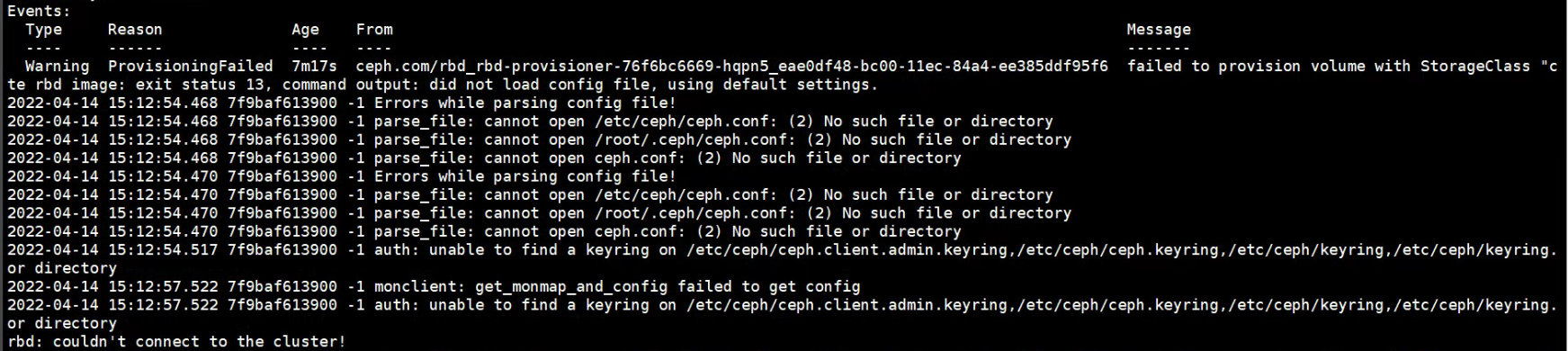
项目主页:https://shihmengli.github.io/extranerf-website/
来源:华盛顿大学,康奈尔大学,谷歌研究,加州大学伯克利分校
标题:ExtraNeRF: Visibility-Aware View Extrapolation of
Neural Radiance Fields with Diffusion Models

文章目录
- 摘要
- 1.引言
- 2.相关工作
- 3.准备工作
- 4.主要方法
- 4.1 NeRF的外延
- 4.2 微调扩散模型
- 4.3 实施细节
- 5.实验
- 5.1 实验设置
- 5.2 LLFF
- 5.3 Tanks & Temples
- 拓展:MUSIQ评价方法
摘要
ExtraNeRF,利用NeRF建模特定于场景的、细粒度的细节,同时利用扩散模型来推理超出观察的数据。一个关键的因素是跟踪可见性,以确定场景的哪些部分没有被观察到,并专注于与扩散模型一致地重建这些区域。我们的主要贡献包括一个基于可见性感知扩散模型的inpainting模块,它微调输入图像,初始化一个NeRF,以及中等质量的(通常模糊)inpaint区域;然后第二个扩散模型训练输入图像,以持续增强,特别是锐化前面的inpaint 图像。文章展示了高质量的结果,推断出少量(通常是6个或更少)的输入视图,有效地outpainting NeRF,并在原始视角内inpaint newly disoccluded的区域。
1.引言
NeRF的基本形式的一个限制是:它的插值比 extrapolating(外延)好得多,并且需要密集的插值。
核心策略是使用神经辐射场(NeRF [29])来捕获特定场景的、细粒度的细节,并利用二维扩散模型来扩展场景超出观测数据的范围。这种直接融合最初导致nerf渲染的图像看起来模糊和细节不足。这主要是由于当从不同的角度应用于3D场景时,2D扩散先验之间的不和谐,特别是在场景级视图外延中,复杂的细节(如叶子和分支)显著减少。
pipeline为多阶段的过程(见图2),其中包括:
(1)可见性模块 ,用于识别所有观察数据中的可见3D内容;
(2)利用可见性感知的 inpainting模块,为每个场景定制想象并添加可信的3D内容用于extrapolatw,并确保观察数据的内容保持不变;
(3)使用 扩散模型,丰富新增内容的视图一致细节。
2.相关工作
2.1 视图合成
给定一组带pose图像,视图合成的目标是从新颖的视角[8,21,52]模拟一个场景的样子。这个问题传统上被表述为基于图像的渲染任务[12,73],通过基于深度映射[7]在视图中混合像素颜色或使用代理几何[19]合成图像,可以获得令人印象深刻的结果。近年来,在深度神经网络[26,37,38,57,72]的帮助下,研究结果得到了进一步的提高。与精心策划的场景表示[15,45,56,62],研究人员已经能够合成新的视图,甚至从一个图像[Pixelsynth,Consistent view synthesis
with pose-guided diffusion models]等。与这些最近的努力类似,我们的工作试图推断出超出可见的内容,并预测在所有图像中被遮挡的内容。然而,我们不是依赖深度网来学习几何关系,并以纯粹的数据驱动的方式生成虚假内容,而是将3D归纳偏差(例如,可见性)烘焙到管道中,以建立生成过程。这使我们能够生成高质量、真实和连贯的场景内容。
2.2 NeRF神经辐射场
现有的基于NeRF的模型往往不受约束,导致以下限制:首先,它们需要对场景的密集观察;其次,当外延而不是插值时,它们的性能会显著下降。为了缓解这些问题,研究人员提出了通过数据分割统计数据[16,33,63]或几何约束[54]来正则化底层场景表示。虽然这些方法大大减少了所需的输入图像的数量,但它们仍然假设输入视图有一个广泛的场景覆盖范围。因此,该任务仍然属于视图插值设置之下。在本文中,我们关注的是一个常见但又具有极具挑战性的实时捕获设置,其中我们只能访问一些具有小基线的图像。我们表明,通过仔细集成生成模型与NeRF,可以有效地扩大NeRF的操作范围,并产生高质量的效果图。
2.3 扩散模型
扩散模型[13,40,48,49]由于其能力和可伸缩性而引起了整个视觉界的广泛关注。他们在大量的2D任务上表现出了显著的性能,如图像inpaint[28,42],去模糊[20,61],并实现了高质量、多样化的图像生成[40,43]。通过结合神经渲染[29], 学习到的扩散先验可以进一步提升到3D,以实现文本到3D[24,35,51,59]或单/多图像3D生成[25,27,36,44,46,47,53]等应用。与这些工作类似,我们也利用扩散模型来合成新的视图,并将生成结果融合回3D。然而,我们研究的不是以对象为中心的内容,而是研究如何建模场景的3D内容。此外,我们明确地跟踪跨视图的可见性,这使我们能够生成现实和一致的3D重建。与我们的工作同时,Sargent等人[Zeronvs]也试图外延3D场景。虽然他们的重点主要是生成超出可见图像边界的内容,但我们的方法同时预测了未被遮挡的区域和未被观察到的区域。
3.准备工作
3.1 NeRF。
神经辐射场 NeRF 是一种隐式的场景表示法。它的核心是一个连续的函数
f
θ
f_θ
fθ:
R
3
×
R
2
→
R
+
×
R
3
R ^3×R^2 →R^+×R^3
R3×R2→R+×R3,由一个神经网络参数化,将3D点
x
∈
R
3
x∈R^3
x∈R3和一个视图方向
d
∈
R
2
d∈R^2
d∈R2映射到一个体积密度
σ
∈
R
+
σ∈R^+
σ∈R+和一个RGB辐射
c
∈
R
3
c∈R^3
c∈R3。对于每个像素,我们从相机中心到像素中心方向投射一个光线
r
(
s
)
=
o
+
s
d
r(s)=o+sd
r(s)=o+sd,并沿射线采样一组三维点,查询它们的亮度和密度。然后通过体渲染获得像素的颜色:
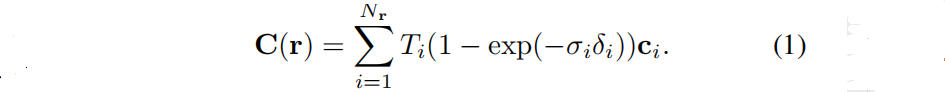
δ
i
=
s
i
+
1
−
s
i
δ_i = s_{i+1}−s_i
δi=si+1−si是相邻样本之间的距离,
T
i
=
e
x
p
(
−
∑
j
=
1
i
−
1
σ
j
δ
j
)
Ti=exp(−\sum ^{i−1}_{j=1}σ_jδ_j)
Ti=exp(−∑j=1i−1σjδj)表示沿光线到
s
i
s_i
si的累积投射率。当距离为
s
i
s_i
si时,可以计算出预期的最终深度:

3.2 扩散模型。
扩散模型依赖于学习到的去噪模块
Ψ
(
x
t
,
t
,
l
)
Ψ(x_t,t,l)
Ψ(xt,t,l),接收一个有噪声的输入图像
x
t
x_t
xt和可能的额外条件反射信号(例如,文本提示l,时间步长t),并预测噪声ϵ。通过迭代预测噪声并从数据中减去噪声,该模型逐渐将原始有噪声的数据
x
t
x_t
xt 转换为感兴趣的目标样本x。为了训练这样一个模型,在原始的干净数据点上加入不同层次的高斯噪声ϵ,并由去噪器Ψ负责预测噪声:
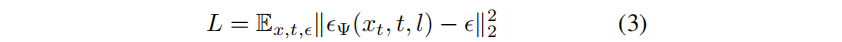
4.主要方法
4.1 NeRF的外延
如图2,通过三个步骤来创建一个能够进行视图外推分析的NeRF。

1.训练BaseNeRF :给定一组稀疏的 [ I i ] i = 1 n [{I_i}]_{i=1}^n [Ii]i=1n及其相关的相机pose和 Π i Π_i Πi,首先训练一个BaseNeRF。由于缺乏密集的多视图图像来有效地正则化底层三维空间,我们利用[Sparf:CVPR 2023]中提出的方法来计算每个输入图像的密集深度映射 [ D i ] i = 1 n [D_i]^n_{i=1} [Di]i=1n,以进行几何监督。为了进一步减少“floater”伪影,我们结合了 distortion loss[1]和hash decay loss[2],并应用 gradient scaling[34]来规范学习过程。
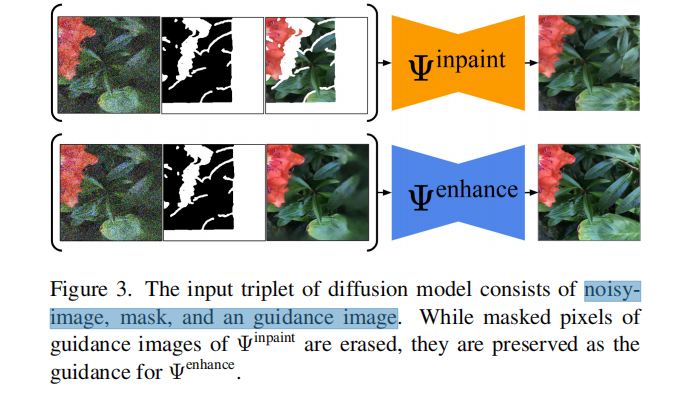
2.Diffusion-guided Inpainting :在超出原始查看域的原始视图和虚拟视图集上反复优化NeRF。对于每个虚拟视图,使用NeRF渲染它,然后使用扩散inpaint 模型 Ψ i n p a i n t Ψ^{inpaint} Ψinpaint 来预测未观察到的区域。我们采用了来自 [40:High-resolution image synthesis with latent diffusion models] 的潜在扩散的inpaint变体,在每个场景的基础上进一步微调(4.2节)。为了将inpaint 限制在未观察到的区域(例如NeRF缺乏监督的区域), Ψ i n p a i n t Ψ^{inpaint} Ψinpaint采用了三个输入:噪声图像、可见性mask和在绘制区域缺乏数据的屏蔽干净图像(见图3)。可见性mask是通过检查在训练图像中是否观察到每个像素处沿光线的三维样本点来计算的(见4.3节).
对于每个虚拟视图,我们还使用深度补全网络来绘制基于inpaint的彩色图像的深度(见4.3节).监督信号分别为 L i n p a i n t r g b L^{rgb}_{inpaint} Linpaintrgb and L d e p t h L^{depth} Ldepth:
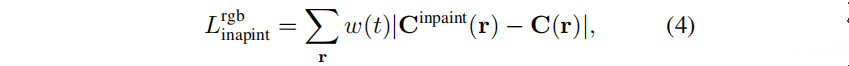
w
(
t
)
w(t)
w(t)是一个噪声级相关的加权函数,
C
i
n
p
a
i
n
t
C^{inpaint}
Cinpaint是inpaint的颜色,C是从NeRF渲染的图像。我们选择在每个虚拟视图上运行少量的扩散去噪步骤(如10步),但是通过多次迭代这些视图来重复整个过程。虽然在多个视图中单独inpaint 可能导致不一致,但实验收敛,因为在每个虚拟视图中,扩散过程是通过噪声图像引导的,噪声图像从每次迭代中不断改进的NeRF中重新估计。这与[Dreamfusion]类似。
3.扩散引导增强。虽然迭代inpaint能够收敛成一个一致的结果,但之后的NeRF仍可能出现一些模糊和颜色漂移。为了缓解这一问题,使用基于扩散的增强模型
Ψ
e
n
h
a
n
c
e
Ψ^{enhance}
Ψenhance,它与
Ψ
i
n
p
a
i
n
t
Ψ^{inpaint}
Ψinpaint具有相同的架构,专门训练用于图像增强。
类似于inpaint的迭代更新,每次训练中,1)渲染图像并从NeRF计算可见性mask,2)从渲染图像和可见性mask中创建一个三组输入数据,3)利用
Ψ
e
n
h
a
n
c
e
Ψ^{enhance}
Ψenhance 从这三组中生成一个增强的图像。与inpaint过程相比,我们没有mask out the pixels in the intact rendered image(见图3)。相反,我们希望
Ψ
e
n
h
a
n
c
e
Ψ^{enhance}
Ψenhance能够增强这些领域的细节。一旦增强的图像被生成,我们就会完成深度。最后,我们按照类似于喷漆阶段的步骤监督NeRF,但用
L
e
n
h
a
n
c
e
r
g
b
L^{rgb}_{enhance}
Lenhancergb替换
L
i
n
p
a
i
n
t
r
g
b
L^{rgb}_{inpaint}
Linpaintrgb
4.2 微调扩散模型
如前所述,使用latent diffusion model 的变体进行inpaint和enhance。为了获得最好的质量,必须使用稀疏的输入图像集,对场景和它们各自的任务进行微调。 Ψ e n h a n c e Ψ^{enhance} Ψenhance的任务并不是完全 inpaint,而是更类似于去模糊。如图7所示,特定于场景的微调对于inpaint模块也很重要。
微调使用输入图像, 生成GroundTruth。第一步:创建虚拟视图中的 可见性mask。对于每个训练图像,我们通过检查像素是否在所有其他训练视图中可见,来计算一个相应的pseudo visibility mask。在另一个视图中不可见的像素被视为disocclusions,通过要求 Ψ i n p a i n t Ψ^{inpaint} Ψinpaint 修复对应的mask区域来微调 Ψ i n p a i n t Ψ^{inpaint} Ψinpaint。具体采用DreamBooth的pipeline中的标准扩散损失。
生成Ψenhance的训练数据:为了给增强任务产生损坏的输入,我们优化了一个NeRF,有意地将来自输入视点的监督替换为pseudo-disocclusion masks 中来自 Ψ i n p a i n t Ψ^{inpaint} Ψinpaint的inpaint监督。我们发现,这充分模拟了 Ψ e n h a n c e Ψ^{enhance} Ψenhance需要减少的模糊和颜色漂移。具体实例见图4

4.3 实施细节
Visibility map。三维点如果在输入视图框之外或被更近的对象遮挡,它们可能会被隐藏。Visibility map 帮我们确定哪些区域在原始图像中没有被观察到,需要inpaint。来自NeRF的累积透光率编码了基本的可见性信息,使我们能够估计任何一个基于输入视图的三维点的可见性。 具体的 ,为了计算虚拟视图中单个像素的Visibility map,我们首先通过该像素构造一条射线。对于沿该射线的每个采样三维点,我们计算每个训练视图的透射率(如:另一条 ray march)。为了在输入视图中的透光率值,我们只需选择第二大的值。这是基于这样一个基本原理,即一个三维点的几何形状只有在被至少两个视图(三角测量的最小值)观察到时才可靠。如果一个三维点只被一个训练视图看到,它的估计深度可能是不可靠的。最后,通过体积渲染将这些聚集的透光率样本聚集到可见性图像素,类似于颜色值。
Depth completion module:深度补全模块,用来补全虚拟视图的深度图。其输入为inpaint的RGB图像、Visibility map和masked 深度图作为输入,并在mask区域内inpaint 深度图。该模型基于MiDaS-v3 [4]的预训练权重,并为输入mask和masked 深度图增加了两个输入通道。该模型在Places2数据集[71]上使用自监督的方法进行了微调。
超参数:我们对500次迭代的inpaint和enhance模型进行了微调,扩散U-Net的学习速率为5e-6,文本编码器的LoRA层的学习速率为4e-5。我们的NeRF使用instant-NGP[32]作为主干,使用场景收缩[1]来处理无边界的场景。我们提出了一个三阶段的管道来训练我们的NeRF。在步骤1中,我们使用 L r g b L^{rgb} Lrgb和 L d e p t h L^{depth} Ldepth对BaseNeRF进行5000次迭代,初始学习率为1e-2,逐渐减少到3e-4。在步骤2中,除了 L r g b L^{rgb} Lrgb和 L d e p t h L^{depth} Ldepth外,NeRF还通过 L i n p a i n t r g b L^{rgb}_{inpaint} Linpaintrgb Ψ i n p a i n t Ψ^{inpaint} Ψinpaint进行500次迭代的监督。在阶段3中,我们监督NeRF再进行500次迭代,但用增强模型 Ψ e n h a n c e Ψ^{enhance} Ψenhance替换了inpaint 模型 Ψ i n p a i n t Ψ^{inpaint} Ψinpaint。
时间消耗: 在我们的实验中,我们使用了一个A100 GPU。步骤1,瓶颈,包括6小时的训练Sparf [54],在30K迭代时提前停止以创建深度图,以及8分钟来训练BaseNeRF模型。步骤2和步骤3通常需要2-3小时,包括1小时用于数据收集和微调两个扩散模型,以及1-2小时用于训练ExtraNeRF模型。我们的总优化时间比NeRF [29]短,当在一个GPU上运行时,可能需要一天或更长的时间。
5.实验
5.1 实验设置
LLFF数据集:LLFF数据集提供了两种设置。在第一个方案中,我们的目标是评估在视图外延任务中的表现。因此,在30-40张图像中,选择视点最接近中心位置的6张作为训练集,并选择8张视点距离中心位置最远的图像作为测试集(见表 1).第二个协议遵循标准的few shot 视图合成设置[33](见表 2).

Tanks & Temples数据集用来展示现实世界设置中管理更复杂的场景的能力。由NeRF++ [67]处理的数据是我们的基础。在每个场景中,我们选择3-5个附近的视图作为训练集,并选择另外5-6个视图,它们的视点围绕着训练视点,作为测试集。
指标:我们采用与[30:Reference-guided control lable inpainting of neural radiance fields]相同的指标,因为我们的目标,类似于他们的目标,涉及到评估合成的3D内容的性能。因此,我们利用了两组度量标准:全参考(FR)和无参考(NR)。对于FR指标,我们只使用LPIPS[68]、KID [3],还包括PSNR和SSIM [58]来进行综合评估。然而,值得注意的是,PSNR和SSIM并不被认为是评估生成性任务[6,9,44]的可靠指标。对于NR指标,我们使用MUSIQ [17]来评估渲染图像的视觉质量。
baseline:与6个开放代码的相关基线进行比较: (1) Sparf [54],稀疏视图重建的最先进的SOTA方法之一。(2) FreeNeRF [66],另一种用于稀疏视图重建的SOTA方法。(3)扩散NeRF[63],采用补丁扩散模型为NeRF提供RGB和深度监督。(4) SPIn-NeRF [31],旨在在3D物体后面绘制未观察到的内容,给出一个完整的物体掩模。在我们的设置中,如果没有对象掩码存在,我们用一个可见性掩码来代替它,表示为*SPIn-NeRF。(5) *SinNeRF [65],能够从单个图像和精确的深度图中推断出3D中的视图。为了进行公平的比较,我们提供了来自训练集中所有图像的RGB监督。(6) *SDS [35]损失,广泛用于3D内容的生成。在这里,我们用SDS损失代替inpaint图像的颜色监督。
5.2 LLFF
视图外延的比较:表1中,ExtraNeRF在各种指标上都超过了相关的工作;图6给出了一个定性比较(左边渲染visibility mask的图像,在右边呈现外延结果。与基线相比,我们的结果明显更清晰,并与现有的场景内容保持一致。我们能够准确地重建叶子(顶部)和部分观察到的椅子(底部)的结构,基线会产生模糊的结果,并难以区分前景和背景)。


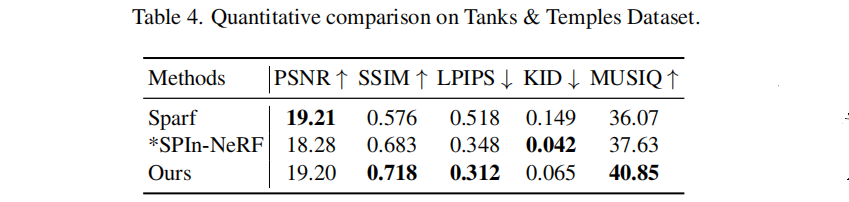
5.3 Tanks & Temples
表4中,我们的方法在LPIPS和MUSIQ评分上优于其他方法,这表明我们的结果具有更好的视觉质量。然而,我们的KID分数低于SPIn-NeRF。我们假设,这可能是由于数据集的小尺寸,可能不足以准确地估计测试集的分布。此外,我们还展示了一个示例,突出显示了我们的模型合成从输入视点中无法观察到的大量内容区域的能力(参见图8)。

拓展:MUSIQ评价方法
MUSIQ(Multi-scale Image Quality Transformer)是一种用于图像质量评估的深度学习模型,专门设计用于处理生成图像以及其他类型的图像。以下是MUSIQ如何评价生成图像质量的主要方法和步骤:
-
多尺度特征提取
MUSIQ通过一种多尺度的方式来提取图像特征。具体来说,它会从多个尺度(例如,不同的分辨率)对图像进行处理,以捕捉不同尺度下的图像质量特征。这种多尺度处理可以帮助模型更好地理解图像中的细节和全局信息,从而更准确地评估图像质量。 -
Transformer架构
MUSIQ使用了Transformer架构,这是一种在自然语言处理和计算机视觉中广泛使用的深度学习模型。Transformer通过自注意力机制(self-attention mechanism)来捕捉图像中不同部分之间的关系。具体来说,MUSIQ使用了视觉Transformer(ViT),将图像分割成一系列的小块(patches),然后通过Transformer对这些小块进行处理和特征提取。 -
训练和监督
MUSIQ的训练过程使用了大量标注好的图像质量数据。这些数据通常包含了人类对图像质量的主观评分(MOS,Mean Opinion Score)。通过这种有监督的方式,MUSIQ可以学习到人类如何评价图像质量,并将这种知识应用于新的图像。 -
多任务学习
为了进一步提升模型的性能,MUSIQ还使用了多任务学习的方法。除了图像质量评估,MUSIQ还可以同时学习其他相关任务,例如图像分类或图像识别。这种多任务学习可以帮助模型共享不同任务之间的知识,从而提高整体的图像质量评估性能。 -
综合评分
在经过上述特征提取和处理步骤后,MUSIQ会将图像的多尺度特征进行整合,并通过一个评分网络(scoring network)生成最终的图像质量评分。这一评分代表了模型对图像质量的整体评估,通常与人类的主观评分高度相关。
总结
MUSIQ通过多尺度特征提取、Transformer架构、自注意力机制、监督学习和多任务学习等多种技术手段,综合评估生成图像的质量。这种方法既能够捕捉图像的局部细节,又能理解全局上下文,使得MUSIQ在图像质量评估任务中表现出色。
d
\sqrt{d}
d
1
0.24
\frac {1}{0.24}
0.241
x
ˉ
\bar{x}
xˉ
x
^
\hat{x}
x^
x
~
\tilde{x}
x~
ϵ
\epsilon
ϵ
ϕ
\phi
ϕ