前言
本文是根据python官方教程中标准库模块的介绍,自己查询资料并整理,编写代码示例做出的学习笔记。
根据模块知识,一次讲解单个或者多个模块的内容。
教程链接:https://docs.python.org/zh-cn/3/tutorial/index.html
本文主要记录性能测试cProfile模块的知识。
cProfile
cProfile是Python标准库中的一个性能分析模块,用于程序代码的性能剖析,帮助开发者找出程序中的瓶颈,以便进行优化。它提供了对程序运行时的函数调用次数、总时间、自耗时间等统计信息。
主要特点:
非侵入性:cProfile可以在不修改代码的情况下对程序进行性能分析。
精度高:相比于Python自带的timeit模块,cProfile能提供更详细的函数级性能数据。
输出格式灵活:结果可以输出到命令行、文件或进一步处理。
常用函数
cProfile.run
cProfile.run(statement, filename=None, sort=-1)
- statement: 要分析的代码字符串,可以是函数名、表达式等。
- filename: 可选参数,如果提供,则将分析结果保存到该文件中,而不是打印到控制台。
- sort: 排序方式,决定输出结果的顺序。默认为-1,表示按累计时间降序排列。其他选项有’cumulative’、‘time’、'calls’等。
import cProfile
def test_func():
# 示例函数,进行一些操作
for i in range(10000):
if i % 2 == 0:
print("偶数")
else:
print("奇数")
# 上述代码将分析test_func的执行情况,按照累计时间降序排列输出结果。
cProfile.run('test_func()', sort='cumulative')
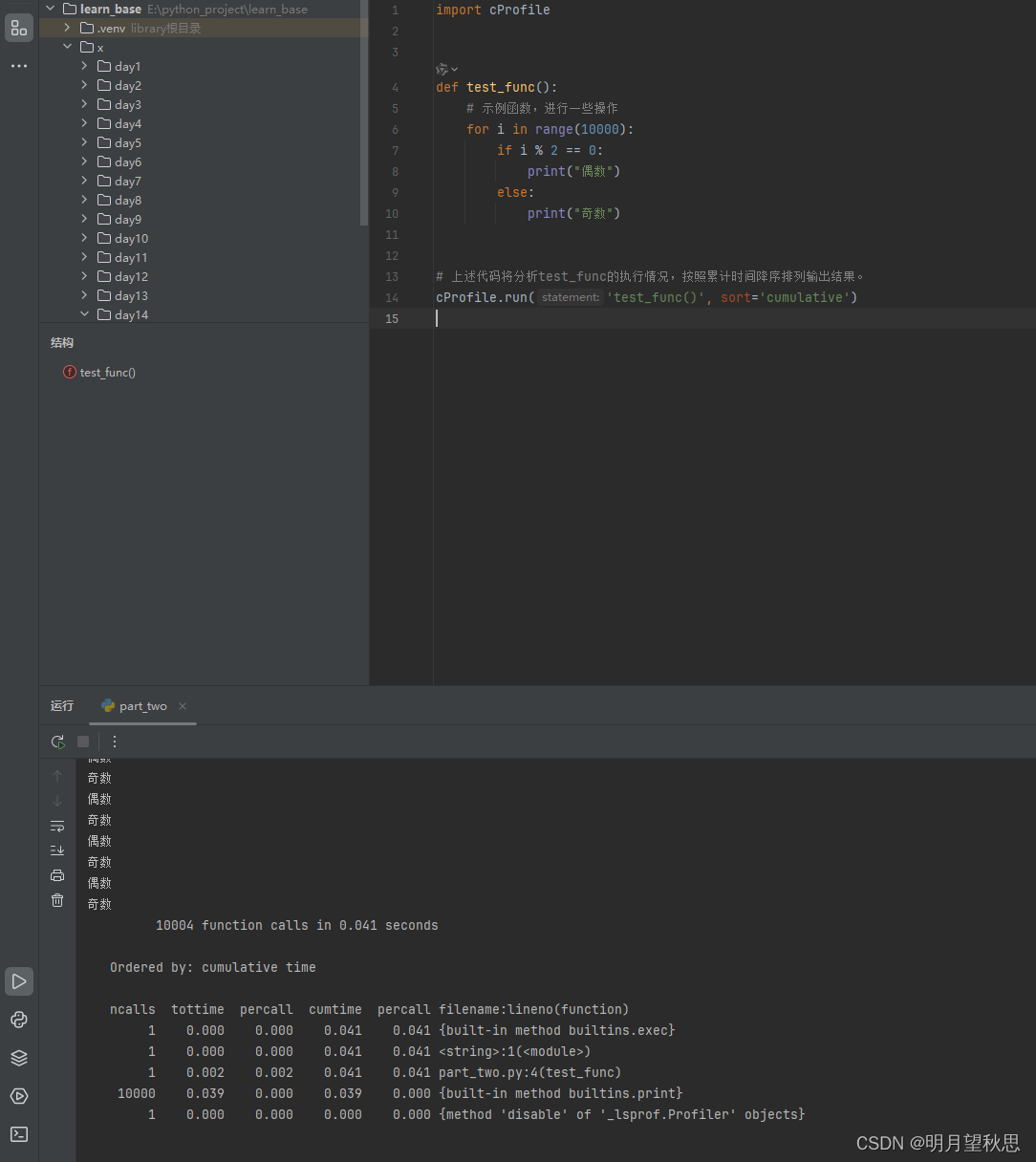
这里介绍一下函数输出结构:
- ncalls: 表示函数被调用的次数。如果是递归函数,这个数字会包括所有层级的调用。
- tottime: 函数执行所消耗的总时间,不包含其调用的子函数所消耗的时间。单位通常是秒。
- percall: 平均每次调用该函数所花费的时间(tottime除以ncalls)。
- cumtime: 函数及其内部调用的所有子函数所消耗的总时间。这是一个“累计”时间,反映了调用该函数对整体运行时间的贡献。
- percall (cumulative): 累计时间的平均值,即每次调用该函数及其子函数的平均总耗时。
- filename:lineno(function): 这部分显示了函数所在的文件名、行号以及函数名称,便于定位代码位置。
结合上面内容,解释一下输出的信息:
- 总共进行了10004次输出,共执行了0.041秒
- 按照累计时间排序
- {built-in method builtins.exec}
ncalls: 1次调用
tottime: 0.000秒,直接执行时间几乎为零
percall: 0.000秒,平均每次调用的直接时间
cumtime: 0.041秒,包括子函数在内的总执行时间
percall (cumulative): 0.041秒,累计时间的平均值
location: {built-in method builtins.exec},表示这是一个内置的exec方法调用,通常用于执行字符串形式的代码块。 - < string >:1(< module >)
同样被调用1次,直接时间和累计时间均为0.041秒,表明这是顶级代码块的执行,可能是脚本的入口点。 - part_two.py:4(test_func)
ncalls: 1次调用
tottime: 0.002秒,函数test_func直接执行耗时
percall: 0.002秒,test_func每次调用的直接时间
cumtime: 0.041秒,包括内部调用的总时间,与上一行相同,意味着这个函数或是其内部调用占了大部分时间
percall (cumulative): 0.041秒,累计时间的平均值
location: part_two.py:4(test_func),表明这是来自part_two.py文件第4行的test_func函数。 - {built-in method builtins.print}
ncalls: 10000次调用
tottime: 0.039秒,直接执行时间总和
percall: 0.000秒,平均每次调用的直接时间非常短,表明单次打印操作非常快
cumtime: 0.039秒,累计时间也是0.039秒,因为这里是直接调用,没有子函数影响
percall (cumulative): 同样是0.000秒
location: {built-in method builtins.print},表示这是内置的print函数调用。 - {method ‘disable’ of ‘_lsprof.Profiler’ objects}
ncalls, tottime, percall, cumtime, percall (cumulative) 全部为0,表示这是关闭Profiler的调用,几乎不占用时间
location: {method ‘disable’ of ‘_lsprof.Profiler’ objects},指的是关闭cProfile Profiler的方法调用。
从这份报告中可以看出,test_func函数及其内部操作(可能包括调用print)是导致程序执行时间较长的主要原因,而直接执行print函数虽然被调用了大量次数,但由于单次执行效率高,对总执行时间的贡献相对较小。
非常枯燥的报告,但是要习惯并且耐心看。
cProfile.runctx
与cProfile.run函数类似,但允许更精细地控制执行环境。
cProfile.runctx(statement, globals, locals, filename=None, sort=-1)
- statement: 要分析的代码字符串,可以是函数名、表达式等。
- filename: 可选参数,如果提供,则将分析结果保存到该文件中,而不是打印到控制台。
- sort: 排序方式,决定输出结果的顺序。默认为-1,表示按累计时间降序排列。其他选项有’cumulative’、‘time’、'calls’等。
- globals: 传递给代码执行的全局变量字典。
- locals: 传递给代码执行的局部变量字典。
def profiled_func(x):
return x * x
globals_dict = {'profiled_func': profiled_func}
locals_dict = {'x': 10}
cProfile.runctx('profiled_func(x)', globals_dict, locals_dict)
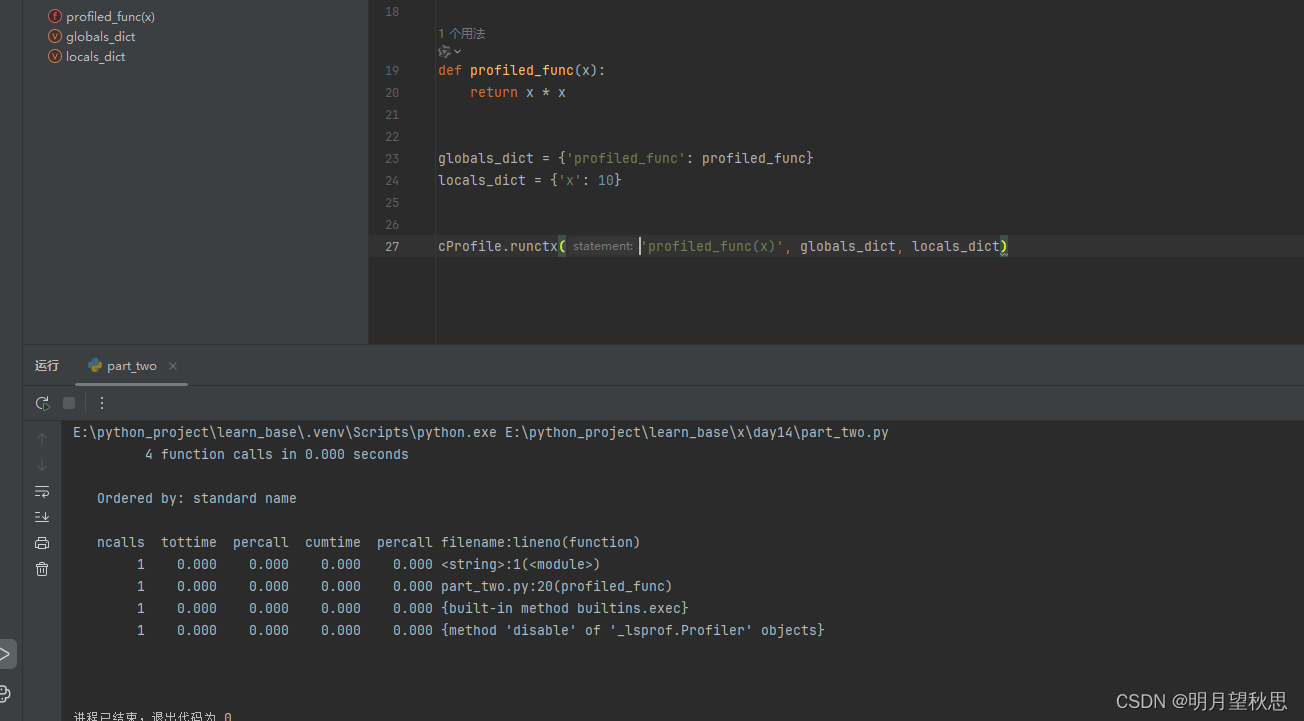
两个函数是类似的,所以输出报告这里就不多说了,参考上一份报告,读取这一份报告的信息。
结尾
性能测试的模块就学习了这两个,这个模块的报告稍微复杂难看点,需要花时间去理解学习。
作业
- 使用
cProfile模块测试自己编写的代码,并读取报告信息。