目录
- 数据存储(3星)
- 判断大小端
- 写一个函数判断大小端
- 截断与整形提升
- 数组和指针(5星)
- 几个特殊的指针
- 数组传参
- 字符串数组
- 库函数的实现(4星)
- atoi与itoa
- memcpy与memmove
- 内存重叠
- 自定义类型(4星)
- 内存对齐
- 结构体,联合体,枚举
- 位段
- 编译链接(3星)
- 编译和链接的过程
- 条件编译
- 操作符和关键字(4星)
- volatile
- const
- static(结合C++)
数据存储(3星)
判断大小端

大端
将数据的高位存储在内存的低地址;
小端(常用)
将数据的低位存储在内存的低地址;
写一个函数判断大小端
强转即可;发生了截断;
bool judge(int i = 1){
//判断是不是小端
return char(i);
}
截断与整形提升
截断
int a = 0x0fffffff;
char c = a;
int b = c;
printf("%d\n", b);// char 1个字节 发生截断,截取低位8个字节(11111111),(注意大小端),输出-1
整形提升
char a = 0xff;//8个1
printf("%d\n",a); //输出-1;a二进制 11111111 ,符号位为1,提升int4字节的时,前面补1!
a= 0x7f;
printf("%d\n",a); //输出127;a二进制 01111111 ,符号位为0,提升int4字节的时,前面补0
数组和指针(5星)
数组
一段连续的内存空间,用于存储若干个指定相同类型的值;
只有在&arr 或者 sizeof(arr)的时候,数组名arr才被看作整个数组,其余情况看做首元素的地址!
指针
指向内存中的一个地址,该地址对应的内存空间下可能存放有特定数据;
几个特殊的指针
注意符号的优先级进行区分!
指针数组
int *arr[NUM]; //[]优先,所以他是一个数组,存储的类型为int*;
数组指针
int (*arr)[NUM]; //()让arr是一个指针,指向的类型为int [NUM]数组
函数指针
int (*ptr)(int int) //ptr是一个指针,指向int (int int),参数为两个int,返回值为int的函数;
//这样比较复杂,一般typedef定义一个新的类型名;
typedef int (*Ptr)(int int) Ptr
Ptr p = Add;//创建实例;
(*p)(1,1);//调用函数Add 返回2
数组传参
一维数组传参相当于退化为指针;
void f1(int arr[])//int *arr
{
cout<<sizeof(arr)<<endl; //输出4
}
int main()
{
int arr[10];
f1(arr);
}
二维数组传参必须指定列数(才能确定+,-这些跳过二维中若干个一维的地址偏移操作),相当于数组指针;
void f2(int arr[][4])//int *arr
{
cout<<sizeof(arr)<<endl; //输出4
}
int main()
{
int arr[4][4];
f2(arr);
}
字符串数组
假设字符串数组为carr,这里要注意strlen(carr)和sizeof(carr)的区别;
- 因为strlen计算字符串长度,他会找‘\0’然后停下,所以不会计算’\0’;
- sizeof则会把’\0’这个特殊字符也算上,所以对于一般的字符串,sizeof(carr) = strlen(carr)+1;
库函数的实现(4星)
atoi与itoa
atoi
int atoi (const char * str);
//将一个字符串转换成int返回;
int My_Atoi(const char* str){
int len = strlen(str);
char tmp[100];
int index = 0;
for(int i = len-1;i>=0;i--){
if(str[i]=='-') continue;//跳过负数,最后再判断;
tmp[index++] = str[i];
}
int ret = 0;
while(len)
{
int c = tmp[len-1] - '0';
ret*=10;
ret+=c;
len--;
}
//判断负数情况
if(str[0] == '-') ret*=-1;
return ret;
}
itoa
char * itoa ( int value, char * str, int base );
//将一个整形转换成对应进制的字符串; 进制转换<-->辗转相除;
void Swap(char* a, char* b)
{
char tmp = *a;
*a = *b;
*b = tmp;
}
char* My_Itoa(int value, char* str, int base)
{
char ret[1024];
int index = 0;
int flag = 0;
char carr[] = { '0','1','2','3','4','5','6','7','8','9','A','B','C','D','E','F' };
//处理负数用'-'加原码表示,暂时不考虑补码这些;
if (value < 0) {
flag = 1;
value *= -1;
}
while (value)
{
ret[index++] = carr[value % base];
value /= base;
}
if (flag) {
ret[index++] = '-';
}
//翻转
int l = 0;
int r = index - 1;
while (l < r)
{
Swap(&ret[l],&ret[r]);
l++;
r--;
}
ret[index++] = '\0';
return ret;
}
memcpy与memmove
strcpy用于string的拷贝,遇到’\0’停止,使用仅限于字符串;
二momcpy是void*类型的内存拷贝,适用更多场景;
在C/C++一些笔试中较常见要求不用标准库函数,实现mommove函数的功能,这里进行一下自我总结:
void * memcpy ( void * dest, const void * src, size_t num );
void * memmove ( void * dest, const void * src, size_t num );
- dest 目的内存首地址;
- src (资)源内存首地址;
- num 拷贝字节数;
- 返回值:最开始的dest的首地址
可以看到memcpy与memmove的返回值或者参数都是一样的,其实在一些编译器中,memcpy已经被优化为了memmove;
两者区别:
memmove是momcpy的升级版,memcpy不处理内存重叠时可能引发的问题,出现重叠情况可能会拷贝紊乱出错(src<dest);而memmove处理了内存重叠时可能引发的问题!;
C还保留memcpy的原因是,让之前用过memcpy的代码能正常运行;
memcpye
void * memcpy ( void * dest, const void * src, size_t num );
//
//不处理内存重叠中的特殊情况;
void* my_memcpy( void * dest, const void * src, size_t num )
{
void* ret = dest;
while(num--){
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;;
}
return ret;
}
int main()
{
int arr[] = {1,2,3,4,5,6,7,8,9,10};
my_memcpy(arr,arr+5,5*4);//6,7,8,9,10,6,7,8,9,10 //内存重叠,但是src<dest,没问题
my_memcpy(arr+1,arr,5*4); //1,1,1,1,1,1,7,8,9,10 //内存重叠,但是src>dest,出现问题了,这种src<dest得从后往前拷贝才能达到预期效果!
return 0;
}
内存重叠
如下图,源src和目的dest内存有公共部分!

上图src>dest时,如果类似memcpy正常从左向右进行拷贝,显然结果是不对的;
这时候后memmove出现了,针对内存重叠情况做出判断,按照特定的方式(前向后 or 后向前)进行拷贝,达到预期效果;
memmove
void * memmove ( void * dest, const void * src, size_t num );
void * my_memmove ( void * dest, const void * src, size_t num )
{
void* ret = dest;
//核心就是根据src与desc的大小关系,进行分类操作(正拷贝 or 逆拷贝)
if(src<dest){
//src在desc前面!逆拷贝;
while(num--){
*( (char*)dest+num) = *( (char*)src+num);//优雅~
}
}
else{
//顺拷贝;
while(num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;;
}
}
return ret;
}
自定义类型(4星)
内存对齐
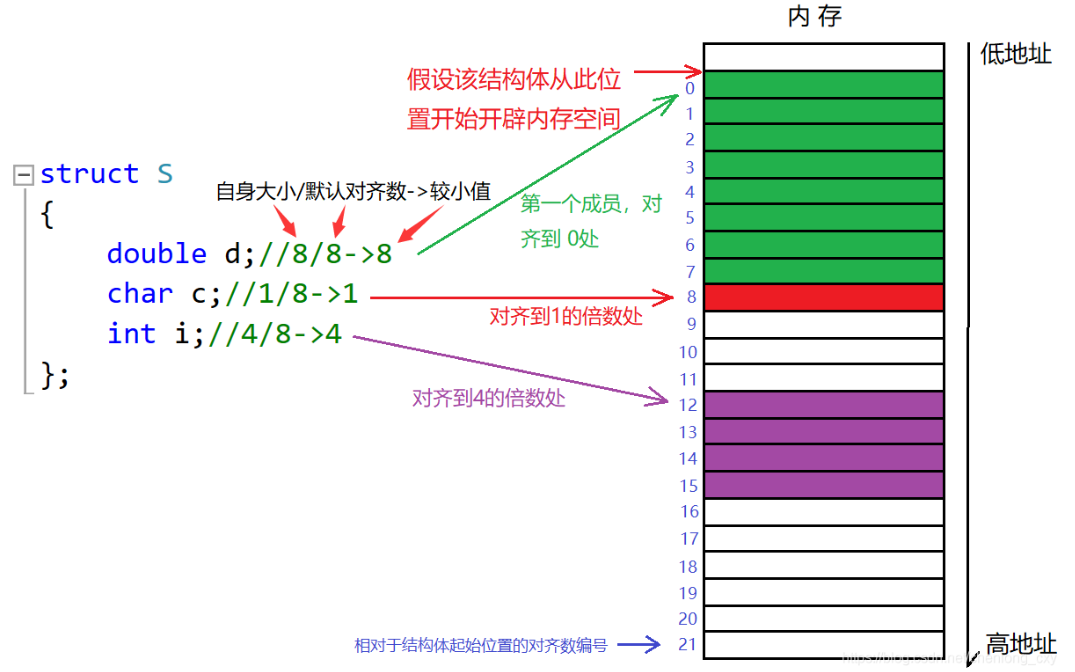
结构体的大小往往不是结构体中各种数据类型的加和,因为其存在内存对齐;
结构体的对齐规则:
- 第一个成员在与结构体变量偏移量为0的地址处。
- 其他成员变量要对齐到对齐数的整数倍的地址处。
对齐数:编译器默认的一个对齐数 **与 该成员大小的较小值 **(VS中默认的值为8 Linux中的默认值为4)
结构体总大小为最大对齐数(每个成员变量确定的较小对齐数最大的那个)的整数倍
(注意,对其书不一定包含VS平台那个8,如果每个成员大小都小于8,那么结构体总大小就是那些成员中最大的类型值得整数倍)
下面是一个对齐后总大小为16的结构体:
为什么存在内存对齐?
性能原因:
CPU的优化规则:与CPU命中率有关,大致原则是这样的:对于n字节的元素(n=2,4,8,…),它的首地址能被n整除,才能获得最好的性能。为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
所以内存对齐本质上是一种空间换时间的优化;(现代内存空间大大的多,更注重时间了);
根据内存对齐的特征,设计结构体时,让较小的成员聚集在一起可以节省空间!
结构体,联合体,枚举
结构体
一个事物具有多重属性或方法,打包成一个结构体,方便操作处理;有点面向对象的意思;
struct People{
int id;
char* name;
//...多重属性
public:
int Getid(){//方法1:返回这个人的id
return id;
}
};
枚举
枚举==列举
enum Day//星期
{
Mon = 1,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
enum Sex//性别
{
MALE,
FEMALE,
SECRET
};
{}中的内容是枚举类型的可能取值,也叫 枚举常量 。
这些可能取值都是有值的,默认从0开始,一次递增1,当然在定义的时候也可以赋初值。 例如:
枚举的优点(与宏定义常量对比一下):
宏定义的常量不够严谨;
枚举自动递增,方便管理,增加代码的可读性和可维护性;
使用方便,一次可以定义多个常量;
联合体(共用体)
联合的成员是共用同一块内存空间的(有重叠),这样一个联合变量的大小,至少是最大成员的大小(因为联合至少得有 能力保存最大的那个成员)。
union Un
{
int i;
char c;
};
union Un un;
un.i = 0x11223344;
un.c = 0x55;
//下面两条输出结果一样,因为他们共用同一块空间,起始地址都是相同的
printf("%x\n", &un.i);
printf("%x\n", &un.c);
printf("%x\n", un.i);//输出11223355; 因为i和c共同一四字节的空间,第二次c放入0x55将i的44覆盖掉了;
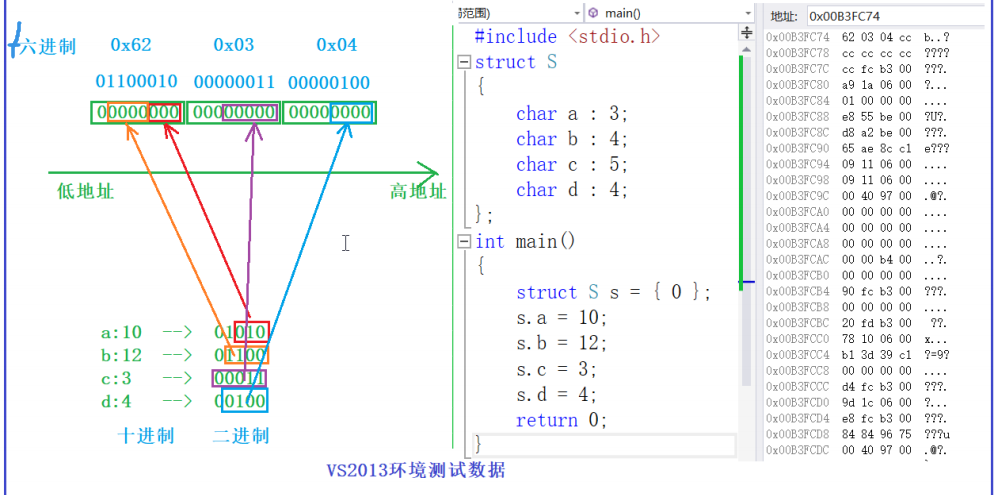
位段
和结构体很像,与结构体相比,位段更节省空间,但是不具有跨平台性;
位段常用在确定的某些结构,省点空间,eg各种网络报文!

struct S
{
char a:3;
char b:4;
char c:5;
char d:4;
};
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
位段**按照类型(char int等)**开空间,如果这个空间的二进制位没用完,而且能放下下一个成员,那就共用一段空间(内存不能重叠),剩余二进制位置放不下的话,那只好再开辟一个类型空间了;
编译链接(3星)
我们编写的程序代码是怎样运行起来的?到底运行的是什么内容?那就是编译和链接的全过程
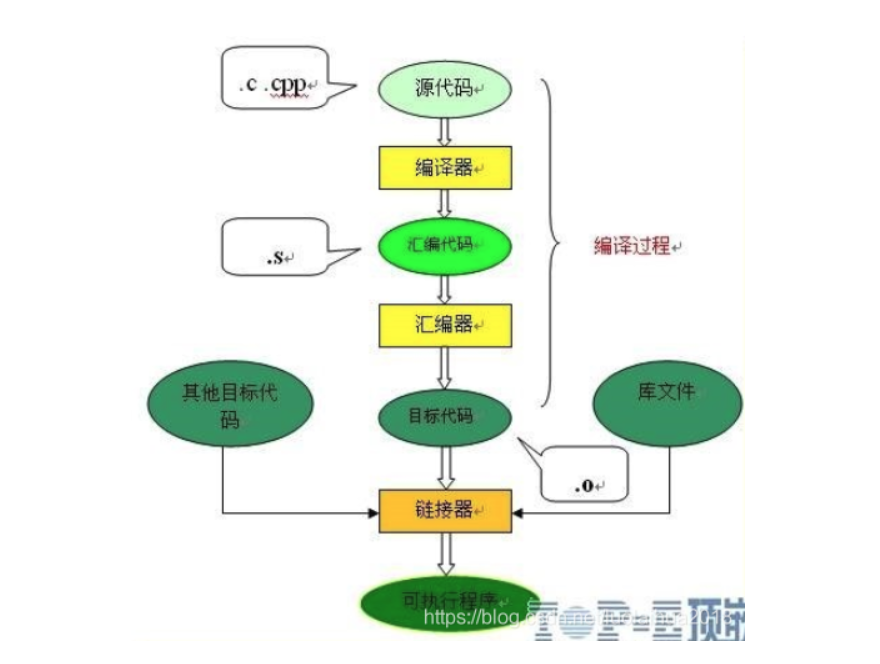
编译和链接的过程
预编译
.c生成.i文件
也叫预处理,宏替换,去掉注释,添加行号等;
编译
.i生成.s汇编文件
编译是对于预处理完的文件进行一些列的词法分析、语法分析、语义分析及优化后产生相应的汇编代码文件,内联函数替换(一种优化)在这一阶段!
汇编
.s文件转成.o文件
将汇编代码转化成机器可以执行的命令,汇编代码转换成机器指令;
前三部分用编译器 后面链接用链接器
链接
静态链接:在编译阶段就把静态库就加到可执行文件中去,这样可执行文件就会比较大。
动态链接:在链接阶段仅仅只加入一些描述信息,而程序执行时再从系统中把相应动态库加载到内存中去。
链接程序的主要工作就是将有关的目标文件彼此相连接,库函数代码,我们写的多个代码文件连接起来,合并成一个可执行程序,即可运行!
条件编译
这里的“条件”就是用IF判断是否编译的时候要执行某些操作;
有点像运行时候的if判断程序怎么运行,条件编译是if判断怎么编译;
条件编译可以用于程序DE_BUG调试,也可以防止某个头文件被重复包含;
#ifndef __TEST_H__
#define __TEST_H__
//头文件的内容
#endif //__TEST_H__ d
#pragma once //也可以防止重复包含;
操作符和关键字(4星)
volatile
volatile(易变的)是一个类型修饰符,作用是作为指令关键字,一般都是和const对应,确保本条指令不会被编译器的优化而忽略,使用这个变量时直接读取原始内存地址。
int main()
{
volatile int i = 10;
int a = i;
printf("%d", i);
//下面 汇编语句 的作用就是改变内存中i的值,但是又 不让编译器知道
__asm
{
mov dword ptr[ebp - 4], 20h
}
int b = i;
printf("i=%d", b);
return 0;
}
然后,在debug(调试)版本模式运行程序,输出结果如下:
i = 10
i = 32 //修改过后的正确的i值
relese版本下的程序会自动优化,编译器不知道汇编语句改了i的值,所以第二次给b赋值i的时候,看之前i没动过,就直接优化把之前i的缓存的10给b了,所以两次结果都是之前的10:
i = 10
i = 10//明明改了值,怎么还是之前的10?错误情况
这显然是有问题的,比如多线程程序改掉共用的一个变量,另个线程不知道,还用的之前的缓存cache,就有问题了;
所以volatile关键字声明这个变量是易变的,换句话说,每次用这个变量的时候,都得直接读取原始内存地址,不能用任何之前的cache优化了!
const
提高程序健壮性
修饰普通变量
- 与宏定义常量很像;但是宏没类型检查,const更安全;
- const可以保护被修饰的东西,防止意外修改,增强程序的健壮性
- const的常量一般不分配内存,直接放入编译符号表,效率更高;
修饰指针
const int* p; //指向常量的指针, p指向位置的内容不能被修改;
int * const p; //指针常量,p指向的位置不能修改;
const int* const p; //p的位置和位置里的内容都不能被修改;
修饰函数参数
void StringCopy(char *strDestination, const char *strSource指针指向的内容不被改变;);
//保证strSource“源”,指针指向的内容 在函数中 不被改变;
修饰函数返回值
针对返回引用或者指针的函数;
class Student {
public:
//返回左值引用,可以修改;
int& GetAge() {
return m_age;
}
//返回右值引用,不能修改;
const int& GetAgeConst() {
return m_age;
}
void ShowAge() {
cout << "Age: " << m_age << endl;
}
private:
int m_age = 0;
};
int main()
{
Student stu;
stu.ShowAge();
stu.GetAge() = 5; // 会修改成员变量的值
stu.ShowAge();
stu.GetAgeConst() = 8; // 编译器会报错,因为该返回值被const了 成为了右值;
stu.ShowAge();
return 0;
}
修饰成员函数
#include <iostream>
using namespace std;
struct A{
private:
int i;
public:
void set(int n){ //set函数需要设置i的值,所以不能声明为const
i = n;
}
int get() const{ //get函数返回i的值,不需要对i进行修改;
//则可以用const修饰。防止在函数体内对i进行修改。
//并且修饰以后,const函数也不能调用其他的非const成员函数,提升程序的健壮性;
return i;
}
};
static(结合C++)
提高程序模块性;
修饰局部变量
普通的变量在函数中或者某个作用于用完以后会被释放,下次使用它的时候重新定义;
static修饰的变量就像一个全局变量一样,作用域内用完以后不会被立即释放,和全局变量一样储存在全局区,只会被定义一次;
因为是在某作用于内部,区别于全局变量在main的外部,所以极有利于模块化了;
修饰全局变量
全局变量定义在函数体外部,在全局数据区分配存储空间,且编译器会自动对其初始化。
-
普通全局变量对整个工程可见,其他文件可以使用extern外部声明后直接使用。也就是说其他文件不能再定义一个与其相同名字的变量了(否则编译器会认为它们是同一个变量)。
-
static修饰过的全局变量只对当前文件可见,其他文件不能访问,其他文件可以定义相同名字的全局变量,两者没有影响;
定义不需要共享的全局变量时,加上static修饰,那么就能有效降低各程序文件之间的耦合度,避免全局变量名冲突;
C++
修饰数据成员
struct S
{
static int a;
};
int S::a = 10;、
S s;
//S::a or s.f()这样用
当数据成员被static修饰以后,他生命周期就随类本身了,储存在全局数据区,只有这一个,不属于任何该类的实例;
修饰成员函数
struct S
{
static int f(){
//....
};
};
int S::a = 10;
S s;
// S::f() or a.f()这样用
类似于修饰数据成员,修饰函数以后,存在全局区; 该函数不属于类的任何实例;
没有this指针!(多线程的handler函数参数就可以匹配了,不然多个this*的参数),也意味着不能访问任何数据成员了,他不属于任何实例!;