摘要:
1,字典树的介绍
2,字典树的插入
3,字典树的查询
4,字典树排序
5,字典树的删除
6,字典树的用途
1,字典树的介绍
字典树又称 Trie 树 ,单词查找树,前缀树,也是一种树状结构,就是在查询目标时,像字典一样按照一定顺序和步骤访问树的节点,它主要利用字符串的公共前缀来减少查询次数,最大限度地减少字符串比较。
比如要查找一个字符串是否存在,或者是否存在 xxx 开头的字符串。假设字符串只包含小写字母,那么我们可以把字典树看作是一棵每个节点最多有 26 个子节点的树。
字典树中根节点是不存储数据的,除了根节点以外,每个节点代表一个字符,从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
比如有 wang, yi ,bo , yibo 等字符串,只需要把它添加到字典树中,然后在每个字符串末尾标记为一个完整的字符串即可,如图下图所示。
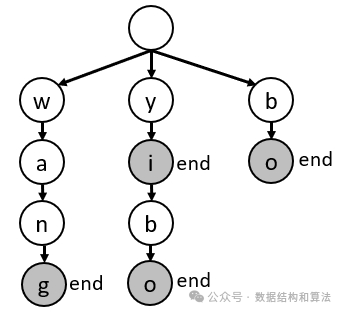
比如查找字符串 wan ,因为字符串的最后一个字符 n 在字典树中没有标记,所以 wan 不是一个完整的字符串。又比如查找字符串 yi ,因为字符串的最后一个字符 i 在字典树中标记了,所以 yi 是一个完整的字符串。
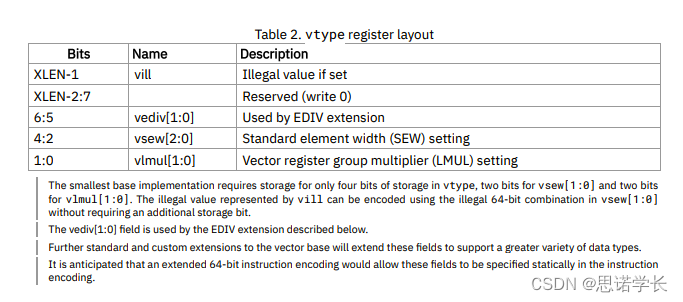
字典树中每个节点需要两个变量,一个是记录子节点的数组,一个是标记从根节点到当前节点是否是一个完整的字符串。
Java 代码:
// 节点类。
class TrieNode {
boolean isEnd; // 标记是否为完整字符串。
TrieNode[] children; // 子节点数组。
public TrieNode() {
isEnd = false;// 默认不是完整字符串。
// 默认每个节点最多有26个子节点,还可以使用map。
children = new TrieNode[26];
}
}C++ 代码:
// 节点类。
class TrieNode {
public:
bool isEnd = false; // 标记是否为完整字符串。
TrieNode *children[26];// 子节点数组。
};这里我们规定只查询小写字母,如果包含其他字母的话可以使用 Map 。
Map<Character, TrieNode> map = new HashMap<>();// java
unordered_map<char, TrieNode> mp;// c++字典树的 3 个基本性质:
1,根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2,从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3,每个节点的所有子节点包含的字符都不相同。
2,字典树的插入
先来看一下字典树的插入,实际上也是字典树的创建,它的步骤如下:
1,从根节点开始,依次读取字符串中的每个字符。