项目要求:获取某二手租房平台关于房源信息的简介和价格
代码:python编写,实现需要准备的第三方库:requests ,lxml, time
代码分析:
导入需要使用的第三方库:
import requests
import time
from lxml import etree构造方法:(代码只有在本文件中可以使用,不可被其他文件中的项目,避免了类似的文件名被重复调用的问题)
if __name__ == "__main__":伪装浏览器发起者:(伪装成使用谷歌浏览器是普通用户在使用)
#UA检测:门户网站的服务器,会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,浏览器会认为这是一个正常的用户,
#说白了就是伪装成用户通过浏览器去访问
headers = {
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36',
'Referer': 'https://www.58.com/zufang/'
}'Referer': 'https://www.58.com/zufang/'
有的网站会鉴别你是从哪里访问本网页信息,一般是你在获取图片时,它会鉴别你来到本网页以前是在那个页面,'Referer',一般大写(其实这是一种错误翻译,正确英语拼法是referrer,只是后来错误的使用习以为常,所以就按照'Referer'这样写),后面一般跟随本网站的主网页。
批量获取数据:(实现翻页获取数据)
i=0
for page_turn in range(1,2,1):
url = 'https://xa.58.com/ershoufang/p{page}/?PGTID=0d30000c-001e-3ac0-24b9-ea2c5f88d0c0&ClickID=1'.format(page=page_turn)如果你需要实现多个页面数据获取,建议你多刷新几个页面,将它们的请求地址粘贴下来分析一番
第一页请求地址:
https://xa.58.com/ershoufang/
第二页请求地址:
https://xa.58.com/ershoufang/p2/?PGTID=0d30000c-001e-359a-4d8a-60a045eac6d5&ClickID=1
第三页请求地址:
https://xa.58.com/ershoufang/p3/?PGTID=0d30000c-001e-359a-4d8a-60a045eac6d5&ClickID=1
第四页请求地址:
https://xa.58.com/ershoufang/p4/?PGTID=0d30000c-001e-359a-4d8a-60a045eac6d5&ClickID=1显然在请求地址的链接中只有,p后面跟随的数字在不断发生变化,其他数据信息都未发生变化,网页通过数字来区分此页面是第几页,p1 就是第一页,p2就是第二页,p3就是第三页,.......,有的朋友又要问第一页显然和其他页面的请求地址连接不一样啊?
那我们这样去试试,“https://xa.58.com/ershoufang/p4/?PGTID=0d30000c-001e-359a-4d8a-60a045eac6d5&ClickID=1”中的p4改为p1,试试看,能不能请求到第一页面的地址信息。

下面我改一下"https://xa.58.com/ershoufang/p4/?PGTID=0d30000c-001e-359a-4d8a-60a045eac6d5&ClickID=1"链接中的数据,将p4改为p1试试,看和我们通过:“https://xa.58.com/ershoufang/”访问的页面信息是否一样。
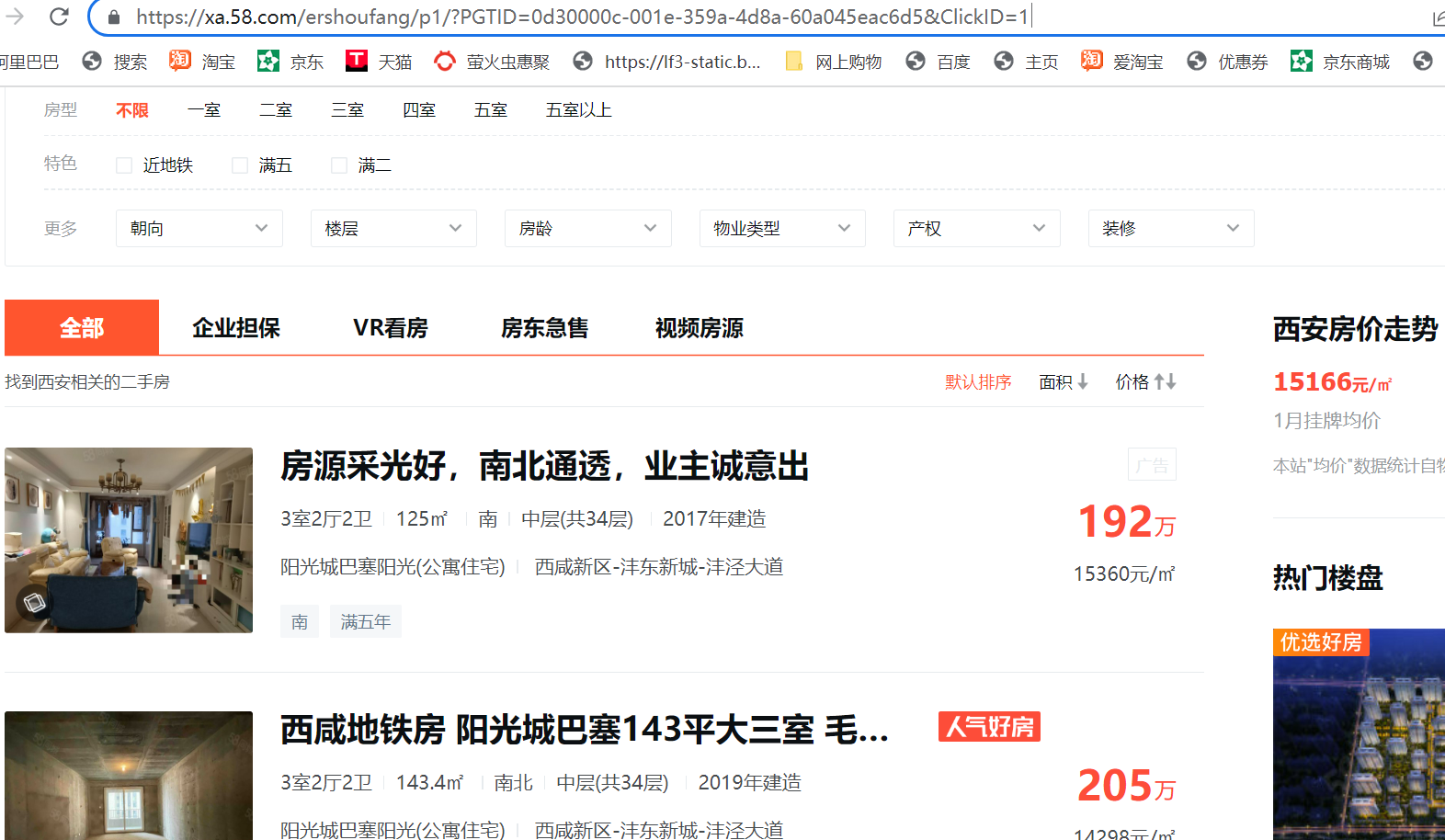
显然是一样的,这说明了什么?这种思想可以解决什么问题?
假如出现:你要获取的页面数据信息,第一页请求链接和其他例如第二页,第三页数据请求链接不一样,例如本项目,你可以通过这种方式测试一下,如果适用你可以按照本方法来,如果你修改了某些参数,它仍然访问不到预估出现的数据,你可以先把第一页页面数据拿到,然后以本项目的方法去拿到其他数据,然后把它们放在一起就好。
使用format函数修改固定位置参数,进行多个页面数据获取
i = 0
for page_turn in range(1,2,1):
url = 'https://xa.58.com/ershoufang/p{page}/?PGTID=0d30000c-001e-3ac0-24b9-ea2c5f88d0c0&ClickID=1'.format(page=page_turn)发起get请求:
page_text = requests.get(url=url,headers=headers).text页面解析:(网页数据使用 HTML)
#xpath 数据解析,解析成html页面形式,因为解析的是网页数据所以要用etree.HTML,如果解析的是本地数据etree.parse
tree = etree.HTML(page_text)用xpath方法解析html页面:
li_list = tree.xpath('//section[@class="list-main"]//section[@class="list"]')for循环遍历section[@class="list"]中所有数据信息(因为section[@class="list"]中有很多div标签)
for li in li_list:
ctiy_span=li.xpath('./a/div[2]//div[@class="property-content-title"]/h3/text()')[0]
titles = li.xpath('./a/div[2]/div[@class="property-price"]/p/span[1]/text()')[0]
每一个div标签就是一个租房信息通过for循环从section标签中,拿全部div标签,也就是获取本页面中的全部租房信息。
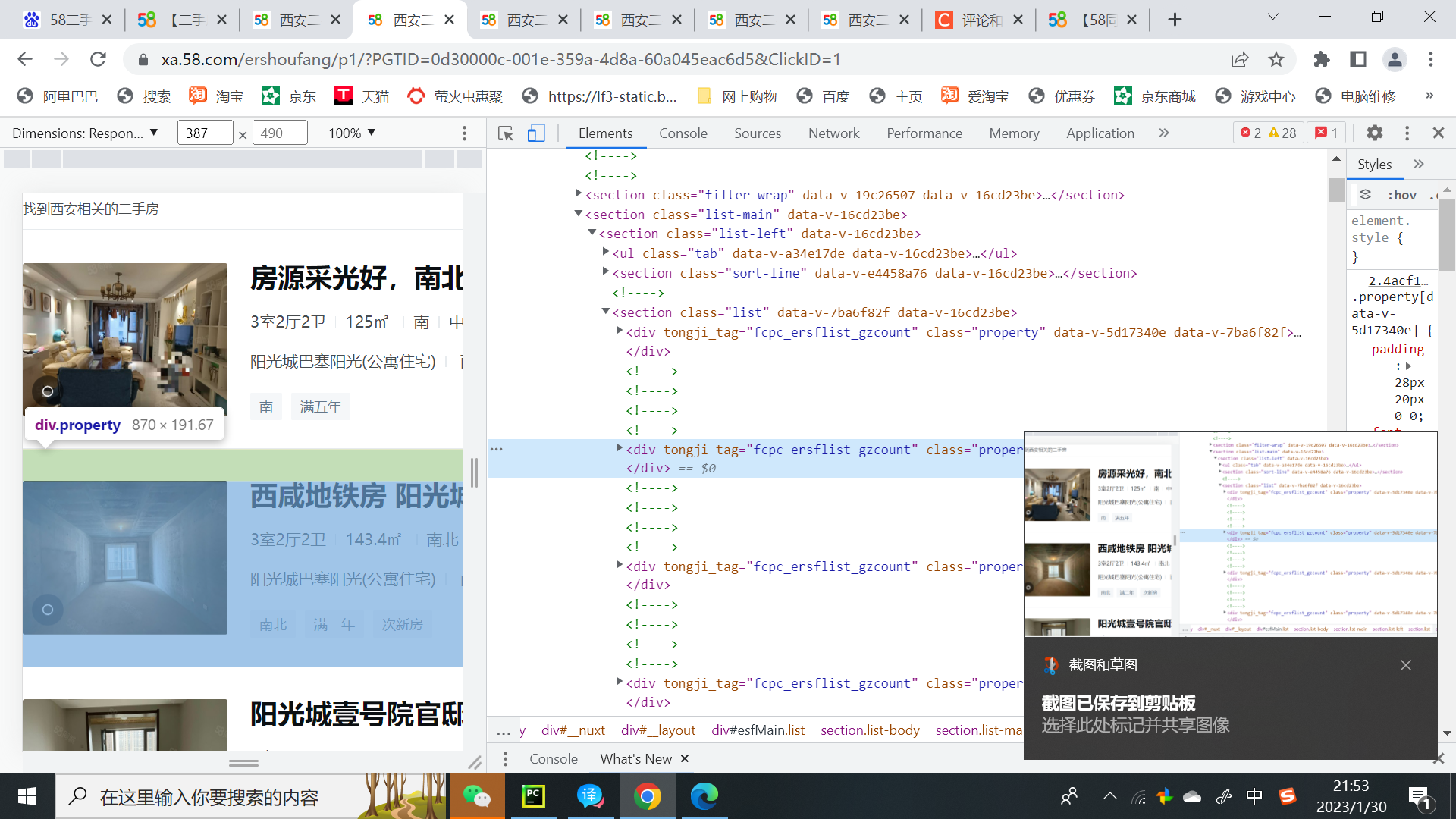
通过xpath方法解析html中租房文本信息(text() 的作用就是获取文本数据的作用):
ctiy_span=li.xpath('./a/div[2]//div[@class="property-content-title"]/h3/text()')
titles = li.xpath('./a/div[2]/div[@class="property-price"]/p/span[1]/text()')进行分页如果第一页数据拿到,通过print打印第一页数据获取完成:
i+=1
print("第{}页爬取完成".format(i))在代码的开始将i定义为0表示为未开始获取数据,通过i+=1,i自增一,来完成第一页数据完成后,打印第一页爬取完成,接下来获取第二页数据,如果获取完毕,将会打印第二页爬去完成,以此类对。
设置time函数设置休眠时间,来规避反扒虫的检测:
time.sleep(2)本项目容易诱发的问题:获取xpath 解析数据时获取到空列表
什么原因呢?被反扒机制检测到了(还是我们的伪装的不够有效,主要是我的能力有限),它会把你的爬虫请求到的页面诱导到其他位置导致你的xpath写法失效
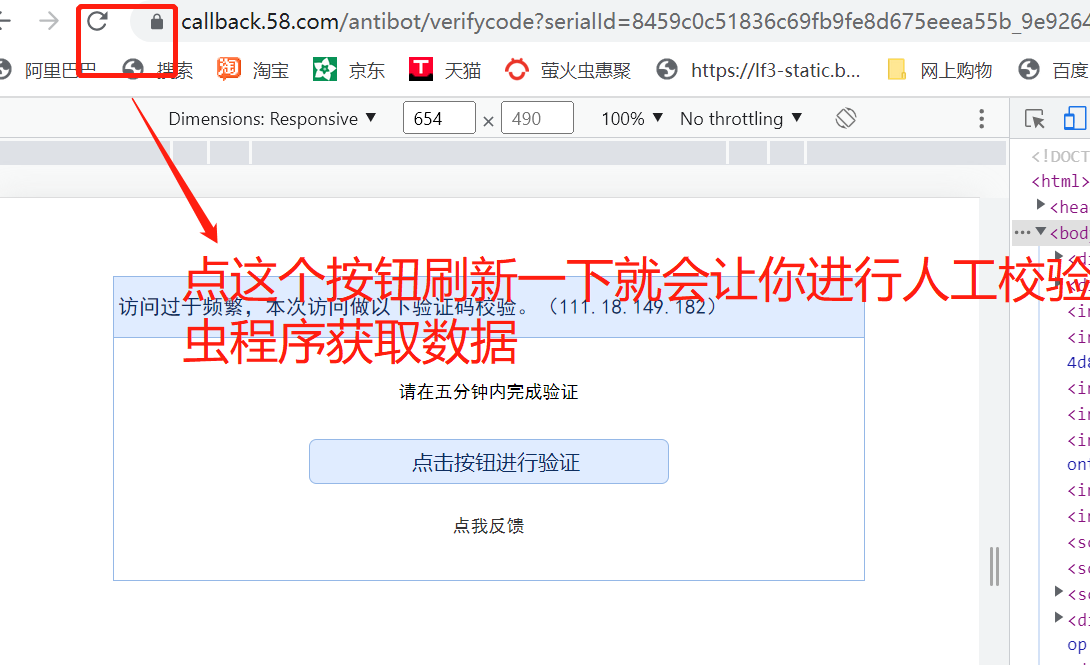
全部代码:(xpath写法哪里有点问题,获取不到数据)个人认为网站的设计设计阴阳合同,你通过阳合同的网页html,来写xpath语法,它不让你获取数据,你只有找到阴合同页面的html,来写xpath语法,这样才能获取导数据
import pprint
,
import requests
import time
from lxml import etree
if __name__ == "__main__":
#爬取页面页面数据
# https://xa.58.com/ershoufang/p2/?PGTID=0d30000c-0000-144c-1515-b98489c92dbc&ClickID=1
# https://xa.58.com/ershoufang/p3/?PGTID=0d30000c-0000-144c-1515-b98489c92dbc&ClickID=1
headers = {
'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Mobile Safari/537.36',
'Referer': 'https://www.58.com/zufang/'
}
i=0
for page_turn in range(1,2,1):
url = 'https://xa.58.com/ershoufang/p{page}/?PGTID=0d30000c-001e-3ac0-24b9-ea2c5f88d0c0&ClickID=1'.format(page=page_turn)
# print(url)
page_text = requests.get(url=url,headers=headers).text
# pprint.pprint(page_text)
#xpath 数据解析,解析成html页面形式,因为解析的是网页数据所以要用etree.HTML,如果解析的是本地数据etree.parse
tree = etree.HTML(page_text)
# print(tree)
#用xpath方法解析html页面,为什么拿到的是li标签呢? 因为所有的租房简介在ul中,ul下层有很多li标签,一个li标签就是一个租房信息简介
li_list = tree.xpath('//section[@class="list-main"]//section[@class="list"]')
li_lists = tree.xpath('//*[@id="esfMain"]/section/section[3]/section[1]/section[2]/div[1]/a/div[2]/div[1]/div[1]/h3/text()')
print(li_lists)
#
all_city_name = []
for li in li_list:
ctiy_span=li.xpath('./a/div[2]//div[@class="property-content-title"]/h3/text()')[0]
print(ctiy_span)
# titles = li.xpath('./a/div[2]/div[@class="property-price"]/p/span[1]/text()')[0]
# # print(titles)
# all_city_name.append(ctiy_span)
# all_city_name.append(titles)
# i+=1
# print("第{}页爬取完成".format(i))
time.sleep(2)
# print(all_city_name)
阳合同页面:(文本信息在h3标签里)

阴合同页面:(文本信息在span标签中)

通过查看阴合同的html页面,来写xpath语法是没有任何的可以获取到数据。
总结:(论语二则)
子在川上曰:“逝者如斯夫,不舍昼夜。”《子罕》
君子站在河流穿过河谷中说:流逝的一切如同奔流不息的河水,不分白天与黑夜
子夏曰:“博学而笃志,切问而近思,仁在其中矣。”《子张》
卜商(子夏)说:广泛的获取知识,且坚定自己的志向,恳切地提问且多考虑当前的事情,仁德就体现在当前这些事情中。











![[Vulnhub] DC-8](https://img-blog.csdnimg.cn/42e66e11668a4f9bbe7c166fc27b9848.png)
