1. 对称加密、流加密和块加密
1.1 对称加密
对称加密(也称为密钥加密)是一种加密方式,其中加密和解密使用相同的密钥。这种加密方法基于二进制层面的操作,如XOR(异或)、SHIFT(位移)、替代和置换等。对称加密系统相对较快。接下来,我们将介绍对称加密的两个主要类别:流加密和块加密。
1.2 流加密
流加密是一种加密方式,其中每个明文字符按时间变化进行转换,通常是通过与伪随机数生成器产生的符号进行XOR操作来实现。这种方法的关键在于使用专门为加密应用设计的伪随机数生成器。流加密的例子包括Vernam密码(一次一密)、A5、RC4、E0等。在这些系统中,每个明文字符 mi 与一个伪随机字符 si 进行XOR运算以生成密文字符 ci 。即 ci = mi + si ,这里的加号表示XOR操作。
1.3 块加密
与流加密不同,块加密将明文分割成固定大小的块,然后对每个块使用时间不变的转换进行加密。这种方式需要将明文分成一系列的块,每个块具有固定的长度,然后使用密钥对这些块进行加密。当处理的数据不足以填充完整的块时,通常需要进行填充。块加密的常见例子包括DES、3-DES、IDEA、RC5、AES等。
总结来说,对称加密包括流加密和块加密两种主要形式,它们都在二进制层面上进行操作,包括XOR、位移、替换和置换等。流加密在时间上变化地对每个字符进行转换,而块加密则将数据分成固定大小的块进行处理。对称加密由于其加密和解密速度快、实现简单等优点,在许多加密场景中被广泛使用。
2. 流加密
对称加密中的流加密是一种加密方法,它对每个明文字符进行变化加密,这种变化随时间不同而不同。最常见的操作是将明文字符与一个伪随机生成器产生的符号进行XOR(异或)操作。具体来说,加密过程中,每个明文字符`mi`与一个伪随机符号`zi`进行XOR操作以生成密文字符`ci`,即`ci = mi + zi`;而在解密过程中,将密文字符`ci`与相同的伪随机符号`zi`进行XOR操作以还原明文字符`mi`,即`mi = ci + zi`。在这里,“+”表示XOR操作。
2.1 伪随机数生成器(GPA)
流加密的核心部分是伪随机数生成器(GPA)。这是一种自动机,它能够从有限数量的符号(称为种子或"seed")产生一个看似无限且随机的序列。为了适应加密应用,这种生成器需要满足特定的要求,特别是要避免那些可能被利用来破解密码的线性特性。
伪随机数生成器在加密中的作用非常重要,因为它决定了加密强度。如果生成器的输出可以预测或存在规律,那么加密就容易被破解。因此,为了安全,伪随机数生成器必须能够产生高度随机的输出,且其输出序列不应有任何可被利用的规律或重复模式。
总的来说,流加密通过将每个明文字符与一个伪随机序列中的对应字符进行XOR操作来加密信息,这一过程依赖于强大且不可预测的伪随机数生成器。流加密的安全性在很大程度上取决于这种生成器的随机性和不可预测性。
2.1.1 伪随机数生成器(GPA)的特点
伪随机数生成器(GPA)是一种有限状态自动机,它的特点可以总结如下:
状态空间Q:通常由n位组成的二进制数表示,例如Q={0, 1}^n,这里n代表自动机的状态位数。
状态转换函数Φ:这是一个将自动机从当前状态qt转换到下一个状态qt+1的函数,即qt+1 = Φ(qt),其中qt ∈ Q是离散时刻t的状态。
输出函数f:这是一个将每个状态映射到输出符号集合Σ中某个符号的函数,即zt = f(qt),这里的zt是时刻t的输出符号。
2.2 线性反馈移位寄存器(LFSR)
伪随机数生成器(GPA)一个典型的例子是线性反馈移位寄存器(LFSR)。LFSR通过将寄存器中的位逐个移位,同时根据反馈函数计算并输入新的位来生成位序列。反馈函数是线性的,通常是通过在特定的点上进行XOR操作来实现的。这些特定的点称为抽头(tap)。
下图是一个线性反馈移位寄存器(LFSR),它是一种用于生成伪随机二进制序列的装置。

2.2.1 LFSR包含的元素
a. 一系列的D触发器(D Flip-Flops),它们用来保存当前的状态位。
b. 每个D触发器的输出连接到下一个D触发器的输入,形成一个链条。
c. 最后一个D触发器的输出通过一些逻辑运算(通常是XOR操作),再反馈到第一个D触发器的输入。
d. ak、ak-1、`ak-2`和`ak-3`表示的是当前LFSR中的状态位,而加号表示的是XOR操作,这种线性结构正是LFSR的名称由来。
在这个系统中,输出位(即寄存器中的最右边一位)会根据反馈函数影响下一个状态,通常通过将一组位进行XOR操作来计算。在图中,这个过程通过反馈路径和XOR门(标记为“+”)实现。每个D盒子代表一个寄存器位,它存储了一个位状态,并将其传递到下一个盒子,实现了位的移动。
2.2.2 线性反馈移位寄存器(LFSR)的基本原理
LFSR生成的序列在数学上是线性的,这意味着通过观察足够长的输出序列,可以推断出生成序列的规则,并预测未来的输出。因此,尽管LFSR很高效,也容易实现,但是如果直接用于流加密,它的线性特性会使得加密系统容易被破解。
在密码学中,为了强化LFSR生成的序列的随机性和不可预测性,通常会采取非线性变换的措施,例如将多个LFSR结合,或者在LFSR的基础上引入非线性函数,从而制造出适用于流加密的伪随机数生成器。
由于其线性结构,LFSR本身并不适合用于流加密。这是因为如果攻击者可以观察到足够的输出位,就可能通过解线性方程来预测之后的输出,这样就破坏了生成器的伪随机性。为了在加密应用中使用,LFSR通常会被结合非线性元素或者与其他LFSR串联使用来增加其输出序列的随机性和不可预测性。
2.2.3 线性递推关系
线性反馈移位寄存器(LFSR)是一个在硬件和软件中广泛使用的结构,用于生成重复模式的序列,这些序列在某些情况下可视为伪随机的。LFSR 利用线性递推关系来产生二进制序列。
在数学上,这个线性递推关系可以表示为:
其中:
是在时间步
产生的位。
是反馈抽头的数量,它决定了递推关系的“记忆”长度。
是反馈抽头的系数,决定了对应位置的位如何影响反馈。
在这种结构中,每个新位的值是由前 个位按照一定规则进行线性组合得到的。这个规则是通过选择特定的位(即抽头)并将它们进行XOR运算来实现的。
在这个例子中,表示使用三个反馈抽头,且系数
意味着第一个和第三个位将会被用来计算新的位,而第二个位则不会被使用。
对于LFSR,如果抽头系数被恰当选择,那么寄存器状态
将会周期性地遍历
个可能的非零状态,因为状态“全零”是一个陷阱状态(一旦进入这个状态,寄存器就会永远保持零)。这意味着序列
将会有一个周期
,如果
是LFSR的位数。这样的序列在密码学和通信系统中非常有用,但它们由于线性的性质而不适用于所有类型的加密需求,因为它们相对较容易被预测和攻击。因此,它们经常被用作随机数生成的一个部分,或者通过某种方式被改进以增加非线性,以便用于加密。
2.2.4 通过线性递归关系生成二进制序列
是的,LFSR(线性反馈移位寄存器)通过线性递归关系生成二进制序列。在给定的例子中,对于所有的,有:
其中m = 3,抽头系数。这意味着每个新的位
是通过取特定的前几个位(在这个例子中是
和
)的XOR来生成的。
由于LFSR的线性特性,可以使用Berlekamp-Massey算法来分析输出序列,并且仅需LFSR序列的一个周期就能计算出LFSR的初始状态和抽头系数。这种算法非常有效,因为它只需要一个与LFSR状态位数相同长度的输出序列。
LFSR由于其线性特性,如果直接用于加密,那么在已知明文和密文的情况下,可以使用Berlekamp-Massey算法恢复出密钥流。这意味着LFSR序列可以被预测,因此,它本身并不适合直接用于加密应用。在密码学中,通常需要在LFSR的基础上增加额外的非线性复杂性,或者将它与其他算法结合使用来增强其安全性,以抵御这种类型的已知明文攻击。
2.3 同步与异步流加密
流加密有两种类型:同步和异步。
2.3.1 同步流加密
在同步流加密中,加密数据流与密钥流是独立的,加密过程的安全性高度依赖于伪随机数生成器(GPA)产生密钥流的质量。以下是同步流加密初始化和加密过程的解释:
2.3.1.1 同步流加密的初始化
在同步流加密中,伪随机数生成器(GPA)的初始状态是由密钥`k`和一个初始化向量`IV`共同决定的。这个过程可以用以下方式表示:
其中,`q0`是GPA的初始状态,k是保持不变的会话密钥,IV是初始化向量,通常是公开传输的,它可以频繁变化,比如每次通信或每个数据包都不同,以保证即使密钥不变,每次加密的输出也应该不同,从而提供更高的安全性。
2.3.1.2 同步流加密
在同步流加密中,GPA的状态仅依赖于其内部状态,而与明文信息无关。状态的转换由状态转换函数Φ定义:
qt = Φ(qt−1)
并且输出函数`f`定义了在任何给定时刻`t`的输出`zt`:
zt = f(qt)
在同步流加密中,明文不会直接影响密钥流的生成。而是,明文会与GPA生成的密钥流同步进行XOR操作以产生密文。同步流加密的一个重要属性是,如果密钥流未泄露,且IV每次都是唯一的,那么即使攻击者知道部分明文,也无法推断出剩余的明文或者密钥流。这是因为同步流加密中密钥流的生成完全独立于明文信息。
因此,在同步流加密中,如果发送者和接收者的GPA的状态能够保持同步,那么接收者就能够使用相同的密钥流解密密文,恢复出原始的明文信息。这种方法的安全性在很大程度上取决于GPA的质量以及IV的正确使用和管理。
2.3.1.3 同步流加密的工作过程
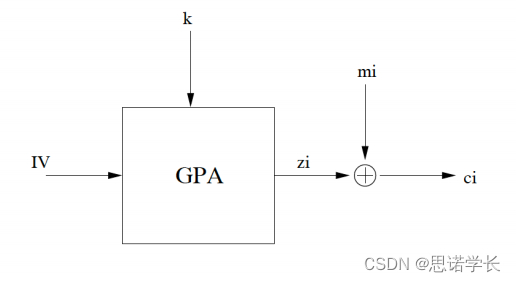
GPA:伪随机数生成器,负责产生密钥流。
k:密钥,作为GPA的一个输入,用来生成密钥流。
IV(初始化向量):另一个输入,通常公开传输,与k一起用于初始化GPA。
zi:在时间i的GPA的输出,即密钥流中的一个元素。
mi:明文消息中的第i个符号或位。
ci:通过将mi和zi进行XOR(表示为⊕符号)操作得到的密文中的第i个符号或位。
加密过程如下:
- 初始化:使用密钥k和IV初始化GPA。
- 生成密钥流:GPA按照其算法产生一个密钥流,其中每个zi是密钥流的一个符号。
- 加密:明文消息的每个符号mi与对应的密钥流符号zi进行XOR操作,产生密文符号ci。
同样地,解密过程也是将密文ci与同样的密钥流zi进行XOR操作,以恢复出明文mi,因为XOR操作是自身的逆运算:
mi = ci ⊕ zi
此图示很好地总结了同步流加密的过程,展示了如何使用密钥和IV生成密钥流,并且如何利用这个密钥流对信息进行加密。这种加密方法的安全性高度依赖于GPA的随机性和不可预测性,以及IV的正确使用,以确保每个加密操作的唯一性。
2.3.2 异步或自同步加密
在流加密中,异步或自同步加密(auto-synchronizing stream cipher)与同步流加密有所不同。在自同步流加密中,伪随机数生成器(GPA)的状态不仅取决于其内部状态,而且还取决于先前的M个密文符号。这样,即使在传输过程中发生数据丢失或错误,接收方的解密过程也能够在接收到足够数量的后续密文字符后自动同步,而无需重新初始化。因此,这种加密方式被称为“自同步”的。
在自同步流加密中,状态转换函数Φ取决于当前状态和M个先前的密文字符:
qt = Φ(qt−1, ct−1, ct−2, ..., ct−M)
这里,qt表示当前状态,ct-1到`ct-M`表示先前的密文字符。
输出函数f仍然负责在任何给定时刻`t`产生输出符号zt`:
zt = f(qt)
这种依赖于前M个密文字符来决定下一状态的设计,允许解密过程在遇到错误时恢复同步。在这种情况下,即使在传输过程中一些密文字符丢失或被篡改,接收方的加密装置仍能在接收到连续M个正确的密文字符后自动恢复到正确的状态。
2.3.2.1 自同步加密的优点与缺点
自同步加密的优点是它能在某种程度上抵抗传输错误,缺点是比同步加密稍微复杂,并且可能导致更高的延迟。此外,因为自同步加密依赖于之前的密文字符,它也更容易受到某些类型重放攻击的影响。因此,设计时需要特别注意抵抗此类攻击。
2.3.2.2 异步(自同步)流加密的工作过程
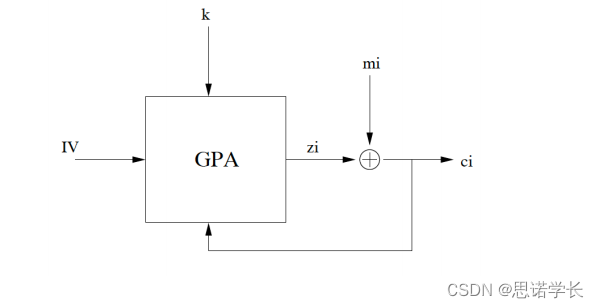
上图展示了一个异步(自同步)流加密的简化模型。在这个模型中,GPA(伪随机数生成器)接收一个密钥`k`和初始化向量`IV`作为输入,生成伪随机输出序列`zi`。这个序列与明文消息`mi`进行异或(XOR)操作生成密文`ci`。
不同于同步流加密,异步流加密的GPA还会接收先前的密文字符作为反馈,用以更新其内部状态,这一点在图像中的反馈路径所示。
工作过程如下:
- 初始化GPA:使用密钥`k`和初始化向量`IV`来初始化GPA的状态。
- 生成密钥流:GPA使用内部状态和过去的密文字符(数量为M)作为输入来生成下一个状态,并产生一个伪随机输出`zi`。
- 加密消息:输出`zi`通过XOR门与明文消息`mi`进行XOR操作,生成密文`ci`。
- 更新GPA状态: GPA的下一个状态不仅基于当前的内部状态,还基于先前的密文字符(这些字符的数量和M值有关)。这意味着,即便在通信过程中某些密文字符丢失或出错,只要连续M个密文字符保持正确,GPA都能够恢复到正确的状态,从而重新同步。
因此,这种自同步的特性允许加密系统在经历错误或数据丢失后能够自行恢复,无需外部的同步信号或重启整个加密过程。这对于数据传输中可能遇到的错误和干扰有很好的抵抗力,特别是在不稳定的通信环境中。
2.4 安全的随机数生成器(GPACS)
在密码学中,密码学上安全的伪随机数生成器(Cryptographically Secure Pseudo-Random Number Generator,简称 CSPRNG),或者密码学上安全的随机数生成器(GPACS),是至关重要的组件。这类生成器的特点是它们产生的序列看起来是随机的,并且在给定多项式时间资源的情况下,攻击者不能预测序列中的下一个位。更具体地说,即使攻击者知道序列的一部分,也无法以实际有效的方式预测序列的下一位
。
CSPRNGs的设计旨在通过以下属性实现这一目标:
下一个位不可预测性:给定序列的当前状态,下一个输出位不能在多项式时间内被预测,除非有先验知识。
前向安全性:即使攻击者在某一时刻获得了生成器的内部状态,也无法重新构建之前生成的序列。
后向安全性(或后向保密性):即使攻击者在某一时刻获得了生成器的内部状态,如果生成器在此之后更新了内部状态,那么攻击者也无法预测之后生成的序列。
相比之下,LFSR由于其线性特性,不满足这些属性,特别是不可预测性。如你所指出的,LFSR生成的序列可以通过Berlekamp-Massey算法等线性方法在已知足够序列的情况下被有效地预测和重构。因此,尽管它们在一些应用中非常高效,但LFSRs并不是GPACS。在设计加密系统时,通常会选用CSPRNG来生成密钥、初始化向量(IV)、随机数等,确保加密系统的强健性。
2.5 Blum-Blum-Shub(BBS)生成器
Blum-Blum-Shub(BBS)生成器是一个以安全性为核心设计的伪随机数生成器,特别适合于密码学应用。它基于二次剩余的数学难题,特别是模大素数乘积的平方运算的困难性。
这个生成器的工作原理如下:
a. 输入:选择两个大的质数p和q,它们对4取模等于3(即),并令
。选取一个与n互质的种子
(即满足
)。
b. 输出:要产生的伪随机序列的长度位。
c. 初始化:设置。
d. 迭代:对于i从1到k,执行以下操作:
计算。
提取的最低有效位作为序列的第
位,即
。
e. 结果:返回生成的序列。
BBS生成器的安全性基于模的平方取模运算的不可预测性,只要
的选择是安全的(即
和q足够大),那么在不知道p和q的情况下,要预测序列是非常困难的。具体来说,BBS生成器被证明在计算上是安全的,这意味着在多项式时间内预测下一个比特是不可行的。
尽管如此,由于每次只生成一个比特,并且涉及到模大数乘法运算,BBS生成器在速度上非常缓慢,因此在实际中不适合用作流加密的密钥流生成器。目前尚未发现既安全又快速的GPACS,这使得流加密通常依赖于更快的、但可能在理论上不那么安全的伪随机数生成器。在实践中,通常会寻求在安全性和性能之间找到合适的平衡点。
2.6 LFSR的安全性与Geffe生成器
实际上,在对称流加密中确实经常使用线性反馈移位寄存器(LFSR),因为它们可以高效地生成比特序列。但是,如您所指出的,单个LFSR由于其线性特性,容易受到密码分析攻击,如已知明文攻击或伯莱坎普-马西算法攻击。为了增加安全性,会采用几种策略来打破这种线性,增加密码的复杂度和抵抗攻击的能力。
一个常见的方法是将多个LFSR的输出通过非线性布尔函数结合起来。这样做的目的是引入非线性元素,以增加潜在攻击者通过线性方法破解生成器的难度。非线性函数保证了即使攻击者可以观察到输出比特序列,也很难逆推出LFSR的初始状态。
2.6.1 Geffe生成器
Geffe生成器是一个使用三个LFSR和一个特定的非线性函数来结合它们的输出的例子。Geffe生成器的输出不是简单地将三个LFSR的输出做XOR操作,而是使用一个更复杂的非线性函数来混合它们,使得分析变得更加困难。
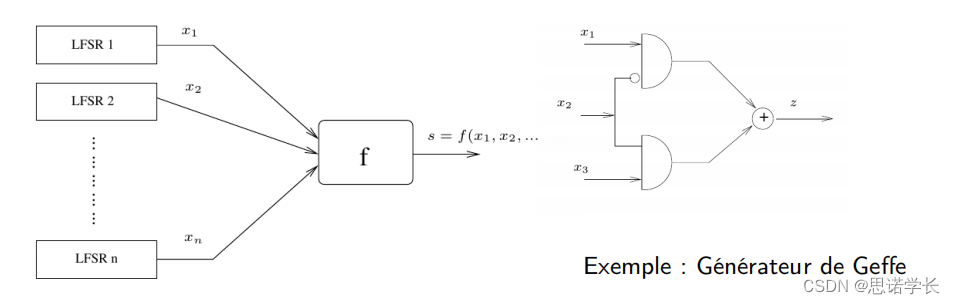
图中展示的是Geffe生成器的结构示意图。Geffe生成器是一个将多个线性反馈移位寄存器(LFSR)的输出通过一个非线性布尔函数组合起来,以生成一个伪随机数序列的机制。它由以下几部分组成:
多个LFSR:图示中的LFSR 1, LFSR 2, ..., LFSR n代表了n个不同的线性反馈移位寄存器,每个寄存器产生一个序列。
非线性布尔函数f:这个函数将所有LFSR的输出作为输入,并产生一个单一的输出序列。这个函数设计得复杂且非线性,目的是使得整个系统的输出序列难以预测。
输出序列:函数的输出s代表了伪随机数序列,它由函数f根据输入的值计算得出。
2.6.2 非线性布尔函数
在示意图的右侧,提供了Geffe生成器具体的非线性布尔函数的一个例子。这个函数包括三个输入和一个输出z,其中输出z是通过某种特定方式组合这三个输入的结果。
总体来说,通过这种方式,Geffe生成器能够抵抗基于LFSR线性特性的攻击。然而,它也可能受到相关性攻击的影响,因为即使是非线性组合,也可能存在某些统计学上的相关性,这可以被特定的分析技术所利用。尽管存在这些潜在的安全风险,Geffe生成器及类似机制的设计为密码学提供了一个在LFSR基础上增加安全性的有效方式。
2.6.3 安全性
尽管通过非线性函数结合多个LFSR可以提高系统的安全性,但这种方法仍然可能受到其他类型的分析攻击,如相关性攻击。在相关性攻击中,攻击者会试图找到不同LFSR之间的统计相关性,然后利用这些信息来破解整个系统。
由于这些潜在的安全隐患,设计流密码系统时需要非常小心,需要在实用性、效率和安全性之间做出权衡。因此,除了使用非线性函数之外,现代的流加密算法也会采用各种其他技术来提高安全性,如状态增强、不规则钟控制和复杂的输出转换等。此外,密码学家会对已知的攻击方法进行充分的评估,以确保所设计的系统能够抵抗这些攻击。
2.7 流加密标准
流加密标准在许多通信技术中都有应用,它们是保障数据传输安全性的重要组成部分。你提到的几个标准如下:
2.7.1 A5/1, A5/2, A5/3
这些是用于GSM(全球移动通信系统)网络的加密算法。A5/1被认为是比A5/2更安全的算法,主要用于欧洲和美国。A5/2提供较低的安全性,主要用于其他地区。A5/3是较新的加密标准,提供更高的安全性。
A5/1是一种同步流加密算法,最初设计用于在大多数欧洲国家的GSM(全球移动通信系统)网络中对电话通话进行加密。这个算法的确切细节一开始是保密的,但后来被逆向工程学家分析并公布了。
2.7.1.1 A5/1加密算法的基本结构
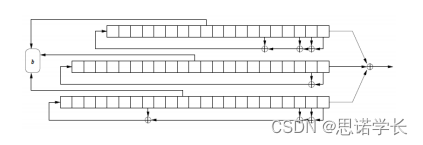
A5/1使用了三个不同长度的线性反馈移位寄存器(LFSR),长度分别为19、22和23位。
这些LFSR会被一个64位的秘密密钥和一个22位的公开的帧数(也称为帧标识符或初始化向量)初始化。
密钥流是通过复杂的机制,如控制多个LFSR之间的时钟,以及通过非线性函数组合它们的输出来生成的。
A5/1设计之初被认为是安全的,但随着计算能力的提高和密码分析方法的进步,它现在被认为是不安全的。实际上,已经有多种实用的攻击方法被发现,可以在短时间内破解A5/1加密,这使得它对现代标准来说太弱,无法提供足够的安全性。
由于这些安全问题,GSM网络后来采用了更安全的算法A5/3,它使用了KASUMI块加密作为其核心。KASUMI是为移动通信设计的加密算法,它比A5/1提供了更高的安全性。然而,即使是A5/3,随着时间的推移,也已经有报告显示它可能存在弱点。
在选择和使用加密技术时,随着密码分析技术的不断发展,我们必须接受加密算法可能会变得不再安全的事实。这就是为什么持续的研究和更新加密算法是保护信息安全的一个关键部分。
2.7.1.2 E0
这是用于蓝牙设备之间的通信加密的流密码算法。E0用于保护蓝牙连接的隐私和安全性。
E0是蓝牙技术中用于加密通信的流加密算法。它采用可变长度的密钥,通常是128位。E0算法的结构包括4个不同长度的线性反馈移位寄存器(LFSR),分别是25位、31位、33位和39位,以及一个2位的内部状态。
E0算法的工作流程如下:
- 初始化:LFSRs和内部状态用预共享的密钥和一些公开参数(比如设备地址和初始计数器)进行初始化。
- 时钟管理:在每个时钟周期,所有LFSRs都会根据它们的反馈函数移位。LFSR的设计确保了输出序列具有良好的统计特性,并尽可能接近随机。
- 内部状态变换:内部状态的更新依赖于它的前两个值以及LFSRs的状态。这个内部状态为LFSRs提供额外的非线性,以提高安全性。
- 输出生成:算法的输出是通过将四个LFSRs的输出和内部状态的一个位进行异或(XOR)运算产生的。这个输出是加密的密钥流。
- 密钥流与明文的结合:最后,这个密钥流与明文进行异或运算,生成密文。在接收端,同样的操作(使用相同的密钥流进行异或运算)将密文转换回明文。
尽管E0算法包含了一些设计来增加安全性的特性,例如使用多个LFSRs和非线性内部状态,但研究人员已经发现了多种攻击方法。这些攻击揭示了E0的一些脆弱性,特别是在某些实现中,密钥管理和密钥更新策略存在缺陷,导致安全性降低。结果是,现代的蓝牙设备通常采用更新的加密方法来提供更高的安全性。
2.7.1.3 RC4
这是一种广泛使用的流密码,最著名的应用是在WEP(有线等效加密)中,它是早期WiFi网络的安全协议的一部分。然而,RC4在实践中已经显示出多种弱点,尤其是在WEP中的实现方式使其容易受到攻击。
不幸的是,上述所有算法都已经在某些情况下被证实是可以被破解的。对于A5/1和A5/2,已经发现了多种攻击方法,可以在实际操作中突破其安全性。对于E0,也发现了若干弱点。而RC4由于一系列已知的漏洞,比如在WEP协议中的应用,被认为是不安全的。
除了这些标准之外,还有其他非标准化的流加密候选算法,如Trivium,它在eSTREAM项目的密码竞赛中被提交。Trivium被设计为高效且安全的流密码,虽然它没有成为正式的加密标准,但是它被广泛认为是一个强大和实用的算法,特别是在需要高性能和低资源消耗的加密应用中。
标准化的流程是一个复杂的行业和政治过程,而不完全是基于技术优越性。有些算法即便在技术上优秀,也可能因为各种原因(如专利问题、商业竞争、政治问题)没有被标准化。因此,一个流加密算法是否被标准化并不直接决定其质量的高低。在选择加密算法时,应该综合考虑安全性、性能、兼容性和实现的复杂性。
2.8 流加密的应用场景
流加密(Stream Ciphers)是密码学中的一个重要分支,它与块加密(Block Ciphers)并行,各有特点和应用场景。流加密的主要特点是它在加密数据时可以处理一个比特(或字节)流,而不需要像块加密那样处理一个固定大小的数据块。这使得流加密在某些实时或者硬件资源受限的环境中非常有用。
Adi Shamir的2004年在AsiaCrypt会议上的演讲提到,在过去的三十年里,流加密的重要性有所下降,它们变得越来越不常用,但这并不意味着流加密已经“死亡”。尽管存在许多针对流加密的攻击,流加密的研究和开发仍然活跃。流加密在特定的应用场合下仍有需求,比如在需要非常高效率加密或者具有严格延迟要求的通信中,流加密因为其较低的处理延迟仍然是首选。
尽管块加密因其结构的安全性和多样性在许多应用中成为了首选,但流加密在以下情况下仍然很有用:
- 性能要求:在某些应用中,尤其是在资源受限的设备上(如RFID标签、智能卡等),流加密算法因为其计算上的高效性而受到青睐。
- 实时通信:在一些需要实时或近乎实时加密的场景(如视频会议或直播)中,流加密算法由于其可以逐比特或逐字节处理数据的能力,因而是一个很好的选择。
- 硬件实现:流加密算法通常更容易转换为高效的硬件实现,这在需要低能耗和高性能的加密硬件中非常有价值。
现代的流加密算法,如ChaCha20和Salsa20,以及eSTREAM项目中的一些算法,例如SOSEMANUK、HC-128等,都表明了流加密算法的进步和它们在现代加密系统中的有效性。
总之,流加密并非“死亡”,而是在特定的场景和需求下依然“活着”。它们与块加密算法一起,作为现代密码学的重要组成部分,继续演化和发展。
3. 块加密
块加密是对称加密的一种形式,它涉及将明文消息分割成固定大小的块,并对每个块使用相同的加密算法进行加密。这种加密方法与流加密不同,后者将输入视为一个连续的比特流。
3.1 块加密的总体介绍
3.1.1 块加密的过程
a. 分割明文:明文消息 m 被分割成`n`位的块,表示为`m1, m2, ..., ml`。如果消息的长度不是`n`的倍数,则需要添加填充(padding),以使最后一个块的大小等于`n`位。
b. 填充(Padding):常见的填充技术包括PKCS#7、ANSI X.923、ISO/IEC 7816-4以及零填充(Zero padding)。RFC 2040提出了与使用RC5算法相关的填充方案。填充确保所有的数据块大小都是一致的,这对于块加密算法的正确执行是必需的。
c. 加密每个块:每个数据块使用相同的加密密钥进行独立加密,通常使用复杂的变换,如替换、置换、混合列和行等操作。
3.1.2 块加密的模式(Modes of Operation)
为了提高安全性和灵活性,块加密可以以不同的模式操作,其中包括:
3.1.2.1 ECB(电子密码本)模式
ECB(电子密码本模式)是块加密算法的一种模式,它将明文分割成多个块,然后独立地加密每个块。这是最简单的加密模式,明文块独立加密。它的一个主要弱点是同样的明文块会产生同样的密文块,这可能会泄露信息。
3.1.2.1.1 加密过程
对于每个明文块`mi`:1. 使用加密函数 E 和密钥 k 对明文块进行加密:。2. 输出加密块
。
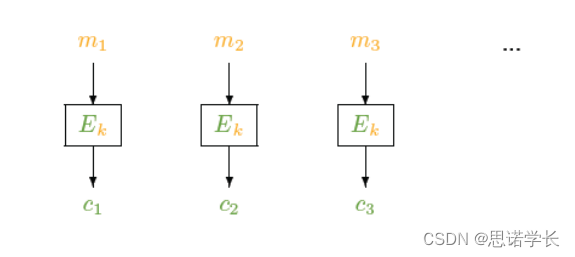
3.1.2.1.2 解密过程
对于每个密文块ci:1. 使用解密函数`D`和同样的密钥`k`对密文块进行解密:。2. 输出明文块`mi`。
ECB模式的主要优点是简单性和并行处理能力 —— 因为它不依赖于前一个块的加密结果,所以可以同时加密多个块。然而,正是因为这种独立性,ECB模式也有一个重大的安全弱点。
3.1.2.1.3 安全弱点
可预测性:在ECB模式中,相同的明文块将总是被加密成相同的密文块。这意味着模式(比如图片的像素布局、文本中的重复)可以在密文中被保留下来,这可能会泄露关于原始数据的信息。
不安全性:如果攻击者能够控制明文,并且能够观察密文的变化,他们可能能够推断出密钥或明文的某些信息。
由于这些问题,ECB模式通常不推荐用于需要高安全性的应用。在实际应用中,更倾向于使用其他模式,如CBC、CFB、OFB或CTR,因为这些模式通过将前一个块的输出以某种方式与当前块结合,解决了ECB模式的可预测性问题。
3.1.2.2 CBC(密码块链接模式)
CBC(Cipher Block Chaining,密码块链接)模式和OFB(Output Feedback,输出反馈)模式是块加密算法的两种运行模式,旨在解决ECB模式中存在的一些问题,特别是重复块问题。
加密前每个明文块与前一个密文块进行异或操作。这个模式使用一个初始化向量(IV)来加密第一个明文块。CBC模式通过将前一个密文块的输出与当前的明文块混合,确保即使两个明文块相同,它们的密文表示也会不同。
3.1.2.2.1 加密过程(CBC)
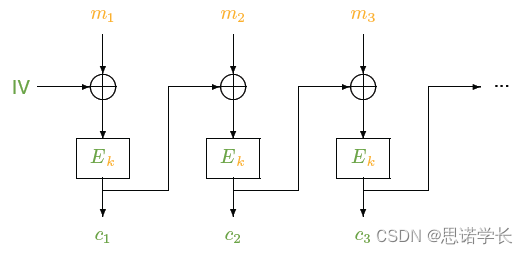
1. 选择一个随机的初始化向量(IV)。
2. 对于第一个明文块`m1`,将它与IV进行异或(XOR)操作,然后加密:c1 = E_k(m1 ⊕ IV)。
3. 对于随后的每个明文块`mi`,将它与前一个密文块`ci-1`进行XOR操作,然后加密:`ci = E_k(mi ⊕ ci-1)。
4. 加密后的IV和所有密文块`ci`被一起传输。
3.1.2.2.2 解密过程(CBC)
1. 对于第一个密文块c1,解密然后与IV进行XOR操作以恢复明文:m1 = D_k(c1) ⊕ IV。
2. 对于随后的每个密文块`ci`,解密然后与前一个密文块`ci-1`进行XOR操作以恢复明文:`mi = D_k(ci) ⊕ ci-1`。
3.1.2.2.3 安全性考量
CBC模式:需要确保IV是随机的,并且每次加密都是唯一的,以保证加密的安全性。如果IV泄露,第一个块的明文可能会被暴露。
3.1.2.3 OFB(输出反馈模式)
类似于CFB,但它生成密钥流,这个密钥流与明文异或生成密文。密钥流的生成与明文无关。
OFB模式将块加密转换为一种流加密形式。通过使用加密算法的输出作为下一个加密操作的输入,它生成一个密钥流,然后将这个密钥流与明文进行XOR操作来加密数据。
3.1.2.3.1 加密过程(OFB)
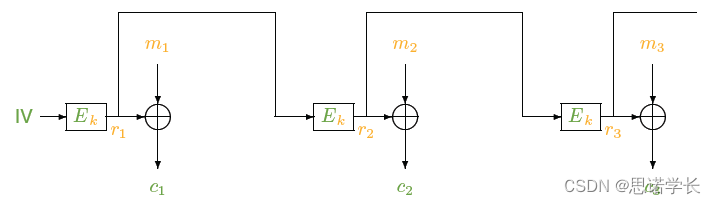
1. 选择一个随机的IV作为第一个反馈值r0。
2. 对每个时钟周期`i`,计算。注意这里`ri`的值仅取决于IV和密钥,与明文无关。
3. 生成密文块`ci`,通过将`ri`与对应的明文块`mi`进行XOR操作:ci = ri ⊕ mi`。
3.1.2.3.2 解密过程(OFB)
1. 解密过程与加密过程相同。使用相同的密钥和IV,生成相同的密钥流。
2. 接收方计算`mi = ri ⊕ ci`来恢复明文。
3.1.2.3.3 安全性考量
OFB模式:由于生成的是密钥流,因此它对密钥和IV的选择非常敏感。如果IV和密钥组合重用,会导致安全性下降,因为重复的密钥流可以被利用来还原明文。
总体而言,这些模式增加了加密操作的复杂性,并解决了ECB模式中相同明文块产生相同密文块的问题。这两种模式都比ECB更安全,因为它们能够隐藏明文数据中的模式。然而,它们的实现需要注意保护IV的安全性,以及在OFB模式中保持密钥流的唯一性。
3.1.2.4 CFB(密码反馈模式)
将块加密转换为自同步的流加密,明文通过与上一块加密后的输出进行异或来加密。
3.1.2.5 CTR(计数器模式)
加密一个递增的计数器和固定的密钥,生成一个密钥流,然后将该密钥流与明文异或得到密文。这种模式将块加密转换为流加密。
CTR模式(计数器模式)是块加密算法的一种运行模式,这种模式通过将加密算法转化为一种流密码系统,它具有相对于其他模式的某些优势,比如简单的并行计算和不需要填充(padding)。
CTR模式的核心思想是加密一个递增的计数器而不是直接加密明文,然后将产生的密钥流与明文进行异或操作来产生密文。这个模式既可以用于加密也可以用于解密,因为它们操作完全相同。
3.1.2.5.1 加密过程(CTR)
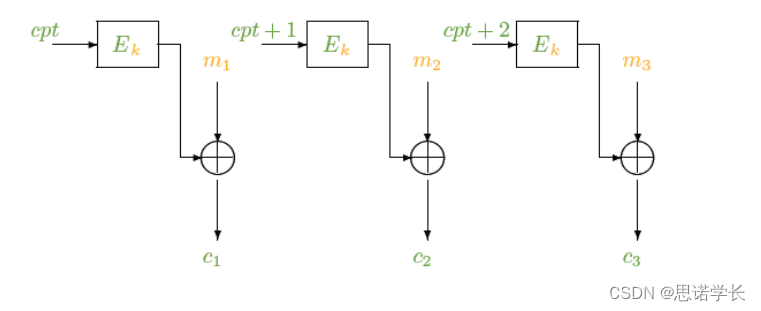
a. 选择一个初始的计数器值`cpt`(通常与一个随机的初始化向量IV一起使用)。
b. 对于每个明文块`mi`,计算`ri = E_k(cpt + i − 1)`。这里,`E_k`是加密函数,`k`是密钥,`i`是块的序号。
c. 生成密文块`ci`,通过将密钥流`ri`与明文块`mi`进行XOR操作:`ci = mi ⊕ ri`。
3.1.2.5.2 解密过程(CTR)
解密过程与加密过程相同,因为XOR操作是自反的(即`a ⊕ b ⊕ b = a`)。
1. 使用相同的密钥`k`和初始计数器`cpt`来生成相同的密钥流`ri`。
2. 将密文块`ci`与密钥流`ri`进行XOR操作,恢复明文块`mi`:`mi = ci ⊕ ri`。
3.1.2.5.3 安全性考量
唯一性:计数器必须对于每个加密消息是唯一的,这通常通过在计数器中包含IV来实现。如果重用计数器和密钥的组合,会导致安全性严重下降。
不可预测性:计数器虽然递增,但整个计数器值(包括IV)不应是可预测的,以免泄露信息。
CTR模式的优势在于它的灵活性和效率,尤其是在需要并行加密或解密操作的场合,因为每个块的加密是独立的。此外,CTR模式不会扩展消息的长度,因为它不需要填充到块的整数倍。这在需要密文和明文大小相同的应用中非常有用,如某些网络协议和硬盘加密。
这些模式设计的目的是为了防止模式分析攻击,并确保加密是安全的,即使是在处理具有重复模式的数据时。它们提供了不同的性能和安全特性,使得块加密在各种应用场景中都能找到合适的应用。
3.2 迭代结构
块加密通常采用迭代结构,这意味着它将一系列固定步骤(称为“轮”或“回合”)重复应用于明文块。在每一轮中,会使用一个从原始密钥派生出来的轮密钥(子密钥)来进行特定的加密操作。迭代过程增强了加密算法的安全性,因为它使得对加密过程的逆向工程变得极其困难。
3.2.1 迭代加密的基本流程

密钥扩展:原始密钥 k 通过密钥扩展算法生成一系列轮密钥。每一轮使用不同的轮密钥,以提供加密的多样性。
初始化:明文块m准备进行加密。
迭代加密:明文块m经过`r`轮变换,每一轮包括:
轮函数F:对数据进行加密处理,如置换、替换、混淆和扩展等操作。
轮密钥结合:每次迭代将轮函数的结果与一个轮密钥结合(通常是XOR操作)。
输出密文:经过`r`轮处理后,最终输出密文块`c`。
3.2.3 迭代加密的典型例子
迭代结构的一个典型例子是AES(高级加密标准),它采用一种称为SP网络的特殊迭代结构。SP网络在每一轮中进行替代(Substitution)和置换(Permutation),这是为了达到混淆(Confusion)和扩散(Diffusion)的目的——混淆是为了使攻击者难以理解密钥和密文之间的关系,扩散是为了将明文的单个位的影响散布到整个密文中。
在设计块加密算法时,轮数`r`通常会根据所需的安全性和效率来选择。轮数越多,算法越安全,但同时也可能会更慢。轮函数的设计也是保障加密强度的关键因素。轮数、轮函数和密钥扩展算法的设计必须共同协作,以抵抗各种密码分析技术,包括差分分析和线性分析。
3.3 DES
DES(Data Encryption Standard,数据加密标准)是一种曾广泛使用的对称密钥加密算法。1977年由美国国家标准局(现为国家标准与技术研究所NIST)正式采纳为标准,它的设计基于IBM的先前算法Lucifer,并在Horst Feistel等人的主导下进行了改进。
DES的设计初衷是为了提供一种可以在各种硬件和软件中实施的加密方法,直到21世纪初,它都是保护电子信息安全的重要工具。
DES(Data Encryption Standard,数据加密标准)是一种基于Feistel网络结构的块加密算法。Feistel结构是一种将块加密的输入分为两半,并通过交叉处理这两半来进行加密的方法。DES的设计旨在通过一系列复杂的操作确保高度的数据安全性。
3.3.1 历史背景和设计特点
设计与批准:DES在1977年被批准为标准,成为公共和私营部门广泛使用的加密技术。
设计者:IBM公司,主要设计者是Horst Feistel,算法是基于他的Feistel网络结构。
使用时长:从1977年到2000年初,DES被广泛用于商业、工业和金融行业的信息安全保护,但由于它的密钥长度较短(56位),在数据安全要求日益增高的背景下,它的安全性逐渐被质疑。
3.3.2 DES的主要特点
块大小:DES以64位(8字节)为一个块进行加密和解密操作。
密钥长度:虽然DES使用的密钥长度为64位,但实际上只有56位用于加密过程,剩下的8位用作奇偶校验位,以检测密钥在传输或存储时是否发生错误。
轮数:DES执行16轮迭代加密。每一轮都使用不同的轮密钥对数据进行处理,这些轮密钥是从原始的64位密钥中派生出的48位密钥。
密钥派生:DES密钥派生使用了一个称为密钥调度的算法,从64位的主密钥中生成16个48位的轮密钥。这一过程包括密钥压缩和移位操作,以生成每一轮所需的密钥。
3.3.3 Feistel结构的加密流程
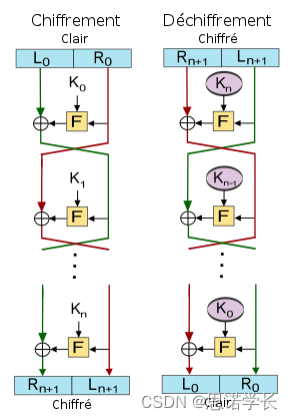
初始置换(IP):在加密的第一步中,对输入的64位数据块进行一个初始置换操作。
16轮迭代:每一轮都包括分裂、混合和置换步骤。具体来说,每一轮都将数据块分为左半部(L)和右半部(R),然后对右半部进行一系列操作(如扩展、与轮密钥结合、替换和压缩),其结果与左半部进行XOR操作。然后,左半部和右半部交换位置进行下一轮操作。在最后一轮后,L和R不进行交换。
逆初始置换(FP):在16轮迭代后,将最后的输出(L和R合并)通过逆初始置换(即初始置换的逆操作)生成最终的密文块。
DES虽然在设计之初被认为是非常安全的,但随着计算能力的提升和密码分析技术的进步,其56位的有效密钥长度逐渐不足以抵抗暴力攻击。这导致了3DES(Triple DES)和后来的AES(Advanced Encryption Standard)的开发,以提供更强的安全性。
3.3.4 安全性
3.3.4.1 安全性和演变
DES自从1977年成为标准以来,一直是密码学和信息安全领域研究的重点。尽管它的设计考虑了当时已知的攻击方法,但随着时间的推移,密码分析学者发展出了更高级的技术来挑战DES的安全性。其中最著名的两种攻击技术是线性密码分析和差分密码分析。
随着计算能力的提高,DES的56位密钥长度成为其安全性的短板。到了1990年代末,通过暴力攻击已经能够在实际时间内破解DES加密,这导致了对DES安全性的重新评估和寻找替代方案的需求。
作为响应,AES(高级加密标准)在2001年被选为DES的后继标准,提供更高的安全性和更长的密钥长度(128位、192位和256位)。同时,为了过渡期间的需要,3DES(或称Triple DES)作为一种临时解决方案,通过连续三次应用DES算法(使用三个不同的密钥)来增加加密的强度。
尽管DES已不再被认为是安全的加密标准,它在密码学和信息安全领域的历史上仍占有重要地位,对后续的加密算法设计产生了深远影响。
3.3.4.2 线性密码分析
发明者:由Mitsuru Matsui于1993年发明,目的是攻击DES。
原理:线性密码分析是基于找到加密算法中的线性近似式,这些近似式以一定的概率描述了输入位、输出位和密钥位之间的线性关系。通过分析大量的明文和对应的密文,攻击者试图利用这些线性关系推断出密钥。
针对DES:DES中的某些S盒因为存在线性关系,所以对线性密码分析比较脆弱。通过足够多的明文-密文对,可以以非常低于穷举搜索的计算量推断出密钥。
3.3.4.3 差分密码分析
发明者:由Eli Biham和Adi Shamir在1990年发表,他们提出了一种针对DES及类似加密算法的差分密码分析方法。
原理:差分密码分析关注两个略有差异的输入在加密过程中产生的输出差异。通过观察特定输入差异导致的输出差异,攻击者可以收集有关密钥信息的线索。
效果:与线性密码分析类似,通过分析大量的明文-密文对,差分密码分析试图降低破解DES的复杂度,使得某些密钥比其他密钥更有可能。
这两种分析技术的提出,明确表明了DES在面对有能力收集和分析大量数据的攻击者时的脆弱性。尽管这些攻击通常需要大量的数据和相对高的计算资源,它们展示了DES密钥空间(56位)不足以抵抗现代的密码分析技术。
差分密码分析和线性密码分析的发展不仅标志着对DES安全性的重大突破,也推动了密码学研究的进步,促进了更安全加密算法(如AES)的发展。这些分析方法如今被广泛应用于对现代加密算法的安全性评估中。
3.3.4.4 总结
DES(数据加密标准)在其设计之初是一个非常先进的加密算法,提供了相当高的安全性。然而,随着计算技术的快速发展,尤其是计算能力的显著提升,DES的安全性逐渐被削弱。
1998年,电子前哨基金会(Electronic Frontier Foundation,EFF)展示了通过硬件攻击DES的可能性。他们构建了一台专用的机器,名为“DES Cracker”,成本为25万美元。这台机器能够通过暴力攻击,在4天内完成对一个DES密钥的穷举搜索,并成功破解了DES加密。这一成就标志着DES在面对有足够资源的攻击者时,其56位密钥长度已不足以提供必要的安全保障。
此外,随着线性密码分析和差分密码分析等先进密码分析技术的出现,DES的理论安全性也受到了挑战。这些技术可以以远低于穷举搜索的成本来破解DES,进一步凸显了其密钥长度的局限性。
鉴于DES的这些安全缺陷,以及公众对更高数据安全标准的需求,美国国家标准与技术研究所(NIST)发起了一项寻找DES替代品的公开竞赛。这一过程最终选出了高级加密标准(AES),它提供了更长的密钥长度(128位、192位和256位)和更高的安全性。从2001年开始,AES逐渐取代了DES,成为新的加密标准。
尽管DES不再被视为安全的加密算法,但它在密码学历史上的地位仍然十分重要。DES不仅促进了加密技术的发展,还引发了对公共加密标准安全性的广泛讨论,对后续加密标准的制定产生了深远影响。
3.3.5 3-DES(或Triple DES)
3-DES(或Triple DES)是一种改进的DES版本,旨在通过多次应用DES加密过程来增加加密的强度。尽管DES本身因为其56位密钥长度而不再被认为是安全的,3-DES提供了一种有效的方法来延长DES算法的使用寿命,同时提高安全性。3-DES已经被广泛用于需要高安全性的场合,直到更高级的加密算法(如AES)成为新的标准。
3.3.5.1 3-DES的工作原理
3-DES使用两种主要方式进行加密:
EDE模式(Encrypt-Decrypt-Encrypt):使用三个密钥(K1、K2、K3)对数据块进行三次连续的DES操作。首先用K1加密,然后用K2解密(实际上是另一次加密操作,因为DES的解密过程只是加密过程的反向而已),最后用K3再次加密。这种模式也可以用两个密钥(K1、K2),其中第一次和最后一次加密使用同一个密钥(K1=K3)。
EEE模式(Encrypt-Encrypt-Encrypt):所有三步都是加密操作,分别使用三个不同的密钥。这种方式相对不太常用。
3.3.5.2 安全性提升
通过这种方法,3-DES显著提高了加密的安全性,因为它增加了密钥的有效长度。在使用两个密钥的配置中,有效密钥长度为112位;在使用三个不同密钥的配置中,有效密钥长度为168位。然而,由于每一轮加密实际上都是在执行DES操作,这意味着3-DES的加密和解密过程需要更多的计算时间,这使得它在性能上比单次DES慢得多,也比新的加密标准如AES慢。
3.3.5.3 应用和转移
尽管3-DES提供了比DES更高的安全性,但它在计算效率上的劣势导致了对更高效加密算法的需求。AES的出现满足了这一需求,提供了更高的安全性以及更好的性能。随着AES成为新的行业标准,3-DES的使用开始逐渐减少。然而,在过渡期间,3-DES作为一种更安全的替代方案,在很多系统中仍然保持着重要的地位,特别是在那些需要与旧系统兼容的场合。
3.4 AES
AES(Advanced Encryption Standard,高级加密标准)是一种广泛使用的对称加密算法,旨在替代老旧的DES算法。1997年,美国国家标准与技术研究所(NIST)发起了寻找DES替代者的公开竞赛,最终选择了由比利时密码学家Joan Daemen和Vincent Rijmen提出的Rijndael算法作为AES。
AES(高级加密标准)是一种广泛使用的对称密钥加密算法,旨在取代DES。它由两位比利时密码学家Joan Daemen和Vincent Rijmen提出的Rijndael算法发展而来,于2001年被美国国家标准与技术研究所(NIST)正式标准化为AES。
3.4.1 AES的主要特点
块长度:AES固定使用128位的数据块大小,这一点与DES的64位数据块不同。较长的块大小提高了加密的安全性和效率。
密钥长度:AES提供三种密钥长度:128位、192位和256位。这比DES的56位密钥和3DES的112位或168位密钥要长得多,提供了更高的安全性。
轮数(迭代次数):AES的迭代次数根据密钥长度的不同而不同。128位密钥使用10轮,192位密钥使用12轮,256位密钥使用14轮。每一轮的操作包括字节替代(SubBytes)、行移位(ShiftRows)、列混淆(MixColumns,最后一轮除外)和轮密钥加(AddRoundKey)。
设计原则:AES的设计强调了安全性、效率、简单性和灵活性。它既适用于硬件实现,也适用于软件实现,无论是在高性能服务器上还是在资源受限的设备上。
3.4.2 AES加密流程的基本步骤
AES(高级加密标准)算法中一个加密轮(round)的过程。AES并不使用Feistel网络,而是采用了一种全块置换-替换(substitution-permutation)结构,也称为SP网络。这里,对整个数据块同时进行替换和置换,增强了安全性。每一轮的主要步骤包括:
a. 初始状态:输入的128位明文块被视为一个4x4的字节矩阵,这是AES处理的“状态(State)”。AES加密中每轮的内部状态`State`是一个4x4的字节矩阵,如下所示:
s00 s01 s02 s03
s10 s11 s12 s13
s20 s21 s22 s23
s30 s31 s32 s33b. 密钥扩展:使用一个密钥扩展算法从原始密钥生成多个轮密钥(Ne + 1个,每个轮密钥为128位)。这一过程称为密钥调度。也是变为一个4x4的字节矩阵
c. 初始轮:初始轮密钥加(AddRoundKey):初始的状态(State,即128位的明文块)与第一个轮密钥进行XOR操作。
c. 中间轮(Ne - 1轮):每一轮包括四个步骤:
字节代替(SubBytes):对状态中的每个字节进行非线性替换,使用一个预定义的查找表(S-box)。每个字节通过一个非线性的S-box进行替换,用于混淆数据。
d.最终轮:最后一轮略有不同,不包括列混淆(MixColumns)步骤。
字节代替(SubBytes)
行移位(ShiftRows)
轮密钥加(AddRoundKey)
输出密文:最后的状态就是加密后的密文。
3.4.3 SUBBYTES
在每个加密轮中,这个`State`会经历几个变换步骤,其中第一步是字节替换,称为SUBBYTES。
3.4.3.1 SUBBYTES(字节替换)步骤详解
S-box的应用:每个字节`sij`在`State`中通过一个S-box进行替换。S-box(替换盒)是一个非线性的替换工具,它根据固定的替换表对字节进行映射。AES中的S-box是一个16x16的表格,其中的每个条目都是一个8位的值。
S-box索引:S-box中的行索引由字节的前4位确定,列索引由字节的后4位确定。这8位合起来表示S-box中一个特定位置的值,该值将替换原始的字节。
代数结构:与DES的看似随机的S-box不同,AES的S-box有明确的代数结构。它可以通过以下步骤得到:
计算字节的逆元素:在有限域`GF(2^8)`中,每个非零元素都有一个逆元素。对于`State`中的每个字节`sij`,都计算其在`GF(2^8)`中的逆元素。
应用仿射变换:计算得到的逆元素再经过一个特定的仿射变换,以获得最终的S-box输出。
3.4.3.2 为什么使用S-box?
S-box的目的是引入非线性,这对抵抗密码分析攻击(如线性和差分密码分析)至关重要。在AES中,这种非线性是通过在有限域`GF(2^8)`上的代数操作实现的。这确保了加密算法不仅仅是一系列线性变换,因此更难以预测和破解。
每次SUBBYTES步骤后,`State`的每个字节都已经根据S-box中定义的规则变换,为接下来的行移位(ShiftRows)和列混淆(MixColumns)步骤做好了准备。
行移位(ShiftRows):对状态中的行进行循环移位。每行的字节进行循环移位,第一行不移位,第二行移位一个位置,以此类推,达到扩散数据的目的。
列混淆(MixColumns):每一列的四个字节通过特定的数学运算进行混合,进一步扩散数据。每一列的四个字节通过特定的数学运算进行混合,进一步扩散数据。左乘一个固定的矩阵。
轮密钥加(AddRoundKey):将转换后的状态与轮密钥进行XOR操作,得到最终状态,即为本轮的输出。
3.4.4 安全性和应用
AES自从2001年被正式采纳为标准以来,已经证明是一种非常安全和高效的加密算法。它抵抗了包括线性密码分析、差分密码分析在内的多种已知密码攻击方法。由于其出色的安全性能和高效率,AES已经成为全球加密通信和数据保护的重要工具。
AES的应用范围非常广泛,包括但不限于互联网安全协议(如SSL/TLS)、无线网络安全(如WPA/WPA2)、文件加密和政府机密通信。它的安全性得到了全球密码学社区的广泛认可,是当今数字安全领域的基石之一。
AES的设计确保了其在多方面的安全性,包括抵抗差分密码分析和线性密码分析等先进的攻击技术。由于其高效的加密性能和强大的安全性,AES已成为全球最重要的加密标准之一,被广泛应用于各种安全通信协议和数据保护方案中。