资源1:晏明 - RISC-V向量扩展指令架构及LLVM自动向量化支持 - 202112118 - 第13届开源开发工具大会(OSDTConf2021)_哔哩哔哩_bilibili资源2:张先轶 - 基于RISC-V向量指令集优化基础计算软件生态【第12届开源开发工具大会(OSDT2020)】_哔哩哔哩_bilibili
资源3:Release Vector Extension 1.0, frozen for public review · riscv/riscv-v-spec · GitHub
1. SIMD简介
1.1 SIMD(单指令多数据)与 SISD
在计算机架构中,SIMD(Single Instruction, Multiple Data)和SISD(Single Instruction, Single Data)是两种不同的处理数据的方法。
SIMD指令允许您执行的操作是将相同的操作应用于多个元素。我们可以将它与SISD(单指令单数据进行对比)
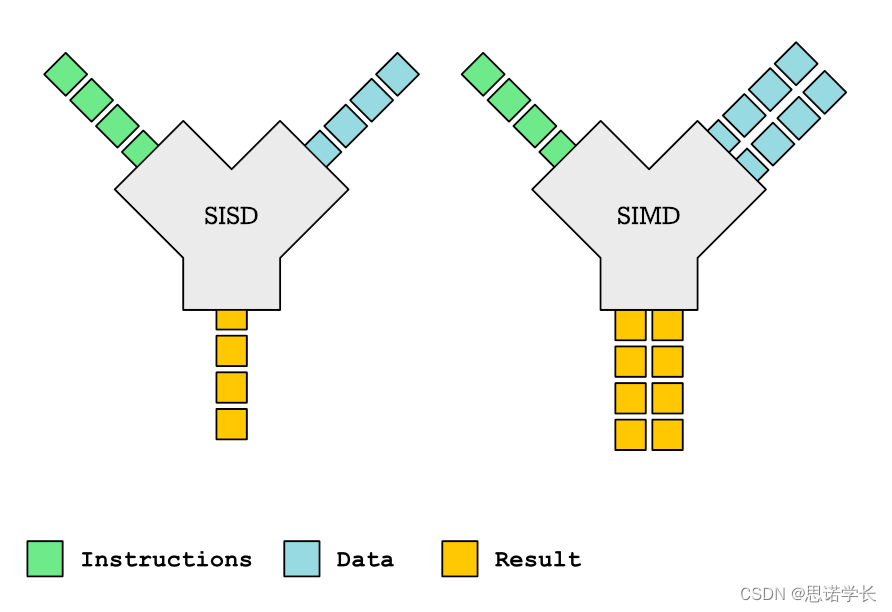
1.1.1 SISD (Single Instruction, Single Data)
标量指令,每次处理一个数据。
这是最传统的计算机架构类型,它在任何时刻只能执行一条指令操作一个数据。这意味着处理器每次只能处理一个数据点。大多数顺序计算机都是基于SISD架构的,它们按顺序执行指令,每个指令操作单个数据项。SISD架构适用于大多数通用计算需求,但在处理大量数据或进行高性能计算任务时,可能不如其他架构高效。
每条指令仅指定处理单个数据。处理多个数据项需要多条指令,如下
add x10,x11,x12
这种方法速度慢,很难看出不同寄存器之间的关系。在32位处理器上,执行大量单独的8位或者16位操作也不能有效地使用机器资源。
1.1.2 SIMD (Single Instruction, Multiple Data)
这种架构允许一条指令同时对多个数据进行操作。这是通过在处理器中使用向量处理单元或SIMD寄存器来实现的,这些单元可以存储多个数据点,并允许一条指令同时对这些数据执行相同的操作。SIMD架构在处理图像处理、科学计算、机器学习等需要对大量数据执行相同操作的应用程序时特别有效。它能够显著提高这些任务的处理速度。
一个操作可以指定对储存在一个寄存器中的多个数据进行相同的处理。
VADD. I16 Q10,Q8,Q9
SIMD(Single Instruction, Multiple Data)架构在特定的应用领域内提供了显著的性能优势,但也存在一些局限性。以下是SIMD的优势与缺点的概述:
1.1.2.1 SIMD的优势
1.1.2.1.1 提高数据处理效率
SIMD可以同时对多个数据执行相同的操作,显著提高了数据处理的速度,尤其是在处理大规模数据集时,如图像处理、视频编解码、科学计算和机器学习等应用。通过同时对多个数据点执行相同的操作,SIMD可以大幅提高数据处理速度,尤其是在涉及大量数据运算的应用中。
1.1.2.1.2 能效比提升
由于可以在单个操作中处理多个数据点,SIMD架构可以更有效地利用处理器资源,减少了必要的指令数量和处理器周期,从而在执行大规模并行数据处理任务时提高能效比。相较于分别对每个数据点执行操作,SIMD通过减少指令的数量来降低能源消耗,从而提高能效。
1.1.2.1.3 简化编程模型
对于能够利用数据并行性的应用,SIMD提供了一种相对简单的方式来加速计算,程序员可以不必管理复杂的多线程或多进程并发模型,而是通过向量化操作来实现性能提升。
1.1.2.1.4 并行处理能力
SIMD架构能够利用数据并行性,有效加速并行处理任务,这对于实时处理和高性能计算来说至关重要。
1.1.2.2 缺点
1.1.2.2.1 编程复杂性
虽然SIMD可以简化某些并行编程任务,但编写有效利用SIMD指令的代码通常需要对目标应用和硬件架构有深入的理解。此外,需要手动优化代码以适应特定的SIMD架构,这可能会增加开发复杂性。利用SIMD的高性能可能需要开发者对算法进行特殊优化,这可能增加编程的复杂性。
1.1.2.2.2 应用局限性
SIMD最适合于那些可以进行大量相同操作的数据并行任务。对于需要不同数据执行不同操作的任务,或者数据依赖性导致无法并行的情况,SIMD的优势可能会大幅减少。
1.1.2.2.3 硬件资源限制
实现SIMD需要额外的硬件资源,如向量寄存器和专门的执行单元。这意味着,与传统的标量处理相比,SIMD架构的处理器可能会更复杂和成本更高。在一些场景中,使用SIMD指令可能会占用大量的处理器资源,如寄存器,这可能限制其他类型操作的性能。
1.1.2.2.4 可移植性问题,向量长度固定,处理器和应用程序的依赖性
不同的处理器可能支持不同的SIMD指令集和向量大小,这可能导致针对特定硬件优化的代码在其他硬件上运行效率不高,甚至无法运行。因此,实现跨平台高性能应用可能需要针对每种目标硬件编写和优化不同的代码版本。
SIMD指令通常对特定长度的数据向量进行操作。如果处理的数据量不匹配处理器支持的向量长度,这可能导致效率低下。
不同的处理器可能支持不同长度的SIMD指令,这意味着软件可能需要针对特定硬件进行优化才能实现最佳性能。
综上所述,SIMD架构能够为适合的应用场景提供显著的性能提升和能效优势,但同时也带来了编程复杂性、应用局限性、硬件资源和可移植性方面的挑战。
1.1.2.2.5 向量长度的限制
可扩展性问题:固定的向量长度可能不适合所有应用场景,特别是当数据集的大小变化较大时,处理器可能无法充分利用其并行处理能力。
效率问题:当数据集大小不能整除向量长度时,可能会出现尾部处理问题,导致处理效率降低。
兼容性问题:软件需要考虑不同硬件平台上SIMD向量长度的差异,以确保最佳性能和兼容性。
尽管存在这些缺点,SIMD架构在许多领域仍然是加速数据处理的有效手段。开发者和架构师需要根据具体的应用需求和硬件能力,权衡SIMD的优势和限制,以实现最佳的性能和效率。
1.1.3 RISC-V架构中的应用
在RISC-V架构中,也支持这两种处理模式。RISC-V是一种开源指令集架构(ISA),它的设计旨在支持从最小的嵌入式处理器到高性能计算(HPC)系统的广泛设备。RISC-V定义了多个扩展,其中一些支持SIMD操作,例如“V”扩展,它为向量处理提供支持。这意味着RISC-V处理器可以配置为支持SIMD操作,以提高处理大规模数据集时的性能。
RISC-V向量扩展(RVV)是RISC-V指令集架构的一部分,专门用于支持向量计算。RVV的设计目标是提供一种高效、可扩展的向量处理能力,以支持从小型嵌入式系统到大型高性能计算环境的广泛应用。以下是RVV的一些关键特点:
1.1.3.1 可扩展的向量长度
RVV允许实现可变的向量长度,这意味着硬件可以根据需要处理不同长度的向量。这种灵活性使得RVV能够高效地适应各种处理需求,从而提高了处理器的通用性和性能。
1.1.3.2 类型和操作的丰富性
RVV支持多种数据类型,包括不同长度的整数和浮点数。它还定义了一系列的向量操作,如算术运算、比较、逻辑运算等,这使得RVV能够支持广泛的数值和非数值计算任务。
1.1.3.3 向量长度不固定
与其他一些固定向量长度的SIMD架构不同,RVV允许在运行时确定向量长度,这提供了更好的资源利用率和灵活性。这意味着软件可以根据当前的硬件配置和数据集大小来优化性能,而无需为特定硬件配置重新编译。
1.1.3.4 掩码操作
RVV支持使用掩码进行向量操作,这允许对向量中的单独元素进行有条件的处理。这种功能对于实现复杂的数据依赖性操作非常重要,如稀疏数据处理或条件分支。
1.1.3.5 分组加载和存储
RVV提供了分组加载和存储指令,允许数据以分组的形式从内存中加载到向量寄存器,或从向量寄存器存储回内存。这有助于更有效地管理内存带宽,提高数据访问效率。
1.1.3.6 向量配置指令
RVV引入了向量配置指令,允许动态调整向量操作的参数,如向量长度和数据类型。这增加了编程的灵活性,允许软件更好地利用硬件资源。
1.1.3.7 兼容性和可扩展性
RVV设计时考虑了与RISC-V其他指令集扩展的兼容性,确保了向量扩展能够无缝集成到现有的RISC-V生态中。此外,它的设计支持未来的扩展和优化,以适应新的计算需求。
总的来说,RISC-V向量扩展通过提供一种灵活、高效的方式来处理向量计算,旨在满足从嵌入式到高性能计算的广泛应用需求。
简而言之,SISD和SIMD代表了处理数据的两种不同方法,SISD适用于处理单个数据点的任务,而SIMD适用于同时处理多个数据点的任务。RISC-V通过支持包括SIMD在内的不同架构扩展,提供了灵活的处理能力,以适应各种应用需求。
2. RISC-V向量扩展
2.1 灵活的访存指令
RISC-V向量扩展(RVV)为了提高数据处理效率和灵活性,设计了一系列灵活的访存指令。这些指令允许高效地从内存加载数据到向量寄存器,以及将数据从向量寄存器存储回内存。以下是一些关键点,描述了RVV中灵活访存指令的特性:
2.1.1 分段加载和存储(Strided Loads and Stores)
这类指令允许从内存中以固定的间隔(步长)加载数据,或者将数据存储到内存中的固定间隔位置。这对于处理间隔排列的数据集(如矩阵的某一列)特别有用。
2.1.2 索引加载和存储(Indexed Loads and Stores)
索引访存指令允许使用另一个向量中的索引值来指定每个元素的加载或存储位置。这为处理非规则数据结构提供了极大的灵活性,例如,当数据分布在内存中的不连续位置时。
2.1.3 单元素加载和存储(Unit-stride Loads and Stores)
这类指令用于连续地加载或存储数据,没有间隔地从一个地址到下一个地址。这是最直接的访存形式,适用于连续数据结构的高效处理。
2.1.4 掩码加载和存储(Masked Loads and Stores)
RVV支持使用掩码来进行条件加载和存储。这意味着可以根据掩码向量中的位来选择性地加载或存储向量中的元素。这对于处理条件操作或稀疏数据集非常有用。
2.1.5 向量-标量操作(Vector-Scalar Operations)
虽然不是直接的访存指令,但RVV允许在向量操作中使用标量值,这包括从标量寄存器加载数据到向量寄存器的能力。这增加了编程模型的灵活性,允许更高效的数据处理。
2.1.6 向量配置指令(Vector Configuration Instructions)
这些指令允许动态配置向量操作的参数,如向量长度和数据类型,进一步提高了对访存操作的控制和灵活性。
通过这些灵活的访存指令,RVV能够有效支持各种数据访问模式,从而优化性能并简化编程模型。这些指令使得RVV非常适合处理广泛的应用场景,包括高性能计算、数据分析、机器学习等,其中数据访问模式可能非常多样。
2.2 配置和设置指令
在RISC-V向量扩展(RVV)中,配置和设置指令是用于定义和控制向量操作的行为的一组指令。这些指令允许程序员在执行向量操作之前对向量处理单元(VPU)进行精确的配置,包括设置向量长度、数据类型和执行掩码等。这种灵活性是RVV设计中的一个关键特点,它允许软件根据运行时的需求和硬件的能力来动态调整参数,从而实现高效的向量处理。以下是一些关键的配置设置指令:
2.2.1 向量长度配置指令(VSETVLI)
这是RVV中最核心的配置指令之一,用于设置向量长度(VL)和向量数据类型。`VSETVLI`指令允许基于硬件的最大向量长度(VLMAX)来动态选择当前操作的向量长度,同时指定操作的数据类型(如整数、浮点数等)。这使得代码能够在不同的硬件上以最优的向量长度运行,而无需重新编译。
2.2.2 向量长度配置指令(VSETVL)
这个指令与`VSETVLI`类似,但它允许程序使用一个寄存器中的值来设置向量长度,提供了更大的灵活性。


2.2.3 掩码配置指令
RVV提供了操作掩码的能力,使得向量操作可以选择性地对向量中的元素进行操作。掩码操作对于执行条件处理和管理稀疏数据集非常有用。
2.2.4 向量数据类型配置
通过`VSETVLI`和`VSETVL`指令中的类型字段,程序可以指定向量操作的具体数据类型,如8位、16位、32位或64位的整数,以及单精度或双精度浮点数等。这允许同一套向量指令在不同数据类型上重用,提高了代码的可移植性和灵活性。
这些配置设置指令为RVV提供了极高的灵活性和可扩展性,允许软件开发者根据具体的应用场景和硬件特性来优化他们的程序。通过动态地调整向量长度和数据类型,RVV能够有效地支持各种向量处理需求,从嵌入式系统到高性能计算应用,同时保持代码的简洁和可维护性。
2.2 vtype
在RISC-V向量扩展(RVV)中,vtype寄存器是一个关键的系统寄存器,用于控制和指示当前向量操作的类型和模式。这个寄存器包含了多个字段,每个字段都有特定的作用,它们共同定义了向量指令的执行特性,包括向量长度(VL),数据类型,以及其他可能的配置选项如分段加载/存储操作的步长等。
2.2.1 vtype寄存器的主要字段
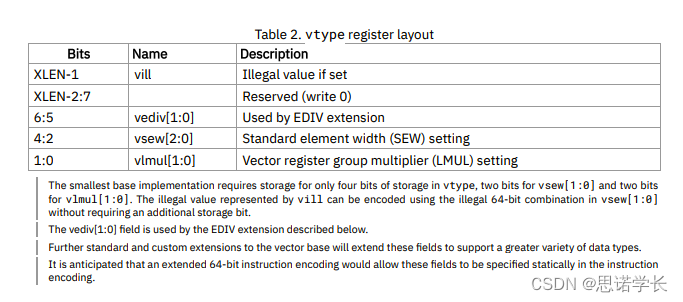
2.2.1.1 向量数据类型(`vsew`)
这个字段指定了向量中元素的数据宽度,例如8位、16位、32位或64位等。它决定了向量操作处理的数据类型大小。
2.2.1.2 向量长度乘数(`vlmul`)
这个字段允许向量寄存器组以不同的组合方式使用,从而支持更宽的向量操作或更多的并行度。它影响了向量寄存器组的配置和使用方式。
2.2.1.3 掩码寄存器(`vta`和`vma`)
这些字段控制向量操作中的掩码类型,包括对齐访问(`vta`)和掩码访问(`vma`),允许细粒度控制向量操作的执行。
2.2.1.4 向量长度(VL)
虽然VL通常是通过`vsetvli`或`vsetvl`指令动态设置的,但`vtype`寄存器的配置直接影响可以实现的VL的最大值和行为。
2.2.1.5 vtype寄存器的作用
配置向量操作:通过设置`vtype`寄存器,软件可以详细配置向量指令的执行方式,包括操作的数据类型和向量长度,这为高效的向量计算提供了基础。
适应不同的硬件:由于`vtype`的配置可以动态变化,软件可以根据运行时检测到的硬件能力(如支持的最大向量长度和数据宽度)来调整向量操作的配置,实现跨不同硬件的可移植性和优化。
优化性能:通过灵活地使用`vtype`寄存器配置,程序可以针对具体的算法和数据特征来优化向量操作,比如选择最适合处理特定数据大小和形状的向量长度和数据类型,从而提高计算效率和性能。
vtype寄存器的设计反映了RISC-V向量扩展的核心设计哲学——灵活性和可扩展性,使得RISC-V向量指令集能够适应广泛的应用需求,从而在不同的计算环境中实现高效的向量计算。
2.3 寄存器组
在RISC-V向量扩展(RVV)中,向量寄存器组是一组专门设计用于存储和操作向量数据的寄存器。这些寄存器与传统的标量寄存器不同,它们能够存储多个数据元素,并支持对这些元素进行并行操作。向量寄存器组的设计旨在提高数据处理的效率,特别是对于那些可以利用数据并行性的应用场景,如数字信号处理、图像处理、科学计算等。
2.3.1 向量寄存器组的特点
2.3.1.1 寄存器数量和大小
RVV规范定义了一组向量寄存器,数量通常为32个(从v0到v31),但这可以根据具体的实现而变化。每个向量寄存器的大小不是固定的,而是可以配置的,允许存储多个数据元素。向量寄存器的大小通常以位(bit)为单位描述,其最大长度由硬件支持的最大向量长度决定。
2.3.1.2 动态配置
通过vsetvli(设置向量长度和类型的指令)等指令,软件可以动态地配置向量寄存器组的行为,包括向量长度(即寄存器中可以存储的元素数量)和元素的数据类型(如8位整数、32位浮点数等)。这种动态配置能力提供了极大的灵活性,允许软件根据不同的应用需求和硬件能力来优化性能。
2.3.1.3 并行操作
向量寄存器组设计用于支持单指令多数据(SIMD)操作,这意味着一条向量指令可以同时对寄存器中的多个数据元素执行相同的操作。这种并行处理能力可以显著提高数据处理任务的效率。
2.3.1.4 掩码操作
RVV允许通过掩码操作来条件地执行向量指令,即只对那些被掩码选中的元素执行操作。这为处理复杂的数据依赖和条件逻辑提供了强大的工具。
2.3.1.5 支持多种数据类型
向量寄存器组支持多种数据类型,包括不同长度的整数和浮点数,这使得它们可以适用于广泛的应用场景。
2.3.1.6 适用于多种计算模型
由于其高度的配置能力和强大的并行处理能力,向量寄存器组适用于多种计算模型,从传统的数据并行处理到更复杂的模型,如图形处理和机器学习等。
向量寄存器组是RISC-V向量扩展的核心组成部分,它们的设计目的是为了提供高效的并行数据处理能力,以适应当前和未来计算密集型应用的需求。通过灵活的配置和强大的处理能力,向量寄存器组使得RISC-V架构能够有效地支持宽广的应用领域。