目录
1.绪论
1.1 研究背景
1.2 研究意义
1.3 文章结构
2. 网络爬虫相关理论
2.1 URL地址格式
2.2 网页爬取策略
2.2.1 深度优先策略
2.2.2 广度优先策略
2.2.3 最佳优先策略
2.3 网页分析算法
2.3.1 正则表达式
2.3.2 DOM解析
2.3.3 Xpath解析
3. 并行网络爬虫的设计
3.1 并行爬虫设计概述
3.2 多线程并行爬虫
3.2.1 设计原理
3.2.2 流程与组件
3.2.3 线程池
3.3 分布式并行爬虫
3.3.1 基本设计思路
3.3.2 实现分布式爬虫的条件
3.3.3 分布式爬虫架构
4. 并行网络爬虫的实现与结果分析
4.1 分布式并行爬虫调研
4.1.1 研究环境配置
4.1.2 爬虫算法评价指标
4.1.3 实验结果及分析
4.2 多线程爬虫测试
4.2.1 实验内容
4.2.2 参数设置
4.2.3 日志输出及可视化
4.3 实验结果及分析
4.3.1 观察并行化下爬取时间变化情况
4.3.2 观察并行化下加速比的变化情况
4.3.3 观察不同线程数、任务数下的爬取时间变化
4.3.4 观察并行化对CPU利用率、内存使用量的影响
4.3.5 观察并行化对爬虫过程网络发送量的影响
五、总结与展望
摘要
随着互联网的快速发展,海量的网络信息日益增长,对这些信息的高效获取和处理成为了研究热点。网络爬虫作为一种自动化的信息收集工具,其性能和效率直接影响到数据获取的速度和质量。然而,传统的单线程爬虫在面对大规模数据时表现出明显的局限性。因此,并行网络爬虫的设计与优化成为了一个重要的研究方向。
本文首先介绍了网络爬虫的基础理论,包括URL地址格式、网页爬取策略以及网页分析算法。在此基础上,本文重点讨论了并行网络爬虫的设计方法,分别从多线程并行爬虫和分布式并行爬虫两个方面进行了详细的阐述。多线程并行爬虫通过在单一机器上利用多线程技术来提升爬取效率,而分布式并行爬虫则通过多机器协同工作来实现大规模数据的高效抓取。
在实现部分,本文对分布式并行爬虫进行了深入调研,并对多线程并行爬虫进行了实际测试。通过实验数据的分析,结果显示并行网络爬虫在数据抓取速度和系统资源利用率方面均表现出显著优势。多线程并行爬虫在适当配置下能够显著提高单机爬取效率,而分布式并行爬虫则在处理更大规模数据时表现出更强的扩展性和稳定性。本文最后总结了研究成果,指出并行网络爬虫在实际应用中的广泛前景,并对未来研究方向进行了展望。
关键词:并行网络爬虫、多线程、分布式、集群、负载均衡
Abstract
With the rapid development of the Internet, the volume of online information is growing exponentially, making efficient information retrieval and processing a research hotspot. As an automated information collection tool, the performance and efficiency of web crawlers directly impact the speed and quality of data acquisition. However, traditional single-threaded crawlers exhibit significant limitations when handling large-scale data. Therefore, the design and optimization of parallel web crawlers have become an important research direction.
This paper first introduces the basic theories of web crawlers, including URL address formats, web crawling strategies, and web page analysis algorithms. On this basis, the paper focuses on the design methods of parallel web crawlers, detailing both multithreaded parallel crawlers and distributed parallel crawlers. Multithreaded parallel crawlers use multithreading technology on a single machine to enhance crawling efficiency, while distributed parallel crawlers achieve efficient large-scale data fetching through the collaboration of multiple machines.
In the implementation section, the paper conducts an in-depth investigation into distributed parallel crawlers and performs practical testing on multithreaded parallel crawlers. Analysis of experimental data shows that parallel web crawlers exhibit significant advantages in data fetching speed and system resource utilization. Multithreaded parallel crawlers can significantly improve single-machine crawling efficiency under appropriate configuration, whereas distributed parallel crawlers demonstrate stronger scalability and stability when handling larger scale data.The paper concludes by summarizing the research findings, highlighting the broad application prospects of parallel web crawlers, and exploring future research directions.
Keywords: parallel web crawler, multithreading, distributed, cluster, load balancing
1.绪论
1.1 研究背景
在现代信息社会中,互联网已经成为人们获取信息和知识的主要渠道之一。随着网络规模的不断扩大和信息量的急剧增长,如何高效地获取和处理海量的网络数据成为了一个重要课题。网页爬虫(Web Crawler)作为一种自动化程序,能够系统地浏览互联网并收集特定的信息,是解决这一问题的有效工具。
传统的单线程爬虫在面对海量数据时,往往表现出效率低下、资源利用率不高等问题。尤其是在处理大规模网络数据和需要快速响应的应用场景中,单线程爬虫的局限性更为明显。为了克服这些瓶颈,并行爬虫应运而生。通过引入并行计算的理念,可以显著提升爬虫的工作效率和数据处理能力。
并行爬虫利用多线程或分布式计算技术,能够同时发起多个请求并处理多个任务,从而大幅提升数据采集速度。同时,并行爬虫还可以充分利用多核处理器和集群计算资源,实现负载均衡和资源优化,提高系统的整体性能[1]。
在大数据时代,快速、全面、准确地获取网络数据对于各类应用具有重要意义。无论是搜索引擎、数据挖掘、信息检索,还是网络监测、市场分析、人工智能训练数据的获取,都离不开高效的爬虫技术。因此,研究并设计高效的并行爬虫具有重要的学术价值和实际应用意义。
1.2 研究意义
随着互联网的快速发展,网络数据量呈指数级增长,传统的单线程爬虫已经难以满足对大规模数据高效处理的需求。并行爬虫作为一种潜在的解决方案,具备以下几点必要性及意义:
(1)提升数据采集效率:并行爬虫能够同时处理多个任务,充分利用系统资源,大幅缩短数据采集时间,提高数据处理效率。
(2)降低系统响应时间:通过并行化处理,能够快速响应用户请求,提供更加即时的数据支持,改善用户体验。
(3)适应大规模网络数据:面对海量网络数据,单线程爬虫往往无法满足实时性和全面性的要求,而并行爬虫可以有效应对大规模数据的处理和管理。
(3)优化资源利用:并行爬虫能够充分利用多核处理器、分布式计算资源等硬件设施,实现资源的有效利用和负载均衡。
1.3 文章结构
本文将围绕并行爬虫的设计与实现展开研究,余下各章节的内容安排如下:
第二章 爬虫相关理论:首先介绍爬虫相关的基本理论,包括URL协议、网页爬取策略以及网页分析算法,为后续并行爬虫设计与实现奠定理论基础。
第三章 并行爬虫的设计:针对现有单线程爬虫的局限性,提出并行爬虫的设计概述,重点探讨多线程并行爬虫和分布式并行爬虫的设计思路和原理。
第四章 并行爬虫的实现与结果分析:详细描述对分布式并行爬虫和多线程爬虫的实现过程,并对实验结果进行深入分析,验证并行爬虫的高效性和可行性。
第五章 总结与展望:最后对本文的研究内容进行总结,并展望未来并行爬虫研究的发展方向和应用前景。
2. 网络爬虫相关理论
2.1 URL地址格式
统计资源定位器是UPL(Uniform Resource Locator)的统称,它代表对网络资源的一个引用(地址),它是因特网的大门,也是因特网上具体资源地址的唯一标识。例如,https://www.bilibili.com/image.gif就标识了一幅存在主机名为www.bilibili.comWeb服务器上的一幅图片。由于爬虫程序是通过网络上遇到的超链接对网络进行访问的,因此在设计爬虫程序时需要解决解析URL地址的问题[2]。
表2-1给出了URL的几个组成部分。URL的通用格式可以解析为两种表达方式:scheme://hostname:port/path?query或scheme://hostname:port/path#anchor。
表2-1:URL的组成
| URL的组成部分 | 作用 |
| Scheme(模式) | URL中指定协议的部分,如http |
| Hostname(主机名) | 真正存储稳定的服务器的名称,可使用域名 |
| Port(端口) | URL可选择指定一个端口。HTTP默认端口为80 |
| Path(路径) | 指定真正向服务器请求的文件路径 |
| Anchor(锚点) | 指定文档中的某个位置,起标注作用 |
2.2 网页爬取策略
在爬虫系统中,待抓取URL队列是很重要的一环。待抓取队列决定了下一步要抓取的URL及被抓取的顺序。而决定这些URL顺序的方法,叫做抓取策略。网页的抓取策略主要包括:深度优先策略、广度优先策略、最佳优先策略。
2.2.1 深度优先策略
互联网链接结构可看成一个巨大的“图”,每个页面可看作图中的一个“节点”。页面中的超链接指向可以看成是图的“有向边”。因此,可以通过遍历图的方式访问互联网上各节点。图的遍历方式通常分为深度优先遍历策略和广度优先遍历策略。
深度优先遍历策略是早期开发爬虫使用较多的方法。其遍历流程是从初始网页开始,若还有以此网页为起点未访问到的路径,则沿此路径继续访问下去;直到达到叶子结点,不能再深入为止。处理完这条路径后,回溯到初始点转入下一起始页。重复上述过程,最终实现所有网页都被访问。
深度优先策略优点是能完整遍历一个网站下的所有网页或深层嵌套的文档集合,缺点是网页链接结构可能会相当深,会使爬虫陷入一个网站内部,导致盲目搜索。
2.2.2 广度优先策略
广度优先遍历思想与树的层序遍历基本相同,是一个分层遍历的过程。基本思想是:从起始网页开始,抽取网页中所有的链接插入待抓取URL队列的队尾。再从待抓取URL队列中取出队头链接,继续抽取在此网页中所有链接并放入队列队尾;重复此过程,逐层抓取。
广度优先策略能实现较高的网页覆盖率,但会导致大量无关网页被下载的情况出现,导致效率较低。因此,不能完全按照广度优先遍历方式进行抓取,可以结合网页过滤技术,过滤掉无关网页;或者给待访问的网页赋予一定优先级,通过优先级决定是否访问及访问顺序。
2.2.3 最佳优先策略
最佳优先策略是一种带偏好的策略,在访问过程中优先把符合偏好条件的网页过滤出来进行抓取。偏好条件可以是主题的相关性,或是与目标网页相似度较高的网页,或者是重要性高的网页(例如,Google采用PageRank算法评价网页权重)。
最佳优先策略是搜索引擎爬虫中常采用的策略存在的问题是:因为最佳优先策略是一种基于局部最优搜索算法的策略,容易陷入局部最优点。即在爬虫抓取过程中,只注重那些满足偏好条件的,导致路径上的很多相关网页可能被忽略。该策略在具体应用时,需结合具体情况改进。采用最佳优先策略的爬虫称为聚焦爬虫或主题爬虫[3]。
2.3 网页分析算法
在爬虫抓取网页后,需要对网页内容进行分析和提取,以便获取有用的信息。常见的网页分析算法有正则表达式、DOM解析和Xpath解析等,它们常用来解析网页的HTML代码,提取其中的文本内容和链接信息。
2.3.1 正则表达式
正则表达式(Regular Expressions)是一种通过定义特定字符序列来查找、替换或提取字符串中子串的文本模式匹配工具。在网页爬虫中,正则表达式常用于从HTML内容中提取特定信息,如链接、电子邮件地址或特定格式的数据。它基于一组规则(正则语法)来描述字符集和字符序列的模式,并使用各种元字符(如.、*、+、?、[]等)构建复杂的匹配模式来识别和处理文本中的特定部分。
正则表达式具有灵活且强大的优点,能够精确匹配复杂的文本模式,适用于快速处理简单且结构不复杂的文本数据。然而,对于嵌套结构或动态生成的复杂网页,正则表达式的编写和维护会变得困难。
2.3.2 DOM解析
DOM解析是一种将HTML文档解析为树形结构的技术,通过该树形结构(DOM树)可以访问和操作网页中的元素。DOM解析器会将HTML文档的各个部分(如标签、属性、文本)转化为节点,从而可以进行遍历和操作。DOM解析器读取HTML文档,并根据其结构创建一个DOM树,其中每个节点代表文档的一部分(如元素、属性、文本)。开发者可以通过编程接口(API)来遍历这棵树、访问特定节点、修改节点内容或结构,实现信息提取或页面操作[4]。
DOM解析能够精确定位网页中的元素,适用于结构清晰、规范的HTML文档,并提供全面的API进行详细操作和修改,特别适用于需要深入分析和操作网页的场景。然而,对于结构复杂或动态生成的网页,DOM解析可能较为困难且解析整个文档的开销较大。此外,处理实时动态内容(如通过JavaScript生成的内容)通常需要额外的处理手段。
2.3.3 Xpath解析
XPath是一种在XML文档中查找信息的语言,也适用于HTML文档。通过路径表达式选择节点,XPath允许开发者高效地定位和提取文档中的特定部分。其表达式使用路径语法来导航文档树,从根节点开始,通过指定路径和条件来选择目标节点。例如,表达式//div[@class='content']可以选择所有类名为“content”的<div>元素。XPath因其广泛的查询功能,在网页爬虫和XML数据处理等领域得到了广泛应用。
XPath具备显著的优缺点。其优点在于语法简洁且功能强大,能够高效地定位和提取网页内容,特别适用于从复杂的DOM结构中精确提取数据的任务。此外,与纯正则表达式相比,XPath更适合处理结构化数据。然而,编写XPath表达式需要对网页的DOM结构有深入了解,并且XPath的学习曲线稍陡峭,要求使用者具备一定的经验和技巧。对于高度动态的网页,XPath同样可能遇到挑战,需要结合其它技术手段一起使用。
3. 并行网络爬虫的设计
3.1 并行爬虫设计概述
随着互联网数据量的急剧增长,传统的单线程爬虫在速度和效率上已无法满足大规模数据采集的需求。并行爬虫通过同时运行多个爬虫实例,提高了网页抓取的速度和效率,成为现代数据采集的重要技术途径。并行爬虫的设计主要包括多线程并行爬虫和分布式并行爬虫两种方案。
并行爬虫的设计旨在通过并发操作提升爬取效率,减小单节点爬取的瓶颈效应,并优化网络带宽和资源利用率。基本思想是将待爬取的网址任务分配给多个线程或节点,分别进行处理,以达到加快数据采集的目的。并行爬虫的实现涉及任务分配、线程管理、数据合并等多个环节,需要综合考虑系统的稳定性、资源使用率、任务调度策略等因素。
3.2 多线程并行爬虫
3.2.1 设计原理
多线程并行爬虫的设计原理是利用现代CPU的多核架构,通过在单个机器上创建多个线程来同时执行多个爬取任务。CPU的多核设计允许多个线程真正并行运行,而超线程技术则进一步允许单个核心执行多个线程,提高了CPU资源的利用率[5]。
3.2.2 流程与组件
多线程并行爬虫的流程如下,包含任务分解、线程创建与同步、资源分配与任务调度、网页抓取与处理和结果合并与存储等步骤。
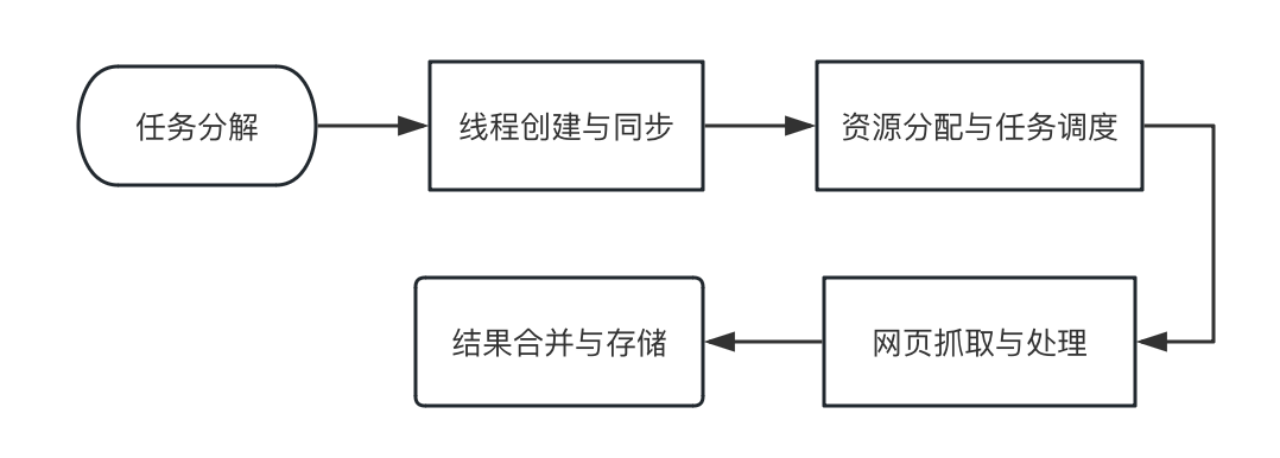
图3-1:多线程并行爬虫流程
组件包括以下几个部分:
(1)URL任务队列:用于存储待抓取的URL。可以使用诸如Python的Queue模块来实现线程安全的队列。特点是FIFO(先进先出),确保URL按顺序被处理。
(2)工作线程:每个线程负责从任务队列中获取一个URL,进行抓取,然后处理结果。
线程的数量通常会设置为CPU核心数的倍数,以充分利用多核处理能力,但也要考虑避免过多线程导致的上下文切换开销。
(3)抓取模块:包含HTTP请求的具体实现,如使用requests库或其他HTTP客户端库。
处理HTTP请求的细节,包括重试机制、超时设置等。
(4)结果处理模块:对抓取到的网页内容进行解析和处理,提取所需信息。可以使用正则表达式、BeautifulSoup、lxml等工具进行HTML解析。
(5)存储模块:将处理后的数据保存到数据库、文件系统或其他存储介质。需设计适当的数据存储格式和策略,保证数据的一致性和完整性。
(6)主控逻辑:管理URL任务队列和工作线程,协调各个组件的工作。负责启动和停止线程池,处理异常情况。
3.2.3 线程池
线程池是一种高级的编程模式,旨在提供高效的线程管理和复用机制,避免频繁创建和销毁线程所带来的开销。线程池的主要内容包括:
①预创建线程:在线程池初始化时预先创建一定数量的线程,这些线程会在任务到来之前处于待命状态,随时准备执行任务。
②任务队列:一个线程安全的队列,用于存放待执行的任务,线程池中的工作线程从该队列中获取任务进行处理。
③工作调度:线程池负责将任务分配给空闲的工作线程,并管理这些线程的执行顺序和优先级。
④自动扩展和收缩:根据系统负载和任务需求,线程池可以动态调整线程数量,自动增加或减少工作线程,以平衡资源使用和响应时间。
⑤生命周期管理:线程池负责管理线程的整个生命周期,包括创建、调度、执行和销毁,简化了线程管理的复杂性。
通过上述机制,线程池不仅减少了系统资源消耗,提高了并发处理效率,还极大地简化了编程的复杂性。
3.3 分布式并行爬虫
3.3.1 基本设计思路
分布式实现并行化爬虫的原理在于将爬虫任务分配到多个物理或虚拟机器上,这些机器通过网络相互连接,形成一个计算集群。每个节点独立执行分配给它的任务,通过这种方式,整个集群能够并行处理大量的数据,从而显著提高爬取效率和整体处理能力。分布式爬虫系统的设计需要考虑任务的合理分配、节点间的通信和协调以及数据的汇总与整合,以实现高效的并行处理[6]。
3.3.2 实现分布式爬虫的条件
实现分布式爬虫需满足以下几个关键条件:
(1)节点硬件条件:具备足够数量的物理或虚拟机器,每个节点应具有基本的计算和存储能力,以支持独立任务的执行。
(2)网络条件:高速、稳定的网络连接,确保节点之间能够快速、可靠地通信和数据传输。
(3)任务分配与调度:一个有效的任务分配和调度机制,能够根据任务量和节点的负载情况,将任务合理地分配到各个节点上。
(4)数据一致性与同步:确保分布式节点间的数据一致性,必要时进行数据同步,避免数据冗余和冲突。
(5)故障容错机制:具备可靠的故障检测和恢复机制,能够及时发现并处理节点故障,以保证系统的稳定运行。
3.3.3 分布式爬虫架构
分布式爬虫系统的架构通常包括以下几个主要组件:
- 中心调度器:中心调度器负责整个系统的任务调度和协调工作。它接收到待爬取的URL队列,然后将这些URL分配给可用的工作节点进行处理。中心调度器需要监控各个工作节点的状态,并根据系统负载情况动态调整任务的分配策略。
- 工作节点:工作节点是实际执行爬取任务的计算节点。每个工作节点从中心调度器获取任务,然后下载网页内容、解析数据并将结果存储到数据存储中。工作节点之间可以相互通信,共享部分数据,以提高系统的效率和性能。
- 数据存储:数据存储组件用于存储爬取到的数据,包括网页内容、页面元数据和其他相关信息。数据存储可以采用分布式文件系统、数据库或其他形式的存储系统,以便支持大规模数据的存储和管理。
- 通信框架:通信框架负责工作节点之间的通信和协作。它通过消息队列、RPC(远程过程调用)或其他通信机制,实现工作节点之间的任务分发、状态同步和数据交换。通信框架的设计需要考虑通信效率、可靠性和扩展性等因素。
这些组件共同构成了分布式爬虫系统的核心架构,通过合理的设计和优化,可以实现高效、可靠地大规模数据爬取和处理,满足不同应用场景的需求。
4. 并行网络爬虫的实现与结果分析
4.1 分布式并行爬虫调研
本部分主要对该方向的现有研究成果、文献进行调研对比和论证,下面以《基于Hadoop的分布式并行增量爬虫技术》作为分析对象,进行多方面的解读[7]。
4.1.1 研究环境配置
测试基于Map/Reduece的并行增量爬虫,该爬虫在分布式框架Hadoop集群上实现。搭建的 Hadoop集群由三台服务器组成,一台作为Master节点,两台作为 Slave节点,节点之间局域网连接,可以相互通信。
4.1.2 爬虫算法评价指标
论文提出了三个很有代表性的爬虫算法评价指标,分别是信息精确度,信息新鲜度和时间复杂度,具体含义如下:
·信息精确度:爬虫获取的数据与实际所需数据之间的匹配程度
·信息新鲜度:爬虫获取的数据与实时性的匹配程度
·时间复杂度:爬虫算法执行所需的时间量
4.1.3 实验结果及分析
(1)对比单机串行算法、单机多核并行算法、基于MapReduce的并行算法的效率和性能,结果如下:

图4-1:串并行爬虫算法的性能对比
可以从图中看出基于MapReduce的分布式并行算法性能优于单机多核并行算法,而并行算法则显著优于串行算法。
(2)对比分布式并行爬虫、串行增量爬虫和普通串行爬虫在冗余百分率、耗时方面的性能。其中冗余率是指冗余率是指在爬取过程中重复获取相同的数据或页面的比例,而增量爬虫的“增量”指的是只爬取自上次爬取以来发生变化或新增的数据,而不是每次都爬取整个网站的全部内容。下面是具体结果:
表4-1:不同爬虫类型性能对比
| 爬虫类型 | 代价 | 冗余百分率/% | 花费的时间/s |
| 分布式并行增量爬虫 | 11 | 0.6 | 341 |
| 串行增量爬虫 | 11 | 0.6 | 13411 |
| 串行爬虫 | 30 | 78.8 | 57150 |
从上表可以看出分布式并行增量爬虫的爬取结果冗余百分率、爬取代价和花费时间都是最低的,具有较好的性能。分析结果也可以得出结论:分布式并行提高了爬虫的爬取效率,降低了耗费时间,减少了爬取代价,而使用增量则能够显著降低爬取结果的冗余百分率。
4.2 多线程爬虫测试
4.2.1 实验内容
评估多线程并行爬虫在提高网页抓取效率方面的表现;对比传统单线程与多线程并行在运行时间、内存占用、CPU利用率和网络发送量等方面的性能。
4.2.2 参数设置
线程数量:单线程---1,多线程并行---2到20
爬取的任务数:初始设置为200,便于观察串行与并行的性能差距
URL模式:【图片】想来想去,还是开个答疑解惑贴。【iphone吧】_百度贴吧
本次实验爬取的对象是百度贴吧网站的各序号对应图片,如下所示:

图4-2:爬取对象
4.2.3 日志输出及可视化
记录单线程与多线程的运行时间。
记录内存占用变化。
记录CPU利用率。
记录网络发送和接收的数据量。
最终的结果以日志形式输出,具体形式如下所示:

图4-3:日志输出
4.3 实验结果及分析
4.3.1 观察并行化下爬取时间变化情况
注:本电脑Apple M1芯片处理机核心数量==8
固定爬取任务数为200,设置多线程的数量从2增加到20,实验结果可视化如下:
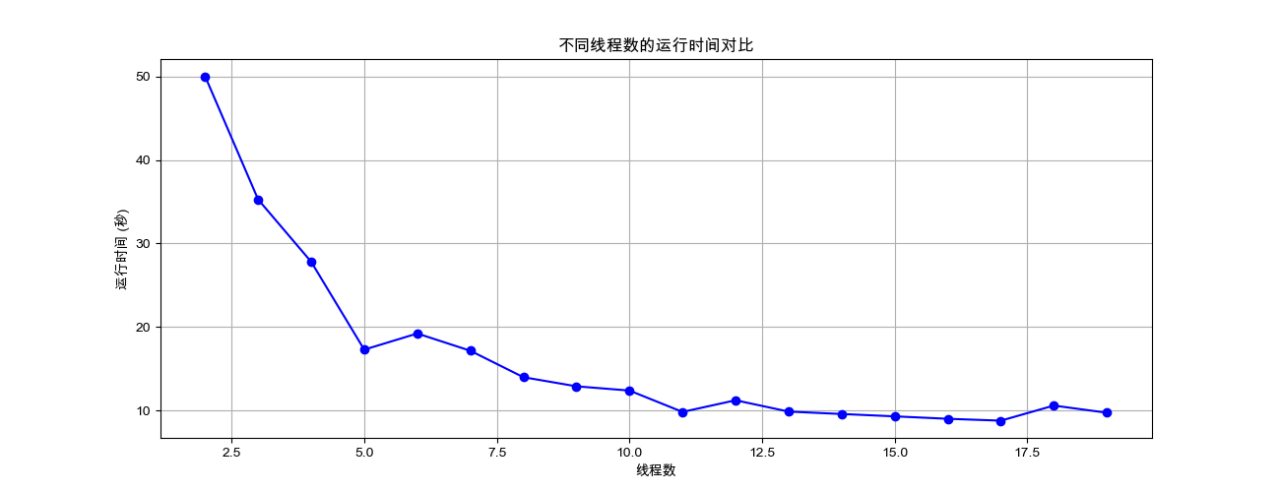
图4-4:不同线程数的运行时间对比
根据上述结果,并行化分析线程数与运行时间之间的关系:
①当线程数从2增加到8时,爬取时间减少,这可能是因为并行化提高了任务执行的效率。如果任务是I/O密集型,那么多线程可以更有效地利用处理器时间。------并行化的初期效果
②当线程数从8增加到9时,爬取时间继续减少,这可能表明操作系统能够通过上下文切换有效地管理额外的线程-OS中的并发、线程调度。
③从9到20,爬取时间出现轻微波动,这可能是由于多种因素造成的,包括上下文切换开销的增加、资源竞争、网络延迟的波动等。
4.3.2 观察并行化下加速比的变化情况
固定爬取任务数为200,设置多线程的数量从2增加到20,可视化结果如下:
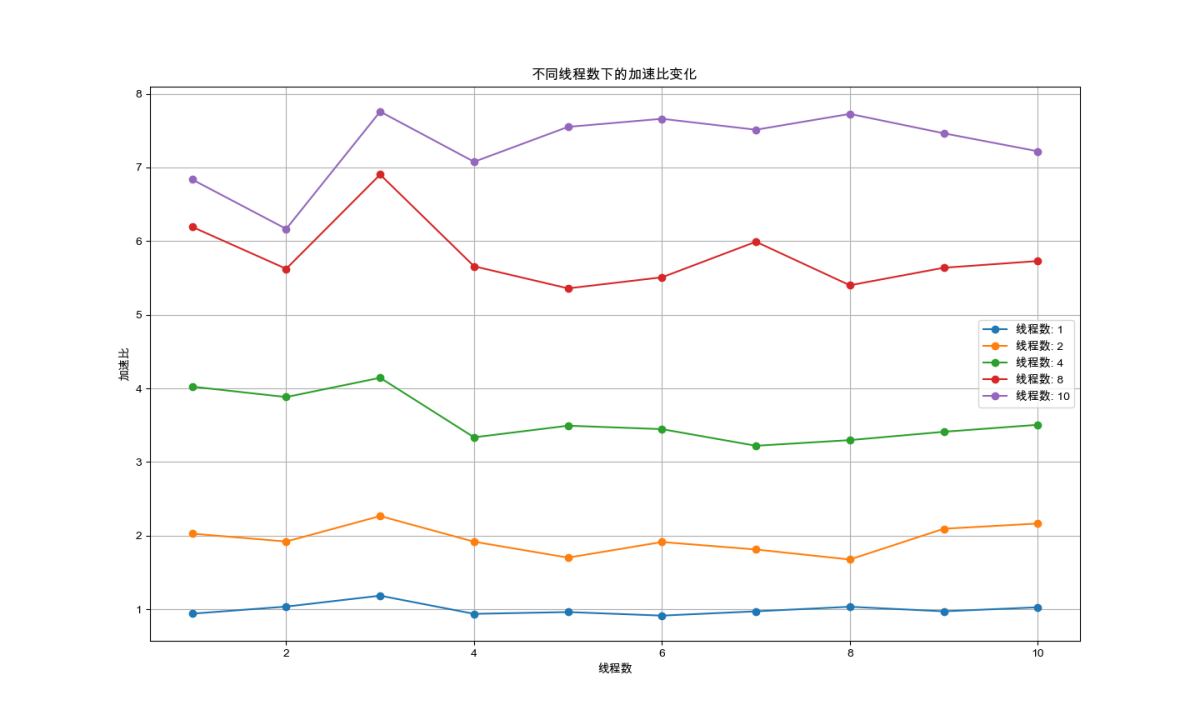
图4-5:并行化下加速比变化
在现实中,由于以下因素,加速比通常低于理想值-8:
①并行性限制:并非所有任务都可以完全并行化。有些部分可能需要串行执行。
②通信开销:线程或进程间的通信会引入额外开销。
③线程管理开销:线程的创建、调度和销毁有开销。
④资源限制:内存、I/O等资源可能成为瓶颈。
因此我们根据上述结果从并行化分析线程数与加速比之间的关系:
对于少于处理机数量的线程,增加线程数可以提高加速比,直到达到处理机的数量。
对于等于处理机数量的线程,当线程数与处理机数量相等时,理想情况下应达到最大加速比。
而多于处理机数量的线程:超过处理机数量的线程数通常不会增加加速比,反而可能导致上下文切换开销增大,降低性能。
当线程数从8增加到10时,理论上在有8个处理机的系统上,加速比应该不再提升,因为所有处理机已经被充分利用。然而,实际情况中可能观察到加速比继续增加,这可能是由以下一些因素导致的:
①任务粒度:如果每个任务的执行时间很短,那么增加线程数可能有助于减少等待时间,因为更多的线程可以在处理机上快速切换,从而可能提高整体的吞吐量。
②I/O密集型任务:如果任务涉及大量的I/O操作(例如网络请求),那么多线程可以在等待I/O操作完成时让其他线程运行,从而提高CPU的利用率。
③并行和并发同时运作;如一个8核的CPU可以同时执行8个线程,这种情况下就是并行的。如果有更多的线程需要执行,操作系统会通过上下文切换来让这些线程在8个核心上并发运行。这样,每个核心可能在不同时间点执行不同的线程,而从宏观上看,这些线程是同时进行的。
4.3.3 观察不同线程数、任务数下的爬取时间变化
设置线程数和爬取任务数为可变,为了便于观察,我们同样将结果进行可视化,如下图所示:
注:考虑程序总运行时间,将爬取任务数上限设置为50,线程数上限设置10
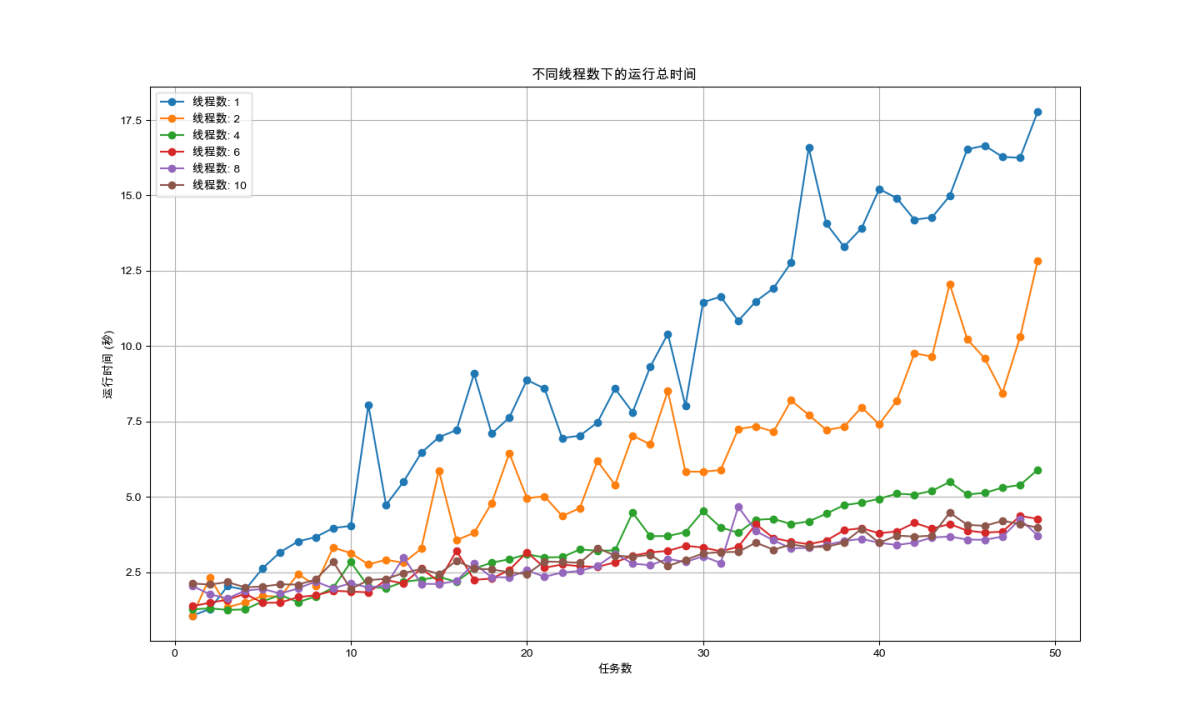
图4-6:不同任务数和线程数下的运行时间变化
从图中也可以清晰的看出并行化导致的性能提升在线程数从1变为2 的过程体现的最为显著;而后由于通信开销或负载均衡等因素,性能仅出现略微提升,如线程数为6、8的时刻;甚至在进程数超过处理机数量8后,性能出现了下降现象。综合上述结果,可以认为本任务的最佳线程数为4.
4.3.4 观察并行化对CPU利用率、内存使用量的影响
(1)固定爬取任务数为200,并设置多线程的数量从2到12,CPU利用率变化情况如下所示。
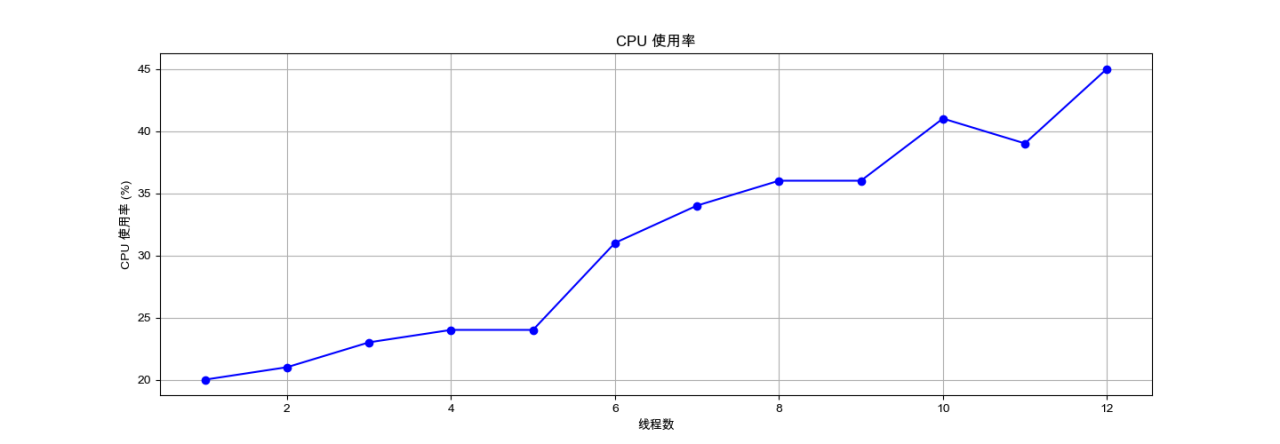
图4-7:并行化下CPU利用率变化
对上图进行并行化分析:首先是并行化开始阶段,即当线程数从1增加到多个时,CPU使用率开始上升,这可能是因为并行化开始执行,更多的任务同时进行。然后是任务分配阶段,随着线程数的增加,任务被分配到更多的线程上,这可能导致CPU使用率的增加,因为更多的核心或线程正在被利用。由于CPU核心数有限,当线程数超过核心数8时,操作系统会通过时间片轮转或其他调度算法来模拟多任务并行执行,这可能导致CPU使用率的波动。
因此对并行化的效率进行讨论,CPU使用率的增长并不是线性的,尤其是在线程数较高时(例如从46%增长到66%)。这可能意味着当线程数增加到一定程度后,由于上下文切换的开销、资源竞争、I/O等待等因素,CPU使用率的提升效率开始降低。
同时该过程存在一定的并行化的瓶颈,首先在线程数为1的情况下,CPU使用率较低,这可能是因为单线程无法充分利用多核处理器的能力。随着线程数的增加,CPU使用率提升,但当接近某个点时,CPU使用率的提升开始放缓,这是由于达到了处理器的核心数上限8。
(2)相同情况下,内存使用量变化情况如下
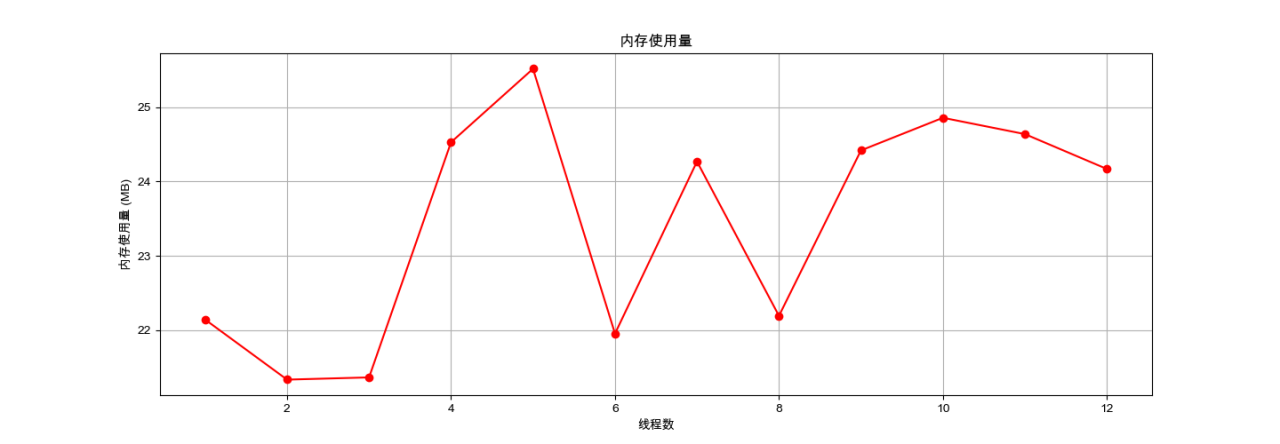
图4-8:并行化下内存使用量变化情况
从上图可以看出并行化的情况下内存使用量在21.11%到25.52%之间波动,并没有显示出明显的增长趋势。
虽然内存使用量并没有随并行化程度提高呈现明显的变化趋势,但从并行效率方面分析,如果程序的并行效率不高,增加线程数可能不会带来性能上的提升,反而可能导致内存使用量的增加,因为更多的线程意味着更多的上下文切换和线程管理开销。
另外在设计并行爬虫时需要考虑数据的局部性,它可以减少内存的使用量,因为数据可以在靠近处理它的线程的地方存储和访问。
4.3.5 观察并行化对爬虫过程网络发送量的影响
固定爬取任务数为250,设置线程数从1至12的范围内变化,对应网络发送量变化的可视化结果如下。
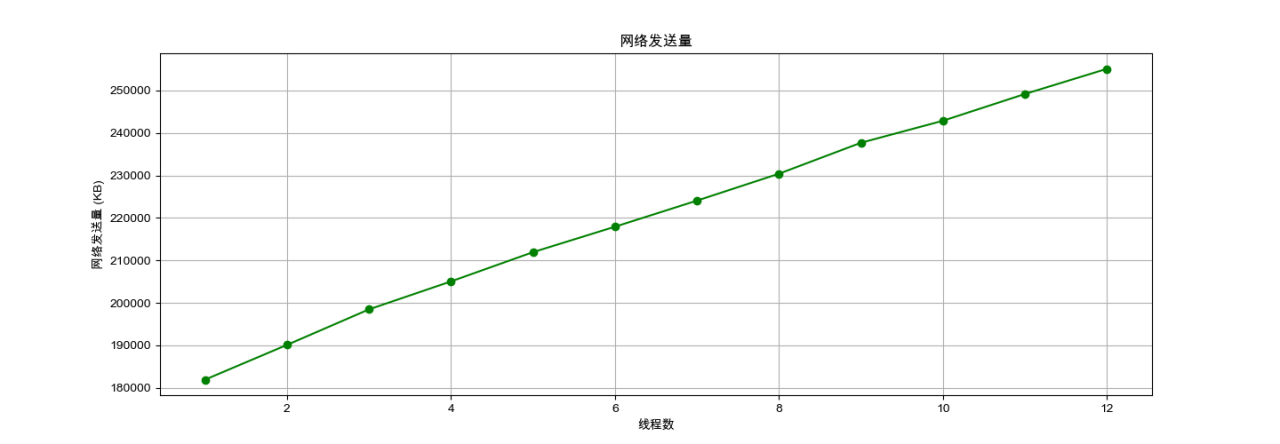
图4-9:并行化下网络发送量的变化情况
对上述结果进行并行化分析:
首先是网络发送量的增加,网络发送量(network_sent)随着线程数的增加而增加,这表明更多的线程可能导致更多的网络请求,从而增加了网络的使用量。
其次是线程数的增加,随着线程数的增加,如果每个线程都参与到网络通信中,那么整体的网络发送量可能会增加,因为有更多的线程在同时发送数据。
对于产生线性变化的原因,考虑任务分配,如果任务分配均匀,每个线程处理的数据量和发送的数据量可能相对一致,导致网络发送量的线性增长。
但需要额外考虑的是网络I/O操作,并行化程序中,网络I/O操作可能成为瓶颈。如果线程数过多,网络I/O操作的速度无法跟上增加的发送量,线程就会被迫等待网络I/O操作完成,处于空闲状态,从而降低了整个并行程序的效率和性能。
从上述结果也可以看出,在并行爬虫的设计和实现过程中,我们需要考虑的因素远远超出了单纯的任务并行化。除了网络I/O操作的影响外,还需要关注数据同步、分布式存储、反爬虫策略、页面解析和结构化数据提取等诸多复杂问题。与其他并行算法或任务相比,爬虫所涉及的网络通信、数据处理和存储等方面更为复杂,这意味着在并行爬虫的设计中需要更加综合地考虑性能、可靠性、安全性和可扩展性等方面的挑战[8]。
五、总结与展望
本论文分析研究了并行爬虫的设计与实现,重点探讨了多线程和分布式两种并行爬虫方案。在详细阐述URL协议、网页爬取策略以及网页分析算法的基础上,结合实际应用场景,设计并实现了多线程和分布式并行爬虫,通过实验对比分析了两者的性能和效率。实验结果表明,分布式并行爬虫在处理大规模数据时具有显著的优势,能够更有效地利用网络带宽和系统资源,提升数据抓取效率。然而,多线程爬虫在应对小规模数据集和简单任务时仍然具有较高的灵活性和实现简便性。
展望未来,随着互联网数据量的持续增长和数据结构的日益复杂,如何进一步提升并行爬虫的性能和智能化水平将成为一个重要的研究方向。未来的研究可以结合人工智能技术,自动识别和规避反爬虫策略,提升数据抓取的准确性和完整性。此外,分布式计算和云计算技术的发展也为并行爬虫提供了更多的可能性,通过更加高效的资源调度和任务管理,实现更大规模、更高效率的数据抓取和处理。
针对多线程爬虫,可以通过优化线程管理并采用更高效的I/O处理技术,例如异步I/O,以实现并行I/O处理。对于分布式并行爬虫,则可以采用更先进的技术平台和架构,如Hadoop集群、Docker的容器化技术以及云计算平台,从而实现更好的可扩展性。在这个基础上,进一步优化负载均衡和数据同步机制,将有助于打造更为健壮和高效的并行爬虫系统。
参考文献
- 周德懋,李舟军,高性能网络爬虫:研究综述[J].计算机科学,2019,36(8):26-29.
- 许笑,张伟哲,张宏莉等,广域网分布式Web爬虫[J].软件学报,2020,21(5):167-182.
- Brain E.Brewington,George Cybenko.How Dynamic is the Web.[C] Dartmouth College.Ninth International World Web Conferrence.2000.
- 丁宝琼,谢远平,吴琼等,基于改进DOM树的网页去噪声方法[J].计算机应用,2009,29(6):175-177.
- 吕晓峰,董守斌,张凌,并行数据采集器任务分配策略的设计与实现.[J] 华中科技大学学报(自然科学版).2023,31:105-107.
- 王毅桐.分布式网络爬虫技术研究与实现[D].成都:电子科技大学信息安全, 2019.
- 刘芳云,张志勇,李玉祥.基于Hadoop集群的分布式并行增量爬虫技术研究[J].科技信息,2019,(15).
- 孙冰.基于 Python 的多线程网络爬虫的设计与实现[D].北京:中国石油大学, 2018.
END~

在市井中放风 和小情绪握手