文章目录
- Github
- 文档
- 推荐文章
- 简介
- 安装
- 官方示例
- google-t5/t5-small
- 使用脚本进行训练
- Pytorch
- 机器翻译
- 数据集下载
- 数据集格式转换
Github
- https://github.com/huggingface/transformers
文档
- https://huggingface.co/docs/transformers/index
- https://github.com/huggingface/transformers/blob/main/i18n/README_zh-hans.md
推荐文章
- http://jalammar.github.io/illustrated-transformer/
简介
Transformers是一种基于注意力机制(Attention Mechanism)的神经网络模型,广泛应用于自然语言处理(Natural Language Processing)任务中,如机器翻译、文本生成和文本分类等。
传统的序列模型(如循环神经网络)在处理长距离依赖时可能遇到困难,而Transformers通过引入注意力机制来解决这个问题。注意力机制使得模型能够在序列中对不同位置的信息进行加权关注,从而捕捉到全局的上下文信息。
在Transformers中,输入序列首先被分别编码为查询(Query)、键(Key)和值(Value)向量。通过计算查询与键的相似度,得到注意力分数,再将注意力分数与值相乘并加权求和,即可得到最终的上下文表示。这种自注意力机制允许模型在编码器和解码器中自由交换信息,从而更好地处理长距离依赖关系。
Transformer模型的核心组件是多层的自注意力机制和前馈神经网络。它的架构被广泛应用于许多重要的NLP任务,其中最著名的是BERT(Bidirectional Encoder Representations from Transformers),它在多项NLP任务上取得了突破性的性能。
除了NLP领域,Transformers模型也被应用于计算机视觉和其他领域,用于处理序列建模和生成任务。它已经成为深度学习中非常重要和有影响力的模型架构之一。
安装
pip install transformers
# PyTorch(推荐)
pip install 'transformers[torch]'
# TensorFlow 2.0
pip install 'transformers[tf-cpu]'
- M1 / ARM 用户在安装 TensorFLow 2.0 之前,需要安装以下内容
brew install cmake
brew install pkg-config
- 验证是否安装成功
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
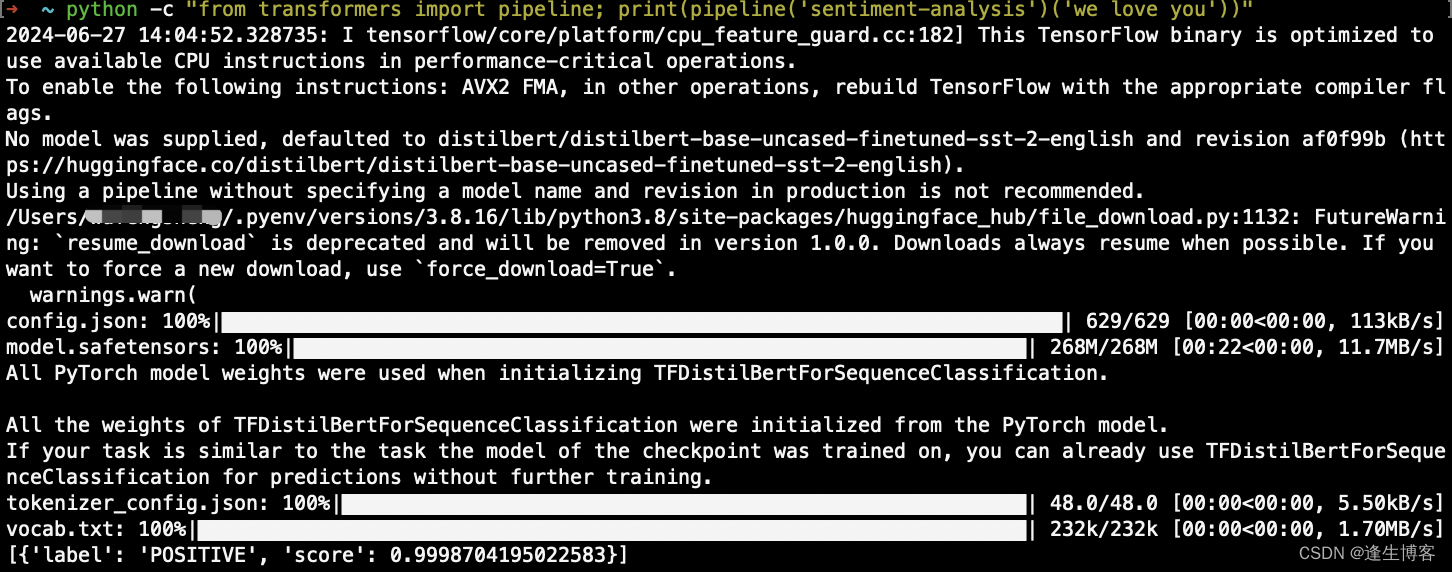
注意: 以上验证操作需要“连网”,否则因无法下载文件而出现报错。
官方示例
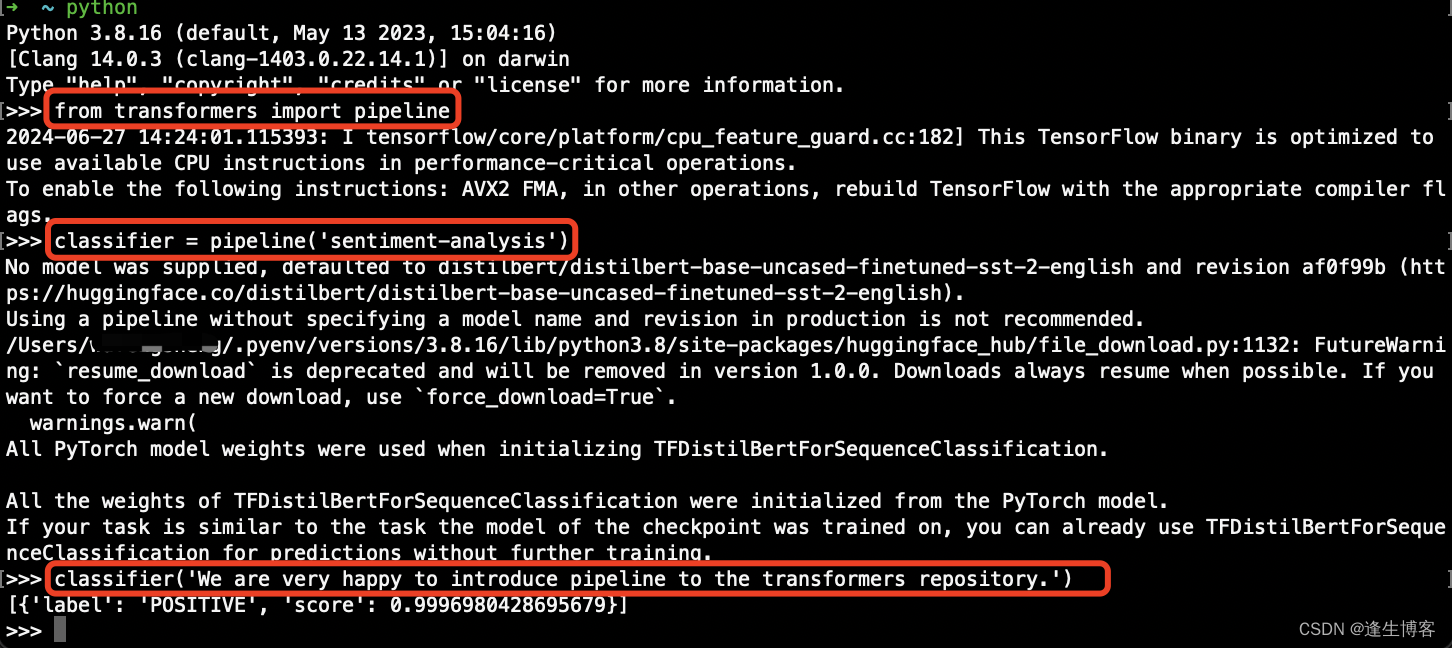
from transformers import pipeline
# 使用情绪分析流水线
classifier = pipeline('sentiment-analysis')
classifier('We are very happy to introduce pipeline to the transformers repository.')
- 输出结果
[{'label': 'POSITIVE', 'score': 0.9996980428695679}]
google-t5/t5-small
- https://huggingface.co/google-t5/t5-small
Google的T5(Text-To-Text Transfer Transformer)是由Google Research开发的一种多功能的基于Transformer的模型。T5-small是T5模型的一个较小的变体,专为涉及自然语言理解和生成任务而设计。
-
Transformer架构:与其它模型类似,T5-small采用了Transformer架构,该架构在各种自然语言处理(NLP)任务中表现出色。
-
多功能性:T5-small的设计理念是将所有的NLP任务都看作文本到文本的转换问题,使得模型可以通过简单地调整输入和输出来适应不同的任务。
-
预训练和微调:T5-small通常通过大规模的无监督预训练来学习通用的语言表示,然后通过有监督的微调来适应特定任务,如问答、摘要生成等。
-
应用广泛:由于其灵活性和性能,在各种NLP应用中都有广泛的应用,包括机器翻译、文本生成、情感分析等。
- 下载 google-t5/t5-small 模型
# 模型大小 4.49G
git clone https://huggingface.co/google-t5/t5-small
- 安装依赖库
pip install 'transformers[torch]'
pip install sentencepiece
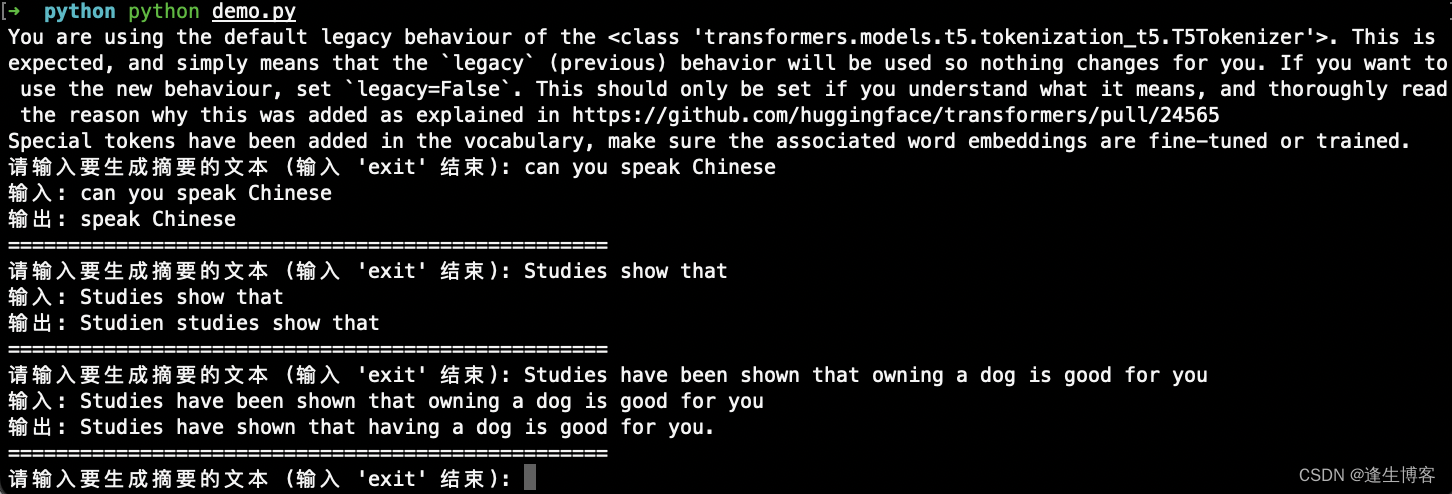
- 文本生成示例
from transformers import T5Tokenizer, T5ForConditionalGeneration
# Step 1: 加载预训练的T5 tokenizer和模型
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
while True:
# Step 2: 接收用户输入
input_text = input("请输入要生成摘要的文本 (输入 'exit' 结束): ")
if input_text.lower() == 'exit':
print("程序结束。")
break
# 使用tokenizer对输入文本进行编码
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
# Step 3: 进行生成
# 使用model.generate来生成文本
output = model.generate(input_ids, max_length=50, num_beams=4, early_stopping=True)
# Step 4: 解码输出
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
# 打印输入和输出结果
print("输入:", input_text)
print("输出:", output_text)
print("=" * 50) # 分隔符,用来区分不同输入的输出结果
使用脚本进行训练
-
https://huggingface.co/docs/transformers/run_scripts
-
从源代码安装 Transformers
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
- 将当前的 Transformers 克隆切换到特定版本
# 本地分支
git branch
# 远程分支
git branch -a
# 切换分支 v4.41.2,因为当前安装的版本是 v4.41.2
git checkout tags/v4.41.2
- 安装依赖库
# 安装用于处理人类语言数据的工具集库
pip install nltk
# 安装用于计算ROUGE评估指标库
pip install rouge_score
Pytorch
示例脚本从 🤗 Datasets库下载并预处理数据集。然后,该脚本使用Trainer在支持摘要的架构上微调数据集。以下示例展示了如何在CNN/DailyMail数据集上微调T5-small。由于训练方式的原因,T5 模型需要额外的参数。此提示让 T5 知道这是一项摘要任务。
cd transformers/examples/pytorch/summarization
pip install -r requirements.txt
python run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
注意: 家用机上训练非常耗时,建议租用GPU服务器进行测试。
- 数据缓存目录
# Linux/macOS
cd ~/.cache/huggingface
# Windows
C:\Users\{your_username}\.cache\huggingface
- datasets
2.6G cnn_dailymail
798M downloads
机器翻译
数据集下载
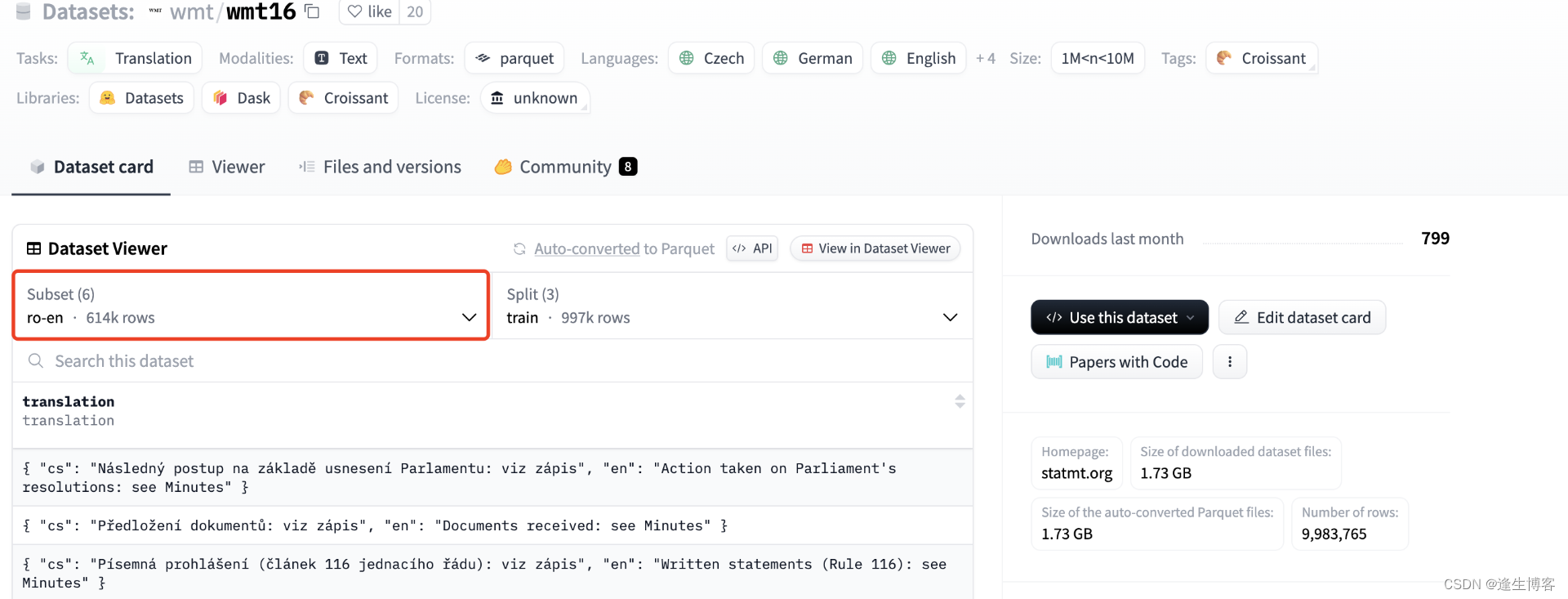
- https://huggingface.co/datasets/wmt/wmt16
数据集格式转换
pip install pandas
import pandas as pd
import jsonlines
# 输入和输出文件路径
input_parquet_file = './input_file.parquet'
output_jsonl_file = './output_file.jsonl'
# 加载 Parquet 文件
df = pd.read_parquet(input_parquet_file)
# 将数据写入 JSONLines 文件
with jsonlines.open(output_jsonl_file, 'w') as writer:
for index, row in df.iterrows():
json_record = {
"source_text": row['source_column'], # 替换成实际的源语言列名
"target_text": row['target_column'] # 替换成实际的目标语言列名
}
writer.write(json_record)
- train.jsonl
{ "cs": "Následný postup na základě usnesení Parlamentu: viz zápis", "en": "Action taken on Parliament's resolutions: see Minutes" }
- validation.jsonl
{ "en": "UN Chief Says There Is No Military Solution in Syria", "ro": "Șeful ONU declară că nu există soluții militare în Siria" }
cd examples/pytorch/translation
pip install -r requirements.txt
python run_translation.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--source_lang en \
--target_lang ro \
--source_prefix "translate English to Romanian: " \
--dataset_name wmt16 \
--dataset_config_name ro-en \
--train_file ./train.jsonl \
--validation_file ./validation.jsonl \
--output_dir /tmp/tst-translation \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
注意: 家用机上训练非常耗时,建议租用GPU服务器进行测试。