1. P-Tuning v1
1.背景
大模型的Prompt构造方式严重影响下游任务的效果。比如:GPT-3采用人工构造的模版来做上下文学习(in context learning),但人工设计的模版的变化特别敏感,加一个词或者少一个词,或者变动位置都会造成比较大的变化。
P-Tuning,在《GPT Understands, Too》中被提出,该方法将离散的Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理,成功地实现了模版的自动构建。
2.技术原理
P-Tuning 提出将 Prompt 转换为可以学习的 Embedding 层,并考虑到直接对 Embedding 参数进行优化会存在这样两个挑战:
1.Discretenes: 对输入正常语料的 Embedding 层已经经过预训练,而如果直接对输入的 prompt embedding进行随机初始化训练,容易陷入局部最优。
2.Association:没法捕捉到 prompt embedding 之间的相关关系。
基于此,作者提出了P-Tuning,设计了一种连续可微的virtual token(同Prefix-Tuning类似)。该方法将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。
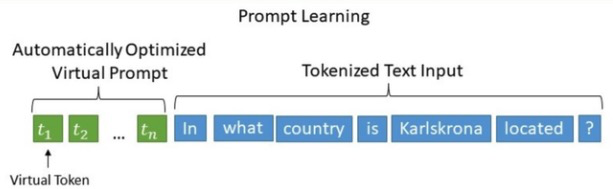
相比Prefix Tuning,P-Tuning加入的可微的virtual token仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token。
优化virtual token:经过预训练的LM的词嵌入已经变得高度离散,如果随机初始化virtual token,容易优化到局部最优值;这些virtual token理论是应该有相关关联的,要对这种关联进行建模。作者发现的是用一个prompt encoder来编码收敛更快,效果更好。也就是说,用一个LSTM+MLP去编码这些virtual token以后,再输入到模型。换言之,P-tuning并不是随机初始化几个新token然后直接训练的,而是通过一个小型的LSTM模型把这几个Embedding算出来,并且将这个LSTM模型设为可学习的。
选择双向长短期记忆网络 (LSTM),使用 ReLU 激活的两层多层感知器 (MLP) 来对prompt embedding 进行一层处理来鼓励离散性。
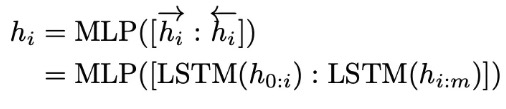
将LSTM作为prompt-encoder,并进行随机初始化。GPT模型仍然会被全部冻结,只更新LSTM的参数。LSTM的参数是所有任务同时共享的,但是LSTM为不同的task输出unique virtual token embeddings。virtual token embedding和Prompt Tuning以一样的方式插入input token中。
class PromptEncoder(torch.nn.Module):
......
def forward(self, indices):
input_embeds = self.embedding(indices)
if self.encoder_type == PromptEncoderReparameterizationType.LSTM:
output_embeds = self.mlp_head(self.lstm_head(input_embeds)[0])
elif self.encoder_type == PromptEncoderReparameterizationType.MLP:
output_embeds = self.mlp_head(input_embeds)
else:
raise ValueError("Prompt encoder type not recognized. Please use one of MLP (recommended) or LSTM.")
return output_embeds2. P-Tuning v2
1.背景
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题:
1.缺乏模型参数规模和任务通用性。
缺乏规模通用性:Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。
缺乏任务普遍性:尽管Prompt Tuning和P-tuning在一些 NLU 基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。
2.缺少深度提示优化,在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,插入连续提示的位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。
由于序列长度的限制,可调参数的数量是有限的。
输入embedding对模型预测只有相对间接的影响。
考虑到这些问题,作者提出了Ptuning v2,它利用深度提示优化(如:Prefix Tuning),对Prompt Tuning和P-Tuning进行改进,作为一个跨规模和NLU任务的通用解决方案。
2.技术原理
针对 P-Tuning v1存在的局限论文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》P-Tuning v2 的目标就是要让 Prompt Tuning 能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌 Fine-tuning 的结果。也就是说当前 Prompt Tuning 方法在这两个方面都存在局限性。基于此,P-Tuning V2进行了下述改进:
1.在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这与Prefix Tuning的做法相同。这样得到了更多可学习的参数,且更深层结构中的Prompt能给模型预测带来更直接的影响。
2.去掉了重参数化的编码器。以前的方法利用重参数化功能来提高训练速度和鲁棒性(例如,用于prefix-tunning的 MLP 和用于 P-tuning的 LSTM)。在 P-tuning v2 中,作者发现重参数化的改进很小,尤其是对于较小的模型,同时还会影响模型的表现。
3.针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,我们发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与Prefix-Tuning中的发现一致,不同的文本生成任务可能有不同的最佳提示长度。比如简单分类任务下 length=20 最好,而复杂的任务需要更长的 Prompt Length。
4.可选的多任务学习。先在多任务的Prompt上进行预训练,然后再适配下游任务。一方面,连续提示的随机惯性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;另一方面,连续提示是跨任务和数据集的特定任务知识的完美载体。比如说,在NER中,可以同时训练多个数据集,不同数据集使用不同的顶层classifer,但是prefix continuous prompt是共享的。
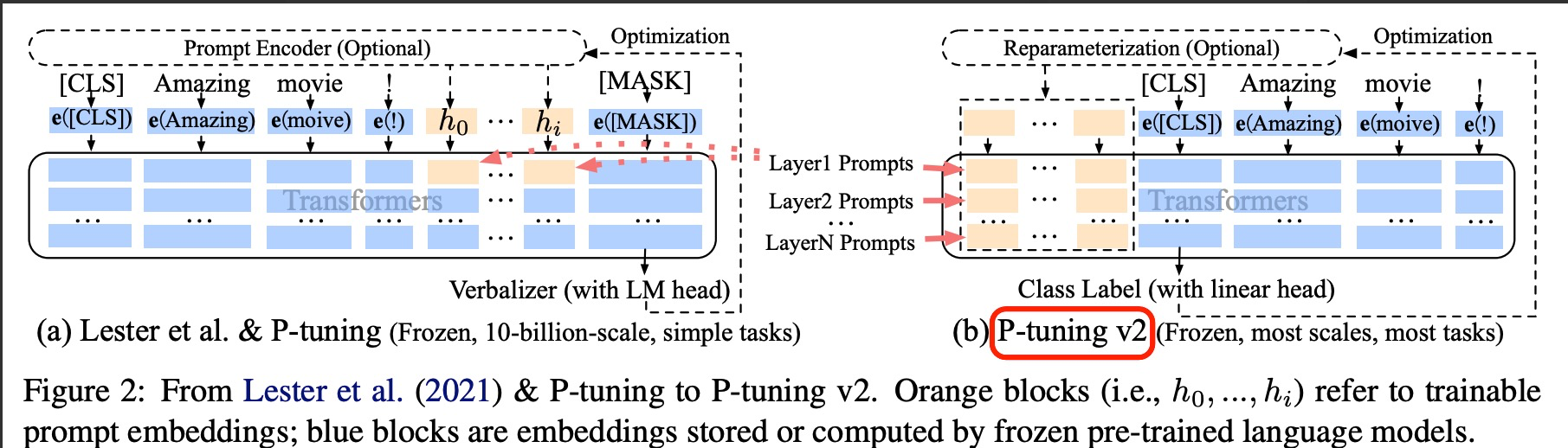
可以看到右侧的p-tuning v2中,将continuous prompt加在序列前端,并且每一层都加入可训练的prompts。在左图v1模型中,只将prompt插入input embedding中,会导致可训练的参数被句子的长度所限制。
另外在V2中,移除了Reparameterization,舍弃了词汇Mapping的Verbalizer的使用,重新利用CLS和字符标签,来增强通用性,这样可以适配到序列标注任务。此外,作者还引入了两项技术:
1.Deep Prompt Encoding:采用 Prefix-tuning 的做法,在输入前面的每层加入可微调的参数。使用无重参数化编码器对pseudo token,不再使用重参数化进行表征(如用于 prefix-tunning 的 MLP 和用于 P-tuning 的 LSTM),且不再替换pre-trained word embedding,取而代之的是直接对pseudo token对应的深层模型的参数进行微调。
2.Muliti-task learning:基于多任务数据集的Prompt进行预训练,然后再适配到下游任务。对于pseudo token的continous prompt,随机初始化比较难以优化,因此采用multi-task方法同时训练多个数据集,共享continuous prompts去进行多任务预训练,可以让prompt有比较好的初始化。
peft_config = PrefixTuningConfig(task_type="SEQ_CLS", num_virtual_tokens=20)
model = AutoModelForSequenceClassification.from_pretrained(model_name_or_path, return_dict=True)
model = get_peft_model(model, peft_config)Reference:
1.大模型炼丹术:大模型微调的常见方法 - 知乎
2.大模型微调之P-tuning方法解析 | 美熙智能
3.Prompt Tuning和P-Tuning的区别在哪里? - 知乎
4.大模型微调总结
5.详解大模型微调方法Prompt Tuning(内附实现代码)