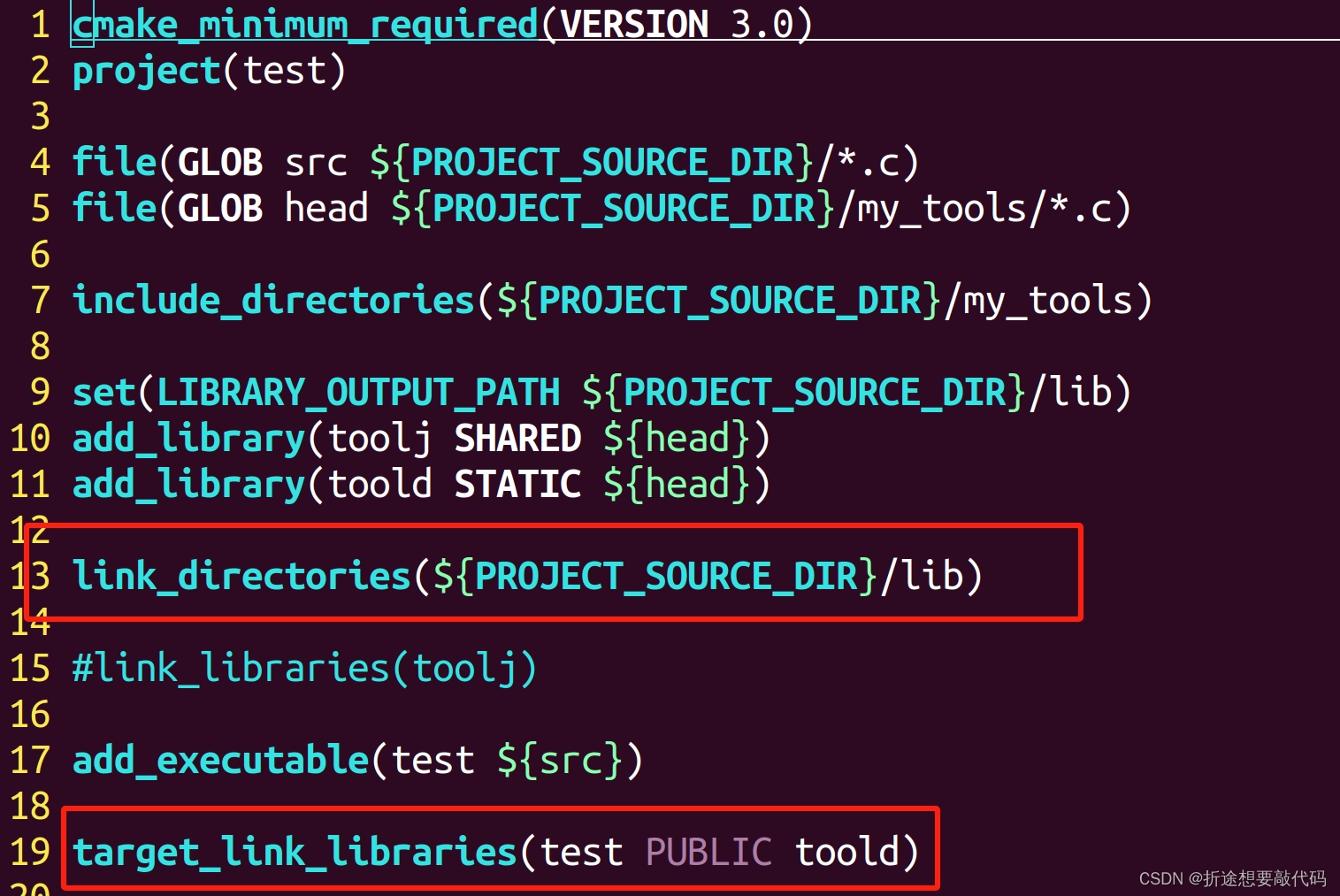
一、数值稳定性:神经网络很深的时候数据非常容易不稳定
1、神经网络梯度
h^(t-1)是t-1层的输出,也就是t层的输入,y是需要优化的目标函数,向量关于向量的倒数是一个矩阵。

2、问题:梯度爆炸、梯度消失
(1)梯度爆炸例子:MLP

当使用ReLu作为激活函数

a、值超出值域(infinity) ,对于16位浮点数尤为严重(数值区间6e-5-6e4)
b、对学习率敏感,如果学习率太大->大参数值->更大的梯度,如果学习率太小>训练无进展,我们可能需要在训练过程不断调整学习率
(2)梯度消失
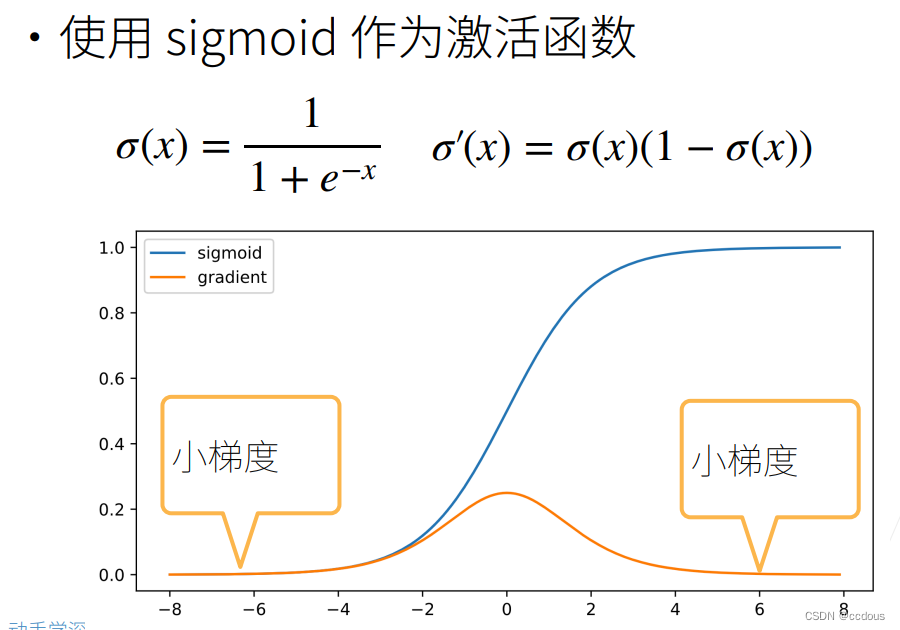
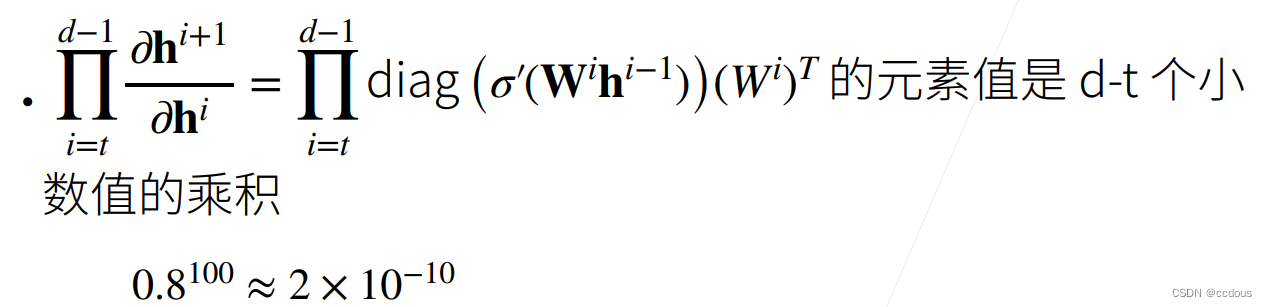
a、梯度值变成0 ,对16位浮点数尤为严重
b、训练没有进展,不管如何选择学习率
c、对于底部层尤为严重,仅仅顶部层训练的较好,无法让神经网络更深
3、总结
(1)当数值过大或者过小时会导致数值问题
(2)常发生在深度模型中,因为其会对n个数累乘
二、模型初始化和激活函数
1、模型初始化权重及选取激活函数让训练更加稳定
2、在上一部分知道梯度消失及梯度爆炸,为使梯度在合理的范围内,有方法
(1)将乘法变为加法
ResNet在很多层的情况下,加入加法,从乘法变成加法;
LSTM是长短时记忆网络,能够有效地解决梯度消失和梯度爆炸的问题(不知道具体的,大概后面学)
(2)归一化、梯度剪裁
归一化,比如将所有梯度归一化为均值为0,方差为1。梯度剪裁,比如大于n的梯度直接变成n,小于m的全部变成m
3、将每一层的输出和梯度都看成随机变量,使每一层权重为均值为0,方差为常数、

4、权重初始化
(1)训练开始的时候更容易有数值不稳定:远离最优解的地方损失函数表面可能很复杂,最优解附近表面会比较平
(2)使用N(0,0.01)来初始可能对小网络没问题,不能保证深度神经网络
(3)在合理值区间里随机初始参数
5、例子:MLP

(1)正向方差推导

Var(x)=E(x^2)-E(x)^2,这里E(x)=0(把E^2变成了Var[])

最终由于等式可得

(2)反向均值和方差(最后一步不是很清楚,方差等于方差怎么得来的)

6、Xavier初始

关于这里的正态分布。pytorch的normal函数里面传参是标准差,数学上的正态分布写的是方差,这里按normal函数来的。
7、在线性激活函数下,必得激活函数y=x(一般情况下激活函数不使用线性)

反向同理

8、常用激活函数
 对sigmoid进行调整,从绿线到蓝线。调整是为了正向和反向的传播,输入和输出的x都是正态分布
对sigmoid进行调整,从绿线到蓝线。调整是为了正向和反向的传播,输入和输出的x都是正态分布
8、合理的权重初始化和激活函数的选取可以提高数值稳定性