1.引言
1.1.DPM模型简介
深度概率模型(Deep Probabilistic Models) 是结合了深度学习和概率论的一类模型。这类模型通过使用深度学习架构(如神经网络)来构建复杂的概率分布,从而能够处理不确定性并进行预测。深度概率模型通常具有以下几个特点:
-
表示能力:深度概率模型能够学习数据的复杂表示,这些表示能够捕捉到数据中的潜在结构和模式。
-
不确定性建模:通过概率论,深度概率模型能够显式地建模不确定性,这对于处理噪声数据、缺失数据或进行长期预测等任务非常重要。
-
生成性:深度概率模型通常是生成性的,即它们能够生成与训练数据相似的新数据。这使得它们在数据增强、异常检测和内容生成等任务中非常有用。
-
可解释性:虽然深度概率模型通常比传统深度学习模型更复杂,但它们通常也提供了更多的可解释性,因为概率论为理解模型提供了强大的数学工具。
-
灵活性:深度概率模型可以很容易地与其他技术(如强化学习、因果推理等)结合使用,以构建更复杂的智能系统。
深度概率模型在多个领域都有广泛的应用,包括自然语言处理、计算机视觉、时间序列分析、推荐系统等。一些著名的深度概率模型包括变分自编码器(Variational Autoencoders)、深度信念网络(Deep Belief Networks)、生成对抗网络(Generative Adversarial Networks)以及循环神经网络(RNNs)和长短期记忆网络(LSTMs)等模型的概率变体。
1.2.本文讨论的内容
文章概览
本文涵盖了深度学习模型深度概率模型(DPM)模块的核心概念。虽然示例主要基于自然语言处理数据集,但所讨论的概念具有普遍性,适用于各个领域的应用。在本文结尾的附录2,我们鼓励读者尝试使用自己感兴趣的数据集,为数据设计合适的编码器,将本文中的概念迁移到其他领域。
文章内容
本文首先介绍了如何对给定的高维和结构化输入进行单变量响应变量的条件建模。我们首先探讨了名义响应变量的情况,随后转向数值响应变量,最后讨论了结构化响应变量。
本文讨论的目标
- 利用PyTorch定义联合概率分布
- 通过最大似然估计来确定模型参数
- 实现基于模型输出的决策过程
1.3.设置
# 导入matplotlib的pyplot模块,用于绘图
import matplotlib.pyplot as plt
# 设置matplotlib的绘图显示方式,使其可以在Jupyter Notebook中直接显示
%matplotlib inline
# 导入IPython的display模块,用于设置绘图格式
from IPython.display import set_matplotlib_formats
# 设置绘图格式为svg和pdf,以便于导出
set_matplotlib_formats('svg', 'pdf')
# 导入matplotlib模块,用于设置绘图参数
import matplotlib
# 设置线条宽度为2.0
matplotlib.rcParams['lines.linewidth'] = 2.0
# 导入random模块,用于生成随机数
import random
# 导入numpy模块,用于数值计算
import numpy as np
# 导入torch模块,用于深度学习相关操作
import torch
try:
# 尝试导入nltk和sklearn模块
import nltk # 注意:这里应该是nltk的拼写错误,通常是nltk或nltk.download,但nltk本身不是有效的模块
import sklearn
except ModuleNotFoundError: # 如果模块未找到,则执行以下操作
# 尝试安装nltk和sklearn模块(注意:这里应该是nltk的拼写错误,并且pip命令中的模块应该用空格分隔)
!pip install --quiet nltk sklearn # 修正了模块名称和pip命令的语法
# 导入nltk模块(注意:这里假设修正了nltk的拼写错误)
import nltk # 通常情况下,应该使用nltk.download()来下载nltk的数据集,而不是直接导入nltk模块
# 定义一个函数,用于设置所有随机数生成器的种子,以确保结果的可复现性
def seed_all(seed=42):
np.random.seed(seed) # 设置numpy的随机数种子
random.seed(seed) # 设置random模块的随机数种子
torch.manual_seed(seed) # 设置torch的随机数种子
# 调用seed_all函数,设置随机数种子为42
seed_all()
2.数据预处理
在文中,我们将设计涉及结构化数据的条件模型。在本文的示例中,我们将设计以下三种模型:
- 一个分类器
- 一个序数回归器
- 一个序列标注器
# 使用 NLTK(Natural Language Toolkit)的下载功能,下载所需的数据集和模型
# 下载 Penn Treebank 数据集,这是一个常用的句法标注和解析的语料库
import nltk
nltk.download('treebank')
# 下载 Brown Corpus 数据集,这是英语语言学研究中的一个重要语料库
nltk.download('brown')
# 下载 Punkt 分词器模型,用于英文文本的分词
nltk.download('punkt')
# 下载 Universal Tagset 标记集,这是一个跨语言的词性标记集
nltk.download('universal_tagset')
# 注意:下面的输出是 NLTK 下载过程中的日志信息,不是代码的一部分
# [nltk_data] 正在将包 treebank 下载到 /home/phillip/nltk_data...
# [nltk_data] 包 treebank 已经是最新版本!
# [nltk_data] 正在将包 brown 下载到 /home/phillip/nltk_data...
# [nltk_data] 正在解压 corpora/brown.zip。
# [nltk_data] 正在将包 punkt 下载到 /home/phillip/nltk_data...
# [nltk_data] 包 punkt 已经是最新版本!
# [nltk_data] 正在将包 universal_tagset 下载到
# [nltk_data] /home/phillip/nltk_data...
# [nltk_data] 包 universal_tagset 已经是最新版本!
2.1.情绪倾向
# 导入所需的库
from nltk.corpus import brown
import numpy as np
# 打印"fiction"类别的示例句子
print("'fiction' 示例")
for i, x in zip(range(3), brown.sents(categories=['fiction'])):
print(i, x)
print()
# 打印"religion"类别的示例句子
print("'religion' 示例")
for i, x in zip(range(3), brown.sents(categories=['religion'])):
print(i, x)
print()
# 打印"learned"类别的示例句子(注意:Brown Corpus中没有名为'learned'的类别,这里只是示例)
# 你可以替换为Brown Corpus中实际存在的类别,比如'news'
print("'learned' 示例(注意:'learned' 类别在 Brown Corpus 中不存在,这里使用 'news' 作为示例)")
for i, x in zip(range(3), brown.sents(categories=['news'])):
print(i, x)
# 定义函数 split_nltk_categorised_corpus
def split_nltk_categorised_corpus(corpus, categories, max_length=30, num_heldout=100):
"""
打乱并分割语料库。
corpus: 包含标签序列的语料库,每个序列是一对,每对是一个标记和一个标签。
max_length: 丢弃长度超过这个值的句子
返回:
(训练词序列, 训练标签序列),
(开发词序列, 开发标签序列),
(测试词序列, 测试标签序列)
"""
sentences = []
labels = []
for k, c in enumerate(categories):
seqs = corpus.sents(categories=[c])
sentences.extend(seqs)
labels.extend(len(seqs) * [k])
# 不要改变这里的随机种子
order = np.random.RandomState(42).permutation(np.arange(len(sentences)))
shuffled_sentences = [[w for w in sentences[i]] for i in order if len(sentences[i]) <= max_length]
shuffled_labels = [labels[i] for i in order if len(sentences[i]) <= max_length]
# 根据num_heldout的数量分割数据集
train_end = len(shuffled_sentences) - 2 * num_heldout
dev_end = train_end + num_heldout
return (shuffled_sentences[train_end:], shuffled_labels[train_end:]), \
(shuffled_sentences[train_end:dev_end], shuffled_labels[train_end:dev_end]), \
(shuffled_sentences[:train_end], shuffled_labels[:train_end])
# 调用函数分割数据集,并打印句子数量
(cat_training_x, cat_training_y), (cat_dev_x, cat_dev_y), (cat_test_x, cat_test_y) = split_nltk_categorised_corpus(brown, brown.categories(), num_heldout=1000)
print(f"句子数量: 训练={len(cat_training_x)} 开发={len(cat_dev_x)} 测试={len(cat_test_x)}")
# 输出各个数据集的句子和标签数量,以及第一个训练样本的句子和标签
print(len(cat_training_x), len(cat_dev_x), len(cat_test_x))
print(cat_training_y[0], cat_training_x[0])
情绪倾向分为15类
['adventure',
'belles_lettres',
'editorial',
'fiction',
'government',
'hobbies',
'humor',
'learned',
'lore',
'mystery',
'news',
'religion',
'reviews',
'romance',
'science_fiction']
以下是词情绪分类的示例
'fiction' examples
0 ['Thirty-three']
1 ['Scotty', 'did', 'not', 'go', 'back', 'to', 'school', '.']
2 ['His', 'parents', 'talked', 'seriously', 'and', 'lengthily', 'to', 'their', 'own', 'doctor', 'and', 'to', 'a', 'specialist', 'at', 'the', 'University', 'Hospital', '--', 'Mr.', 'McKinley', 'was', 'entitled', 'to', 'a', 'discount', 'for', 'members', 'of', 'his', 'family', '--', 'and', 'it', 'was', 'decided', 'it', 'would', 'be', 'best', 'for', 'him', 'to', 'take', 'the', 'remainder', 'of', 'the', 'term', 'off', ',', 'spend', 'a', 'lot', 'of', 'time', 'in', 'bed', 'and', ',', 'for', 'the', 'rest', ',', 'do', 'pretty', 'much', 'as', 'he', 'chose', '--', 'provided', ',', 'of', 'course', ',', 'he', 'chose', 'to', 'do', 'nothing', 'too', 'exciting', 'or', 'too', 'debilitating', '.']
'religion' examples
0 ['As', 'a', 'result', ',', 'although', 'we', 'still', 'make', 'use', 'of', 'this', 'distinction', ',', 'there', 'is', 'much', 'confusion', 'as', 'to', 'the', 'meaning', 'of', 'the', 'basic', 'terms', 'employed', '.']
1 ['Just', 'what', 'is', 'meant', 'by', '``', 'spirit', "''", 'and', 'by', '``', 'matter', "''", '?', '?']
2 ['The', 'terms', 'are', 'generally', 'taken', 'for', 'granted', 'as', 'though', 'they', 'referred', 'to', 'direct', 'and', 'axiomatic', 'elements', 'in', 'the', 'common', 'experience', 'of', 'all', '.']
'learned' examples
0 ['1', '.']
1 ['Introduction']
2 ['It', 'has', 'recently', 'become', 'practical', 'to', 'use', 'the', 'radio', 'emission', 'of', 'the', 'moon', 'and', 'planets', 'as', 'a', 'new', 'source', 'of', 'information', 'about', 'these', 'bodies', 'and', 'their', 'atmospheres', '.']
2.2.研究者年龄数据集
研究数据集介绍
在2006年,Schler等人搜集并注释了一个博客文章的数据集,其中包含了作者的年龄信息。我们将利用这个数据集的一个子集进行我们的分析。如果您对整个数据集感兴趣,可以在Kaggle上找到它。
重要提示
虽然我们将利用这个数据集来阐释泊松回归的模型,但我们必须认识到,在某些应用场景中,年龄可能属于个人隐私范畴。因此,设计和部署任何可能涉及年龄识别的系统时,我们应当深思熟虑,确保尊重个人隐私并避免任何可能的负面影响。
# 导入所需的库
import json
import numpy as np
from nltk.tokenize import word_tokenize # 注意:通常应该是nltk.tokenize,但这里假设是自定义的库或别名
# 下载数据
# 注意:wget命令通常在Linux或macOS的shell环境中使用,如果你在Windows环境下,请改用其他方式下载文件
# !wget https://surfdrive.surf.nl/files/index.php/s/2xWdFxnewjN9gsq/download -O blog-authorship.json.gz
# !gzip -d blog-authorship.json.gz
# 假设你已经有了解压后的blog-authorship.json文件
with open("blog-authorship.json") as f:
blog_data = json.load(f)
# 查看数据的键
# print(blog_data.keys())
# 查看source和ack字段(如果存在的话)
# print(blog_data['source'], blog_data['ack'])
# 查看训练集、开发集和测试集的大小
print(f"训练集大小: {len(blog_data['training'])}")
print(f"开发集大小: {len(blog_data['dev'])}")
print(f"测试集大小: {len(blog_data['test'])}")
# 查看训练集中的一个数据点
# print(blog_data['training'][0])
# 示例:计算数据预处理所需时间(注意:%%time是Jupyter Notebook中的魔法命令,这里用普通的时间计算)
import time
start_time = time.time()
# 对数据进行分词和打乱顺序
order = np.random.RandomState(42).permutation(np.arange(len(blog_data["training"])))
blog_training_x = [word_tokenize(blog_data["training"][i][0].lower()) for i in order]
blog_training_y = [[blog_data["training"][i][1]] for i in order]
blog_dev_x = [word_tokenize(x[0].lower()) for x in blog_data["dev"]]
blog_dev_y = [[x[1]] for x in blog_data["dev"]]
blog_test_x = [word_tokenize(x[0].lower()) for x in blog_data["test"]]
blog_test_y = [[x[1]] for x in blog_data["test"]]
# 示例:打印预处理后的一个数据点
print(f"输入文本: {blog_training_x[0]}")
print(f"作者年龄: {blog_training_y[0]}")
# 计算处理时间
end_time = time.time()
print(f"数据预处理时间: {end_time - start_time} 秒")
2.3.句法分类
句法类别的应用
我们将利用NLTK库中的资源,特别是带有句法类别标注的语料库。这些数据将使我们能够深入分析句子的句法结构。
语料库介绍
我们特别关注Treebank语料库,它包含了大量带有词性标注的句子。这些标注不仅帮助我们识别每个单词的语法角色,如名词、动词或形容词,还有助于我们理解句子的整体结构。
分析方法
通过这种方法,我们将获得标记化句子的视图,这些句子不仅被分解成单独的词汇单元,还附有对应的滞后标签,即tagged_sents。这种标记化和标注过程为我们提供了一种强大的工具,用于进一步的句法分析和自然语言理解。
import numpy as np
# 假设 treebank 是一个已经定义好的 NLTK 风格的语料库对象
# 这里我们先模拟一下 treebank.tagged_sents 的行为,因为原始代码中没有给出 treebank 的定义
def mock_tagged_sents(tagset='universal'):
# 这里只是模拟返回一些带标签的句子,实际情况下应该返回 treebank 的内容
return [("我", "r"), ("喜欢", "v"), ("吃", "v"), ("苹果", "n"), ("。", "w"), ...] # 这里省略了其他句子
# 修改 split_nltk_tagged_corpus 函数,因为 treebank 没有 tagged_sents 方法,我们直接传入句子列表
def split_nltk_tagged_corpus(corpus, max_length=30, num_heldout=100):
"""
打乱并分割语料库。
corpus: 一个带标签的句子列表,每个句子是一个 (token, tag) 对的列表。
max_length: 丢弃长度超过此值的句子。
返回:
(训练词序列, 训练标签序列),
(开发集词序列, 开发集标签序列),
(测试集词序列, 测试集标签序列)
"""
# 不要在这里改变随机种子
order = np.random.RandomState(42).permutation(np.arange(len(corpus)))
# 过滤长度超过 max_length 的句子,并提取词和标签
word_sequences = [[w.lower() for w, t in sentence] for i, sentence in enumerate(corpus) if i in order and len(sentence) <= max_length]
tag_sequences = [[t for w, t in sentence] for i, sentence in enumerate(corpus) if i in order and len(sentence) <= max_length]
# 划分训练集、开发集和测试集
train_end = len(word_sequences) - 2 * num_heldout
dev_start = train_end
dev_end = dev_start + num_heldout
return (word_sequences[train_end:], tag_sequences[train_end:]), (word_sequences[dev_start:dev_end], tag_sequences[dev_start:dev_end]), (word_sequences[:dev_start], tag_sequences[:dev_start])
# 假设 treebank 是通过 mock_tagged_sents 得到的句子列表
treebank = mock_tagged_sents() # 这里应该使用真实的 treebank.tagged_sents 方法
# 调用 split_nltk_tagged_corpus 函数并打印结果
(tagger_training_x, tagger_training_y), (tagger_dev_x, tagger_dev_y), (tagger_test_x, tagger_test_y) = split_nltk_tagged_corpus(treebank, num_heldout=100)
print(f"句子数量: 训练集={len(tagger_training_x)} 开发集={len(tagger_dev_x)} 测试集={len(tagger_test_x)}")
print("# 几个训练句子\n")
for n in range(3):
print(f"x_{n} = {tagger_training_x[n]}")
print(f"y_{n} = {tagger_training_y[n]}")
print()
2.4.词汇标记
词汇表的重要性
在构建NLP模型时,我们需要一个系统来追踪和管理我们所了解的词汇。这通常通过单词标记化来实现。
词汇类的功能
我们将创建一个词汇类,它将维护一个已知标记的集合,并提供一个双向映射机制:将标记转换为内部代码,以及将这些代码转换回原始标记。这有助于模型在处理文本数据时保持一致性和效率。
特殊符号的处理
在我们的词汇管理中,我们还将特别考虑一些特殊符号,例如BOS(句子的开始)、EOS(句子的结束)、UNK(未知标记)和PAD(填充标记)。这些符号在文本预处理和模型训练中扮演着重要角色。
标记器的选择
在模型训练完成后,如果我们希望在未经标记化的新句子上测试模型,我们可以选择使用任何标记器,只要它与我们训练模型时使用的标记化级别相似。例如,NLTK库中的nltk.tokenize.word_tokenize函数就是一个常用的选择。
词汇类的用途
这个词汇类将作为我们模型的核心组件,用于维护和管理词汇表以及与标记器相关的数据。
import numpy as np
from itertools import chain
from collections import Counter, OrderedDict
class Vocab:
def __init__(self, corpus: list, min_freq=1):
"""
构造函数初始化词汇表。
corpus: 文档列表,每个文档是标记列表,每个标记是字符串。
min_freq: 词频小于这个值的词将被丢弃。
"""
# 统计词频
counter = Counter(chain(*corpus))
# 按词频降序排序
sorted_by_freq_tuples = sorted(counter.items(), key=lambda pair: pair[1], reverse=True)
# 特殊标记
self.pad_token = "-PAD-" # 用于填充序列到批次中的最大序列长度
self.bos_token = "-BOS-" # 序列开始
self.eos_token = "-EOS-" # 序列结束
self.unk_token = "-UNK-" # 未知符号
self.pad_id = 0
self.bos_id = 1
self.eos_id = 2
self.unk_id = 3
self.known_symbols = [self.pad_token, self.bos_token, self.eos_token, self.unk_token]
self.counts = [0, 0]
# 词汇表
self.word2id = OrderedDict()
self.word2id[self.pad_token] = self.pad_id
self.word2id[self.bos_token] = self.bos_id
self.word2id[self.eos_token] = self.eos_id
self.word2id[self.unk_token] = self.unk_id
self.min_freq = min_freq
for w, n in sorted_by_freq_tuples:
if n >= min_freq: # 丢弃低频词
self.word2id[w] = len(self.known_symbols)
self.known_symbols.append(w)
self.counts.append(n)
# 存储词频
self.counts = np.array(self.counts)
def __len__(self):
# 返回已知符号的数量
return len(self.known_symbols)
def __getitem__(self, word: str):
# 根据词返回对应的id
return self.word2id.get(word, self.unk_id)
def encode(self, doc: list, add_bos=False, add_eos=False, pad_right=0):
"""
将文档转换为整数标记数组。
doc: 标记列表,每个标记是字符串
add_bos: 是否添加BOS标记
add_eos: 是否添加EOS标记
pad_right: 后缀填充标记的数量
返回: 可能带有BOS和EOS以及填充的代码列表
"""
return [self.word2id.get(w, self.unk_id) for w in chain(
[self.bos_token] * int(add_bos), doc, [self.eos_token] * int(add_eos), [self.pad_token] * pad_right)]
def batch_encode(self, docs: list, add_bos=False, add_eos=False):
"""
将一批文档转换为整数标记的numpy数组。
这将把较短的文档填充到最长文档的长度。
docs: 文档列表
add_bos: 是否添加BOS标记
add_eos: 是否添加EOS标记
返回: numpy数组,形状为[len(docs), longest_doc + add_bos + add_eos]
"""
max_len = max(len(doc) for doc in docs)
return np.array([self.encode(doc, add_bos=add_bos, add_eos=add_eos, pad_right=max_len-len(doc)) for doc in docs])
def decode(self, ids, strip_pad=False):
"""
将整数标记数组转换为标记列表。
ids: 形状为[num_tokens]的numpy数组
strip_pad: 是否从输出中删除PAD标记
返回: 大小为[num_tokens - num_padding]的字符串列表
"""
if strip_pad:
return [self.known_symbols[id] for id in ids if id != self.pad_id]
else:
return [self.known_symbols[id] for id in ids]
def batch_decode(self, docs, strip_pad=False):
"""
将整数标记的文档集合转换为标记列表的集合。
ids: 形状为[num_docs, max_length]的numpy数组
strip_pad: 是否从输出中删除PAD标记
返回: 每个文档都是标记列表的文档列表,每个标记都是字符串
"""
return [self.decode(doc, strip_pad=strip_pad) for doc in docs]
# 创建词的词汇表
word_vocab = Vocab(tagger_training_x, min_freq=2)
# 创建标签的词汇表
tag_vocab = Vocab(tagger_training_y, min_freq=1)
# 查看词汇表的大小 V 和 C
print(len(word_vocab), len(tag_vocab))
上述方法实现了以下功能:
编码方法
该方法的功能是将字符串(str)形式的符号序列转换成整数(int)形式的代码序列。这是通过encode方法实现的。
特殊符号的添加
在编码过程中,我们可以为序列添加一些特殊符号,例如BOS、EOS和PAD。但重要的是要保持一致性,确保编码后的标记序列和标签序列长度匹配。
批量编码和解码
我们还提供了对整批序列进行编码和解码的能力。这涉及到使用特殊符号/代码,以确保同一批次中的所有序列长度相同,从而方便批量处理。
我们来看看预处理的效果
array([[ 45, 907, 13, 36, 18, 600, 1078, 8, 1651, 1652, 6,
41, 19, 36, 66, 71, 2194, 55, 5, 2195, 10, 5,
487, 4, 21, 2, 0, 0, 0],
[ 488, 14, 1309, 156, 2196, 3, 3, 16, 3, 31, 449,
908, 19, 3, 601, 909, 772, 8, 343, 910, 26, 9,
2197, 344, 4, 2, 0, 0, 0],
[ 5, 542, 129, 40, 2198, 12, 34, 5, 1310, 264, 16,
44, 378, 54, 37, 44, 324, 10, 5, 2199, 186, 8,
25, 1311, 23, 9, 111, 4, 2]])
[['they',
'know',
'0',
'he',
'is',
'generally',
'opposed',
'to',
'cop-killer',
'bullets',
',',
'but',
'that',
'he',
'had',
'some',
'reservations',
'about',
'the',
'language',
'in',
'the',
'legislation',
'.',
"''",
'-EOS-'],
['california',
"'s",
'education',
'department',
'suspects',
'-UNK-',
'-UNK-',
'for',
'-UNK-',
'at',
'40',
'schools',
'that',
'-UNK-',
'changed',
'wrong',
'answers',
'to',
'right',
'ones',
'on',
'a',
'statewide',
'test',
'.',
'-EOS-'],
['the',
'loan',
'may',
'be',
'extended',
'*-1',
'by',
'the',
'mcalpine',
'group',
'for',
'an',
'additional',
'year',
'with',
'an',
'increase',
'in',
'the',
'conversion',
'price',
'to',
'$',
'2.50',
'*u*',
'a',
'share',
'.',
'-EOS-']]
2.5 语料库与数据加载器
在PyTorch中,Dataset类用于封装数据集,提供数据的索引访问方法,而DataLoader类则用于实现数据的批量加载和打乱等操作,以便于模型训练时使用。这样,我们可以方便地将处理好的语料数据喂入模型进行训练。
import torch
from torch.utils.data import Dataset, DataLoader
class TextRegressionCorpus(Dataset):
"""
此类用于让PyTorch能够访问带有简单响应变量注释的文档语料库(例如,类别或实数)。
这个类还将知道token的词汇表对象,
并且它将负责一致地将字符串编码成整数。
"""
def __init__(self, corpus_x, corpus_y, vocab_x: Vocab):
"""
在PyTorch中,我们最好总是操作数字代码,而不是文本。
因此,我们的语料库对象将包含一个词汇表,用于将单词转换为代码。
corpus_x: 词序列
corpus_y: 响应值
vocab_x: 输入符号的词汇表
"""
self.corpus_x = list(corpus_x) # 将输入文档转换为列表
self.corpus_y = list(corpus_y) # 将响应值转换为列表
if len(self.corpus_x) != len(self.corpus_y): # 确保输入文档和响应值的数量相同
raise ValueError("需要成对的数据")
self.vocab_x = vocab_x # 输入词汇表
def __len__(self):
"""返回语料库中序列对的数量"""
return len(self.corpus_x)
def __getitem__(self, idx):
"""返回转换为代码的corpus_x[idx]和corpus_y[idx],并在末尾添加EOS代码"""
x = self.vocab_x.encode(self.corpus_x[idx], add_bos=False, add_eos=True) # 编码词序列
y = self.corpus_y[idx] # 响应值
return x, y
def pad_to_longest(self, pairs, pad_id=0):
"""
取一系列编码序列,并返回一个torch张量,其中
每个句子都有相同的长度(通过使用PAD标记)
"""
longest = max(len(x) for x, y in pairs) # 找到最长序列的长度
batch_x = torch.tensor([x + [self.vocab_x.pad_id] * (longest - len(x)) for x, y in pairs]) # 填充序列
batch_y = torch.tensor([y for x, y in pairs]) # 响应值序列
return batch_x, batch_y
# ParallelCorpus和TaggedCorpus类的注释类似,根据上述模式进行注释即可。
class ParallelCorpus(Dataset):
"""
此类用于让PyTorch能够访问成对序列的语料库。
这个类还将知道两个数据流的词汇表对象,
并且它将负责一致地将字符串编码成整数。
"""
def __init__(self, corpus_x, corpus_y, vocab_x: Vocab, vocab_y: Vocab):
"""
在PyTorch中,我们最好总是操作数字代码,而不是文本。
因此,我们的语料库对象将包含词汇表,用于将单词转换为代码。
corpus_x: 词序列
corpus_y: 标签序列
vocab_x: 词序列的词汇表
vocab_y: 标签序列的词汇表
"""
self.corpus_x = list(corpus_x) # 将输入文档转换为列表
self.corpus_y = list(corpus_y) # 将标签序列转换为列表
assert len(self.corpus_x) == len(self.corpus_y), "需要成对的序列" # 确保词序列和标签序列数量相同
self.vocab_x = vocab_x # 词序列的词汇表
self.vocab_y = vocab_y # 标签序列的词汇表
def __len__(self):
"""返回语料库中序列对的数量"""
return len(self.corpus_x)
def __getitem__(self, idx):
"""
返回转换为代码的corpus_x[idx]和corpus_y[idx],
后者在末尾添加了EOS代码
"""
x = self.vocab_x.encode(self.corpus_x[idx], add_bos=False, add_eos=True) # 编码词序列
y = self.vocab_y.encode(self.corpus_y[idx], add_bos=False, add_eos=True) # 编码标签序列
return x, y
def pad_to_longest(self, pairs, pad_id=0):
"""
取一系列编码序列,并返回一个torch张量,其中
每个句子都有相同的长度(通过使用PAD标记)
"""
longest_x = max(len(x) for x, y in pairs) # 找到编码词序列中的最长序列
longest_y = max(len(y) for x, y in pairs) # 找到编码标签序列中的最长序列
batch_x = torch.tensor(
[x + [self.vocab_x.pad_id] * (longest_x - len(x)) for x, y in pairs]) # 填充编码词序列
batch_y = torch.tensor(
[y + [self.vocab_y.pad_id] * (longest_y - len(y)) for x, y in pairs]) # 填充编码标签序列
return batch_x, batch_y
class TaggedCorpus(ParallelCorpus):
"""
此类用于让PyTorch能够访问标记序列的语料库。
这个类还将知道词和标签的词汇表对象,
并且它将负责一致地将字符串编码成整数。
"""
def __init__(self, corpus_x, corpus_y, vocab_x: Vocab, vocab_y: Vocab):
"""
在PyTorch中,我们最好总是操作数字代码,而不是文本。
因此,我们的语料库对象将包含词汇表,用于将单词转换为代码。
corpus_x: 词序列
corpus_y: 标签序列
vocab_x: 词序列的词汇表
vocab_y: 标签序列的词汇表
"""
super().__init__(corpus_x, corpus_y, vocab_x, vocab_y) # 调用基类的构造函数
assert all(len(x) == len(y) for x, y in zip(corpus_x, corpus_y)), "每个序列对的长度应该匹配" # 确保每个词序列和标签序列长度相同
我们将输入和输出数据整合为PyTorch张量(tensor)对象,以便用于训练、开发和测试。请注意,训练、开发和测试数据都使用相同的词汇表,该词汇表仅基于训练集构建。我们可以将这些标注器数据封装为一个PyTorch的Dataset对象。
以下是一个如何为语料库获取PyTorch DataLoader的示例。我们只需选择所需的数据集对象(训练/开发/测试),设置所需的批处理大小,决定是否需要对数据进行打乱(例如,在随机梯度下降中的训练批次),以及确定如何将不同长度的数据点“填充”至同一长度(即,使用如pad_to_longest这样的函数为我们处理)。
DataLoader Dataset pad_to_longest 这些术语在PyTorch中用于描述数据加载和预处理的相关组件,而不是具体的类名或方法名,因此在此不进行直接翻译。在实际应用中,Dataset和DataLoader是PyTorch提供的类,用于加载和批处理数据;而pad_to_longest可能是一个自定义函数,用于确保每个批次的数据长度一致。
# 创建一个TaggedCorpus对象,其中包含了训练数据x和y,以及对应的单词和标签词汇表
tagger_training = TaggedCorpus(tagger_training_x, tagger_training_y, word_vocab, tag_vocab)
# 创建一个DataLoader对象,用于批量加载数据。这里设置批处理大小为3,每次迭代时打乱数据,并使用tagger_training的pad_to_longest方法作为数据整理函数
batcher = DataLoader(tagger_training, batch_size=3, shuffle=True, collate_fn=tagger_training.pad_to_longest)
# 遍历DataLoader,获取批量的数据
for batch_x, batch_y in batcher:
print("# 这是数据加载器输出的一个批次中的标注序列\n")
# 遍历一个批次中的每一个数据点(句子和对应的标签)
for x, y in zip(batch_x, batch_y):
print(x) # 打印句子的编码(可能是单词ID序列)
print(y) # 打印句子对应的标签编码(可能是标签ID序列)
print() # 换行
print("# 我们可以对它们进行解码以便检查\n")
# 去掉填充部分使得例子更容易阅读
# 使用word_vocab和tag_vocab的batch_decode方法解码句子和标签
for x, y in zip(word_vocab.batch_decode(batch_x, strip_pad=True), tag_vocab.batch_decode(batch_y, strip_pad=True)):
print(x) # 打印解码后的句子(单词序列)
print(y) # 打印解码后的标签(标签序列)
print() # 换行
# 假设我们只想看一个批次的数据,所以这里使用break退出循环
break
# This is how the tagged sequences in a batch come out of the data loader
tensor([ 77, 2535, 5, 318, 6, 43, 776, 4, 2, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
tensor([14, 5, 8, 4, 6, 14, 4, 6, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0])
tensor([ 3, 3, 11, 3, 98, 13, 45, 29, 3, 7, 101, 918,
175, 34, 1491, 15, 8, 3, 49, 3, 748, 213, 4, 2])
tensor([ 4, 4, 15, 4, 5, 10, 14, 5, 9, 7, 8, 4, 10, 7, 4, 10, 13, 5,
15, 5, 4, 4, 6, 2])
tensor([ 46, 882, 69, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
tensor([4, 4, 6, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
# And we can always decode them for inspection
['i', 'loved', 'the', 'school', ',', 'its', 'history', '.', '-EOS-']
['PRON', 'VERB', 'DET', 'NOUN', '.', 'PRON', 'NOUN', '.', '-EOS-']
['-UNK-', '-UNK-', 'and', '-UNK-', 'say', '0', 'they', 'are', '-UNK-', 'of', 'any', 'efforts', '*ich*-1', 'by', 'mcgraw-hill', '*', 'to', '-UNK-', 'or', '-UNK-', 'scoring', 'high', '.', '-EOS-']
['NOUN', 'NOUN', 'CONJ', 'NOUN', 'VERB', 'X', 'PRON', 'VERB', 'ADJ', 'ADP', 'DET', 'NOUN', 'X', 'ADP', 'NOUN', 'X', 'PRT', 'VERB', 'CONJ', 'VERB', 'NOUN', 'NOUN', '.', '-EOS-']
['new', 'account', ':', '-EOS-']
['NOUN', 'NOUN', '.', '-EOS-']
2.6.文本编码器
在自然语言处理(NLP)应用中,我们经常需要将文本片段进行编码。这种需求在文本分类、回归以及序列标注等任务中尤为常见。
以文本分类器为例,它接收一个文档作为输入,其中每个词(token)来自一个有限的词汇表。文本分类器的目标是对一系列类别进行预测,并输出一个类别分布。一个编码函数可以将文档映射到一个固定维度的向量(比如d维),随后,我们可以使用一个仿射变换(affine transformation)将这个向量转换为另一个维度(比如k维)的分数向量。最后,通过softmax函数将这个分数向量转换为概率分布,使得所有类别的概率之和为1。
x
1
:
l
=
<
x
1
,
x
2
,
⋯
,
x
l
>
x
i
∈
W
V
C
T
=
{
1
,
2
,
⋯
,
c
}
x
1
:
l
D
u
C
x_{1:l}=<x_1,x_2,\cdots,x_l>x_i\in{WVCT}=\{1,2,\cdots,c\}x_{1:l}D_uC
x1:l=<x1,x2,⋯,xl>xi∈WVCT={1,2,⋯,c}x1:lDuC
Y
∣
x
1
:
l
=
x
1
:
l
∼
C
a
t
e
g
o
r
i
c
a
l
(
g
(
x
1
:
l
;
θ
)
)
u
=
e
n
c
o
d
e
D
(
x
1
:
l
;
θ
c
)
u
=
a
f
f
i
n
e
D
(
u
;
θ
o
u
t
)
g
(
x
1
:
l
;
θ
)
=
s
o
f
t
m
a
x
(
s
)
Y|x_{1:l}=x_{1:l}\sim{Categorical(g(x_{1:l}; \theta))}\\ u=encode_D(x_{1:l}; \theta_{c})\\u=affine_D(u; \theta_{out})\\g(x_{1:l}; \theta)=softmax(s)
Y∣x1:l=x1:l∼Categorical(g(x1:l;θ))u=encodeD(x1:l;θc)u=affineD(u;θout)g(x1:l;θ)=softmax(s)
通常,文本编码器可以为整个文档返回一个单一的输出向量,或者为文档中的每个词返回一个向量。这些向量捕捉了文本中的语义信息,使得机器学习模型能够理解和处理文本数据。
import torch
import torch.nn as nn
class Encoder(nn.Module):
"""
编码器类,将输入数据编码为指定维度的输出。
"""
def __init__(self, input_dim, output_dim):
"""
初始化编码器。
参数:
- input_dim (int): 输入数据的特征维度。
- output_dim (int): 输出数据的特征维度。
"""
super(Encoder, self).__init__()
self._input_dim = input_dim # 添加输入维度属性
self._output_dim = output_dim
self.linear = nn.Linear(input_dim, output_dim) # 定义一个线性层进行编码
@property
def input_dim(self):
"""
获取输入数据的特征维度。
返回:
- int: 输入数据的特征维度。
"""
return self._input_dim
@property
def output_dim(self):
"""
获取输出数据的特征维度。
返回:
- int: 输出数据的特征维度。
"""
return self._output_dim
def forward(self, x):
"""
前向传播函数,对输入数据进行编码。
参数:
- x (torch.Tensor): 输入数据,形状为 [batch_size, max_length, input_dim]。
返回:
- torch.Tensor: 编码后的数据,形状为 [batch_size, max_length, output_dim]。
注意: 这里假设输入数据已经是三维的,包含了batch_size、max_length和input_dim三个维度。
如果输入数据是二维的(例如[batch_size, input_dim]),则需要在送入编码器之前进行相应的reshape操作。
"""
# 假设x的形状为[batch_size, max_length, input_dim]
# 使用reshape(-1, self.input_dim)将x展平为[batch_size * max_length, input_dim]
# 然后通过线性层进行编码,得到形状为[batch_size * max_length, output_dim]的输出
# 最后使用view(x.size(0), x.size(1), self.output_dim)将输出重新塑形为[batch_size, max_length, output_dim]
x_flat = x.reshape(-1, self.input_dim)
encoded = self.linear(x_flat)
encoded = encoded.view(x.size(0), x.size(1), self.output_dim)
return encoded
# 使用示例(假设)
# encoder = Encoder(input_dim=10, output_dim=20)
# input_data = torch.randn(32, 100, 10) # 假设输入数据形状为[batch_size, max_length, input_dim]
# output_data = encoder(input_data) # 编码后的数据形状为[batch_size, max_length, output_dim]
我们基于双向长短期记忆网络(BiLSTM)开发了一个非常基础的文本编码器。理论上,可以使用任何功能强大的编码器(包括预训练的编码器),但我们选择使用BiLSTM,以便让示例保持轻量级。
class TextEncoder(Encoder):
"""
给定预测器x,这个神经网络参数化了随机变量Y在给定X=x的条件下的概率密度函数pdf。
换句话说,它预测条件分布P(Y|X=x)。
当reduce_mean为True时,前向传播将为每个文档返回一个单一的输出向量。
当reduce_mean为False时,将为文档中的每个词返回一个向量。
"""
def __init__(self, vocab_size: int, word_embed_dim: int, hidden_size: int, reduce_mean=False, pad_id=0, p_drop=0.):
super().__init__(2 * hidden_size) # 调用基类的构造函数,输出维度为2 * hidden_size
self.pad_id = pad_id # 填充标记的ID
self.word_embed_dim = word_embed_dim # 词嵌入的维度
self.hidden_size = hidden_size # LSTM隐藏层的维度
self.vocab_size = vocab_size # 词汇表的大小
self.word_embed = nn.Embedding(self.vocab_size, embedding_dim=word_embed_dim) # 词嵌入层
self.encoder = nn.LSTM(
input_size=word_embed_dim, # 输入尺寸为词嵌入的维度
hidden_size=hidden_size, # 隐藏层尺寸
num_layers=1, # 层数
batch_first=True, # 输入和输出张量的第一个维度为batch_size
bidirectional=True, # 使用双向LSTM
)
self.reduce_mean = reduce_mean # 是否使用平均池化
def forward(self, x):
"""
x: [batch_size, max_length] 形状的输入张量
"""
# 首先对token进行嵌入
# 形状变为 [batch_size, max_length, embed_dim]
h = self.word_embed(x)
# 通过LSTM编码器,形状变为 [batch_size, max_length, 2*hidden_size*num_layers]
h, _ = self.encoder(h)
if self.reduce_mean: # 如果使用平均池化
h = torch.where( # 将填充标记的位置置为0
(x == self.pad_id).unsqueeze(-1),
torch.zeros_like(h),
h
)
# 计算非填充标记的平均值
h = torch.sum(h, axis=-2) / torch.sum((x != self.pad_id).float(), -1, keepdims=True)
return h # 返回编码后的输出
在这个TextEncoder类中,我们定义了一个基于双向LSTM的文本编码器,它可以将输入文本编码为一个固定大小的向量。构造函数__init__中初始化了词嵌入层和LSTM层,并设置了是否使用平均池化参数reduce_mean。forward方法定义了前向传播的逻辑,它首先将文本转换为词嵌入,然后通过LSTM层进行编码,最后根据reduce_mean的设置决定是返回整个序列的平均值还是每个词的编码。如果设置了平均池化,它会将填充标记的值忽略,只对实际的词进行平均。
3.建立概率模型
概率模型为随机实验定义了概率度量。在文中,我们将通过神经网络(NNs)明确参数化概率密度函数(pdf)来设计模型。当我们的随机变量(rvs)是多元或具有特定结构时,我们将选择联合概率密度函数的因式分解,为每个因子决定统计族,并使用神经网络来参数化这些因子。
通常,我们会根据一些随机变量(通常是结构化的)的分配来建模某些随机变量(单变量、多变量、结构化)的分布 . Y X = x .YX=x .YX=x。
例如,输入可能是一段文本或一张图片。而响应变量可能是一个类别、一个数值测量结果、一组属性/测量值的向量、或者一个数据结构(如序列、树、图)。
对于我们来说,概率模型至少能够执行以下两个功能:
- 为给定的分配赋予概率密度
- 从给定的分布中采样一个分配
我们将使用PyTorch模块的forward方法
.
Y
=
y
X
=
x
Y
X
=
x
.Y=yX=xYX=x
.Y=yX=xYX=x来参数化相关的条件概率分布。
此外,我们偶尔还会支持其他操作,如寻找中位数、均值、众数等统计量。
class Model(nn.Module):
"""
概率模型预测随机实验的概率测度。
我们将预测在给定随机变量X=x的条件下,随机变量Y的条件分布。
作为建模机制,我们将使用概率质量函数(pmfs)和概率密度函数(pdfs),因此预测分布P(Y|X=x)需要从x映射到Y的pmf/pdf的参数,或者,在多变量/结构化数据的情况下,是我们决定其分解的联合pdf。
对我们来说,一个模型需要满足以下期望:
* 参数化pdf是可行的
* 给定结果Y=y|X=x时,评估pdf是可行的
* 从P(Y|X=x)中抽取样本是可行的
* pdf p(y|x)对于预测其参数的神经网络的参数是可微的
模型API中唯一固定的方面是:
* log_prob(x, y) -> 浮点数张量,每批一个值
* sample(x, sample_size) -> 样本批次
* forward(...) -> 一个torch.distribution对象
前向方法的签名在子类中可能会变化
"""
def __init__(self, event_shape=tuple()):
"""
event_shape是随机变量Y结果的形状。
"""
super().__init__() # 调用基类的构造函数
self._event_shape = event_shape # 存储事件形状
@property
def event_shape(self):
return self._event_shape # 只读属性,返回事件形状
def num_parameters(self):
"""
计算模型参数的总数。
"""
return sum(np.prod(theta.shape) for theta in self.parameters()) # 对所有参数求和
def forward(self, x):
"""
x: [batch_size, ...]
"""
raise NotImplementedError("每种模型将在这里有不同的实现")
def sample(self, x, sample_size=tuple()):
"""
x: [batch_size, ...]
从条件分布Y|X=x中返回一批样本。
"""
raise NotImplementedError("每种模型将在这里有不同的实现")
def log_prob(self, x, y):
"""
计算每对在批次中的Y=y|X=x的对数pdf。
x: batch_shape + event_shape_x
y: batch_shape + event_shape
"""
# 使用前向函数预测条件概率分布。
# 这将为每个批次元素返回一个概率分布。
cpds = self(x=x)
# 计算批次中每个元素的对数概率。
logp = cpds.log_prob(y) # [batch_size]
return logp # 返回对数概率
在这个Model类中,我们定义了一个概率模型的基础框架,它应该能够预测给定输入X条件下随机变量Y的分布。模型需要满足几个关键的条件,包括参数化pdf的可行性、评估给定结果的pdf的可行性、从分布中抽样的可行性,以及pdf对网络参数的可微性。
类中定义了几个关键的方法:
forward:需要子类实现,用于根据输入X预测条件分布。sample:需要子类实现,用于从条件分布中抽样。log_prob:计算给定输入和输出的对数概率,使用forward方法预测的条件分布。
event_shape属性定义了随机变量Y的结果形状,而num_parameters方法提供了计算模型参数总数的方式。
4. 参数估计
在参数估计的过程中,我们将采用最大似然估计(MLE)方法,通过基于梯度的搜索技术来实现。具体而言,我们需要基于给定的数据集(或数据批次)来评估模型的似然性。为了实现这一点,似然函数必须是易于处理的,并且相对于神经网络参数而言是可微分的。
def loss(self, x, y):
"""
无论概率模型是什么,损失函数都是对单个批次上的参数估计的负对数似然:
- 1/batch_size * ∑(log P(y[s]|x[s], theta))
x: batch_shape + event_shape_x
y: batch_shape + event_shape
"""
# 计算对数概率,取平均值,然后取负值得到损失值
return -self.log_prob(x=x, y=y).mean(0)
def distortion(model, dl, device):
"""
使用数据加载器中的所有数据点估计失真度的包装器。
model: 要评估的模型
dl: 数据加载器,包含数据批次
device: 用于执行计算的设备(例如CPU或GPU)
"""
total_log_prob = 0. # 总对数概率初始化为0
data_size = 0 # 数据大小初始化为0
with torch.no_grad(): # 不计算梯度,以节省内存和计算资源
for batch_x, batch_y in dl: # 遍历数据加载器中的每个批次
# 将批次数据移动到指定的设备上
total_log_prob += model.log_prob(batch_x.to(device), batch_y.to(device)).sum()
data_size += batch_x.shape[0] # 更新数据大小
return - total_log_prob / data_size # 返回平均对数概率的负值作为失真度
在loss函数中,我们计算了批次数据的平均负对数似然损失。这是概率模型常用的损失函数,用于衡量模型预测与实际观测数据之间的差异。
distortion函数是一个评估模型在整个数据集上性能的辅助函数。它通过在数据加载器dl中累积对数概率并将它们平均来计算失真度。使用torch.no_grad()上下文管理器可以避免计算和存储梯度,这在评估或推断时是有用的,因为它减少了内存消耗并提高了计算速度。函数返回的是整个数据集上的对数似然的负平均值,这可以作为模型性能的一个指标。
5. 决策规则
一个理性的决策者会选择行动以最大化预期效用。
让我们量化在真相为时选择行动的好处。在不确定性的情况下做决策时,我们需要解决以下问题:
u
(
y
,
c
)
c
∈
γ
y
u(y,c)c\in\gamma{y}
u(y,c)c∈γy
y
⋆
=
arg
max
c
∈
Y
E
[
u
(
Y
,
c
)
∣
X
=
x
]
\begin{align} y^\star &= \arg\max_{c \in \mathcal Y}~\mathbb E[u(Y, c)|X=x] \end{align}
y⋆=argc∈Ymax E[u(Y,c)∣X=x]
这里的期望是关于概率密度函数(pdf)的
p
Y
∣
X
=
x
p_{Y|X=x}
pY∣X=x。
对于某些效用函数和pdf组合,这个问题可以通过闭式解来解决。在很多情况下,这个决策问题没有现成的算法可以处理,那么就需要使用近似方法 u ( y , c ) = [ y = c ] u(y, c) = [y = c] u(y,c)=[y=c]。
当效用函数是(如果和相同,其值为1,否则为0)时,就对应于的众数。
在结构预测中,效用函数可能会奖励和之间的部分/结构相似性。例如,字符串的效用函数可能基于Levenshtein距离/相似度 . y c .yc .yc。
class DecisionRule:
"""
决策规则类,用于根据模型和输入数据以及预测的概率分布来确定单一结果。
"""
def __init__(self):
super().__init__() # 调用基类的构造函数
def __call__(self, model, x):
"""
该函数应将模型、输入和预测的概率分布映射到一个单一的结果。
"""
raise NotImplementedError("实现我!")
class ExactMode(DecisionRule):
"""
这种决策规则在假设概率分布是单峰或离散的情况下,返回预测概率分布下最可能的结果。
"""
def __call__(self, model, x):
# 返回模型在给定输入x下最可能的结果
return model.mode(x)
def predict(model, rule, dl, device, return_targets=False, strip_pad=True):
"""
使用决策规则进行预测的包装器。
model: 我们的标注器之一
dl: 用于保留数据的 DataLoader
device: 存储模型的 PyTorch 设备
return_targets: 也返回 DataLoader 中的目标
当数据加载器中包含实际目标时可以使用此选项(例如,对于开发集)
返回
* 一个预测列表,每个预测是一个标签序列(已经解码)
* 如果 return_targets=True,还会额外返回一个目标列表,每个目标是一个标签序列(已经解码)
"""
all_preds = [] # 存储所有预测结果
all_targets = [] # 存储所有目标结果
with torch.no_grad(): # 不计算梯度,节省内存和计算资源
for batch_x, batch_y in dl: # 遍历数据加载器中的每个批次
preds = rule(model, batch_x.to(device)) # 使用决策规则进行预测
all_preds.extend(preds.cpu().numpy()) # 将预测结果添加到列表,并转移到CPU,转换为NumPy数组
if return_targets: # 如果需要返回目标
all_targets.extend(batch_y.cpu().numpy()) # 将目标结果添加到列表,并转移到CPU,转换为NumPy数组
if return_targets: # 如果需要返回目标
return all_preds, all_targets # 返回预测结果和目标结果
else:
return all_preds # 只返回预测结果
在这段代码中,DecisionRule类是一个抽象基类,用于定义决策规则的接口。ExactMode类是DecisionRule的一个具体实现,它使用模型预测的单峰或离散概率分布中最可能的结果作为决策结果。
predict函数是一个通用的预测函数,它接受一个模型、决策规则、数据加载器、设备以及一些可选参数。该函数遍历数据加载器中的所有批次,使用模型和决策规则进行预测,并将结果存储在列表中。如果指定了return_targets,则还会返回目标标签的列表。使用torch.no_grad()可以提高评估时的效率,因为它会告诉PyTorch不要跟踪梯度。
6. 典型的训练过程
不论采用何种模型,训练过程都是一致的。因此,我们为您概述了一个通用的训练过程框架。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.distributions as td
import torch.optim as opt
from tqdm.notebook import tqdm
import matplotlib.pyplot as plt
from sklearn.metrics import classification_report, mean_squared_error, mean_absolute_error, median_absolute_error
from collections import defaultdict
from itertools import chain
def flatten(seq):
"""将Python列表展平"""
return list(chain.from_iterable(seq))
def report_regression(y_true, y_pred):
"""回归任务的性能报告,包括均方误差(MSE)、平均绝对误差(MAE)和中位绝对误差(MdAE)"""
return {
"MSE": mean_squared_error(y_true, y_pred),
"MAE": mean_absolute_error(y_true, y_pred),
"MdAE": median_absolute_error(y_true, y_pred)
}
def report_classification(y_true, y_pred):
"""分类任务的性能报告,返回一个包含各种分类指标的字典"""
return classification_report(y_true, y_pred, output_dict=True, zero_division=0)
def report_tagging(y_true, y_pred, score_pad=False, pad_id=0):
"""标记任务的性能报告,可以选择是否忽略填充标记(pad_id)"""
if not score_pad:
# 过滤掉填充标记
pairs = [(t, p) for t, p in zip(flatten(y_true), flatten(y_pred)) if t != pad_id]
y_true = [t for t, p in pairs]
y_pred = [p for t, p in pairs]
return classification_report(y_true, y_pred, output_dict=True, zero_division=0)
def train_neural_model(model: Model, optimiser, decision_rule: DecisionRule,
training_data, dev_data,
batch_size=200, num_epochs=10, check_every=10,
report_fn=None, report_metrics=[],
device=torch.device('cuda:0')
):
"""
训练神经网络模型的函数。
model: PyTorch模型
optimiser: PyTorch优化器
training_data: 用于训练的TaggedCorpus
dev_data: 用于开发的TaggedCorpus
batch_size: 批量大小,如果内存足够可以增大
num_epochs: 迭代次数,增加可以改善收敛性
check_every: 在开发集上检查性能的频率
device: 运行实验的设备
report_fn: 用于生成报告的函数
report_metrics: 要记录的指标列表
返回训练期间计算的数量的日志(用于绘图)
"""
# 使用随机顺序的数据进行参数估计
batcher = DataLoader(training_data, batch_size=batch_size, shuffle=True, collate_fn=training_data.pad_to_longest)
# 开发数据用于训练过程中的评估(这里不需要随机化)
dev_batcher = DataLoader(dev_data, batch_size=batch_size, shuffle=False, collate_fn=dev_data.pad_to_longest)
total_steps = num_epochs * len(batcher)
log = defaultdict(list)
model.eval()
# 计算开发集上的失真度
log['D'].append(distortion(model, dev_batcher, device=device).item())
# 如果提供了报告函数,则生成报告
if report_fn:
preds, targets = predict(
model,
decision_rule,
dev_batcher,
device=device,
return_targets=True
)
report = report_fn(targets, preds)
for metric in report_metrics:
log[metric].append(report[metric])
step = 0
with tqdm(range(total_steps)) as bar: # 使用tqdm显示进度条
for epoch in range(num_epochs): # 遍历每个epoch
for batch_x, batch_y in batcher: # 遍历每个批次
model.train() # 设置模型为训练模式
optimiser.zero_grad() # 清空梯度
# 计算损失
L = loss(model, batch_x.to(device), batch_y.to(device))
L.backward() # 反向传播
optimiser.step() # 更新参数
# 更新进度条
bar_dict = OrderedDict()
bar_dict['loss'] = f"{L.item():.2f}"
bar_dict['D'] = f"{log['D'][-1]:.2f}"
for metric in report_metrics:
bar_dict[metric] = "{:.2f}".format(log[metric][-1])
bar.set_postfix(bar_dict)
bar.update()
log['loss'].append(L.item()) # 记录损失
# 定期在开发集上检查性能
if step % check_every == 0:
model.eval() # 设置模型为评估模式
log['D'].append(distortion(model, dev_batcher, device=device).item())
if report_fn:
preds, targets = predict(
model,
decision_rule,
dev_batcher,
device=device,
return_targets=True
)
report = report_fn(targets, preds)
for metric in report_metrics:
log[metric].append(report[metric])
step += 1
model.eval() # 设置模型为评估模式
log['D'].append(distortion(model, dev_batcher, device=device).item())
# 如果提供了报告函数,则再次生成报告
if report_fn:
preds, targets = predict(
model,
decision_rule,
dev_batcher,
device=device,
return_targets=True
)
report = report_fn(targets, preds)
for metric in report_metrics:
log[metric].append(report[metric])
return log # 返回训练日志
这段代码定义了一系列函数,用于训练和评估神经网络模型。flatten函数用于展平列表,report_*函数用于生成回归或分类任务的性能报告。train_neural_model函数是核心的训练函数,它接受模型、优化器、决策规则、训练数据、开发数据和其他训练参数,执行模型的训练并在每个epoch结束时在开发集上评估模型性能。使用tqdm库显示训练进度,并通过DataLoader对数据进行批量处理。loss函数和distortion函数分别用于计算损失和失真度,这两个函数需要在其他地方定义。最后,predict函数用于生成预测结果。
7. 文本分类实践
7.1 分类响应变量
我们将设计一个概率模型,该模型能够根据给定的文档 d 预测一个分类响应变量:
Y
x
Yx
Yx
Y
∣
X
=
x
∼
C
a
t
e
g
o
r
i
c
a
l
(
g
(
x
;
θ
)
)
u
=
e
n
c
o
d
e
D
(
x
;
θ
enc
)
s
=
a
f
f
i
n
e
C
(
u
;
θ
out
)
g
(
x
;
θ
)
=
s
o
f
t
m
a
x
(
s
)
\begin{align} Y|X=x &\sim \mathrm{Categorical}(\mathbf g(x; \theta)) \\ \mathbf u &= \mathrm{encode}_D(x; \theta_{\text{enc}}) \\ \mathbf s &= \mathrm{affine}_C(\mathbf u; \theta_{\text{out}}) \\ \mathbf g(x; \theta) &= \mathrm{softmax}(\mathbf s) \end{align}
Y∣X=xusg(x;θ)∼Categorical(g(x;θ))=encodeD(x;θenc)=affineC(u;θout)=softmax(s)
7.1.1 建立模型
class CategoricalModel(Model):
"""
给定预测器x,这个神经网络参数化了在给定X=x的条件下随机变量Y的概率密度函数pdf,
其中Y符合多项分布。
换句话说,它预测条件分布P(Y|X=x)。
"""
def __init__(self, support_size, hidden_size: int, encoder: Encoder, p_drop=0.):
super().__init__(tuple()) # 调用基类的构造函数,不关心事件形状
self.encoder = encoder # 文本编码器
self.support_size = support_size # 分布的支持大小(即类别数量)
self.hidden_size = hidden_size # 隐藏层的尺寸
# 我们有一个简单的神经网络,它将文本编码映射到多项分布的对数几率(logits)。
self.logits_predictor = nn.Sequential(
nn.Dropout(p_drop), # 防止过拟合的dropout层
nn.Linear(encoder.output_dim, hidden_size), # 线性层,从编码器输出维度到隐藏层
nn.ReLU(), # 激活函数
nn.Dropout(p_drop), # 另一层dropout
nn.Linear(hidden_size, support_size) # 最终的线性层,从隐藏层到支持大小
)
def forward(self, x):
# 首先对token进行编码
h = self.encoder(x) # 编码后的输出形状为(batch_shape, (enc_dim,))
# 使用对数几率预测网络将编码转换为logits
logits = self.logits_predictor(h) # logits的形状为(batch_shape, (support_size,))
# 返回一个Categorical分布,其参数为预测的logits
return td.Categorical(logits=logits)
def sample(self, x, sample_size=tuple()):
with torch.no_grad(): # 不计算梯度,节省内存和计算资源
cpd = self(x=x) # 获得条件概率分布
return cpd.sample(sample_size) # 从分布中采样
def mode(self, x):
with torch.no_grad(): # 不计算梯度
# 预测P(Y|X=x)的多项分布
cpd = self(x=x)
# 通过在logits上取argmax,我们可以轻松地获得确切的模式(众数)
mode = torch.argmax(cpd.logits, -1)
return mode # 返回模式
在这个CategoricalModel类中,我们定义了一个多项分布模型,它基于给定的输入x(例如文本数据)预测随机变量Y的条件概率分布。模型使用一个编码器(encoder)来将输入数据编码为一个连续的向量表示,然后通过一个简单的前馈神经网络(logits_predictor)将这些编码转换为多项分布的logits。forward方法返回一个参数化为这些logits的多项分布。
sample方法用于从预测的条件概率分布中采样,而mode方法用于找到分布的最可能结果,即logits最大值对应的类别。这些方法使用torch.no_grad()上下文管理器来禁用梯度计算,这在推断或评估时是常见的做法,因为它减少了内存消耗并提高了计算速度。
7.1.2.训练并评估模型
为了验证我们实现的正确性,我们将对随机初始化的文本编码器和分类模型进行一次前向传播(forward pass)测试。
# 创建一个文本编码器实例,参数包括词汇表大小、词嵌入维度、隐藏层大小以及是否使用均值池化
encoder = TextEncoder(len(word_vocab), 7, 5, True)
# 基于编码器创建一个多项分布模型实例,支持大小为3,隐藏层大小为12
cat_model = CategoricalModel(3, 12, encoder)
# 假设batcher是一个DataLoader实例,用于生成训练数据的批次
for batch_x, batch_y in batcher:
print(batch_x.shape) # 打印批次数据的形状
print(cat_model(batch_x).logits) # 打印模型预测的logits,这是多项分布的参数
# 以下代码在实际训练循环中不会执行,因为它们在循环中没有逻辑上的结束
break
# 假设cat_vocab是之前创建的词汇表,这里打印其大小
cat_vocab = Vocab(cat_training_x, min_freq=2)
print(len(cat_vocab))
# 下面是模型训练的代码,首先重置随机数生成器的种子
seed_all()
# 使用GPU加速,如果GPU可用
my_device = torch.device('cuda:0')
# 创建模型,支持大小为类别数,隐藏层大小为32
model = CategoricalModel(
support_size=len(brown.categories()),
hidden_size=32,
encoder=TextEncoder(
vocab_size=len(cat_vocab),
word_embed_dim=100,
hidden_size=64,
reduce_mean=True,
pad_id=cat_vocab.pad_id
),
p_drop=0.1
).to(my_device)
# 构建Adam优化器
optimiser = opt.Adam(model.parameters(), lr=5e-3)
# 打印模型结构和参数数量
print("Model")
print(model)
print(f"Model size: {model.num_parameters():,} parameters")
# 训练模型
log = train_neural_model(
model, optimiser,
decision_rule=ExactMode(),
training_data=TextRegressionCorpus(cat_training_x, cat_training_y, cat_vocab),
dev_data=TextRegressionCorpus(cat_dev_x, cat_dev_y, cat_vocab),
report_fn=report_classification,
report_metrics=['accuracy'],
batch_size=500, num_epochs=20, check_every=100,
device=my_device
)
# 绘制训练损失和验证指标
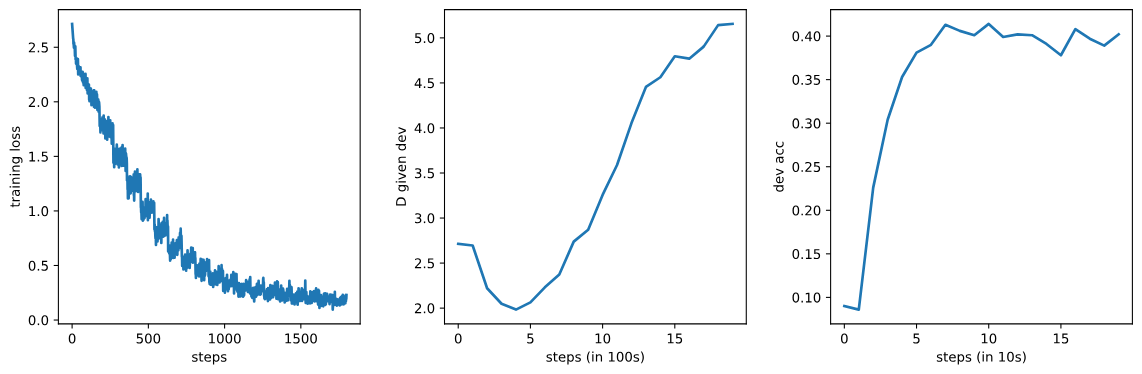
fig, axs = plt.subplots(1, 3, sharey=False, figsize=(12, 4))
_ = axs[0].plot(np.arange(len(log['loss'])), log['loss'])
_ = axs[0].set_xlabel('steps')
_ = axs[0].set_ylabel('training loss')
_ = axs[1].plot(np.arange(len(log['D'])), log['D'])
_ = axs[1].set_xlabel('steps (in 100s)')
_ = axs[1].set_ylabel('D given dev')
_ = axs[2].plot(np.arange(len(log['accuracy'])), log['accuracy'])
_ = axs[2].set_xlabel('steps (in 10s)')
_ = axs[2].set_ylabel('dev acc')
_ = fig.tight_layout(h_pad=2, w_pad=2)
plt.show()
代码片段展示了如何使用PyTorch框架来创建、配置和训练一个基于多项分布的分类模型。
-
文本编码器实例化:
TextEncoder类的实例encoder被创建,用于将文本数据编码为连续的向量表示。这个类可能是之前定义的,用于文本的嵌入表示。
-
分类模型实例化:
CategoricalModel类的实例cat_model被创建,表示一个多项分布模型,用于分类任务。这个模型接受来自编码器的输出,并预测分类的概率分布。
-
批次数据处理:
- 代码中存在一个假设的循环,用于处理
batcher生成的数据批次。batcher可能是一个DataLoader对象,用于批量加载数据。循环中打印了批次数据的形状和模型预测的logits。
- 代码中存在一个假设的循环,用于处理
-
词汇表创建:
cat_vocab是使用训练数据cat_training_x创建的词汇表,用于将文本数据中的单词转换为整数ID。
-
模型训练设置:
- 重置随机数生成器的种子以确保结果的可重复性。
- 设置设备为GPU(如果可用)以加速训练过程。
-
模型创建:
- 创建
CategoricalModel的具体实例,包括定义类别数量、隐藏层大小、编码器配置和dropout比例。
- 创建
-
优化器配置:
- 使用Adam优化器来更新模型的参数,设置学习率为5e-3。
-
模型参数报告:
- 打印模型的概述和参数数量,以了解模型的规模。
-
模型训练:
- 使用
train_neural_model函数训练模型,该函数执行模型的训练循环,并在每个epoch结束时在开发集上评估模型性能。训练函数接受模型、优化器、决策规则、训练和开发数据集、报告函数、要报告的指标列表、批量大小、epoch数量和检查频率等参数。
- 使用
-
结果可视化:
- 使用Matplotlib库绘制训练损失、验证失真度(D值)和开发集准确率,以监控模型训练过程中的性能变化。
Model
CategoricalModel(
(encoder): TextEncoder(
(word_embed): Embedding(22734, 100)
(encoder): LSTM(100, 64, batch_first=True, bidirectional=True)
)
(logits_predictor): Sequential(
(0): Dropout(p=0.1, inplace=False)
(1): Linear(in_features=128, out_features=32, bias=True)
(2): ReLU()
(3): Dropout(p=0.1, inplace=False)
(4): Linear(in_features=32, out_features=15, bias=True)
)
)
Model size: 2,363,015 parameters
7.1.3.推理预测
# 设置测试数据的DataLoader
cat_test_corpus = TextRegressionCorpus(cat_test_x, cat_test_y, cat_vocab)
cat_test_dl = DataLoader(cat_test_corpus, batch_size=3, shuffle=True, collate_fn=cat_test_corpus.pad_to_longest)
batch_x, batch_y = next(iter(cat_test_dl))
# 使用众数作为决策规则来形成预测。
decision_rule = ExactMode()
predictions = decision_rule(model, batch_x.to(my_device))
# 打印输入文本、预测结果和实际结果
for x, pred, truth in zip(batch_x, batch_y, predictions):
print(f"input: {' '.join(cat_vocab.decode(x, strip_pad=True))}")
print(f"prediction: {brown.categories()[pred]}")
print(f"truth: {brown.categories()[truth]}")
print()
# 可视化预测的多项分布,并可以用于采样或输入到任意决策规则。
import seaborn as sns
import pandas as pd
with torch.no_grad(): # 不计算梯度
batch_x, batch_y = next(iter(cat_test_dl))
cpds = model(batch_x.to(my_device)) # 获取条件概率分布
fig, axes = plt.subplots(3, 1, figsize=(15, 10))
for ax, x, y, predicted_probs in zip(axes, batch_x, batch_y, cpds.probs):
# 绘制每个类别的预测概率条形图
sns.barplot(data=pd.DataFrame({"category": brown.categories(), "prob": predicted_probs.cpu()}),
x="category", y="prob", ax=ax)
ax.set_title(f"{' '.join(cat_vocab.decode(x, strip_pad=True))}, truth = {brown.categories()[y]}")
plt.tight_layout() # 调整子图布局以避免重叠
plt.show() # 显示图表
代码演示了如何使用训练好的分类模型进行测试数据的预测和可视化。
-
测试数据加载器设置:
- 使用
TextRegressionCorpus类创建测试数据集的实例cat_test_corpus,它将测试数据cat_test_x和cat_test_y与词汇表cat_vocab结合起来。 DataLoader对象cat_test_dl被创建用于批量加载测试数据,设置批量大小为3,并使用随机打乱。
- 使用
-
获取测试数据批次:
- 使用
iter函数和next函数从测试数据加载器中获取一个批次的数据batch_x和batch_y。
- 使用
-
使用模型进行预测:
ExactMode决策规则用于根据模型预测的概率分布形成预测结果。这里,它通过取概率最高的类别作为预测结果。
-
打印预测结果:
- 循环遍历输入文本、预测结果和实际结果,打印原始文本、预测的类别和实际的类别。
-
可视化预测的概率分布:
- 使用
seaborn和pandas库在图表中可视化每个类别的预测概率。
- 使用
-
绘制条形图:
- 对于测试批次中的每个样本,绘制一个条形图,显示每个类别的预测概率,并设置图表标题显示输入文本和实际类别。

- 对于测试批次中的每个样本,绘制一个条形图,显示每个类别的预测概率,并设置图表标题显示输入文本和实际类别。
7.2 泊松分布
在这里,我们为给定的文档设计一个有序响应变量的概率模型,我们选择使用泊松概率质量函数(pmf)来建模:
Y
x
Yx
Yx
Y
∣
X
=
x
∼
P
o
i
s
s
o
n
(
g
(
x
;
θ
)
)
u
=
e
n
c
o
d
e
D
(
x
;
θ
enc
)
s
=
a
f
f
i
n
e
1
(
u
;
θ
out
)
g
(
x
;
θ
)
=
s
o
f
t
p
l
u
s
(
s
)
\begin{align} Y|X=x &\sim \mathrm{Poisson}(g(x; \theta)) \\ \mathbf u &= \mathrm{encode}_D(x; \theta_{\text{enc}}) \\ s &= \mathrm{affine}_1(\mathbf u; \theta_{\text{out}}) \\ g(x; \theta) &= \mathrm{softplus}(s) \end{align}
Y∣X=xusg(x;θ)∼Poisson(g(x;θ))=encodeD(x;θenc)=affine1(u;θout)=softplus(s)
泊松率参数必须严格为正,因此我们使用softplus函数作为输出。
class PoissonModel(Model):
"""
该模型预测序数数据的条件泊松分布 Y|X=x。
"""
# ... [类定义的其余部分] ...
# 训练泊松模型的代码
# 构造词汇表
blog_vocab = Vocab(blog_training_x, min_freq=2)
print(f"词汇表中共有 {len(blog_vocab):,} 个词。")
# 重置随机种子
seed_all()
# 使用GPU加速
my_device = torch.device('cuda:0')
# 创建模型,预测泊松分布
model = PoissonModel(
hidden_size=32,
encoder=TextEncoder(
vocab_size=len(blog_vocab),
word_embed_dim=100,
hidden_size=64,
reduce_mean=True,
pad_id=blog_vocab.pad_id
),
p_drop=0.1
).to(my_device)
# 构建Adam优化器
optimiser = opt.Adam(model.parameters(), lr=5e-3)
# 打印模型结构和参数数量
print("模型")
print(model)
print(f"模型大小:{model.num_parameters():,} 个参数")
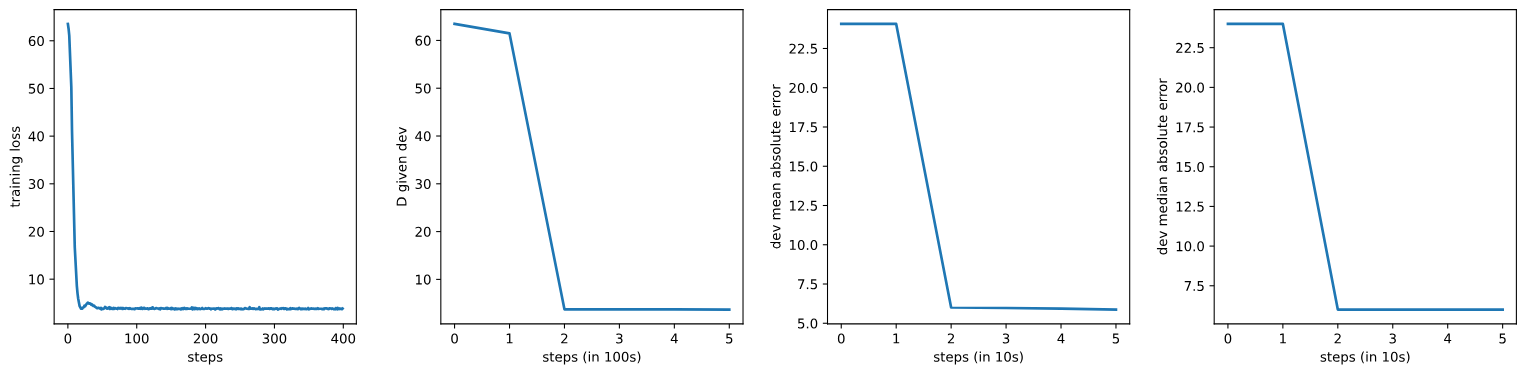
# 训练模型
log = train_neural_model(
# ... [训练函数的参数] ...
)
# 绘制训练损失和验证指标
# ... [绘图代码] ...
plt.show()
代码定义了一个基于泊松分布的条件概率模型,用于序数数据,并通过训练过程调整模型参数。
-
泊松模型类定义 (
PoissonModel):- 继承自
Model类,用于预测给定序数数据X=x的条件下的泊松分布Y|X=x。 - 初始化方法中,创建了一个神经网络
rate_predictor,用于从文本编码映射到泊松分布的速率参数。速率参数通过Softplus激活函数确保为正数。
- 继承自
-
模型训练前的准备:
- 使用
Vocab类创建词汇表blog_vocab,用于处理训练数据blog_training_x。 - 重置随机种子以确保结果的可重复性(
seed_all函数)。 - 设置设备为GPU以加速训练过程。
- 使用
-
模型创建:
- 创建
PoissonModel实例,配置隐藏层大小、编码器(TextEncoder)和dropout比例。 - 将模型移动到配置的设备上(GPU或CPU)。
- 创建
-
优化器配置:
- 使用Adam优化器来更新模型参数,设置学习率。
-
模型概览和参数报告:
- 打印模型结构和参数数量。
-
模型训练:
- 使用
train_neural_model函数训练模型,传入模型、优化器、决策规则、训练和验证数据集、回归报告函数、回归指标等参数。 - 训练过程中定期在验证集上评估模型性能,并记录训练损失和其他指标。
- 使用
-
结果可视化:
- 使用Matplotlib库绘制训练损失、验证失真度(D值)、平均绝对误差(MAE)和中位绝对误差(MdAE)。
代码中省略了部分函数和类的实现细节,例如 Vocab、TextEncoder、train_neural_model、seed_all 以及数据集 blog_training_x、blog_training_y 等。这些可能是特定于项目的实现或数据集。
22,734 words in the vocabulary.
Model
PoissonModel(
(encoder): TextEncoder(
(word_embed): Embedding(83532, 100)
(encoder): LSTM(100, 64, batch_first=True, bidirectional=True)
)
(rate_predictor): Sequential(
(0): Dropout(p=0.1, inplace=False)
(1): Linear(in_features=128, out_features=32, bias=True)
(2): ReLU()
(3): Dropout(p=0.1, inplace=False)
(4): Linear(in_features=32, out_features=1, bias=True)
(5): Softplus(beta=1, threshold=20)
)
)
Model size: 8,442,353 parameters
# 设置测试数据的DataLoader
blog_test_corpus = TextRegressionCorpus(blog_test_x, blog_test_y, blog_vocab)
blog_test_dl = DataLoader(blog_test_corpus, batch_size=3, shuffle=True, collate_fn=blog_test_corpus.pad_to_longest)
batch_x, batch_y = next(iter(blog_test_dl))
# 使用众数作为决策规则来形成预测
decision_rule = ExactMode()
predictions = decision_rule(model, batch_x.to(my_device))
# 打印输入文本、预测结果和实际结果
for x, pred, truth in zip(batch_x, batch_y, predictions):
print(f"input: {' '.join(blog_vocab.decode(x, strip_pad=True))}")
print(f"prediction: {pred.item()}")
print(f"truth: {truth.item()}")
print()
# 可视化预测的条件泊松分布的pmf
with torch.no_grad():
batch_x, batch_y = next(iter(blog_test_dl))
cpds = model(batch_x.to(my_device))
mode = model.mode(batch_x.to(my_device))
# 准备用于绘制pmf的x轴数据
x = torch.arange(0, 50).repeat(3, 1)
# 计算pmf
pmf = cpds.log_prob(x.to(my_device)).exp()
# 创建图形和坐标轴
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
for i in range(3):
# 绘制pmf曲线
axes[i].plot(x[i].cpu(), pmf[i].cpu().numpy(), ls='-.', color='b', label='pmf')
# 绘制预测模式的垂直线
axes[i].axvline(mode[i].cpu().numpy(), ls="--", color='b', label='mode')
# 绘制实际年龄的垂直线
axes[i].axvline(batch_y[i].numpy(), color='r', ls='--', label='truth')
axes[i].set_xlabel("年龄")
axes[i].set_ylabel("概率质量")
axes[i].set_title(f"{' '.join(blog_vocab.decode(batch_x[i], strip_pad=True))[:40]}...")
axes[i].legend()
plt.tight_layout()
plt.show()
代码演示了如何使用训练好的泊松回归模型对测试数据进行预测,并可视化预测的概率质量函数(Probability Mass Function, pmf)。
-
测试数据加载器设置:
- 创建
TextRegressionCorpus类的实例blog_test_corpus,用于处理测试数据blog_test_x和blog_test_y,以及词汇表blog_vocab。 DataLoader对象blog_test_dl被创建用于批量加载测试数据,设置批量大小为3,并使用随机打乱。
- 创建
-
获取测试数据批次:
- 使用
iter函数和next函数从测试数据加载器中获取一个批次的数据batch_x和batch_y。
- 使用
-
使用模型进行预测:
ExactMode决策规则用于根据模型预测的泊松分布形成预测结果。这里,它通过取分布的模式(rate的下取整)作为预测结果。
-
打印预测结果:
- 循环遍历输入文本、预测结果和实际结果,打印原始文本、预测的年龄和实际的年龄。
-
可视化预测的泊松分布:
- 使用
torch.no_grad()上下文管理器来禁用梯度计算,以便于进行推断或评估。 - 计算预测的泊松分布的pmf,并使用
matplotlib库绘制其图形。 - 同时在图中标记了预测的模式和实际的年龄值。
- 使用
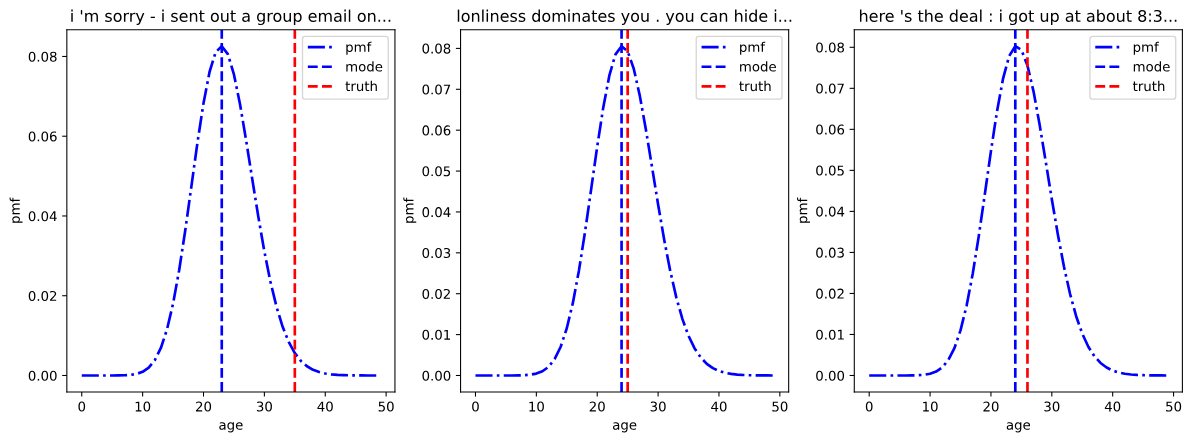
7.3 序列标注
在序列标注任务中,我们处理的是两个等长的序列:一个词序列和一个标签序列。 X 1 : l y 1 : l X_{1:l}y_{1:l} X1:ly1:l
词序列(w_1, ..., w_n)由序列长度n个词标记组成,每个词标记都属于一个已知的词汇表。
x
1
:
l
=
⟨
x
1
,
…
,
x
l
⟩
l
x
i
W
V
x_{1:l} = \langle x_1, \ldots, x_l \rangle{lx_i}\mathcal W\mathcal V
x1:l=⟨x1,…,xl⟩lxiWV
标签序列(t_1, ..., t_n)与词序列w具有相同的长度,每个标签都属于一个已知的标签集合。
y
1
:
l
=
⟨
y
1
,
…
,
y
l
⟩
x
1
:
l
y
i
T
y_{1:l} = \langle y_1, \ldots, y_l \rangle{x_{1:l}}y_i\mathcal T
y1:l=⟨y1,…,yl⟩x1:lyiT
我们的模型始终是概率分布,但这次我们需要一个能够描述序列空间的分布。由于序列的长度是可变的,它不能简单地被视为一个固定维度的向量(多元随机变量)。相反,序列最好被视为一种数据结构。为了为这种数据结构指定一个分布,我们可以将其分解成更小的部分,为每个部分指定分布,并使用链式法则将它们组合成一个统一的概率密度函数(pdf)。
链式法则允许我们将一个复杂的概率分布(具有多元或结构化结果)分解为一系列简单的概率分布的乘积,每个简单分布都定义在更简单的空间上(例如,只包含单一结果):
p
(
y
1
:
l
∣
x
1
:
l
,
θ
)
=
∏
i
=
1
l
p
(
y
i
∣
x
1
:
l
,
y
1
i
−
1
,
θ
)
=
∏
i
=
1
l
C
a
t
e
g
o
r
i
c
a
l
(
y
i
∣
g
(
x
1
:
l
,
y
1
i
−
1
;
θ
)
)
\begin{align} p(y_{1:l}|x_{1:l}, \theta) &= \prod_{i=1}^l p(y_i|x_{1:l}, y_1^{i-1}, \theta) \\ &= \prod_{i=1}^l \mathrm{Categorical}(y_i|\mathbf g(x_{1:l}, y_1^{i-1}; \theta)) \end{align}
p(y1:l∣x1:l,θ)=i=1∏lp(yi∣x1:l,y1i−1,θ)=i=1∏lCategorical(yi∣g(x1:l,y1i−1;θ))
class Tagger(Model):
"""
标注器模型,用于序列标注任务,如词性标注或命名实体识别。
"""
def __init__(self, vocab_size: int, tagset_size: int, pad_id=0, bos_id=1, eos_id=2):
super().__init__()
# 词汇表大小
self._vocab_size = vocab_size
# 标签集大小
self._tagset_size = tagset_size
# 填充标记的ID
self._pad = pad_id
# 序列开始标记的ID
self._bos = bos_id
# 序列结束标记的ID
self._eos = eos_id
# 以下是一系列的属性,提供对初始化参数的只读访问
@property
def vocab_size(self):
return self._vocab_size
@property
def tagset_size(self):
return self._tagset_size
@property
def pad(self):
return self._pad
@property
def bos(self):
return self._bos
@property
def eos(self):
return self._eos
def num_parameters(self):
"""
计算模型参数的总数。
"""
return sum(np.prod(theta.shape) for theta in self.parameters())
def forward(self, x, y_in):
"""
前向传播方法,预测给定输入x和部分标签序列y_in的标签分布。
x: 输入序列,形状为[批量大小, 最大长度]
y_in: 已给定的标签序列,形状为[批量大小, 最大长度]
返回:每一步的cpd(概率分布)批次。
"""
raise NotImplementedError("每种标注器的实现将有所不同")
def log_prob(self, x, y):
"""
计算一个批次中每个标签序列的条件对数概率。
x: 输入序列,形状为[批量大小, 最大长度]
y: 标签序列,形状为[批量大小, 最大长度]
"""
# 将输出序列平移并添加BOS代码
batch_size, max_len = y.shape
bos = torch.full((batch_size, 1), self.bos, device=y.device)
y_in = torch.cat([bos, y], 1)[:,:-1]
# 对每个批次中的每个标记,计算一个C维的多项分布cpd
cpds = self(x=x, y_in=y_in)
# 计算对数概率
logp = cpds.log_prob(y)
# 忽略填充标记的对数概率,并按批次求和
logp = torch.where(y != self.pad, logp, torch.zeros_like(logp)).sum(-1)
return logp
def greedy(self, x):
"""
贪婪解码,对于每个条件概率分布Y[i]|X=x,预测其模式(众数)。
x: 输入序列,形状为[批量大小, 最大长度]
返回:标签序列,形状为[批量大小, 最大长度]
"""
raise NotImplementedError("每种标注器的实现将有所不同")
def sample(self, x, sample_size=tuple()):
"""
对于批次中的每个词序列,从模型中抽取一定数量的样本,每个样本是完整的标签序列。
x: 输入序列,形状为[批量大小, 最大长度]
返回:如果sample_size为None,则形状为[批量大小, 最大长度]的标签序列
否则形状为[sample_size, 批量大小, 最大长度]
"""
raise NotImplementedError("每种标注器的实现将有所不同")
# 创建词汇表
word_vocab = Vocab(tagger_training_x, min_freq=2) # 词的词汇表
tag_vocab = Vocab(tagger_training_y, min_freq=1) # 标签的词汇表
# 打印词汇表大小
print(f"词词汇表大小: {len(word_vocab)}, 标签集大小: {len(tag_vocab)}")
代码实现了以下功能:
Tagger类继承自Model类,是一个用于序列标注任务的模型框架。- 类的构造函数接收词汇表大小、标签集大小以及特殊标记的ID,并设置为实例变量。
num_parameters方法用于统计模型的参数总数。forward方法是一个抽象方法,应该在子类中实现,用于计算给定输入x和部分标签序列y_in的条件概率分布。log_prob方法计算一个批次中每个标签序列的条件对数概率,它使用forward方法获得概率分布,并计算对数概率总和,忽略填充标记。greedy方法是一个抽象方法,用于贪婪解码,即对于每一步的条件概率分布,选择最可能的标签。sample方法是一个抽象方法,用于从模型中采样,生成完整的标签序列样本。
在第一等式的右侧,我们为每个序列步骤指定了概率密度函数(pdf)或概率质量函数(pmf)。具体来说,在第二个序列中,由于每个步骤都是一个分类变量,我们采用了分类概率质量函数(Categorical pmf)。这些pmf通过具有参数θ的可训练函数在上下文中进行参数化。
g
θ
g\theta
gθ
上述是对联合pdf的因式分解。这种因式分解是有效的,并且它并没有引入任何条件独立性假设(即,它依赖于整个已生成的序列结构)。然而,通过引入条件独立性(或马尔可夫)假设,我们可以简化这种因式分解。例如,在参数化t_i的分布时,我们可能仅依赖于当前词w_i和前一个标签t_{i-1}。这些假设的合理性取决于具体的应用场景。
X
1
:
l
y
1
:
l
Y
i
X_{1:l}y_{1:l}Y_i
X1:ly1:lYi
7.3.1 独立的C类分类器
我们的第一个标注器模型实际上是一个C类分类器,它基于整个输入序列X的条件来预测输入序列中不同位置上的标签分布。
C
C
CC
CC
给定输入序列
x
1
:
l
x_{1:l}
x1:l,第l个标签t_l的预测模型可以表示为:
Y
i
∣
S
=
x
1
:
l
∼
C
a
t
e
g
o
r
i
c
a
l
(
g
(
i
,
x
1
:
l
;
θ
)
)
\begin{align} Y_i | S=x_{1:l} &\sim \mathrm{Categorical}(\mathbf g(i, x_{1:l}; \theta)) \end{align}
Yi∣S=x1:l∼Categorical(g(i,x1:l;θ))
例如
e
j
=
e
m
b
e
d
D
(
x
j
;
θ
in
)
j
∈
{
1
,
…
,
l
}
u
1
:
l
=
b
i
r
n
n
2
K
(
e
1
:
l
;
θ
bienc
)
s
i
=
a
f
f
i
n
e
C
(
u
i
;
θ
out
)
g
(
i
,
x
1
:
l
)
=
s
o
f
t
m
a
x
(
s
i
)
\begin{align} \mathbf e_j &= \mathrm{embed}_D(x_j; \theta_{\text{in}}) & j \in \{1, \ldots, l\}\\ \mathbf u_{1:l} &= \mathrm{birnn}_{2K}(\mathbf e_{1:l}; \theta_{\text{bienc}})\\ \mathbf s_i &= \mathrm{affine}_C(\mathbf u_i; \theta_{\text{out}})\\ \mathbf g(i, x_{1:l}) &= \mathrm{softmax}(\mathbf s_i) \end{align}
eju1:lsig(i,x1:l)=embedD(xj;θin)=birnn2K(e1:l;θbienc)=affineC(ui;θout)=softmax(si)j∈{1,…,l}
其中NN是一个神经网络,例如可以包含一个双向RNN(循环神经网络)层。双向RNN层通过将两个独立的RNN层的状态进行拼接来实现,一个RNN层从左到右处理序列,另一个RNN层从右到左处理序列。
值得注意的是,这个模型在预测每个标签时忽略了序列中的其他所有标签,即它假设标签之间是相互独立的。
class BasicTagger(Tagger):
"""
基本的序列标注器实现,使用一个TextEncoder编码器和一个线性层来预测每个词的标签分布。
"""
def __init__(self, vocab_size, tagset_size, word_embed_dim: int, hidden_size: int, p_drop=0, pad_id=0, bos_id=1, eos_id=2):
"""
初始化方法,设置词汇表大小、标签集大小、词嵌入维度、隐藏层维度等参数。
"""
super().__init__(vocab_size=vocab_size, tagset_size=tagset_size, pad_id=pad_id, bos_id=bos_id, eos_id=eos_id)
# 词嵌入维度
self.word_embed_dim = word_embed_dim
# 隐藏层维度
self.hidden_size = hidden_size
# 文本编码器,用于将输入序列编码为连续向量
self.encoder = TextEncoder(
vocab_size=vocab_size,
word_embed_dim=word_embed_dim,
hidden_size=hidden_size,
reduce_mean=False,
pad_id=pad_id,
p_drop=p_drop
)
# 线性层,用于将编码器的输出映射到标签集上
self.logits_predictor = nn.Sequential(
nn.Dropout(p_drop),
nn.Linear(self.encoder.output_dim, self.tagset_size)
)
def forward(self, x, y_in=None):
"""
前向传播方法,用于预测给定输入序列x的标签分布。
x: 输入序列的张量,形状为[批量大小, 最大长度]
y_in: 不被此类使用
返回:每个时间步的Categorical分布批次,表示每个词的标签分布。
"""
# 编码输入序列
h = self.encoder(x)
# 预测每个时间步的logits
s = self.logits_predictor(h)
# 将logits转换为Categorical分布
return td.Categorical(logits=s)
def greedy(self, x):
"""
贪婪解码,对于每个词的标签分布,预测最可能的标签。
x: 输入序列的张量,形状为[批量大小, 最大长度]
返回:预测的标签序列张量。
"""
# 使用模型的前向传播方法获取分布
cpds = self(x)
# 获取分布的最可能结果(众数)
y_pred = torch.argmax(cpds.probs, -1)
# 如果输入序列中包含填充,相应位置的输出序列也应填充
y_pred = torch.where(x != self.pad, y_pred, torch.full_like(y_pred, self.pad))
return y_pred
def mode(self, x):
"""
模式解码,与贪婪解码相同。
"""
return self.greedy(x)
def sample(self, x, sample_size=None):
"""
采样方法,从模型中为每个词序列生成样本。
x: 输入序列的张量
sample_size: 要采样的序列数量
返回:采样得到的标签序列。
"""
# 使用模型的前向传播方法获取分布
cpds = self(x)
# 根据分布进行采样
y_pred = cpds.sample(sample_size)
# 如果输入序列中包含填充,相应位置的输出序列也应填充
y_pred = torch.where(x != self.pad, y_pred, torch.full_like(y_pred, self.pad))
# 调整输出形状以匹配sample_size
if sample_size is None:
return y_pred.squeeze(0)
else:
return y_pred
# 测试BasicTagger类的功能
def test_basic_tagger(training_x, training_y, vocab_x, vocab_y):
# 初始化标注器
toy_uni_tagger = BasicTagger(
vocab_size=len(vocab_x),
tagset_size=len(vocab_y),
word_embed_dim=32,
hidden_size=32
)
# 进行一系列断言测试,确保标注器的行为符合预期
# ...
# 调用测试函数
test_basic_tagger(tagger_training_x, tagger_training_y, word_vocab, tag_vocab)
代码功能:
BasicTagger类继承自Tagger类,实现了一个基于文本编码器的序列标注模型。- 在初始化方法中,创建了文本编码器和用于预测标签分布的线性层。
forward方法实现了模型的前向传播,编码输入序列并预测每个时间步的标签分布。greedy方法实现了贪婪解码,选择每个标签分布的最可能标签作为预测结果。mode方法是greedy方法的别名,返回众数解码的结果。sample方法实现了从模型中采样,生成随机的标签序列。test_basic_tagger函数用于测试BasicTagger类的功能,确保其方法返回预期的形状和类型。
7.3.2 自回归标注器
自回归标注器在预测第i个标签t_i的分布时,会依赖于到目前为止已经生成的标签序列t_{1:i-1}以及输入序列X,从而避免了对马尔可夫假设的依赖。这种依赖性的建模可以通过以下公式来表示:
p
(
t
i
∣
t
1
:
i
−
1
,
X
)
=
softmax
(
NN
(
t
1
:
i
−
1
,
X
)
)
i
p(t_i|t_{1:i-1}, X) = \text{softmax}(\text{NN}(t_{1:i-1}, X))_i
p(ti∣t1:i−1,X)=softmax(NN(t1:i−1,X))i
对
t
h
th
th标签给定的
Y
i
i
Y_ii
Yii来说:
Y
i
∣
S
=
x
1
:
l
,
H
=
y
1
i
−
1
∼
C
a
t
e
g
o
r
i
c
a
l
(
g
(
i
,
x
1
:
l
,
y
1
i
−
1
;
θ
)
)
\begin{align} Y_i | S=x_{1:l}, H=y_1^{i-1} &\sim \mathrm{Categorical}(\mathbf g(i, x_{1:l}, y_1^{i-1}; \theta)) \end{align}
Yi∣S=x1:l,H=y1i−1∼Categorical(g(i,x1:l,y1i−1;θ))
对于神经网络
g
g
g而言
e
j
=
e
m
b
e
d
D
1
(
x
j
;
θ
words
)
j
∈
{
1
,
…
,
l
}
t
k
=
e
m
b
e
d
D
2
(
y
k
;
θ
tags
)
k
<
i
u
1
:
l
=
b
i
r
n
n
2
K
(
e
1
:
l
;
θ
bienc
)
v
i
=
r
n
n
s
t
e
p
K
(
v
i
−
1
,
t
i
−
1
;
θ
dec
)
s
i
=
f
f
n
n
C
(
c
o
n
c
a
t
(
u
i
,
v
i
)
;
θ
out
)
g
(
i
,
x
1
:
l
)
=
s
o
f
t
m
a
x
(
s
i
)
\begin{align} \mathbf e_j &= \mathrm{embed}_{D_1}(x_j; \theta_{\text{words}}) & j \in \{1, \ldots, l\}\\ \mathbf t_k &= \mathrm{embed}_{D_2}(y_k; \theta_{\text{tags}}) & k < i\\ \mathbf u_{1:l} &= \mathrm{birnn}_{2K}(\mathbf e_{1:l}; \theta_{\text{bienc}})\\ \mathbf v_i &= \mathrm{rnnstep}_K(\mathbf v_{i-1}, \mathbf t_{i-1}; \theta_{\text{dec}})\\ \mathbf s_i &= \mathrm{ffnn}_C(\mathrm{concat}(\mathbf u_i, \mathbf v_i); \theta_{\text{out}})\\ \mathbf g(i, x_{1:l}) &= \mathrm{softmax}(\mathbf s_i) \end{align}
ejtku1:lvisig(i,x1:l)=embedD1(xj;θwords)=embedD2(yk;θtags)=birnn2K(e1:l;θbienc)=rnnstepK(vi−1,ti−1;θdec)=ffnnC(concat(ui,vi);θout)=softmax(si)j∈{1,…,l}k<i
再次,我们有两个不同的嵌入层,一个用于单词,一个用于标签。同样地,我们使用双向RNN来编码整个文档。现在,对于第i个位置,我们使用一个RNN生成器/解码器单元来编码之前所有标签的完整历史。然后,我们通过一个前馈神经网络(FFNN)将历史编码与第i个位置的文档编码结合起来,以预测对数几率(logits)。
还有一种参数化这个模型的方式,即我们让RNN解码器将历史特征与文档特征进行组合:
e
j
=
e
m
b
e
d
D
1
(
x
j
;
θ
words
)
j
∈
{
1
,
…
,
l
}
t
k
=
e
m
b
e
d
D
2
(
y
k
;
θ
tags
)
k
<
i
u
1
:
l
=
b
i
r
n
n
2
K
(
e
1
:
l
;
θ
bienc
)
v
i
=
r
n
n
s
t
e
p
K
(
v
i
−
1
,
c
o
n
c
a
t
(
u
i
,
t
i
−
1
)
;
θ
dec
)
s
i
=
a
f
f
i
n
e
C
(
v
i
;
θ
out
)
g
(
i
,
x
1
:
l
)
=
s
o
f
t
m
a
x
(
s
i
)
\begin{align} \mathbf e_j &= \mathrm{embed}_{D_1}(x_j; \theta_{\text{words}}) j\in \{1, \ldots, l\}\\ \mathbf t_k &= \mathrm{embed}_{D_2}(y_k; \theta_{\text{tags}}) k < i\\ \mathbf u_{1:l} &= \mathrm{birnn}_{2K}(\mathbf e_{1:l}; \theta_{\text{bienc}})\\ \mathbf v_i &= \mathrm{rnnstep}_K(\mathbf v_{i-1}, \mathrm{concat}(\mathbf u_i, \mathbf t_{i-1}); \theta_{\text{dec}})\\ \mathbf s_i &= \mathrm{affine}_C(\mathbf v_i; \theta_{\text{out}})\\ \mathbf g(i, x_{1:l}) &= \mathrm{softmax}(\mathbf s_i) \end{align}
ejtku1:lvisig(i,x1:l)=embedD1(xj;θwords)j∈{1,…,l}=embedD2(yk;θtags)k<i=birnn2K(e1:l;θbienc)=rnnstepK(vi−1,concat(ui,ti−1);θdec)=affineC(vi;θout)=softmax(si)
class AutoregressiveTagger(Tagger):
"""
自回归标注器,用于序列标注任务,如词性标注或命名实体识别。
此类在预测每个标签时考虑了词序列和之前标签序列的历史信息。
"""
def __init__(self, vocab_size: int, tagset_size: int, word_embed_dim: int, tag_embed_dim: int, hidden_size: int, p_drop=0., pad_id=0, bos_id=1, eos_id=2):
"""
初始化方法,设置词汇表大小、标签集大小、词嵌入维度、标签嵌入维度、隐藏层维度等参数。
"""
# ... [初始化代码] ...
def forward(self, x, y_in):
"""
前向传播方法,用于参数化给定词序列x和标签序列历史y_in的条件分布Y[i]。
考虑了标签序列的历史信息,并处理了填充标记。
"""
# ... [前向传播代码] ...
def greedy(self, x):
"""
贪婪解码方法,对于每个条件概率分布Y[i]|X=x,预测最可能的标签。
考虑了词序列和之前标签序列的历史信息。
"""
# ... [贪婪解码代码] ...
def mode(self, x):
"""
模式解码方法,由于自回归标注器的模式搜索是不可解的,这里没有实现。
"""
raise NotImplementedError("自回归标注器的模式搜索是不可解的,考虑使用贪婪解码或基于采样的近似方法。")
def _sample(self, x):
"""
采样方法,从模型中为每个词序列生成样本,考虑了词序列和之前标签序列的历史信息。
"""
# ... [采样代码] ...
def sample(self, x, sample_size=None):
"""
采样方法,从模型中为每个词序列生成指定数量的样本。
"""
# ... [采样代码] ...
# 测试AutoregressiveTagger类的功能
def test_autoreg_tagger(training_x, training_y, vocab_x, vocab_y):
# 初始化标注器
toy_ar_tagger = AutoregressiveTagger(
# ... [参数] ...
)
# 进行一系列断言测试,确保标注器的行为符合预期
# ...
# 调用测试函数
test_autoreg_tagger(tagger_training_x, tagger_training_y, word_vocab, tag_vocab)
代码功能:
AutoregressiveTagger类继承自Tagger类,实现了一个自回归序列标注模型,该模型在预测每个标签时考虑了词序列和之前标签的历史信息。- 在初始化方法中,创建了文本编码器、标签嵌入层、LSTM解码器和用于预测标签分布的线性层。
forward方法实现了模型的前向传播,编码输入序列和标签序列的历史信息,并预测每个时间步的标签分布。greedy方法实现了贪婪解码,选择每个标签分布的最可能标签作为预测结果,并考虑了标签序列的历史信息。mode方法指出自回归标注器的模式搜索是不可解的,没有具体实现。_sample方法是一个私有方法,用于从模型中采样生成标签序列,考虑了词序列和标签序列的历史信息。sample方法实现了从模型中采样生成指定数量的标签序列样本。test_autoreg_tagger函数用于测试AutoregressiveTagger类的功能,确保其方法返回预期的形状和类型。
由于标注任务涉及一系列连续的分类决策,我们可以通过评估这些决策的准确性来评估标注器的性能。为实现这一目标,我们需要一个明确的决策规则。在自然语言处理(NLP)中,我们通常选择最可能的标签序列作为决策依据。具体而言,给定一个句子,我们会在所有可能的长度为n的标签序列中进行搜索,以找到模型赋予最高概率的序列,即条件分布中的众数(模式)。
x
1
:
l
{
1
,
…
,
C
}
l
l
x_{1:l}\{1, \ldots, C\}^ll
x1:l{1,…,C}ll
y
⋆
=
arg
max
c
1
:
l
∈
{
1
,
…
,
C
}
l
log
P
(
G
=
c
1
:
l
∣
S
=
x
1
:
l
)
\begin{align} y^\star &= \arg\max_{c_{1:l} \in \{1, \ldots, C\}^l}~ \log P(G=c_{1:l}|S=x_{1:l}) \end{align}
y⋆=argc1:l∈{1,…,C}lmax logP(G=c1:l∣S=x1:l)
对于条件独立的标注器来说,其决策搜索通常是在一个庞大的标签组合空间中进行,这在实际操作中往往不可行。然而,由于某些标注器基于条件独立性假设,其搜索可以在多项式时间内(以序列长度为函数)完成,但这并非对所有类型的标注器都适用。
对于基本的标注器而言,由于它假设在给定的句子中标签是相互独立的,因此搜索过程可以精确执行。这是因为独立地贪婪地最大化每一步等同于最大化该模型对整个序列的联合分配。
一元标注器的搜索
对于一元标注器(即只考虑单个标签的标注器),我们在每个位置寻找最佳标签,每个位置的搜索都需要一定的时间。
O
(
C
)
\mathcal O(C)
O(C)
y
i
⋆
=
arg
max
c
∈
{
1
,
…
,
C
}
log
P
(
Y
i
=
c
∣
S
=
x
1
:
l
)
\begin{align} y^\star_i &= \arg\max_{c \in \{1, \ldots, C\}}~ \log P(Y_i=c|S=x_{1:l}) \end{align}
yi⋆=argc∈{1,…,C}max logP(Yi=c∣S=x1:l)
并将它们组合成一个序列。整个操作需要的时间。
O
(
l
×
C
)
\mathcal O(l \times C)
O(l×C)
自回归标注器搜索
对于自回归标注器,由于其不依赖条件独立性假设,搜索问题变得异常复杂且难以直接解决。这种不可处理性意味着没有已知的高效算法可以在合理的时间内找到最优解。实际上,根据目前的假设,在标准计算机架构下,找到能在多项式时间内(以n为变量)解决问题的有效算法实际上是不可能的。这类问题被称为NP完全问题,它们具有极高的计算复杂性。
在文中,为了简化问题,我们将再次采用贪婪近似法作为解决方案。
y
^
i
=
arg
max
c
∈
{
1
,
…
,
C
}
log
P
(
Y
i
=
c
∣
S
=
x
1
:
l
,
H
=
y
^
1
i
−
1
)
\begin{align} \hat y_i &= \arg\max_{c \in \{1, \ldots, C\}}~ \log P(Y_i=c|S=x_{1:l}, H=\hat y_1^{i-1}) \end{align}
y^i=argc∈{1,…,C}max logP(Yi=c∣S=x1:l,H=y^1i−1)
我们采用一种局部贪婪策略,在序列的每个位置上从左至右独立求解最大值。对于序列中的每一步,我们都依赖于之前所有步骤已经确定的最大值来进行条件判断。
建立好用于预测的搜索算法之后,我们便能够计算出分类任务中常用的准确度和其他相关指标。
下面的代码演示了如何使用PyTorch创建、配置和训练一个基于贪婪策略的序列标注模型,并对结果进行可视化。
class GreedyMode(DecisionRule):
"""
贪婪模式决策规则,用于通过贪婪解码获取模型预测结果。
"""
def __call__(self, model, x):
"""
使用模型的贪婪解码方法进行预测。
model: 标注模型
x: 输入数据
"""
return model.greedy(x)
# 重置随机数生成器,确保结果的可重复性
seed_all()
# 设置设备为GPU(如果可用)
my_device = torch.device('cuda:0')
# 创建基础标注模型实例,并将其移动到GPU
tagger = BasicTagger(
vocab_size=len(word_vocab),
tagset_size=len(tag_vocab),
word_embed_dim=4,
hidden_size=8,
).to(my_device)
# 构建Adam优化器
optimiser = opt.Adam(tagger.parameters(), lr=5e-3)
# 打印模型结构
print("模型")
print(tagger)
# 打印模型参数数量
print(f"模型大小:{tagger.num_parameters():,} 参数")
# 训练模型
log = train_neural_model(
tagger, optimiser,
decision_rule=GreedyMode(), # 使用贪婪模式作为决策规则
training_data=TaggedCorpus(tagger_training_x, tagger_training_y, word_vocab, tag_vocab),
dev_data=TaggedCorpus(tagger_dev_x, tagger_dev_y, word_vocab, tag_vocab),
report_fn=report_tagging, report_metrics=['accuracy'],
batch_size=10, num_epochs=10, check_every=100,
device=my_device
)
# 可视化训练损失和验证指标
fig, axs = plt.subplots(1, 3, figsize=(12, 4))
_ = axs[0].plot(np.arange(len(log['loss'])), log['loss'])
_ = axs[0].set_xlabel('步数')
_ = axs[0].set_ylabel('训练损失')
_ = axs[1].plot(np.arange(len(log['D'])), log['D'])
_ = axs[1].set_xlabel('步数(每100步)')
_ = axs[1].set_ylabel('验证D值')
_ = axs[2].plot(np.arange(len(log['accuracy'])), log['accuracy'])
_ = axs[2].set_xlabel('步数(每10步)')
_ = axs[2].set_ylabel('验证准确率')
_ = fig.tight_layout(h_pad=2, w_pad=2)
plt.show()
Model
BasicTagger(
(encoder): TextEncoder(
(word_embed): Embedding(3358, 4)
(encoder): LSTM(4, 8, batch_first=True, bidirectional=True)
)
(logits_predictor): Sequential(
(0): Dropout(p=0, inplace=False)
(1): Linear(in_features=16, out_features=16, bias=True)
)
)
Model size: 14,600 parameters
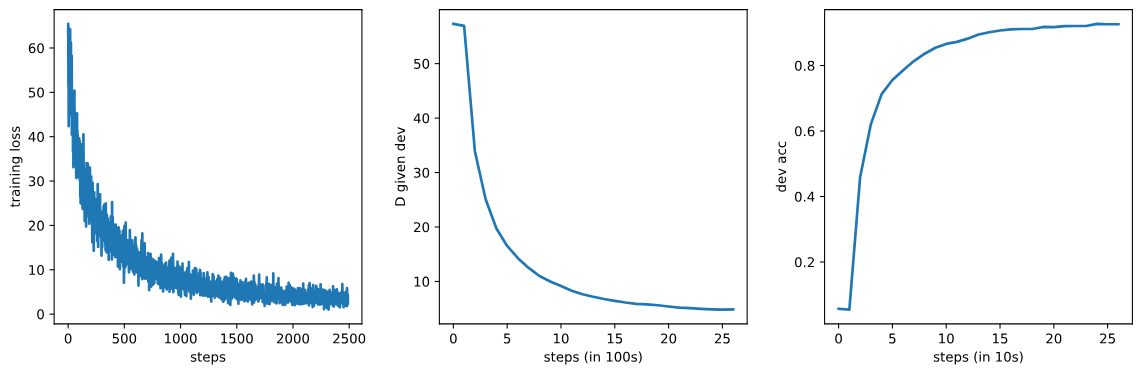 下面的代码展示了如何重置随机数生成器、设置设备、初始化自回归标注模型(
下面的代码展示了如何重置随机数生成器、设置设备、初始化自回归标注模型(AutoregressiveTagger)、构建优化器、训练模型,并最终绘制训练过程中的损失和验证指标。
# 重置随机数生成器,确保结果的可重复性
seed_all()
# 设置设备为GPU(如果可用)
my_device = torch.device('cuda:0')
# 创建自回归标注模型实例,并将其移动到GPU
ar_tagger = AutoregressiveTagger(
vocab_size=len(word_vocab),
tagset_size=len(tag_vocab),
word_embed_dim=4,
tag_embed_dim=4,
hidden_size=8,
).to(my_device)
# 构建Adam优化器
optimiser = opt.Adam(ar_tagger.parameters(), lr=5e-3)
# 打印模型结构
print("模型")
print(ar_tagger)
# 打印模型参数数量
print(f"模型大小:{ar_tagger.num_parameters():,} 参数")
# 训练模型
log = train_neural_model(
ar_tagger, optimiser,
decision_rule=GreedyMode(), # 使用贪婪模式作为决策规则
training_data=TaggedCorpus(tagger_training_x, tagger_training_y, word_vocab, tag_vocab),
dev_data=TaggedCorpus(tagger_dev_x, tagger_dev_y, word_vocab, tag_vocab),
report_fn=report_tagging, report_metrics=['accuracy'],
batch_size=10, num_epochs=10, check_every=100,
device=my_device
)
# 可视化训练损失和验证指标
fig, axs = plt.subplots(1, 3, figsize=(12, 4))
_ = axs[0].plot(np.arange(len(log['loss'])), log['loss'])
_ = axs[0].set_xlabel('步数')
_ = axs[0].set_ylabel('训练损失')
_ = axs[1].plot(np.arange(len(log['D'])), log['D'])
_ = axs[1].set_xlabel('步数(每100步)')
_ = axs[1].set_ylabel('验证D值')
_ = axs[2].plot(np.arange(len(log['accuracy'])), log['accuracy'])
_ = axs[2].set_xlabel('步数(每10步)')
_ = axs[2].set_ylabel('验证准确率')
_ = fig.tight_layout(h_pad=2, w_pad=2)
plt.show()
Model
AutoregressiveTagger(
(encoder): TextEncoder(
(word_embed): Embedding(3358, 4)
(encoder): LSTM(4, 8, batch_first=True, bidirectional=True)
)
(tag_embed): Embedding(16, 4)
(decoder): LSTM(4, 8, batch_first=True)
(logits_predictor): Sequential(
(0): Dropout(p=0.0, inplace=False)
(1): Linear(in_features=24, out_features=8, bias=True)
(2): ReLU()
(3): Dropout(p=0.0, inplace=False)
(4): Linear(in_features=8, out_features=16, bias=True)
)
(init_state): Sequential(
(0): Dropout(p=0.0, inplace=False)
(1): Linear(in_features=16, out_features=8, bias=True)
(2): Tanh()
)
(init_cell): Sequential(
(0): Dropout(p=0.0, inplace=False)
(1): Linear(in_features=16, out_features=8, bias=True)
(2): Tanh()
)
)
Model size: 15,456 parameters
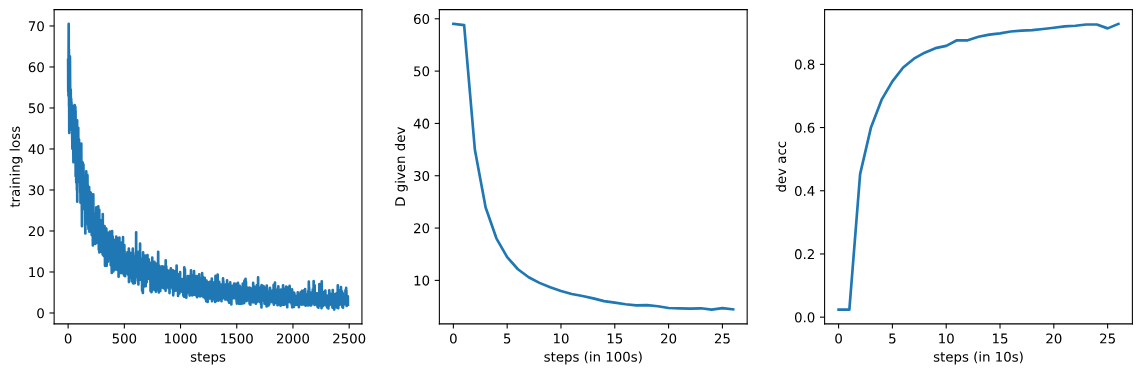
下面的代码演示了如何使用训练好的自回归标注模型对开发集(tagger_dev_data)进行预测,并打印出样本预测和贪婪预测的结果。
# 创建开发集的数据封装对象
tagger_dev_data = TaggedCorpus(tagger_dev_x, tagger_dev_y, word_vocab, tag_vocab)
# 为开发集创建DataLoader,批量大小为1,不打乱数据,使用最长序列填充方法
tagger_dev_dl = DataLoader(tagger_dev_data, batch_size=1, shuffle=False, collate_fn=tagger_dev_data.pad_to_longest)
# 遍历开发集的每个批次
for batch_x, batch_y in tagger_dev_dl:
print("样本预测")
# 使用模型进行采样预测,并将输入数据移动到指定设备
y_out = ar_tagger.sample(batch_x.to(my_device))
# 对批次数据进行解码,并打印预测的标签序列
for x, y in zip(word_vocab.batch_decode(batch_x, strip_pad=True), tag_vocab.batch_decode(y_out, strip_pad=False)):
print(" ".join(f"{w}/{t}" for w, t in zip(x, y)))
print("\n贪婪预测")
# 使用模型进行贪婪预测
y_out = ar_tagger.greedy(batch_x.to(my_device))
# 对批次数据进行解码,并打印贪婪预测的标签序列
for x, y in zip(word_vocab.batch_decode(batch_x, strip_pad=True), tag_vocab.batch_decode(y_out, strip_pad=False)):
print(" ".join(f"{w}/{t}" for w, t in zip(x, y)))
# 由于是批量大小为1,打印第一个批次后即可中断循环
break
代码功能:
- 使用
TaggedCorpus类创建开发集的数据封装对象tagger_dev_data,该对象将用于封装开发集的输入和标签数据以及词汇表。 - 创建
DataLoader对象tagger_dev_dl,用于从开发集中批量加载数据,批量大小设置为1,不进行数据打乱,使用pad_to_longest方法进行序列填充。 - 通过
DataLoader遍历开发集,对每个批次的数据进行预测。 - 使用
ar_tagger.sample方法进行采样预测,获取随机的标签序列样本。 - 使用
ar_tagger.greedy方法进行贪婪预测,获取最可能的标签序列。 - 使用
word_vocab.batch_decode和tag_vocab.batch_decode方法对输入的词序列和预测的标签序列进行解码,以便于打印可读的结果。 - 打印出每个词及其对应的预测标签。
以下是对上述段落的改写,以提高清晰度和流畅度:
8.构建属于你的深度概率模型
为进行深入的实践,提升对概率模型的认识和理解,建议你亲手构建一个概率模型。任务是挑选一个数据集,并为其设计一个由神经网络驱动的概率模型。在挑选适合数据的分布时,请务必谨慎,以确保它们与您的数据类型相匹配。采用最大似然估计方法来确定神经网络的参数。同时,对于您选择的决策规则也要深思熟虑。是否能够精确地求得模型的模式?该规则在您的模型中是否恰当?是否存在更加合适的标准?您是否考虑过运用期望效用最大化原则来优化您的模型?
尽管在前面的讨论中已经提供了一系列辅助类来帮助读者从文本数据中提取学习特征,但我们仍然鼓励大家探索文本数据集。当然,你构建的模型可以应用于任何类型的数据,包括序数数据、实数、离散数据或结构化数据等。
以下是可用的数据集资源:
- NLTK:https://www.nltk.org/nltk_data/
- HuggingFace:https://huggingface.co/datasets
- Kaggle:https://www.kaggle.com/datasets
关于不同类型的数据,这里有一些额外的说明:
- 某些结构化数据具有固定维度(例如,一个尺寸为HxWxC的图像)。一些模型可能基于像序列标注器那样的链式规则分解,但它们在参数化时可能会利用固定维度的特性。
- 某些结构化数据由连续部分组成(例如,金融或医疗领域中的时间序列)。在这些情况下,条件因素可能来自数值型分布家族(如泊松分布、正态分布、伽马分布等)。有时,可能需要比典型的单峰指数族分布更强大的模型。在这种情况下,您可以考虑使用混合模型或归一化流。
9.总结和展望
9.1 总结
在本文中,我们深入探讨了深度概率模型(DPMs)的理论和实践。从基础的概率论概念出发,我们逐步过渡到了复杂的神经网络结构,这些结构能够用于建模和预测各种类型的数据。以下是我们所涵盖的关键点:
-
深度概率模型简介:介绍了DPMs如何结合深度学习与概率论的优势,以及它们在不确定性建模、数据生成和提高模型可解释性方面的应用。
-
数据预处理:讨论了数据预处理的重要性,包括文本清洗、分词、构建词汇表等步骤。
-
模型构建:详细描述了如何构建自回归和非自回归的序列标注模型,以及如何使用PyTorch框架实现这些模型。
-
参数估计:介绍了最大似然估计(MLE)的原理,并展示了如何通过梯度下降算法来优化模型参数。
-
决策规则:分析了不同的决策规则,包括贪婪解码和期望效用最大化,以及它们在模型预测中的应用。
-
模型训练与评估:提供了一个通用的训练框架,包括损失函数的定义、模型性能的评估指标和可视化结果的方法。
-
实践案例:通过文本分类和序列标注任务的具体实例,展示了如何应用深度概率模型,并提供了相应的代码实现。
9.2 展望
随着机器学习领域的快速发展,深度概率模型将继续在理论和应用层面取得进展。以下是一些未来可能的发展方向:
-
模型泛化能力:研究如何提高模型对新数据的泛化能力,减少过拟合现象。
-
计算效率:优化算法和硬件加速,以提高深度概率模型的训练和推理效率。
-
多模态学习:探索将深度概率模型应用于多模态数据(如结合文本、图像和声音)的方法。
-
强化学习集成:将深度概率模型与强化学习相结合,以处理更复杂的决策问题。
-
可解释性和透明度:提高模型的可解释性,使研究人员和用户能够更好地理解和信任模型的预测。
-
跨领域应用:将深度概率模型应用于更多领域,如医疗诊断、金融风险评估和自然语言理解等。
-
伦理和隐私:在使用个人数据训练模型时,考虑伦理和隐私问题,确保技术的发展符合社会价值观。
通过本文的学习,读者应该对深度概率模型有了全面的了解,并具备了将这些模型应用于实际问题的能力。随着技术的不断进步,我们期待在未来看到更多创新的应用和突破。