2 安装部署
六、FileBeat安装部署
6.1为什么要有FileBeat?
6.2FileBeat配置
七、ElasticStack全链路配置
7.1 Filebeat部署
本博文将详细阐述如何通过一系列技术栈——包括Filebeat、Logstash、Elasticsearch(ES)和Kibana——来处理、索引、存储并可视化nannanw-demo.log日志文件的整个过程。将详细介绍这些步骤,确保您能够轻松地检索、分析和洞察日志文件中的重要信息。
通过下面的流程,nannanw-demo.log日志文件将被Filebeat高效地收集,并通过Logstash进行必要的转换和过滤,然后发送到Elasticsearch集群中进行索引和存储。最终,用户将能够通过Kibana这个强大的数据可视化工具来检索和分析这些日志数据,从而获取有价值的业务洞察。
一、SpringBoot3.X整合logback配置
1.1 log4j、logback、slf4j 之间关系
SLF4J(Simple logging Facade for Java) 门面设计模式 |外观设计模式
把不同的日志系统的实现进行了具体的抽象化,提供统一的日志使用接口具体的日志系统就有log4j,logback等;
logback也是log4j的作者完成的,有更好的特性,可以取代log4j的一个日志框架, 是slf4j的原生实现
log4j、logback可以单独的使用,也可以绑定slf4j一起使用
编码规范建议不直接用log4j、logback的API,应该用slf4j, 日后更换框架所带来的成本就很低
1.2 SpringBoot3.X整合logback配置
打印代码:
private static final Logger logger =
LoggerFactory.getLogger(ProductController.class);
@RequestMapping("findById")
public Object findById(@RequestParam("id") long id ){
ProductDO productDO = productService.findById(id);
logger.info("这个是查询接口日志,info级别");
logger.error("这个是查询接口日志,error级别");
return productDO;
}
配置文件
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="LOG_HOME" value="./logs" />
<!--采用打印到控制台,记录日志的方式-->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!-- 采用保存到日志文件 记录日志的方式,
%d{yyyy-MM-dd HH:mm:ss.SSS}:输出日志发生的时间,精确到毫秒。
[%thread]:输出日志所在的线程名。
%-5level:输出日志级别,使用占位符%5level可以保持日志级别的对齐。
%logger{36}:输出日志所在的类名(只输出类名的后36个字符)。
%msg:输出日志消息。
%n:新行。
-->
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/nannanw-demo.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/nannanw-demo-%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!-- 指定某个类单独打印日志 logger是配置某个包或者类采用哪几个appender记录日志,比如控制台/文件;-->
<logger name="net.nannanw.service.impl.LogServiceImpl"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
<appender-ref ref="console" />
</logger>
<root level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
</root>
</configuration>
二、日志可视化分析ElasticStack
2.1为什么要有Elastic Stack
操作系统、网关、应用程序产生了很多日志,有单机有分布式部署,怎么看方便?
日志数据,字段格式参差不齐,如果进行过滤处理?
服务器多肉眼查看日志不方便,是否有各种图表、仪表盘,将数据分析结果以可视化的方式展示出来,更好理解和分析数据?
2.2 什么是Elastic Stack
它是一个开源的数据分析和可视化平台,由Elasticsearch、Logstash、Kibana和Beats组成,广泛用于实时数据分析、搜索和可视化
我们之前说的ELK实际上是分别由Elasticsearch、 Logstash、Kibana组成
在这两年发展的过程中有新成员Beats的加入,所以就形成了Elastic Stack,ELK是旧的称呼,Elastic Stack是新的名字
常见的数据采集流程:Beats 采集(Filebeat/Metricbeat)–> Logstash –> Elasticsearch –> Kibana
Elasticsearch:一个分布式实时搜索和分析引擎,能够快速地存储、搜索和分析大量结构化和非结构化数据,它是Elastic Stack的核心组件,提供分布式数据存储和搜索能力。
Logstash:是一个用于数据收集、转换和传输的数据处理引擎,支持从各种来源(如文件、日志、数据库等)收集数据
可以对数据进行结构化、过滤和转换,然后将数据发送到Elasticsearch等目标存储或分析系统。
Kibana:数据可视化和仪表盘工具,连接到Elasticsearch,通过简单易用的用户界面创建各种图表、图形和仪表盘
Beats:是轻量级的数据收集器,用于收集和发送各种类型的数据到Elasticsearch或Logstash
Beats提供了多种插件和模块,用于收集和传输日志、指标数据、网络数据和安全数据等
总结:Elastic Stack的架构主要是将各个组件连接起来形成数据处理和分析的流程
三、ElasticSearch8.X源码部署
1.上传安装包和解压:
tar -zxvf elasticsearch-8.4.1-linux-x86_64.tar.gz

2.新建一个用户,安全考虑,elasticsearch默认不允许以root账号运行
创建用户:useradd es_user
设置密码:passwd es_user

3.修改目录权限
# chmod是更改文件的权限
# chown是改改文件的属主与属组
# chgrp只是更改文件的属组。
chgrp -R es_user /usr/local/software/elk_test/elasticsearch-8.4.1
chown -R es_user /usr/local/software/elk_test/elasticsearch-8.4.1
chmod -R 777 /usr/local/software/elk_test/elasticsearch-8.4.1

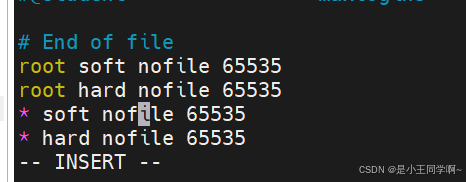
4.修改文件和进程最大打开数,需要root用户,如果系统本身有这个文件最大打开数和进程最大打开数配置,则不用
在文件内容最后添加后面两行(切记*不能省略)
vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535

5.修改虚拟内存空间,默认太小
在配置文件中改配置 最后一行上加上,执行 sysctl -p(立即生效)
vim /etc/sysctl.conf
vm.max_map_count=262144
6.修改elasticsearch的JVM内存,机器内存不足,常规线上推荐16到24G内存
vim config/jvm.options
-Xms1g
-Xmx1g

7.修改 elasticsearch相关配置
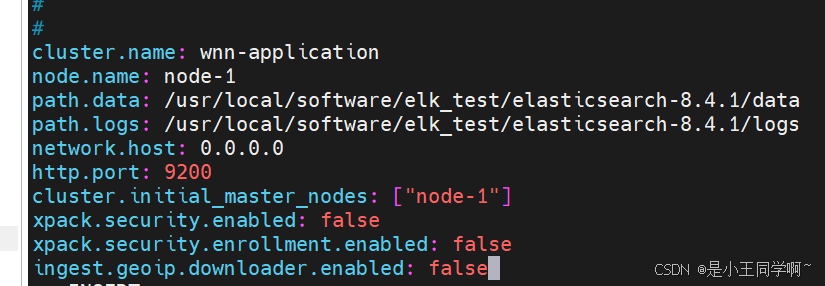
vim config/elasticsearch.yml
cluster.name: nannanw-application
node.name: node-1
path.data: /usr/local/software/elk_test/elasticsearch-8.4.1/data
path.logs: /usr/local/software/elk_test/elasticsearch-8.4.1/logs
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
xpack.security.enabled: false
xpack.security.enrollment.enabled: false
ingest.geoip.downloader.enabled: false

8.配置说明
cluster.name: 指定Elasticsearch集群的名称。所有具有相同集群名称的节点将组成一个集群。
node.name: 指定节点的名称。每个节点在集群中应该具有唯一的名称。
path.data: 指定用于存储Elasticsearch索引数据的路径。
path.logs: 指定Elasticsearch日志文件的存储路径。
network.host: 指定节点监听的网络接口地址。0.0.0.0表示监听所有可用的网络接口,开启远程访问连接
http.port: 指定节点上的HTTP服务监听的端口号。默认情况下,Elasticsearch的HTTP端口是9200。
cluster.initial_master_nodes: 指定在启动集群时作为初始主节点的节点名称。
xpack.security.enabled: 指定是否启用Elasticsearch的安全特性。在这里它被禁用(false),意味着不使用安全功能。
xpack.security.enrollment.enabled: 指定是否启用Elasticsearch的安全认证和密钥管理特性。在这里它被禁用(false)。
ingest.geoip.downloader.enabled: 指定是否启用GeoIP数据库下载功能。在这里它被禁用(false)
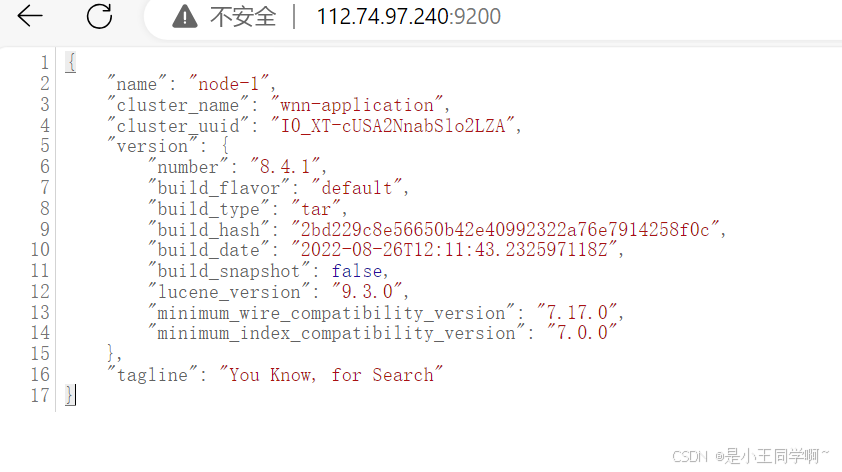
9.启动ElasticSearch
切换到es_user用户启动, 进入bin目录下启动, &为后台启动,再次提示es消息时 Ctrl + c 跳出
./elasticsearch &

10.常见命令,可以用postman访问(使用阿里云网络安全组记得开放端口)
#查看集群健康情况
http://112.24.7.xxx:9200/_cluster/health#查看分片情况
http://11224.7.xxx9200/_cat/shards?v=true&pretty#查看节点分布情况
http://112.24.7.xxx:9200/_cat/nodes?v=true&pretty#查看索引列表
http://112.24.7.xxx:9200/_cat/indices?v=true&pretty
11.常见问题注意
磁盘空间需要85%以下,不然ES状态会不正常
不要用root用户安装
linux内存不够
linux文件句柄
没开启远程访问 或者 网络安全组没看开放端口
有9300 tcp端口,和http 9200端口,要区分
没权限访问,重新执行目录权限分配
chgrp -R es_user /usr/local/software/elk_test/elasticsearch-8.4.1
chown -R es_user /usr/local/software/elk_test/elasticsearch-8.4.1
chmod -R 777 /usr/local/software/elk_test/elasticsearch-8.4.1

四、Kibana源码部署
1.上传安装包和解压
tar -zxvf kibana-8.4.1-linux-x86_64.tar.gz
2.配置用户权限
chgrp -R es_user /usr/local/software/elk_test/kibana-8.4.1
chown -R es_user /usr/local/software/elk_test/kibana-8.4.1
chmod -R 777 /usr/local/software/elk_test/kibana-8.4.1

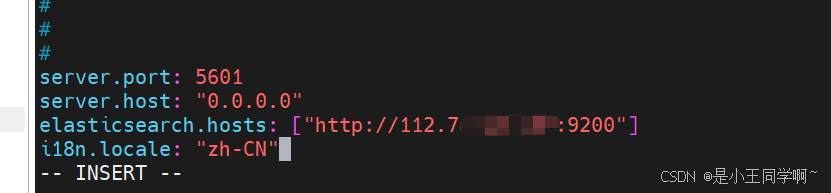
3.修改配置文件
vim config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://112.74.7.xxx:9200"]
i18n.locale: "zh-CN" #汉化
server.port: 指定Kibana服务器监听的端口号,Kibana将在5601端口上监听HTTP请求。
server.host: 指定Kibana服务器绑定的网络接口地址, "0.0.0.0"表示监听所有可用的网络接口。
elasticsearch.hosts: 指定ES集群的主机地址,可以配置多个,Kibana将连接到位于"112.74.7.xxx"主机上、使用默认HTTP端口9200的es
i18n.locale: 指定Kibana界面的语言区域,"zh-CN"表示使用简体中文作为语言。
4.启动,切换到es_user 用户, 建议先不用守护进程方式启动,可以直接启动查看日志
./kibana &
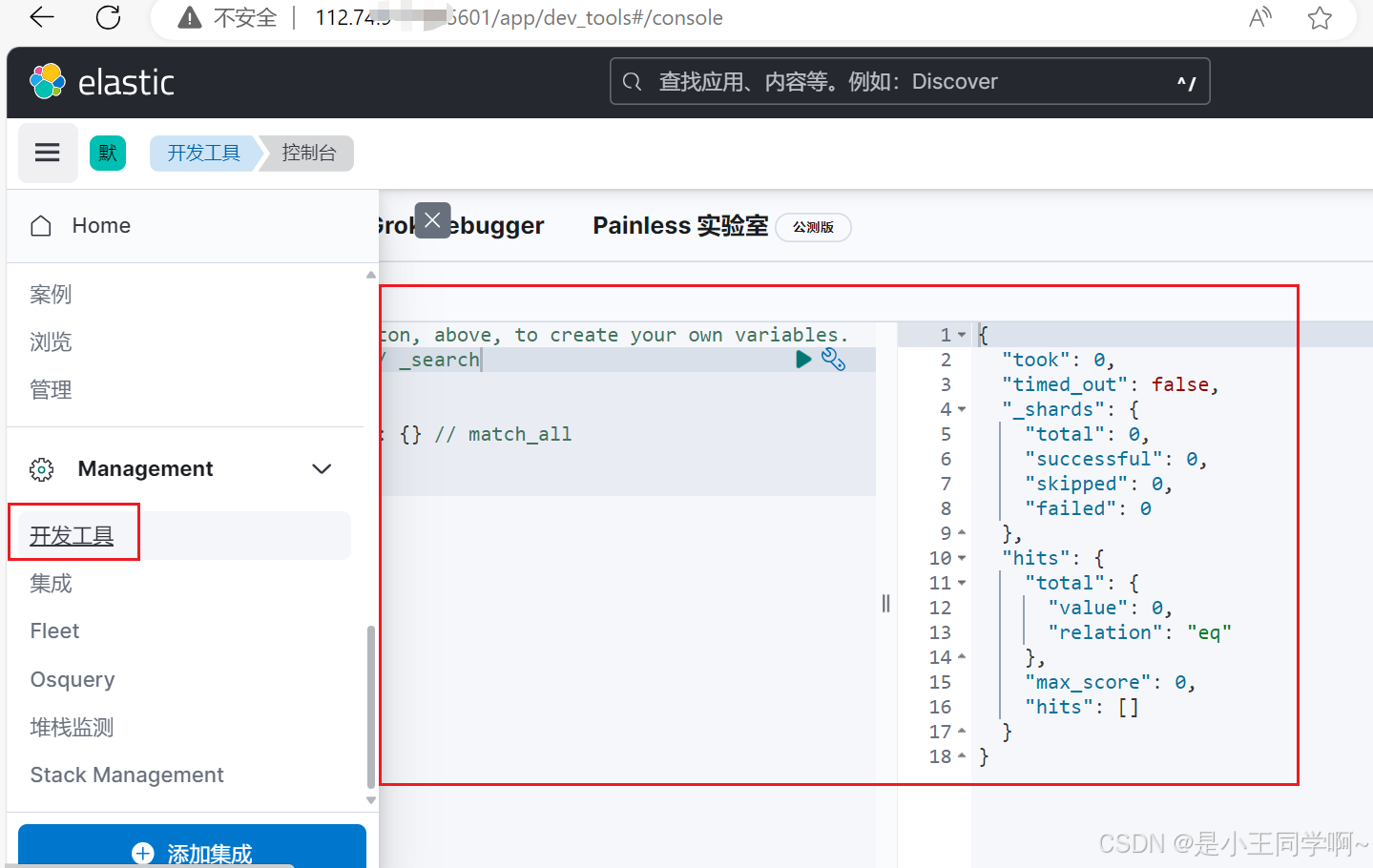
5.访问(网络安全组记得开发端口)
# 验证请求
http://112.74.7.xxx:5601
#查看集群健康情况
GET /_cluster/health
#查看分片情况
GET /_cat/shards?v=true&pretty
#查看节点分布情况
GET /_cat/nodes?v=true&pretty
#查看索引列表
GET /_cat/indices?v=true&pretty
验证连接es是否成功:
五、LogStash8.X源码安装部署
5.1 LogStash宏观配置文件组成
# 输入
input {
...
}
# 过滤器
filter {
...
}
# 输出
output {
...
}
5.2 安装部署
1.上传安装包和解压
tar -zxvf logstash-8.4.1-linux-x86_64.tar.gz
JVM内存不够的话修改 config/jvm.options
2.创建新配置文件 touch config/test-logstash.conf
input {
file {
path => "/usr/local/software/elk_test/nannanw-demo.log"
start_position => "beginning"
stat_interval => "3"
type => "nannanw-demo-log"
}
}output {
if [type] == "nannanw-demo-log" {
elasticsearch {
hosts => ["http://112.74.97.xxx:9200"]
index => "nannanw-demo-%{+YYYY.MM.dd}"
}
}
}

注: 这个内容输入得时候,注意不要有多余得换行符 空格等得。建议在linux中 vim直接编辑。
3.配置文件
input:指定Logstash接收数据的输入插件,使用file插件作为输入。file插件用于读取并处理文件中的数据。
file:指定使用的输入插件是file插件。
path:指定要读取的文件路径,Logstash会读取位于"/usr/local/software/elk_test/log/springboot-nannanw-demo.log"路径下的文件。
start_position:指定从文件的哪个位置开始读取数据。设置为"beginning"表示从文件的开始位置开始读取数据。
stat_interval:指定文件的状态检查间隔(以秒为单位)。设置为"3"表示每隔3秒检查一次文件状态,以判断是否有新数据。
type:指定数据的类型名称。设置为"nannanw-demo-log"表示数据的类型是SpringBoot访问日志。
output:指定Logstash处理完数据后的输出插件。使用elasticsearch插件将处理后的日志数据发送到Elasticsearch。
elasticsearch:指定使用的输出插件是elasticsearch插件。
hosts:指定Elasticsearch集群的主机地址。Logstash将处理后的数据发送到位于"112.74.97.XXXX"主机上,HTTP端口9200的ES节点
index:指定数据在Elasticsearch中的索引名称,比如【filebeat-8.4.1-2024.06.16 】
使用[@metadata][beat]字段、[@metadata][version]字段和当前日期来构建索引名称
可以根据采集数据的来源和版本动态创建索引。
4.启动,进入bin目录
./logstash -f /usr/local/software/elk_test/logstash-8.4.1/config/test-logstash.conf &
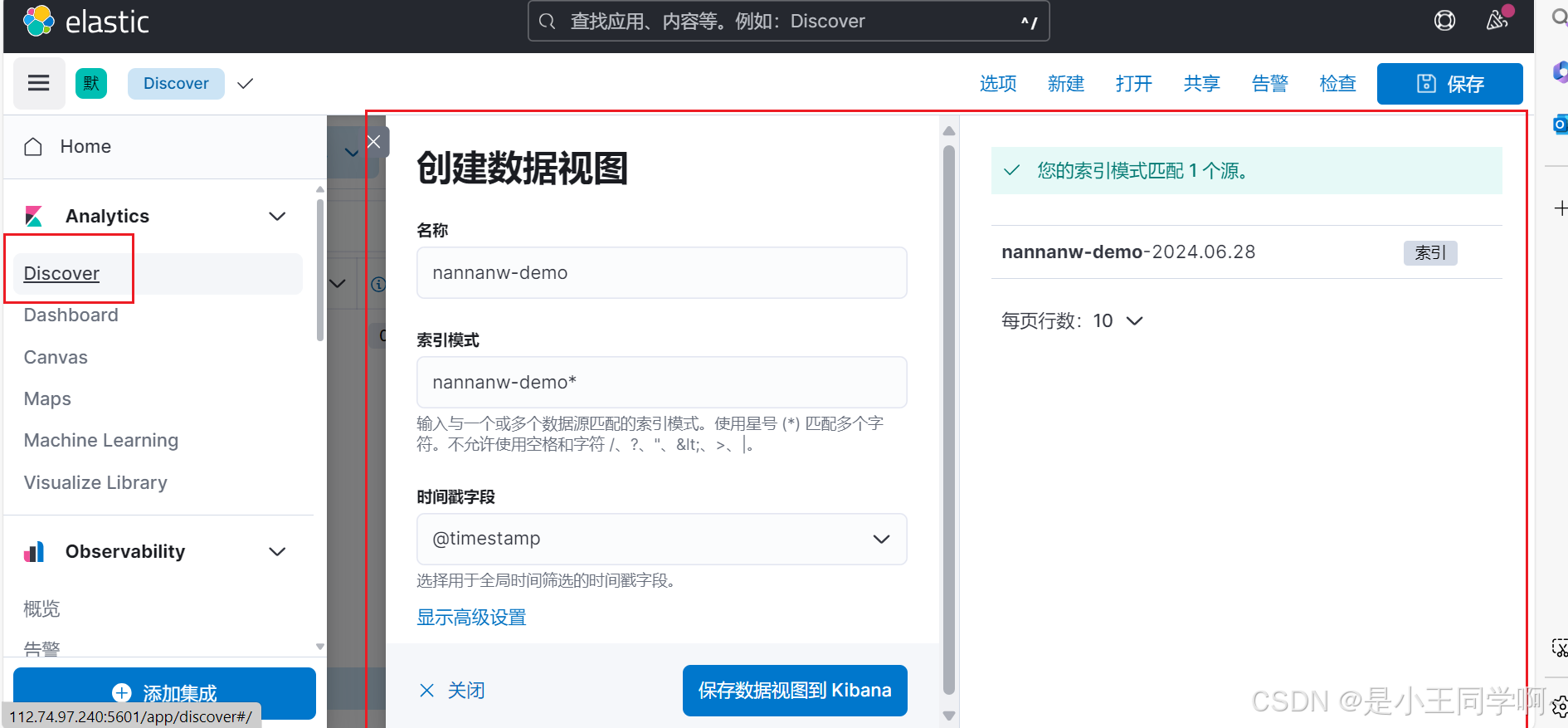
执行成功后,进入kibana索引管理页面查看:
出现下图得这种就表示logstash内容已经写入es了

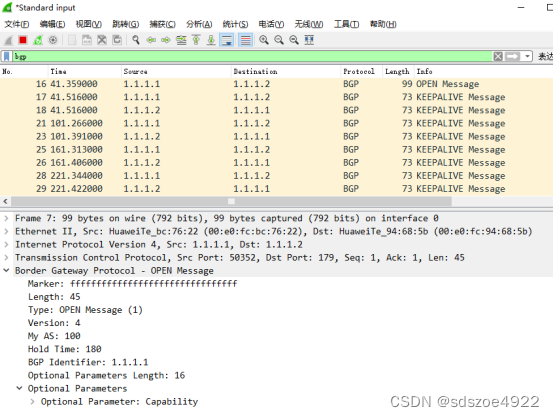
通过kibana查看es日志:
可以指定traceId:888888889123进行检索

六、FileBeat安装部署
6.1为什么要有FileBeat?
Beats 可以直接把数据直接写入到 Elasticsearch 之中,为什么还需要 Logstash 呢?
是因为 Logstash 有丰富的 filter 供我们使用,可以帮加工数据,并最终把数据转为对应要求的格式
beats是轻量级的用来收集日志的 用来优化logstash的, 而logstash更加专注一件事(消耗的性能比较多),那就是数据转换,格式化,等处理工作
6.2FileBeat配置
filebeat.inputs: //指定Filebeat的输入配置,用于定义要监视的日志文件。
- type: log //指定日志文件的类型, 可以是log、file等。
paths:
- /path/to/logfile1.log //指定要监视的日志文件的路径。可以是单个路径或多个路径的列表。
- /path/to/logfile2.log
fields: //为每个输入配置添加自定义字段,用于标记和分类日志数据。
app: myapp
fields_under_root: true//控制是否将fields字段中的自定义字段添加到根级别的事件中,以便在输出时可见。output.logstash://指定Filebeat的输出配置,将日志数据发送到Logstash
hosts: ["logstash-host:5044"]//指定Logstash的地址和端口号,可以是单个地址或多个地址的列表。
此外,Filebeat配置文件还可以包含其他参数,用于定制Filebeat的行为和功能,如日志采集的过滤规则、证书设置、日志解析器等。
七、ElasticStack全链路配置
数据采集链路
Beats 采集(Filebeat/Metricbeat)–> Logstash –> Elasticsearch –> Kibana
7.1 Filebeat部署
1.安装包和解压
tar -zxvf filebeat-8.4.1-linux-x86_64.tar.gz

2.进入目录,创建配置文件 touch test-filebeat.yml
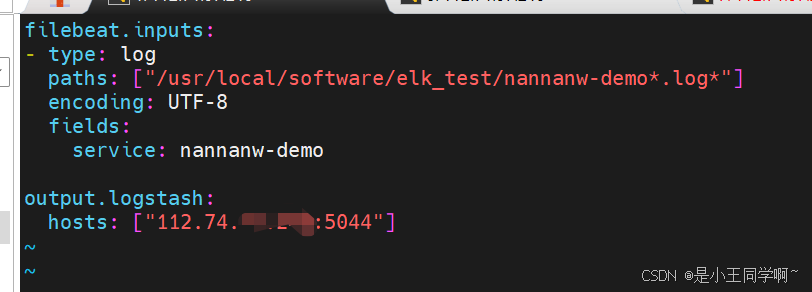
filebeat.inputs:
- type: log
paths: ["/usr/local/software/elk_test/nannanw-demo*.log*"]
encoding: UTF-8
fields:
service: nannanw-demooutput.logstash:
hosts: ["112.74.97.xxx:5044"]
模拟日志数据,准备日志文件,/usr/local/software/elk_test/nannanw-demo.log
3.配置LogStash配置文件
input {
beats {
port => 5044
}
}output {
if [type] == "nannanw-demo" {
elasticsearch {
hosts => ["http://112.74.97.xxx:9200"]
index => "nannanw-type-beat-demo-%{+YYYY.MM.dd}"
}
}if [fields][service] == "nannanw-demo" {
elasticsearch {
hosts => ["http://112.74.97.xxx:9200"]
index => "nannanw-fields-beat-demo-%{+YYYY.MM.dd}"
}
}
}
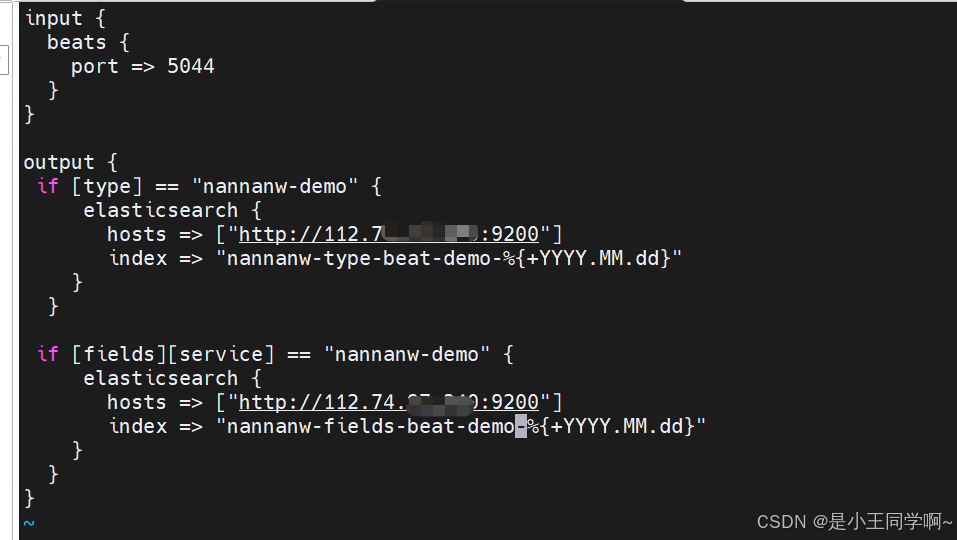
input:指定Logstash接收数据的输入插件。使用beats插件作为输入.beats插件用于接收来自Beats数据采集器的日志数据。
beats:指定使用的输入插件是beats插件。
port:指定beats插件监听的端口号, Logstash会监听5044端口,等待来自Beats采集器的数据。
4.启动logstash (停止之前进程)
./logstash -f /usr/local/software/elk_test/logstash-8.4.1/config/test-beat-logstash.conf &
5.启动filebeat,停止方案 ps -ef |grep filebeat
./filebeat -e -c test-filebeat.yml &
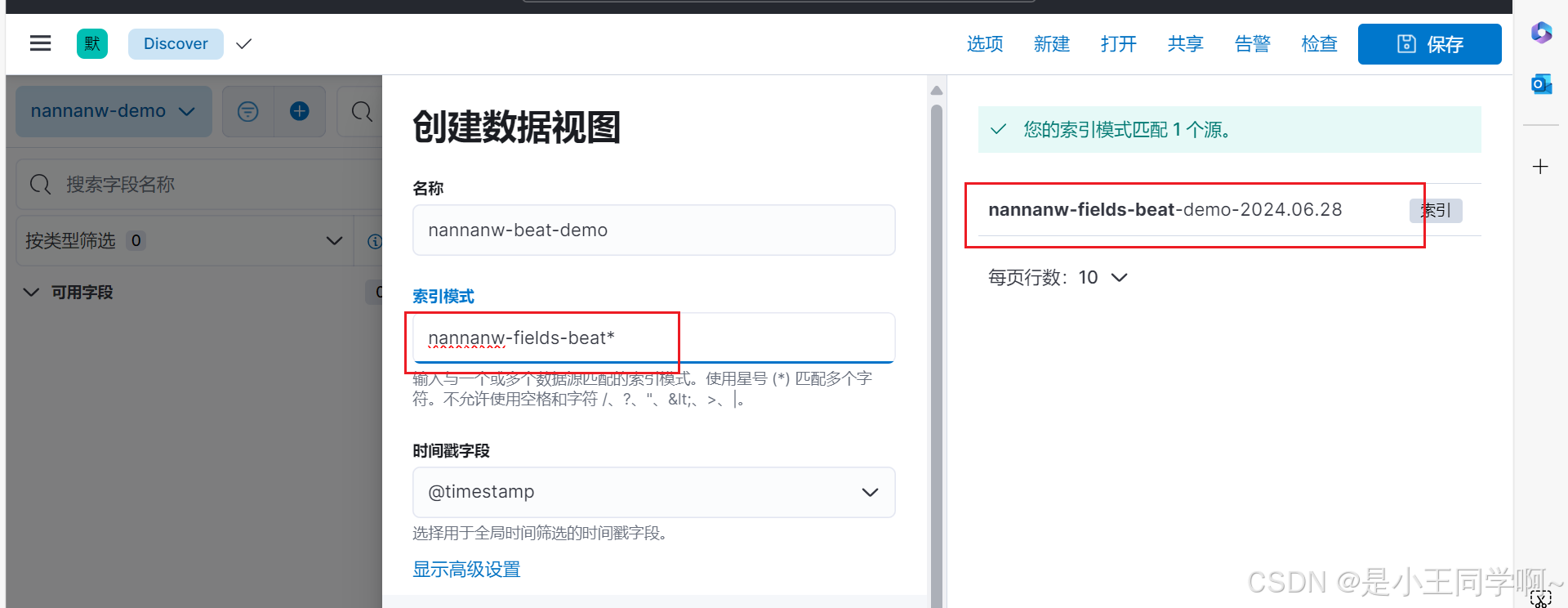
6.kibana验证

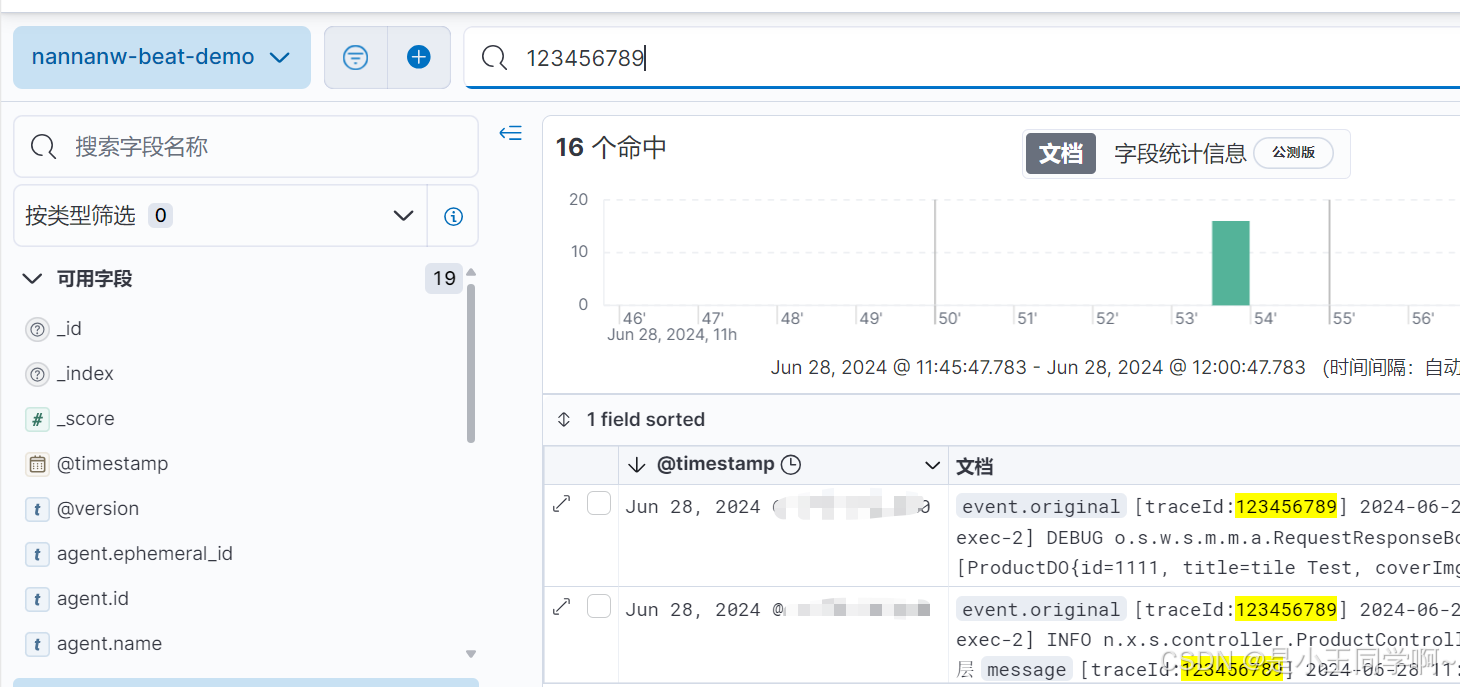
全文到这就结束了,以上内容就是nannanw-demo.log 从文件到写入es 到kibana展示检索得全部过程~