深度学习论文: Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
PDF:https://arxiv.org/pdf/2405.14578
PyTorch: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
本文研究了Adam等风格的优化器在深度学习任务中的使用,发现它们与传统的SGD优化器不同,最优学习率与批量大小的关系并非线性。文章首先提出了一个理论分析,证明在梯度符号的情况下,最优学习率随批量大小增加先上升后下降,并随着训练进展趋向于更大的批量。
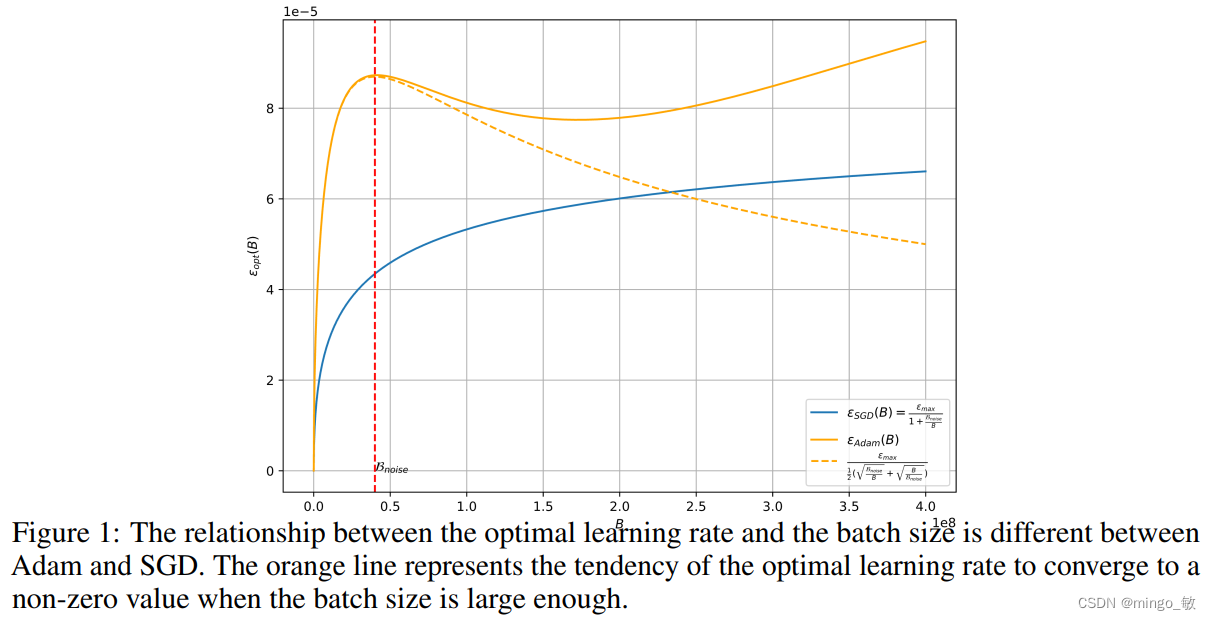
此外,当批量小于特定阈值时,Adam优化器的学习率缩放将遵循平方根规则,而SGD则遵循线性规则。通过在CV和NLP上的实验,验证了理论的正确性,并观察到随着训练的进行,最优学习率的峰值会逐渐向右移动,表明需要对超参数进行细致调整以适应不同阶段的训练需求。
2 Theorems
2-1 Batch Size and Optimal Learning Rate
当使用SGD风格的优化器时,Batch size与学习率之间存在特定的线性放缩关系(OpenAI 2018)。
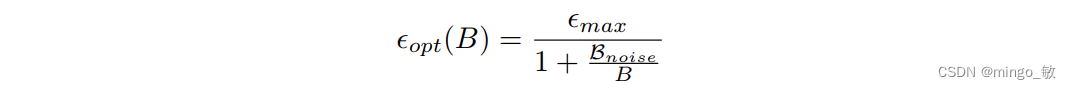
然而,当切换到Adam风格的优化器时,放缩规律则有所不同,需要遵循特定的平方根放缩规律。
在深入的探索和研究过程中,研究团队对Adam优化器的更新机制进行了细致的剖析。他们提出了一个假设,即每个样本的参数梯度遵循一种特定形态的高斯分布,其中均值和方差均遵循特定的数学规律。为了更准确地模拟和优化更新过程,研究团队还引入了sigmoid型函数对高斯误差函数进行数值上的近似处理。
基于上述的假设和数值近似方法,研究团队成功地推导出了完整的Scaling law公式。
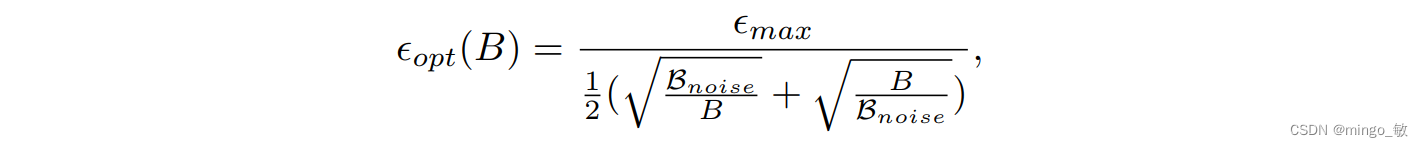
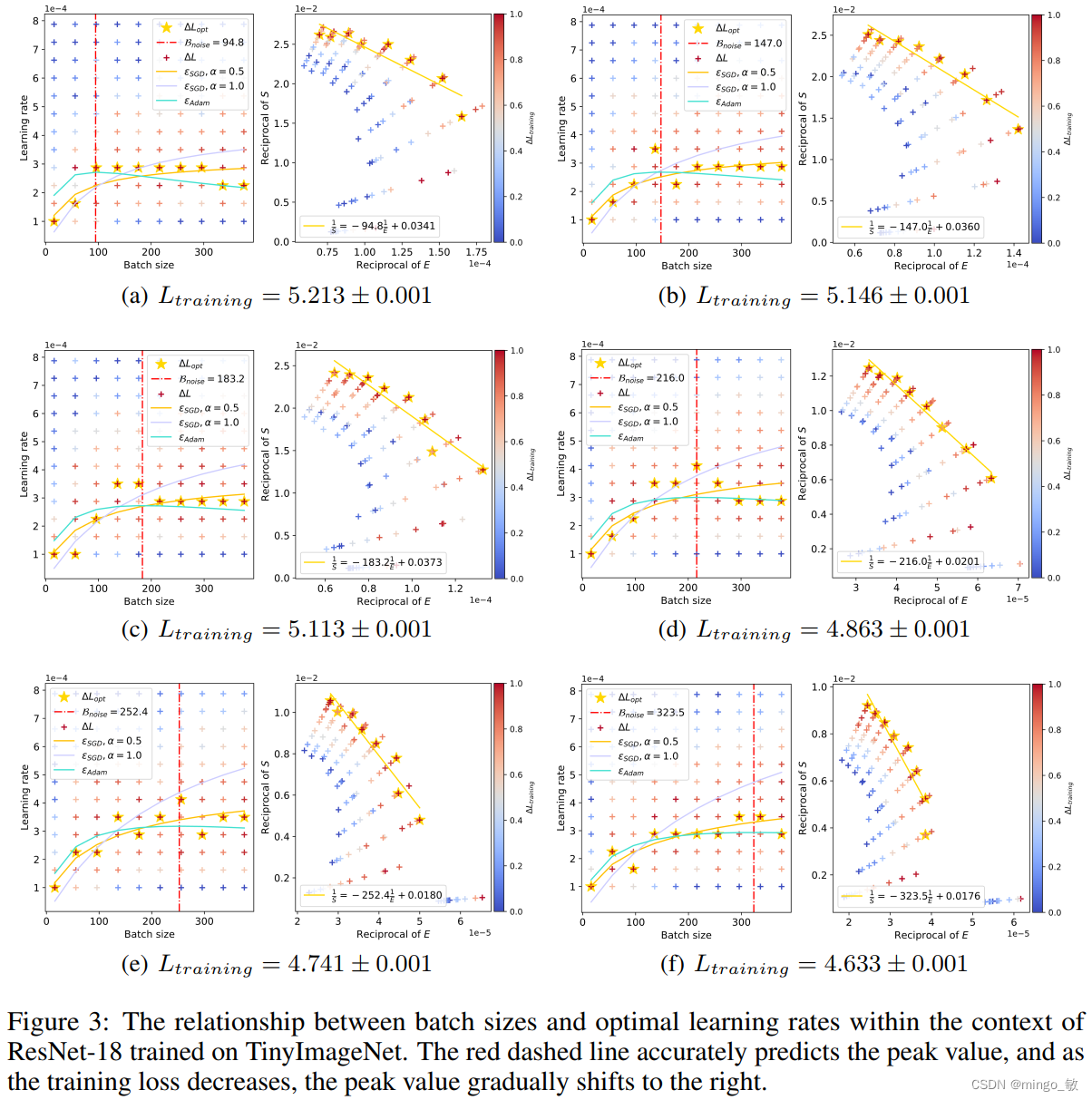
具体而言,随着Batch size的逐步增加,最优学习率会经历一个先上升后下降的变化过程,这种变化模式与海浪起伏的形态颇为相似。而当Batch size趋于无穷大时,最优学习率将达到一个稳定的饱和状态,不再随Batch size的增加而发生显著变化。这一发现不仅为我们优化深度学习模型提供了新的策略,也为我们理解大规模数据集下的模型训练行为提供了重要的参考。
2-2 Data/Time Efficiency Trade-off
本文根据大批量训练的经验模型,讨论了批量大小选择时数据与时间效率的权衡。文中证明,该定理与SGD情况下的结论一致,表明SGD优化器导出的训练速度与数据效率的关系同样适用于Adam风格优化器。随着训练的进行,损失减少,最优批量大小会逐渐增加, B n o i s e B_{noise} Bnoise 既是最优学习率的局部最大值,也是训练速度和数据效率的平衡点。
3 Experiments