芯片初创公司Etched近日宣布推出了一款针对 Transformer架构专用的AISC芯片 “Sohu”,并声称其在AI大语言模型(LLM)推理性能方面击败了NVIDIA最新的B200 GPU,AI性能达到了H100的20倍。这也意味着Sohu芯片将可以大幅降低现有AI数据中心的采购成本和安装成本。
目前,Etched公司已就其Sohu芯片的生产与台积电4nm工艺展开直接合作,并且已从顶级供应商处获得足够的 HBM 和服务器供应,以快速提高第一年的生产能力。
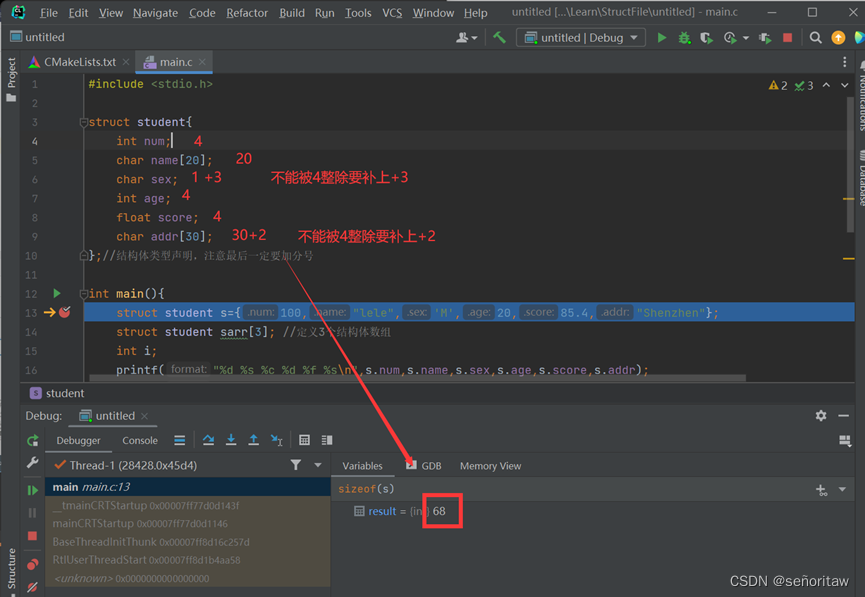
一些早期客户已经向Etched公司预订了数千万美元的硬件。

一、AI性能超过NVIDIA H100的20倍,是如何做到的?
据Etched公司介绍,Sohu是世界上第一个基于Transformer架构的ASIC。
根据Etched公司披露的数据显示,一台配备了8颗Sohu芯片的服务器每秒可以处理超过 500,000 个 Llama 70B Token,达到了同样配备8张NVIDIA H100 GPU加速卡的服务器的20倍。
同样,也远远超过了配备8张NVIDIA最新的B200 GPU加速卡的服务器约10倍。
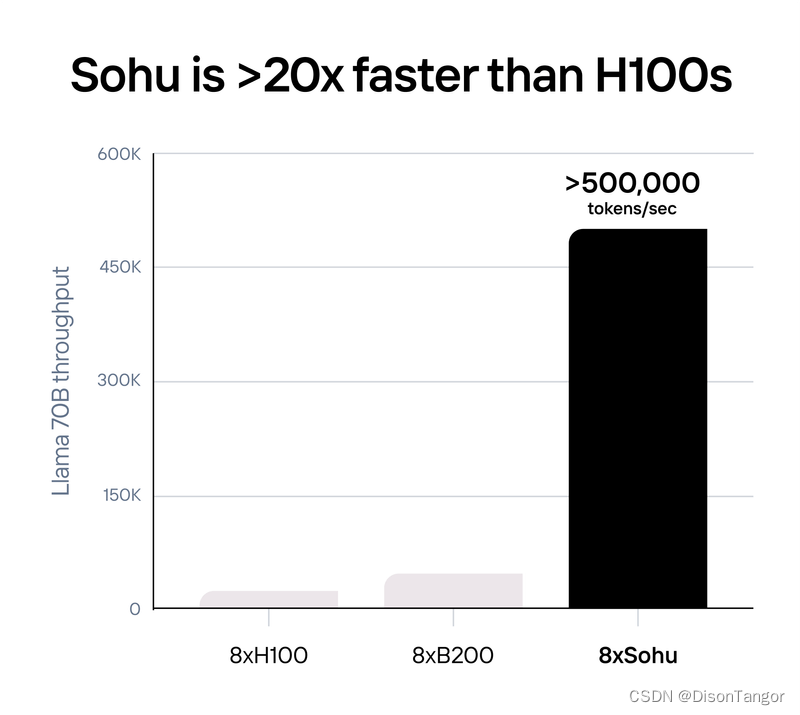
基准测试针对的是 FP8 精度的 Llama-3 70B:无稀疏性、8x 模型并行、2048 输入/128 输出长度。使用 TensorRT-LLM 0.10.08(最新版本)计算的 8xH100,8xGB200 的数字是估算的。
Etched公司表示,Sohu速度比NVIDIA的最新一代Blackwell架构的B200 GPU还要快一个数量级,而且价格更便宜。可以帮助客户构建 GPU 无法实现的产品。
不过,这里还是要强调以下,虽然Sohu的AI性能要比NVIDIAGPU更好,但这是有一个前提的,因为Sohu是专为基于Transformer架构的大模型定制的,所以其也仅支持基于Transformer架构的大模型加速。
“通过将Transformer架构集成到我们的芯片中,虽然无法运行大多数传统的 AI 模型,比如为 Instagram 广告提供支持的 DLRM、像 AlphaFold 2 这样的蛋白质折叠模型、像 Stable Diffusion 2 这样的旧的图像模型,以及CNN、RNN 或 LSTM等模型,但是针对基于Transformer架构的大模型,Sohu将是有史以来最快的AI芯片,没有哪个芯片能够与之匹敌。”Etched公司说道。
1、更高的计算利用率
由于Sohu只运行Transformer这一种类型的算法,因此可以删除绝大多数控制流逻辑,从而拥有更多数学计算逻辑。因此,Sohu的 FLOPS 利用率超过 90%(而使用 TRT-LLM 的GPU上 FLOPS 利用率约为 30%)。
虽然NVIDIA H200 拥有 989 TFLOPS 的 FP16/BF16 计算能力(无稀疏性),这无疑是非常强大的,甚至比谷歌的新 Trillium 芯片还要好。
但NVIDIA已经发布的B200的计算能力仅高出25%(每个芯片 1,250 TFLOPS)。这是由于 GPU 的绝大部分区域都用于可编程性,因此专注于 Transformer 可以让芯片进行更多的计算。
比如,构建单个 FP16/BF16/FP8 乘加电路需要 10,000 个晶体管,这是所有矩阵数学的基石。NVIDIA H100 SXM 有 528 个张量核心,每个都有4 x 8 × 16FMA 电路。
因此,NVIDIA H100 有 27 亿个专用于张量核心的晶体管。但是 H100 拥有 800 亿个晶体管!这意味着 H100 GPU 上只有 3.3% 的晶体管用于矩阵乘法!
这是NVIDIA和其他灵活的 AI 芯片经过深思熟虑的设计决定的。如果想要支持所有类型的模型(比如CNN、LSTM、SSM 等),那么没有比这更好的设计了。
而Etched公司的Sohu芯片仅支持运行Transformer架构的AI大模型,这使得其可以在芯片上安装更多的 FLOPS,且无需降低精度或稀疏性。
2、提升内存带宽利用率
通常来说,AI推理会受到内存带宽的限制,计算的限制相对较小。但是事实上,对于像Llama-3这样的现代模型来说,需要更高的计算力来提升带宽的利用率。
如果使用NVIDIA和 AMD 的标准基准:2048 个输入标记和 128 个输出标记。大多数 AI 产品的提示比完成时间长得多(即使是新的 Claude 聊天应用在系统提示中也有 1,000 多个标记)。
在 GPU 和Sohu上,推理是分批运行的。每个批次加载一次所有模型权重,并在批次中的每个标记中重复使用它们。
通常,大语言模型输入是计算密集型的,而输出是内存密集型的。当我们将输入和输出标记与连续批处理相结合时,工作负载变得非常计算密集型。
以下是大语言模型连续批处理的示例。这里我们运行具有四个输入标记和四个输出标记的序列;每种颜色都是不同的序列。
我们可以扩展同样的技巧来运行具有 2048 个输入标记和 128 个输出标记的 Llama-3-70B。让每个批次包含一个序列的 2048 个输入标记和 127 个不同序列的 127 个输出标记。
如果我们这样做,每个批次将需要大约(2048 + 127) × 70B params × 2 bytes per param = 304 TFLOPs,而只需要加载70B params × 2 bytes per param = 140 GB模型权重和大约127 × 64 × 8 × 128 × (2048 + 127) × 2 × 2 = 72GBKV缓存权重。这比内存带宽要多得多。
NVIDIA H200需要6.8 PFLOPS的计算才能最大限度地利用其内存带宽。这是在100%的利用率下——如果利用率为30%,将需要3倍的计算量。
由于Sohu拥有如此之多的计算能力且利用率极高,因此可以运行巨大的吞吐量而不会出现内存带宽瓶颈。
3、 软件问题不再是一场噩梦
在 GPU 和 TPU 上,通常 软件开发是一场噩梦。处理任意 CUDA 和 PyTorch 代码需要极其复杂的编译器。第三方 AI 芯片(AMD、英特尔、AWS 等)在软件上总共花费了数十亿美元,但收效甚微。
但由于Etched公司的Sohu只运行Transformers,因此开发人员只需要为 Transformer 编写 软件!
大多数运行开源或内部模型的公司都使用特定于 Transformer 的推理库,如 TensorRT-LLM、vLLM 或 HuggingFace 的 TGI。
这些框架非常僵化 ——虽然你可以调整模型超参数,但实际上不支持更改底层模型代码。但这没关系,因为所有 Transformer 模型都非常相似(甚至是文本/图像/视频模型),调整超参数就是你真正需要的。
虽然这支持了 95% 的 AI 公司,但最大的 AI 实验室还是采用定制化。他们有工程师团队手动调整 GPU 内核以挤出更多的利用率,逆向工程哪些寄存器对每个张量核心的延迟最低。
Etched公司表示,“有了Sohu,您不再需要进行逆向工程。因为我们的 软件(从驱动程序到内核再到服务堆栈)都将是开源的。如果您想实现自定义转换器层,您的内核向导可以自由地这样做。”
4、成本优势
对于目前的AI基础市场运营商来说,NVIDIA的AI GPU是最为高昂的一项投资,其H100 80G版本的价格高达3万美元,即便是便宜的英特尔Gaudi 3 的价格也要15,650美元左右。
现在一座大型的AI数据中心的建设已经达到了数百亿美元,甚至传闻微软和OpenAI正计划推出被称为“星际之门”(Stargate)的AI超级计算机,用来为OpenAI提供更强的算力支持,该项目的总成本或将超过1150亿美元。显然,这当中NVIDIAAI GPU将会占据相当大的一部分成本。
并且这些高能耗的GPU还将会带来庞大的能源供应支出(按照现有的发展速度,很多地区的能源供应已经不足以支撑大型AI数据中心的建设)互联支出和散热支出。
如果一颗Etched的Sohu芯片就能够代替20颗NVIDIA H100芯片,那么这无疑将会带来巨大的采购及建设成本和运营成本的降低。
二、专用芯片替代GPU已不可避免
在Etched看来,近年来虽然GPU性能得到了增长,但是实际上并没有变得更好,因为主要是通过更先进的制程工艺以及更大的芯片面积来实现的。
近四年来,GPU芯片单位面积的计算能力 (TFLOPS) 几乎保持不变。比如NVIDIA的GB200、AMD的MI300、英特尔的Gaudi 3 和亚马逊的Trainium2 几乎都将两块芯片算作称一张加速卡,以实现“双倍”性能。
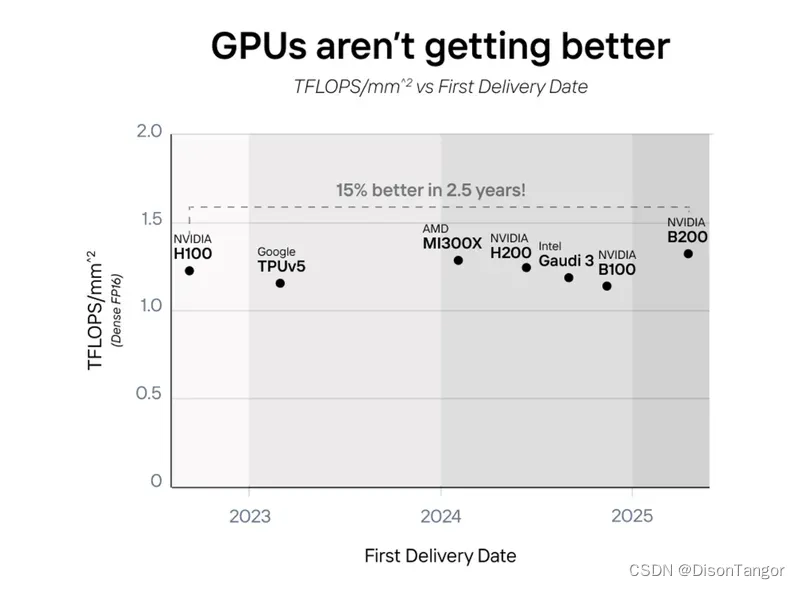
面对越来越庞大的大语言模型对于AI算力需求的快速增长,GPU芯片在摩尔定律放缓以及单位面积AI算力提升放缓的背景之下,已经难以满足需求,因此提高性能的唯一方法就是采用专用芯片。
Etched公司指出,在Transformer架构的模型统治世界之前,许多公司都构建了灵活的 AI 芯片和 GPU 来处理数百种不同的算法模型。
比如:NVIDIA的GPU、谷歌的TPU、亚马逊的 Trainium、AMD的MI系列加速器、英特尔的Gaudi加速器、Graphcore 的 IPU、SambaNova SN 系列芯片、Cerebras的CS系列晶圆级AI芯片、Groq的GroqNode、Tenstorrent 的 Grayskull、D-Matrix 的 Corsair、寒武纪的思源等。
但是几乎没有厂商制造过专门针对Transformer架构算法的专用 AI 芯片 (ASIC)。因为一个芯片项目至少将花费 5000 万到 1 亿美元,需要数年时间才能投入生产。
如果真的一个特定算法模型推出专用的AI芯片,很可能在这期间由于新的更优秀算法架构出现,而使得原来的专用的AI芯片不再有效,这将会没有市场。
但是现在情况变了,Transformer 架构的算法模型市场规模正在迅速增长。在 ChatGPT 出现之前,Transformer 推理的市场规模约为 5000 万美元,而现在已达到数十亿美元。
所有大型科技公司都使用 Transformer 架构的模型,比如OpenAI、谷歌、亚马逊、微软、Meta 等。
另外,AI算法经过多年的发展,已经开始出现架构上的融合趋势。AI模型过去发展很快,因此可能每个几个月就会有新的AI模型出来。
但是自GPT-2以来,最先进的模型架构几乎保持不变,不论是OpenAI 的 GPT 系列、Google 的 PaLM、Facebook 的 LLaMa,甚至 Tesla FSD 都是基于Transformer架构。

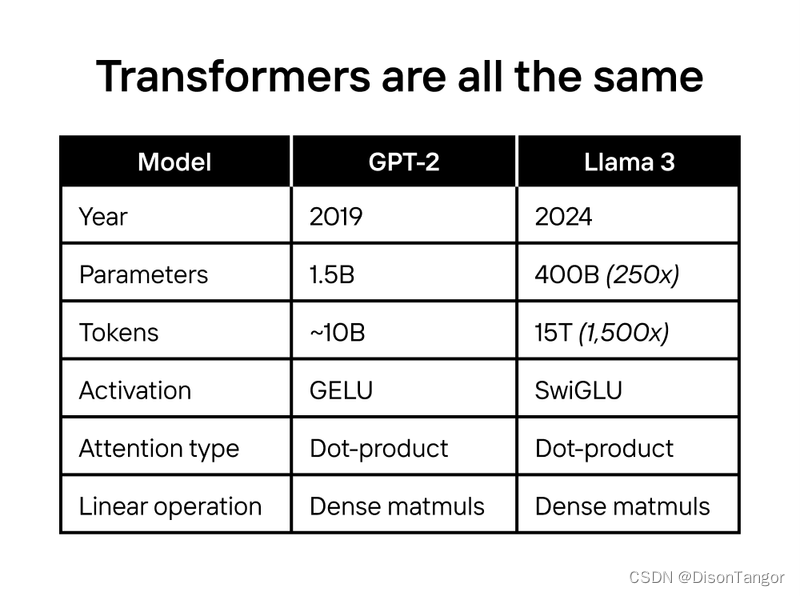
在此背景之下,如果算法模型架构开始趋于稳定,那么想要进一步提升算力,专拥的ASIC芯片将会是很好的选择。
特别是在目前基于GPU的AI训练和推理基础设施成本超过100亿美元时,这样高昂的成本的压力之下,专用的AISC是不可避免的,因为1%的改进就足以覆盖专用AISC的成本。
事实上,在特定算法模型上,ASIC 的速度可能会比 GPU 快几个数量级。比如,当针对比特币矿机的AISC芯片于 2014 年进入市场时,传统的利用GPU 来“挖矿”的做法很快被抛弃,因为使用AISC比使用GPU来挖掘比特币更便宜。
显然,在AI算法模型基础架构开始趋于稳定,GPU算力提升遭遇瓶颈以及成本越来越高的情况下,人工智能领域可能也将会发生同样的事情。这也正是Etched公司下重注推出基于Transformer架构专用的AISC芯片 “Sohu”的原因。
三、对于未来的一场豪赌
与NVIDIA等头部的AI公司一样,Etched公司也预测,在五年内,AI模型在大多数标准化测试中将变得比人类更聪明。
Etched公司进一步指出, Meta训练的 Llama 400B(2024 SoTA,比大多数人类都聪明)所用的计算量,比 OpenAI 在 GPT-2(2019 SoTA)上所用的计算量要高出 50,000 倍。通过为人工智能模型提供更多计算力和更好的数据,它们会变得更聪明。
规模化将是未来几十年来唯一持续有效的秘诀,每家大型人工智能公司(谷歌、OpenAI / 微软、Anthropic / 亚马逊等)都将在未来几年投入超过 1000亿美元来保持规模的增长。我们正处于有史以来最大规模的基础设施建设中。
OpenAI 首席执行官Sam Altman此前就曾表示:“规模化确实是一件好事。当我们在太阳周围建造出戴森球时,我们就可以讨论是否应该停止规模化,但在此之前不能停止。”
Anthropic 首席执行官 Dario Amodei也表示:“我认为 (我们)的规模可以扩大到 1000 亿美元,我们将在几年内实现这一目标。”
不过,如果按照现在的AI数据中心算力,再扩大 1,000 倍,将会面临非常昂贵的成本。下一代数据中心的成本将超过一个小国一年的GDP。按照目前的速度,现有的硬件、电网和资金投入都跟不上需求。
Etched公司表示:“我们并不担心数据耗尽。无论是通过合成数据、注释管道还是新的 AI 标记数据源,我们都认为数据问题实际上是推理计算问题。Meta CEO Mark Zuckerberg、Anthropic CEO Dario Amodei、 Google DeepMind CEO Demis Hassabis 似乎都同意这一观点。”
基于这样的发展趋势,Etched公司认为,未来能够获胜的大模型一定会是那些能够在硬件上运行速度最快、成本最低的模型。
Transformer 功能强大、实用且利润丰厚,足以在替代方案出现之前主宰每个主要的 AI 计算市场。
目前,Transformer 正在为每款大型 AI 产品提供动力:从代理到搜索再到聊天。很多AI 实验室已投入数亿美元进行研发,以优化 GPU 以支持 Transformer。
并且当前的和下一代最先进的大模型也都是 Transformer架构的。
随着这些大模型的规模在未来几年内所需要的硬件资源从 10 亿美元扩大到 100 亿美元,再到 1000 亿美元,测试新架构的风险也随之飙升。
与其重新测试缩放定律和性能,不如花时间在 Transformer 之上构建功能,例如多标记预测等。
当今的很多 软件堆栈也针对 Transformer 进行了优化。每个流行的库(TensorRT-LLM、vLLM、Huggingface TGI 等)都有用于在 GPU 上运行 Transformer 架构模型的特殊内核。
许多基于Transformer 构建的功能在替代方案中不易获得支持(例如推测解码、树搜索)。
所以,未来的硬件堆栈也将持续针对 Transformer 进行优化。比如,NVIDIA的 GB200 特别支持 Transformer(TransformerEngine)。
在Etched公司看来,Transformer架构就是未来,“如果我们猜对了,Soho将改变世界。这就是我们下注的原因。”Etched公司在网站上写道。
在2022年的时候,Etched公司就已经开始下注,开始研发基于Transformer架构的Sohu芯片,当时ChatGPT还没有推出,图像和视频生成模型是 U-Nets,自动驾驶汽车由 CNN 驱动,而 Transformer 架构并未无处不在。显然这是一场豪赌。
虽然现在看来,Sohu可以支持所有的Transformer架构的AI大模型,比如OpenAI的GPT、Sora,谷歌的Gemini、Stability AI公司的Stable Diffusion 3 等,但是在两年前,这些模型都还没有出现。
如果,Transformer架构的AI大模型没有成为主流,再加上无法支持CNN、RNN 、LSTM等传统模型以及SSM、RWKV 或其他的全新架构的AI大模型,那么Sohu将会毫无用处。
幸运的是,从目前来看,形势已经对Etched公司有利。从语言到视觉,每个领域的顶级模型现在都是基于Transformer架构的。
这种融合不仅验证了Etched公司下对了赌注,也有望使Sohu成为十年来最重要的硬件项目。
“像 Sohu 这样的 ASIC 芯片进入市场,标志着进入一条不归路。其他Transformer “杀手”要想成功,需要在 GPU 上的运行速度需要比 Transformer 在 Sohu 芯片上的运行速度更快。
如果发生这种情况,我们也会为此构重新建一个 ASIC!”Etched公司非常坚定的说道。
最后说一句,Etched公司的看法与芯智讯在多年前所写的《NVIDIA的AI盛世危机!》所表达的核心观点类似,即GPU并是不专为处理特定AI算法所设计的,其优势在于比其他AI芯片更通用,可以适应各种AI算法,但是当未来AI算法的演进开始趋于稳定时,那么届时专用的面向特定算法的更高效的ASIC芯片无疑将会更具优势。
现在越来越多的云服务厂商都有推出自研的云端AI芯片也正是顺应这一趋势。
感谢大家花时间阅读我的文章,你们的支持是我不断前进的动力。期望未来能为大家带来更多有价值的内容,请多多关注我的动态!