文章目录
- 单元测试框架
- 如何引入
- 如何使用
- 测试相关
- SUBCASE
- TEST_SUITE
- TEST_CASE_FIXTURE
- TEST_CASE_TEMPLATE
- 断言相关
- 常用断言宏
- 常用工具函数
- benchmark框架
- 如何引入
- 如何使用
- 防止被优化
- 优化不稳定
- 比较测试结果
- 计算BigO
- 输出结果到其他格式
- CLion中查看测试覆盖率
- CLion中使用sanitizers检测内存错误
- 环境准备
- 如何使用
- 内存泄漏检测(leak)
- 内存访问错误检测(address)
- 多线程数据竞争检测(thread)
- CLion中使用perf生成火焰图
- 环境准备
- 如何使用
单元测试框架
google test是一个C++中常用且历史悠久的测试框架,其他类似且较新的测试框架有 catch2 或 doetest等,这两个测试框架的优势在于引入简单,是完全 head only 的,但是也正是因为 head only 导致编译速度很慢,当然 doctest 还是挺快的,但 catch2 真的编译太慢了。而 googletest 引入就需要我们自行编译了,当然用cmake的话是可以简化这个过程的,gtest 的使用和引入其实也很简单,由于是直接链接编译好的库,所以编译速度是比较快的(最近测试了下,同样以链接库的方式比 doctest 慢一些… )。我现在更推荐使用 doctest 而不是 gtest 了。
本来是想讲 Google test 的使用的(看我开篇就知道),但是使用了 doctest 后,我现在完全放弃了 Googletest,对我而言有以下几点非常好:
- 文件轻量,非常轻量,就几个文件,而且代码量好像就7000行,编译速度奇快,而相对的 Googletest 里包含的东西有点多,比如 gmock,对比起来略显重量级。
- CLion 对 doctest 的支持更好,每次我用 Googletest 的时候,CLion都需要重新我当前使用的测试框架,而使用doctest后,则完全没有这方面困扰,反应奇快,这也是轻量带来的好处。
- api超级友好,用过就真的回不去。虽然断言宏不是很多,但核心观点是它分解了比较表达式,所以会比其他框架用起来方便太多。
- 功能丰富(比如支持对模板进行批量测试),尽管代码轻量,但是功能也毫不含糊,感觉比googletest更好用。
如何引入
正如上述所说,doctest 是head-only的,所以仅仅只需要一个 .h 文件即可,但是我建议不要这样,这样编译速度会慢一些,建议使用编译库再链接的方式,这种方式在cmake里面也很简单,如果不懂cmake,可以看看我这期视频:cmake入门 。
你只需在cmake项目中添加下列代码:
include(FetchContent)
FetchContent_Declare(
doctest
GIT_REPOSITORY https://github.com/doctest/doctest.git
GIT_TAG v2.4.9
GIT_SHALLOW TRUE
)
FetchContent_MakeAvailable(doctest)
target_link_libraries(target doctest_with_main)
这里的仓库链接由于是GitHub上,如果你不会科学上网的话,建议可以去手动下载GitHub上的代码然后 add_subdirectory() 也是一样的。当然也可以把对应的仓库在gitee上创建一个镜像,那么你就可以直接把上面的 GIT_REPOSITORY 换成你镜像的地址了,比如我拉了一个镜像地址如下:https://gitee.com/acking-you/doctest.git 替换即可。
如何使用
开始前,你可以直接去看官方文档,写的也挺详细:官方文档
首先,我们要清楚,一个测试框架,你需要注意的就只有两点:
- 如何组织测试 -> 测试宏
- 如何进行测试断言 -> 断言宏
通过下面这个简单的测试进行一个简单的讲解:
//这个宏如果是通过链接的方式引入库的话千万不要加,如果是通过直接的include头文件引入的则需要加入
//#define DOCTEST_CONFIG_IMPLEMENT_WITH_MAIN
#include "doctest.h"
int factorial(int number) { return number <= 1 ? number : factorial(number - 1) * number; }
TEST_CASE("testing the factorial function") {
CHECK(factorial(1) == 1);
CHECK(factorial(2) == 2);
CHECK(factorial(3) == 6);
CHECK(factorial(10) == 3628800);
}
上述代码是在测试斐波那契数列的值。
-
通过
TEST_CASE这个宏来组织一个测试,参数是该测试的名字是一个字符串值,在CLion中会以这个名字来标识这个测试。与googletest相比,对应的是TEST宏,但不同的是 googletest 需要传两个参数,两个都不是字符串,而且必须符合C++变量命名的字符规则,所以不能以空格或者其他非字母数字的任何符号放在其中,这点其实很不方便。 -
通过
CHECK宏来进行断言判断,如果失败了CLion中会有对应的提示。参数是一个判断表达式,不要小看这个宏,它是默认支持几乎所有内置的类型,并且包括stl容器。对应的 googletest 一般使用EXPECT_EQ()传递两个参数来进行比较,默认不支持const char*类型,需要使用EXPECT_STREQ,而 doctest 则不需要有这方面的考虑,只需要关注这个CHECK宏即可,当然它也有对应的CHECK_XX宏。
测试相关
经过一个小demo的讲解,那么大家对于测试宏有了一定的了解,下面将继续介绍更多的测试宏。
SUBCASE
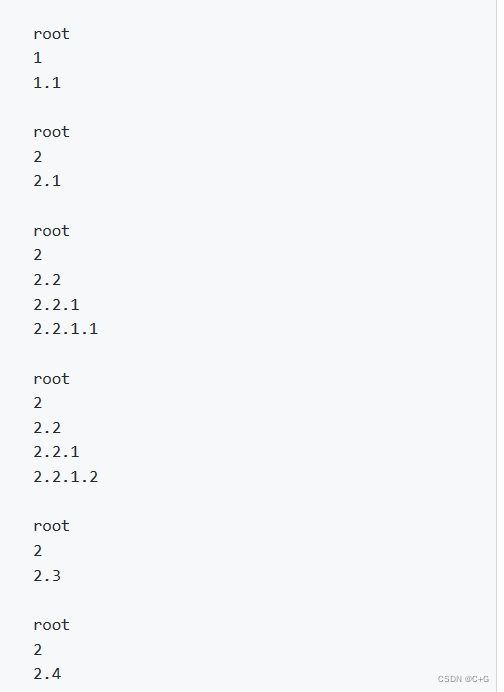
这个宏用于在TEST_CASE中继续产生更小的分组,然后你可以安全的捕获到外界的变量来使用。因为每个SUBCASE都是完全独立的重新执行,而不是在同一次执行,比如我将下面的代码块分为1、2、3,那么第一个SUBCASE的顺序将会是 1->2->结束 ,第二个SUBCASE的执行顺序将会是 1->3->结束 。如果最外层的代码在 SUBCASE 后面,那么不会被执行,所有的 SUBCASE 执行情况,我们可以看作是从一个树的根节点到子节点的简单遍历,但每次遍历没有前后文关系(也就是每次遍历都是重新执行的)
TEST_CASE("vectors can be sized and resized") {
std::vector<int> v(5);
//1
REQUIRE(v.size() == 5);
REQUIRE(v.capacity() >= 5);
SUBCASE("adding to the vector increases it's size") {
//2
v.push_back(1);
CHECK(v.size() == 6);
CHECK(v.capacity() >= 6);
}
SUBCASE("reserving increases just the capacity") {
//3
v.reserve(6);
CHECK(v.size() == 5);
CHECK(v.capacity() >= 6);
}
}
例如下面这个例子将会输出:
TEST_CASE("lots of nested subcases") {
cout << endl << "root" << endl;
SUBCASE("") {
cout << "1" << endl;
SUBCASE("") { cout << "1.1" << endl; }
}
SUBCASE("") {
cout << "2" << endl;
SUBCASE("") { cout << "2.1" << endl; }
SUBCASE("") {
cout << "2.2" << endl;
SUBCASE("") {
cout << "2.2.1" << endl;
SUBCASE("") { cout << "2.2.1.1" << endl; }
SUBCASE("") { cout << "2.2.1.2" << endl; }
}
}
SUBCASE("") { cout << "2.3" << endl; }
SUBCASE("") { cout << "2.4" << endl; }
}
}
TEST_SUITE
test suite表示测试集,顾名思义,就是可以把 test case 分组。
比如可以这样写:
TEST_SUITE("math") {
TEST_CASE("") {} // part of the math test suite
TEST_CASE("") {} // part of the math test suite
}
也可以分开用 TEST_SUITE_BEGIN 和 TEST_SUITE_END 宏来实现:
TEST_SUITE_BEGIN("utils");
TEST_CASE("") {} // part of the utils test suite
TEST_SUITE_END();
TEST_CASE("") {} // not part of any test suite
分组后的好处当然是可以直接分组执行了。
TEST_CASE_FIXTURE
这个宏是用来直接测试某个类的方法的,相当于是通过继承的方式创建了一个新的类,所以 protect 修饰的东西都能访问,比如:
class UniqueTestsFixture
{
private:
static int uniqueID;
protected:
int conn;
public:
UniqueTestsFixture()
: conn(10)
{
}
protected:
static int getID()
{
return ++uniqueID;
}
};
int UniqueTestsFixture::uniqueID = 0;
TEST_CASE_FIXTURE(UniqueTestsFixture, "test get ID")
{
REQUIRE(getID() == conn);
}
TEST_CASE_TEMPLATE
这个宏是用来测试模板的,如果需要测试的模板功能有共通性,只是类型不一致,那么你可以减少重复劳动,直接用这个宏来帮忙实例化再测试。
比如下列代码测试了 std::any 对于接收字符串类型和整数类型的情况测试:
TEST_CASE_TEMPLATE("test std::any as integer", T, char, short, int, long long int) {
auto v = T();
std::any var = T();
CHECK(std::any_cast<T>(var)==v);
}
TEST_CASE_TEMPLATE("test std::any as string", T, const char*, std::string_view, std::string) {
T v = "hello world";
std::any var = v;
CHECK(std::any_cast<T>(var)==v);
}
也可用 TEST_CASE_TEMPLATE_DEFINE 先定义一个模板测试,后面再用 TEST_CASE_TEMPLATE_INVOKE 来决定实例化模板的类型:
TEST_CASE_TEMPLATE_DEFINE("test std::any as integer", T,integer) {
auto v = T();
std::any var = T();
CHECK(std::any_cast<T>(var)==v);
}
TEST_CASE_TEMPLATE_DEFINE("test std::any as string", T,string) {
T v = "hello world";
std::any var = v;
CHECK(std::any_cast<T>(var)==v);
}
TEST_CASE_TEMPLATE_INVOKE(integer, char, short, int, long long int);
TEST_CASE_TEMPLATE_INVOKE(string, const char*, std::string_view, std::string);
断言相关
doctest的断言宏是很有规律的,它的设计我之前也提到过,是一种尽量以表达式的方式去简化对api的记忆,你只需要清楚三个断言的等级即可,当然如果想要直接通过对应的类似于 gtest 的 EXPECT_XXX 之类的api来进行断言,实际上也是有的。
断言宏一共有以下三个等级:
- REQUIRE:这个等级算是最高的,如果断言失败,不仅会标记为测试不通过,而且会强制退出测试(也就是后续的测试将不会再进行)。
- CHECK:如果断言失败,标记为测试不通过,但不会强制退出(也就是后续的测试还是会执行)。
- WARN:如果断言失败,不会标记测试不通过,也不会强制退出,但是会给出对应的提示。
常用断言宏
下面为常见的宏使用,使用这些宏比直接使用表达式的编译速度要快一点。
<LEVEL> 表示 REQUIRE、CHECK、WARN 三个等级。
<LEVEL>_EQ(left, right)- same as<LEVEL>(left == right)<LEVEL>_NE(left, right)- same as<LEVEL>(left != right)<LEVEL>_GT(left, right)- same as<LEVEL>(left > right)<LEVEL>_LT(left, right)- same as<LEVEL>(left < right)<LEVEL>_GE(left, right)- same as<LEVEL>(left >= right)<LEVEL>_LE(left, right)- same as<LEVEL>(left <= right)<LEVEL>_UNARY(expr)- same as<LEVEL>(expr)<LEVEL>_UNARY_FALSE(expr)- same as<LEVEL>_FALSE(expr)
小提示:在引入头文件之前定义
DOCTEST_CONFIG_SUPER_FAST_ASSERTS这个宏,也可以提升编译速度。
<LEVEL>_MESSAGE :这个宏用于在错误的适合你可以设置对应的提示信息。
同样,你可以为了方便,先通过 INFO 宏来进行提示消息的预设,然后只要出现测试失败,都会提示这个预设的消息。
CHECK_MESSAGE(2==1,"not valid");
比如上面的代码可以用 INFO 宏,写成下面这样:
INFO("not valid")
CHECK(2==1);
常用工具函数
doctest::Contains() 用于判断字符串是包含这其中的字符。
比如下面这个例子:
REQUIRE("foobar" == doctest::Contains("foo"));
doctest::Approx() 用于更精确的比较浮点数。
比如下面这个例子:
REQUIRE(22.0/7 == doctest::Approx(3.141).epsilon(0.01)); // allow for a 1% error
benchmark框架
关于benchmark,我建议使用 nanobench ,同样也是因为引入简单轻量,使用简单且 head only 。
官方文档如下:https://nanobench.ankerl.com/tutorial.html#usage
如何引入
其实官方文档已经介绍了如何引入,它也是推荐使用下面的方式进行引入:
cmake_minimum_required(VERSION 3.14)
set(CMAKE_CXX_STANDARD 17)
project(
CMakeNanobenchExample
VERSION 1.0
LANGUAGES CXX)
include(FetchContent)
FetchContent_Declare(
nanobench
GIT_REPOSITORY https://github.com/martinus/nanobench.git
GIT_TAG v4.1.0
GIT_SHALLOW TRUE)
FetchContent_MakeAvailable(nanobench)
add_executable(MyExample my_example.cpp)
target_link_libraries(MyExample PRIVATE nanobench)
如何使用
使用非常简单,不依赖于宏,而是使用对应的类的成员函数。
比如:
#include <nanobench.h>
#include <atomic>
int main() {
int y = 0;
std::atomic<int> x(0);
ankerl::nanobench::Bench().run("compare_exchange_strong", [&] {
x.compare_exchange_strong(y, 0);
});
}
输出如下:

可以看得出来,上述的输出结果其实可以直接copy到markdown中,会被渲染为表格。
- ns/op:每个bench内容需要经历的时间(ns为单位)。
- op/s:每秒可以执行多少次操作。
- err%:运行多次测试的波动情况(误差)。
- ins/op:每次操作需要多少条指令。
- cyc/op:每次操作需要多少次时钟周期。
- bra/op:每次操作有多少次分支预判。
- miss%:分支预判的miss率。
- total:本次消耗的总时间。
- benchmark:对应的名字。
对于不同的机器上述的指标支持程度略有不同,官方的描述为:
CPU statistics like instructions, cycles, branches, branch misses are only available on Linux, through perf events. On some systems you might need to change permissions through
perf_event_paranoidor use ACL.
防止被优化
如下示例:
#include <nanobench.h>
#include <thirdparty/doctest/doctest.h>
TEST_CASE("tutorial_fast_v1") {
uint64_t x = 1;
ankerl::nanobench::Bench().run("++x", [&]() {
++x;
});
}
可能无法输出结果,因为x被优化了,所以可以改为下面这样:
#include <nanobench.h>
#include <doctest/doctest.h>
TEST_CASE("tutorial_fast_v2") {
uint64_t x = 1;
ankerl::nanobench::Bench().run("++x", [&]() {
ankerl::nanobench::doNotOptimizeAway(x += 1);
});
}
优化不稳定
有些时候输出结果会提示你测试不稳定,你可以按照提示增加 minEpochIterations 。
比如:
#include <nanobench.h>
#include <doctest/doctest.h>
#include <random>
TEST_CASE("tutorial_fluctuating_v1") {
std::random_device dev;
std::mt19937_64 rng(dev());
ankerl::nanobench::Bench().run("random fluctuations", [&] {
// each run, perform a random number of rng calls
auto iterations = rng() & UINT64_C(0xff);
for (uint64_t i = 0; i < iterations; ++i) {
ankerl::nanobench::doNotOptimizeAway(rng());
}
});
}
输出如下:

我们按照提示修改代码如下:
#include <nanobench.h>
#include <doctest/doctest.h>
#include <random>
TEST_CASE("tutorial_fluctuating_v2") {
std::random_device dev;
std::mt19937_64 rng(dev());
ankerl::nanobench::Bench().minEpochIterations(5000).run(
"random fluctuations", [&] {
// each run, perform a random number of rng calls
auto iterations = rng() & UINT64_C(0xff);
for (uint64_t i = 0; i < iterations; ++i) {
ankerl::nanobench::doNotOptimizeAway(rng());
}
});
}
结果果然稳定了。
比较测试结果
有时候我们需要对很多测试结果进行比较,在 nanobench 中,很容易做到,只要共用同一个 Bench 对象即可,在开始的时候调用对应的方法。
比如官方给出了一个对比不同随机数生成器的性能的例子:完整代码:example_random_number_generators.cpp
private:
static constexpr uint64_t rotl(uint64_t x, unsigned k) noexcept {
return (x << k) | (x >> (64U - k));
}
uint64_t stateA;
uint64_t stateB;
};
namespace {
// Benchmarks how fast we can get 64bit random values from Rng.
template <typename Rng>
void bench(ankerl::nanobench::Bench* bench, char const* name) {
std::random_device dev;
Rng rng(dev());
bench->run(name, [&]() {
auto r = std::uniform_int_distribution<uint64_t>{}(rng);
ankerl::nanobench::doNotOptimizeAway(r);
});
}
} // namespace
TEST_CASE("example_random_number_generators") {
// perform a few warmup calls, and since the runtime is not always stable
// for each generator, increase the number of epochs to get more accurate
// numbers.
ankerl::nanobench::Bench b;
b.title("Random Number Generators")
.unit("uint64_t")
.warmup(100)
.relative(true);
b.performanceCounters(true);
// sets the first one as the baseline
bench<std::default_random_engine>(&b, "std::default_random_engine");
bench<std::mt19937>(&b, "std::mt19937");
bench<std::mt19937_64>(&b, "std::mt19937_64");
bench<std::ranlux24_base>(&b, "std::ranlux24_base");
bench<std::ranlux48_base>(&b, "std::ranlux48_base");
bench<std::ranlux24>(&b, "std::ranlux24_base");
bench<std::ranlux48>(&b, "std::ranlux48");
bench<std::knuth_b>(&b, "std::knuth_b");
bench<WyRng>(&b, "WyRng");
bench<NasamRng>(&b, "NasamRng");
bench<Sfc4>(&b, "Sfc4");
bench<RomuTrio>(&b, "RomuTrio");
bench<RomuDuo>(&b, "RomuDuo");
bench<RomuDuoJr>(&b, "RomuDuoJr");
bench<Orbit>(&b, "Orbit");
bench<ankerl::nanobench::Rng>(&b, "ankerl::nanobench::Rng");
}
我们需要注意的几个关键方法:
unit:用于将原本默认的xx/op中的 op 替换为自定义的字符串。warmup:在测试开始之前进行预热的次数,也就是先执行这么些次数,不会计入最终数据。relative:设置为 true 之后,再run,之后的所有run都会以这个为基准线做对比。performanceCounters:是否测试ins/op、bra/op、miss%。
上述测试结果如下:
| relative | ns/uint64_t | uint64_t/s | err% | ins/uint64_t | bra/uint64_t | miss% | total | Random Number Generators |
|---|---|---|---|---|---|---|---|---|
| 100.0% | 31.42 | 31,828,534.72 | 5.0% | 219.22 | 20.48 | 1.4% | 0.00 | std::default_random_engine |
| 266.3% | 11.80 | 84,745,762.71 | 9.3% | 155.67 | 18.01 | 0.1% | 0.00 | 〰️ std::mt19937 (Unstable with ~1,685.8 iters. Increase minEpochIterations to e.g. 16858) |
| 1,019.7% | 3.08 | 324,567,855.83 | 6.6% | 34.63 | 1.50 | 0.2% | 0.00 | 〰️ std::mt19937_64 (Unstable with ~7,097.7 iters. Increase minEpochIterations to e.g. 70977) |
| 148.9% | 21.11 | 47,380,744.69 | 2.3% | 204.09 | 19.00 | 0.0% | 0.00 | std::ranlux24_base |
| 171.1% | 18.36 | 54,456,268.71 | 1.4% | 143.51 | 14.00 | 2.9% | 0.00 | std::ranlux48_base |
| 47.1% | 66.76 | 14,979,338.84 | 22.8% | 799.13 | 50.23 | 0.6% | 0.00 | 〰️ std::ranlux24_base (Unstable with ~293.1 iters. Increase minEpochIterations to e.g. 2931) |
| 18.2% | 172.82 | 5,786,199.91 | 21.7% | 1,744.87 | 85.30 | 0.3% | 0.00 | 〰️ std::ranlux48 (Unstable with ~118.9 iters. Increase minEpochIterations to e.g. 1189) |
| 64.6% | 48.64 | 20,558,002.94 | 1.1% | 289.60 | 20.41 | 1.2% | 0.00 | std::knuth_b |
| 1,665.9% | 1.89 | 530,227,329.50 | 0.1% | 10.00 | 0.00 | 63.4% | 0.00 | WyRng |
| 1,293.7% | 2.43 | 411,770,089.69 | 7.4% | 23.00 | 0.00 | 100.0% | 0.00 | 〰️ NasamRng (Unstable with ~9,712.3 iters. Increase minEpochIterations to e.g. 97123) |
| 1,197.4% | 2.62 | 381,101,236.99 | 0.1% | 20.00 | 0.00 | 100.0% | 0.00 | Sfc4 |
| 1,243.4% | 2.53 | 395,763,921.94 | 0.1% | 15.00 | 0.00 | 100.0% | 0.00 | RomuTrio |
| 1,193.0% | 2.63 | 379,720,219.70 | 1.1% | 14.00 | 0.00 | 100.0% | 0.00 | RomuDuo |
| 1,268.4% | 2.48 | 403,703,084.51 | 1.0% | 11.00 | 0.00 | 100.0% | 0.00 | RomuDuoJr |
| 1,511.6% | 2.08 | 481,135,323.92 | 0.7% | 23.00 | 2.00 | 0.0% | 0.00 | Orbit |
| 1,309.5% | 2.40 | 416,799,283.87 | 0.4% | 11.00 | 0.00 | 100.0% | 0.00 | ankerl::nanobench::Rng |
计算BigO
计算BigO也很简单,只需要模拟一个数据,然后将其中的 n 传入 complexityN 方法中,然后再run,它会输出对应的结果。
下面是一个测试 std::set::find BigO的代码:
#include <nanobench.h>
#include <doctest/doctest.h>
#include <iostream>
#include <set>
TEST_CASE("tutorial_complexity_set_find") {
// Create a single benchmark instance that is used in multiple benchmark
// runs, with different settings for complexityN.
ankerl::nanobench::Bench bench;
// a RNG to generate input data
ankerl::nanobench::Rng rng;
std::set<uint64_t> set;
// Running the benchmark multiple times, with different number of elements
for (auto setSize :
{10U, 20U, 50U, 100U, 200U, 500U, 1000U, 2000U, 5000U, 10000U}) {
// fill up the set with random data
while (set.size() < setSize) {
set.insert(rng());
}
// Run the benchmark, provide setSize as the scaling variable.
bench.complexityN(set.size()).run("std::set find", [&] {
ankerl::nanobench::doNotOptimizeAway(set.find(rng()));
});
}
// calculate BigO complexy best fit and print the results
std::cout << bench.complexityBigO() << std::endl;
}
上述先是模拟了一个set不断被插入,从 10 ~ 10k 的数据规模,所有数据的输入都是使用 nanobench 中提供的 Rng 类来生成随机数。
最终结果如下:
| coefficient | err% | complexity |
|---|---|---|
| 3.4946962e-09 | 46.5% | O(log n) |
| 8.0377807e-12 | 62.9% | O(n) |
| 6.0188709e-13 | 67.6% | O(n log n) |
| 2.6440637e-08 | 77.4% | O(1) |
| 7.3746892e-16 | 87.8% | O(n^2) |
| 6.7357968e-20 | 97.0% | O(n^3) |
输出结果到其他格式
nanobench还支持将测试结果输出到其他文件格式,比如csv、json,或者html形成可视化界面。
还能输出到 pyperf 中进行进一步性能分析。
具体就不讲了,大家看文档:https://nanobench.ankerl.com/tutorial.html#rendering-mustache-like-templates
CLion中查看测试覆盖率
关于测试覆盖率,截一段chatgpt的对话:
其实测试覆盖率是几乎所有编译器自带的功能(CLion中暂时不支持msvc,mingw是支持的),但是需要在编译的时候加入对应的参数,但不同的编译器参数很多很繁杂,CLion就为我们提供了便利性,使用CLion你只需要点击两下鼠标就行了。
第一次点击鼠标:用于CLion帮我们生成对应的coverage配置项。
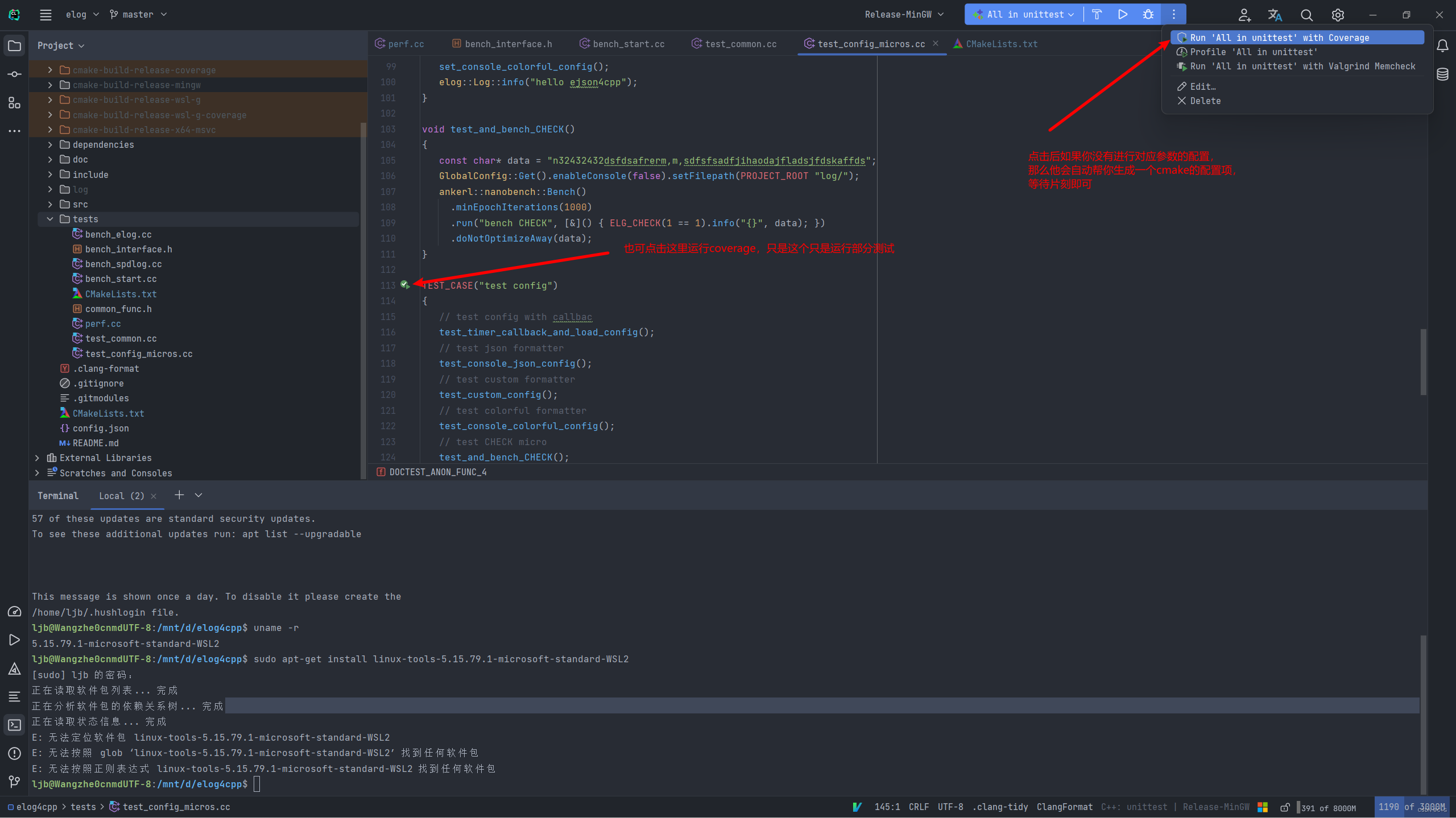
第二次点击鼠标:用于运行coverage配置项生成覆盖率数据,然后CLion将会有图形化显示。
已经生成好了对应的配置项,用对应配置项去运行这个测试即可得出结果如下:
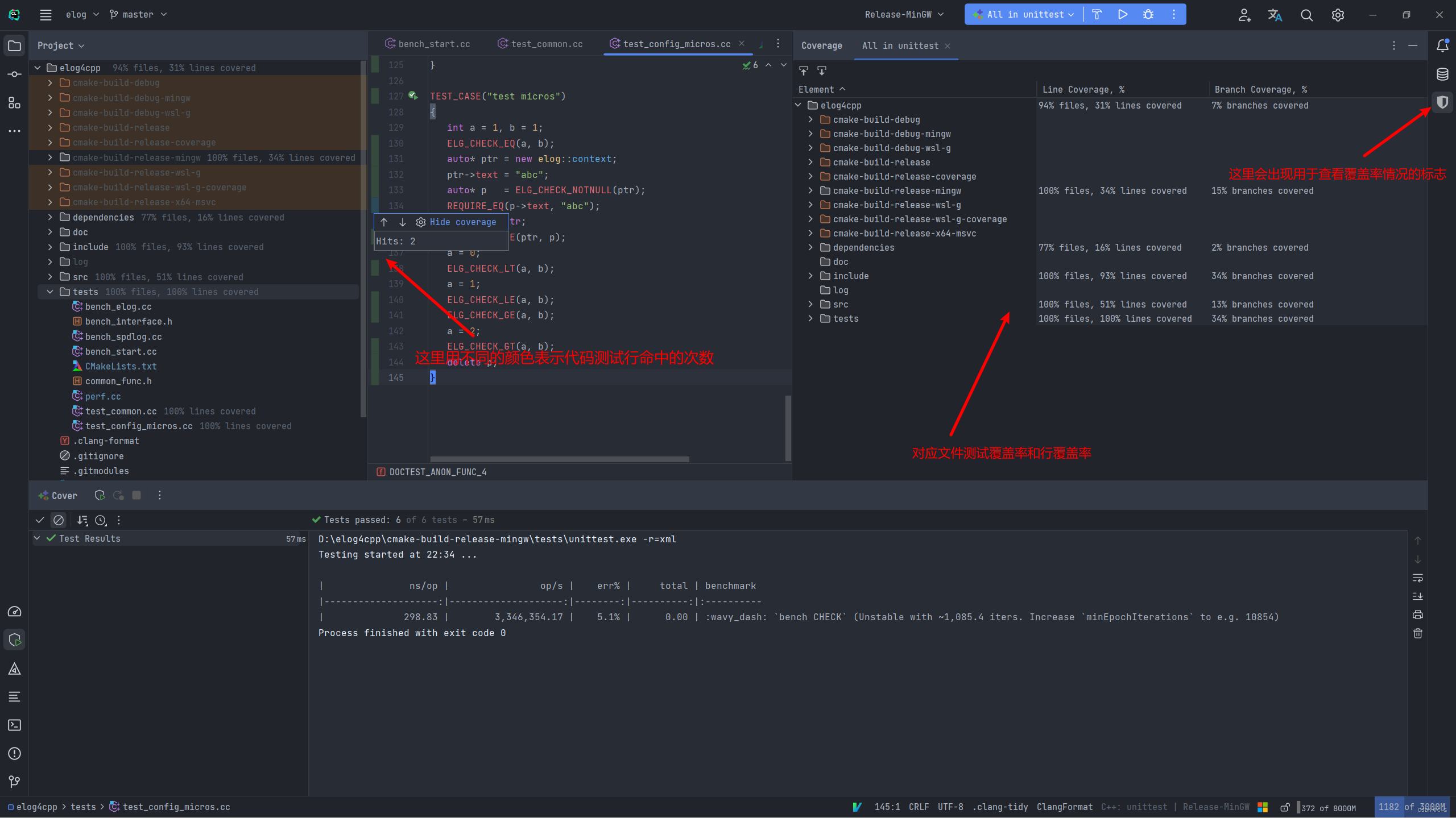
当然你也可以自己在配置项里面添加对应的编译器flag,下面是gcc编译器的flag,别的编译器有所不同,所以CLion提供了自动帮我们生成配置项的功能。
-DCMAKE_CXX_FLAGS="--coverage"
CLion中使用sanitizers检测内存错误
关于sanitizer是什么,可以看下面这段chatgpt的截图:

现在其实在clang/gcc中已经自带了这个功能,只需要在编译时加入编译选项 -fsanitize 即可(亲测Windows下的mingw里的gcc并不支持)。
整个所有的 sanitize 功能如下:
AddressSanitizer(ASan):检测内存访问错误,如越界访问和使用释放的内存。它通过在程序执行期间在内存中插入虚拟填充来实现这一点,并在程序试图访问这些填充时生成错误消息。LeakSanitizer(LSan):检测内存泄漏,即程序未释放的内存。它通过跟踪程序中的每个动态分配来实现这一点,并在程序结束时生成报告。ThreadSanitizer(TSan):检测多线程程序中的数据竞争。它通过在程序执行期间跟踪线程之间的共享变量访问来实现这一点,并在发现竞争时生成错误消息。UndefinedBehaviorSanitizer(UBSan):检测未定义行为,如类型转换错误和溢出。它通过在程序执行期间插入检查代码来实现这一点,并在发现错误时生成错误消息。MemorySanitizer(MSan):检测未初始化内存的使用,这是一个非常隐蔽的错误,它通过在程序中所有未初始化内存插入值来实现这一点,并在程序试图使用这些值时生成错误消息。
其实上述的 memory 和 ub 问题的检测,在CLion中你还未编译时就已经给出了提示。
环境准备
官方文档在这:https://www.jetbrains.com/help/clion/google-sanitizers.html,如果是windows环境可以通过安装clang-cl编译器来得到 AddressSanitizer 的能力,具体操作在这个文档中:https://www.jetbrains.com/help/clion/quick-tutorial-on-configuring-clion-on-windows.html#clang-cl
如果是 Linux/wsl/macos 环境使用 gcc/clang 都可以得到 AddressSanitizer 、LeakSanitizer 、ThreadSanitizer、 UndefinedBehaviorSanitizer 的能力。
我推荐使用clang,至少在我的wsl上gcc的 ThreadSanitizer 能力是错误的。
如何安装clang环境就非常简单了,apt install即可。
如何使用
其实使用对应的能力很简单,只需要在编译选项中加入对应的参数即可。
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=[sanitizer_name] [-g] [-OX]")
下面这些是 [sanitizer_name] 对应的选项:
address:表示开启 AddressSanitizerleak: 表示开启LeakSanitizerthread: 表示开启 ThreadSanitizerundefined: 表示开启UndefinedBehaviorSanitizer (other options are also available, see the UBSan section)memory: 表示开启MemorySanitizer
-g 是用来生成调试信息的,建议不要再选项里面加,因为CLion会根据cmake配置项里的 Release/Debug 模式来自动加上,所以你不要画蛇添足,这样会出错,加入调试信息可以让最终收集到的信息有具体的源码位置,方便我们查看分析的结果。
-ox 是优化选项,比如 -o1 -o2之类的,这个也不用管,CLion同样也是根据cmake配置项里的信息生成,比如Release就是-o3,Debug就是-o2。
设置哈对应的编译参数后,我们对需要分析的程序运行一次即可,然后CLion中就会出现图形化的结果。
内存泄漏检测(leak)
比如我现在有下面这段内存泄漏代码,我开了 -fsanitize=leak 并且为Debug模式 :
int main(){
auto* p = new int(3234);
(void)p;
}
最终的结果图如下:
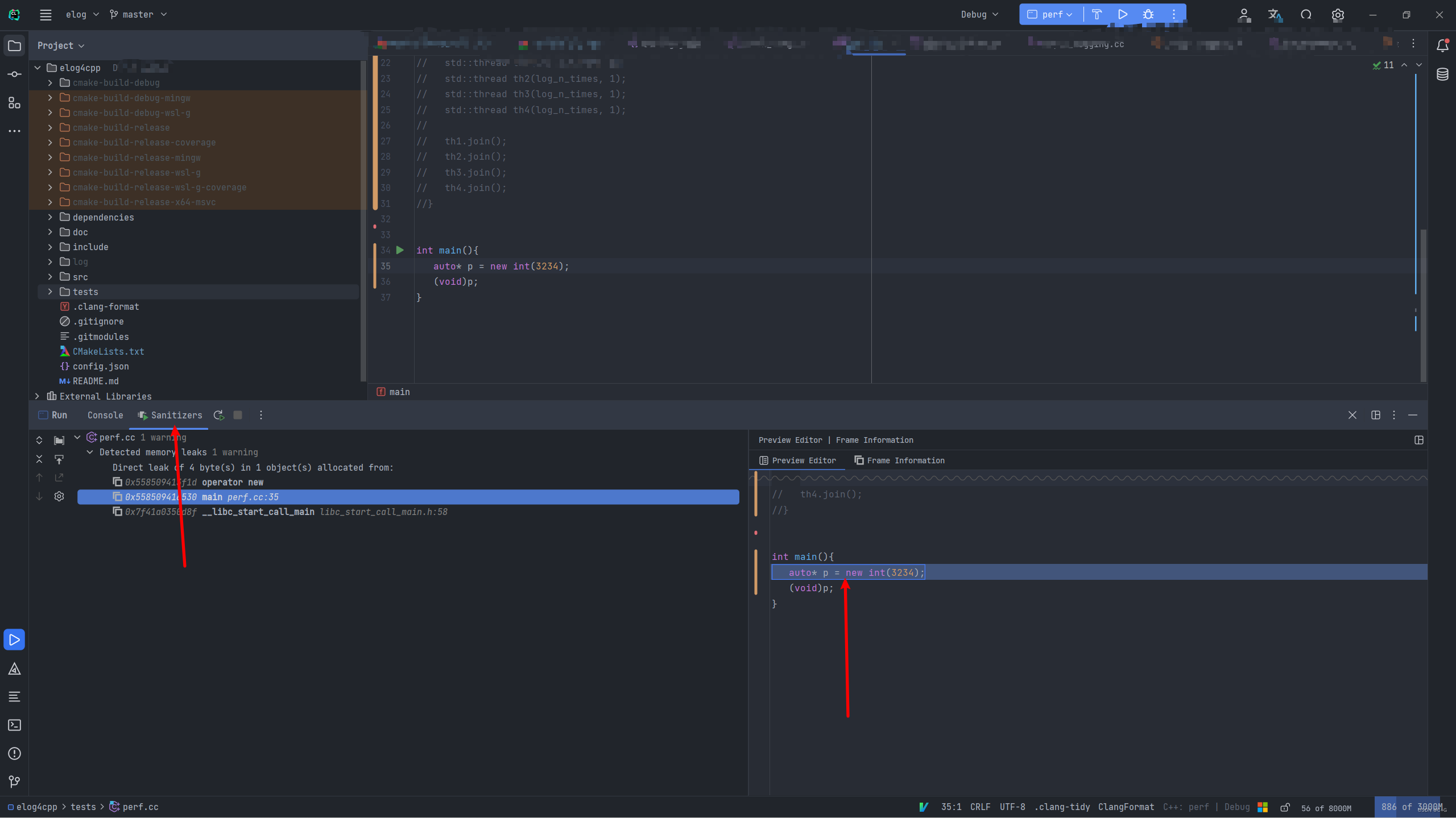
请不要同时开启多个选项,可能会报错,如果没有报错,也可能只出现一个效果。
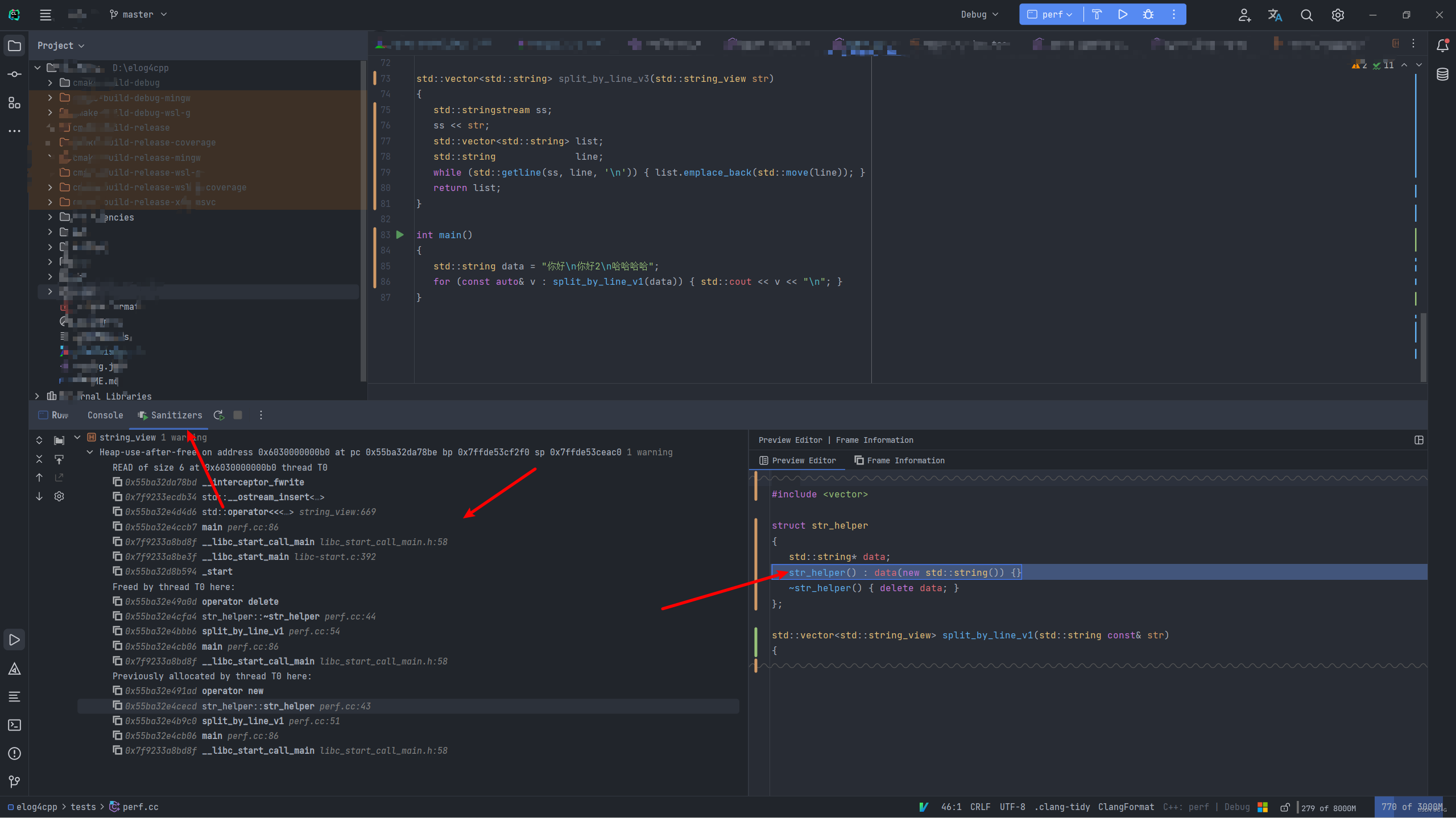
内存访问错误检测(address)
加入 -fsanitize=address 并设置为Debug模式。
同样我有下面这段代码(请在C++17及以上进行编译):
#include <iostream>
#include <sstream>
#include <string>
#include <string_view>
#include <vector>
struct str_helper
{
std::string* data;
str_helper() : data(new std::string()) {}
~str_helper() { delete data; }
};
std::vector<std::string_view> split_by_line_v1(std::string const& str)
{
std::stringstream ss(str);
std::vector<std::string_view> ret;
str_helper line;
while (std::getline(ss, *line.data, '\n')) { ret.push_back(*line.data); }
return ret;
}
std::vector<std::string_view> split_by_line_v2(std::string const& str)
{
size_t pos = str.find('\n'), pre_pos = 0;
auto ret = std::vector<std::string_view>();
while (pos != std::string::npos)
{
ret.emplace_back(str.data() + pre_pos, pos - pre_pos);
pre_pos = pos + 1;
pos = str.find('\n', pre_pos);
}
if (pre_pos + 1 < str.size())
{
ret.emplace_back(str.data() + pre_pos, str.size() - pre_pos);
}
return ret;
}
std::vector<std::string> split_by_line_v3(std::string_view str)
{
std::stringstream ss;
ss << str;
std::vector<std::string> list;
std::string line;
while (std::getline(ss, line, '\n')) { list.emplace_back(std::move(line)); }
return list;
}
int main()
{
std::string data = "你好\n你好2\n哈哈哈哈";
for (const auto& v : split_by_line_v1(data)) { std::cout << v << "\n"; }
}
这段代码有三个版本的split实现,很明显,第一个版本有空悬指针的问题,还有我解释为什么我第一个版本要专门再写一个 str_helper ,因为如果直接用 std::string 的话,它是检查不出来问题的,必须要使用new和delete进行内存的申请与释放才能被检测到,而标准库容器中使用的是 std::acllocator 。
第二个版本,没有内存安全问题,且不存在拷贝,但是使用的时候需要注意生命周期的问题,因为都是浅拷贝(string_view)。
第三个版本,没有内存安全问题,且不需要注意生命周期问题,但是有深拷贝和堆内存创建的性能损耗。
使用第一个版本检测出的情况如下图:
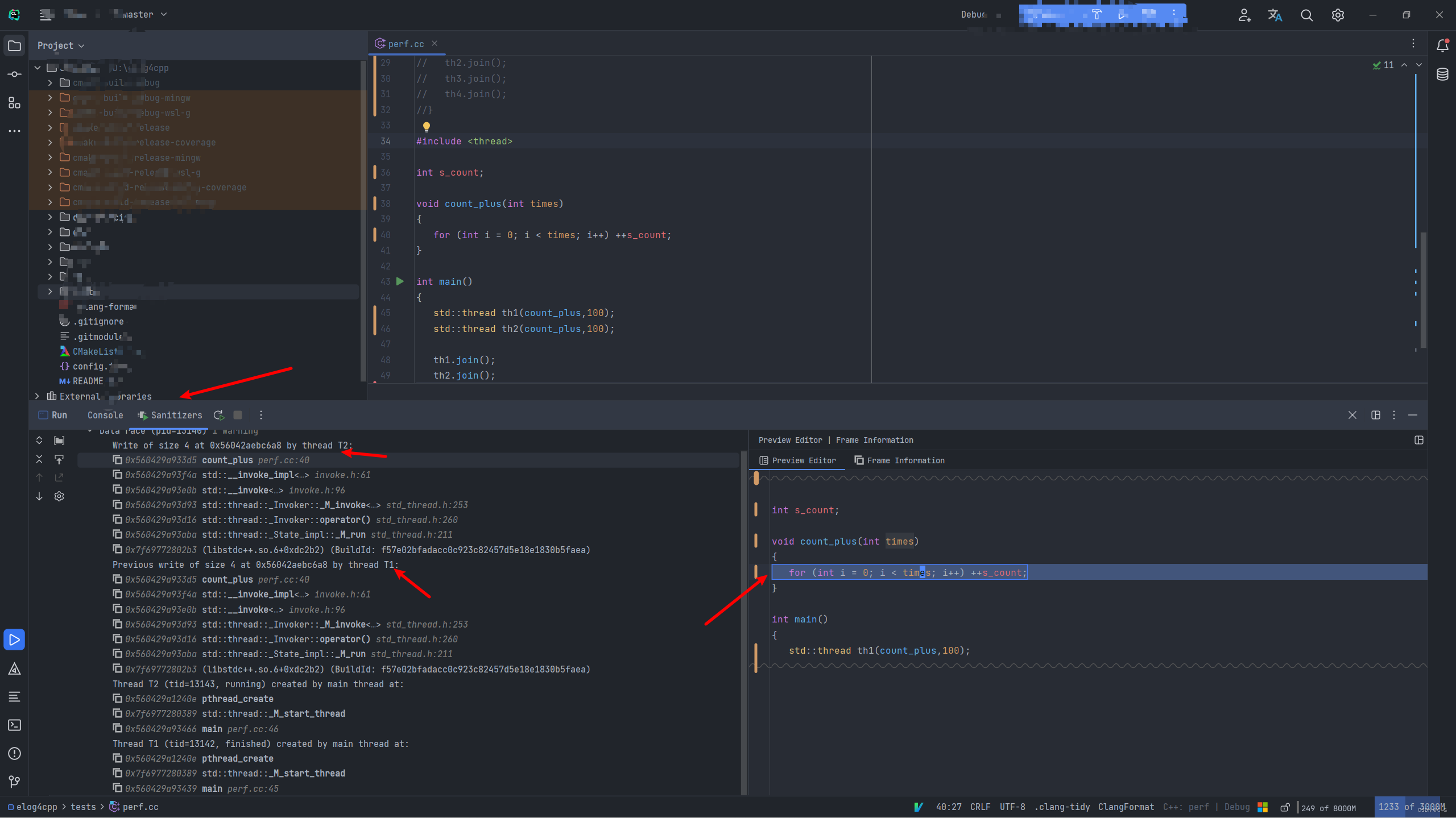
多线程数据竞争检测(thread)
加入 -fsanitize=thread 并设置为Debug模式。
有下列简单代码:
#include <thread>
int s_count;
void count_plus(int times)
{
for (int i = 0; i < times; i++) ++s_count;
}
int main()
{
std::thread th1(count_plus,100);
std::thread th2(count_plus,100);
th1.join();
th2.join();
}
检测结果如下:
CLion中使用perf生成火焰图
同样截取一段chatgpt的回答:

说白了就是分析软件的性能瓶颈,具体是通过查看各个函数调用所占用的时间或cpu消耗等等。
这个功能需要下载 perf 工具,而 perf 需要Linux环境,所以Windows可以使用wsl2来实现,但是我的wsl2无法直接使用需要手动去下载wsl2内核源代码然后编译安装,安装好后,我使用后发现还是有bug(无法显示非系统调用函数),所以这个还是只适合在 Linux/macos 使用。官方文档在:https://www.jetbrains.com/help/clion/2022.3/cpu-profiler.html
环境准备
我这里就偷个懒直接把官方文档的中文翻译截图放这里了,建议自己去看官方文档:
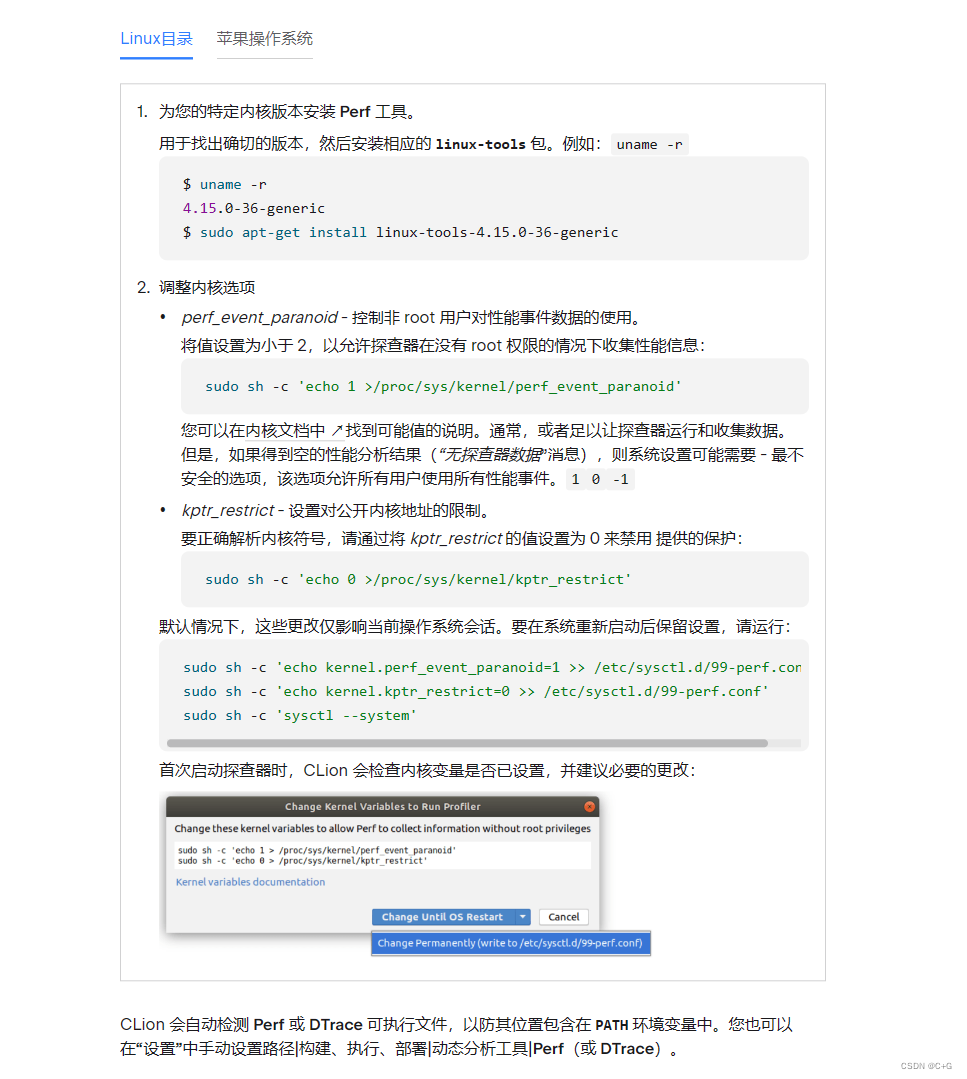
如何使用
使用的话,只需要像下面这样配置即可:
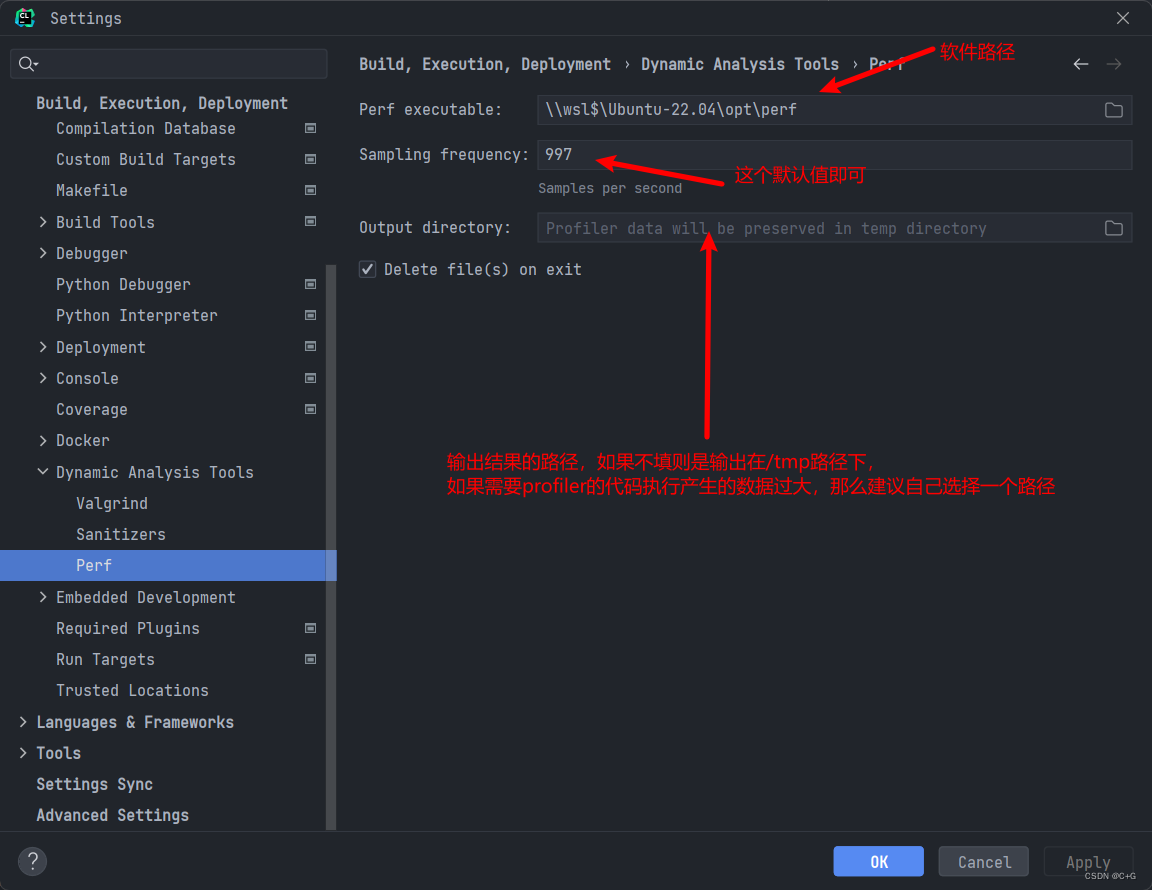
在CLion中运行的时候按下这个按钮即可:
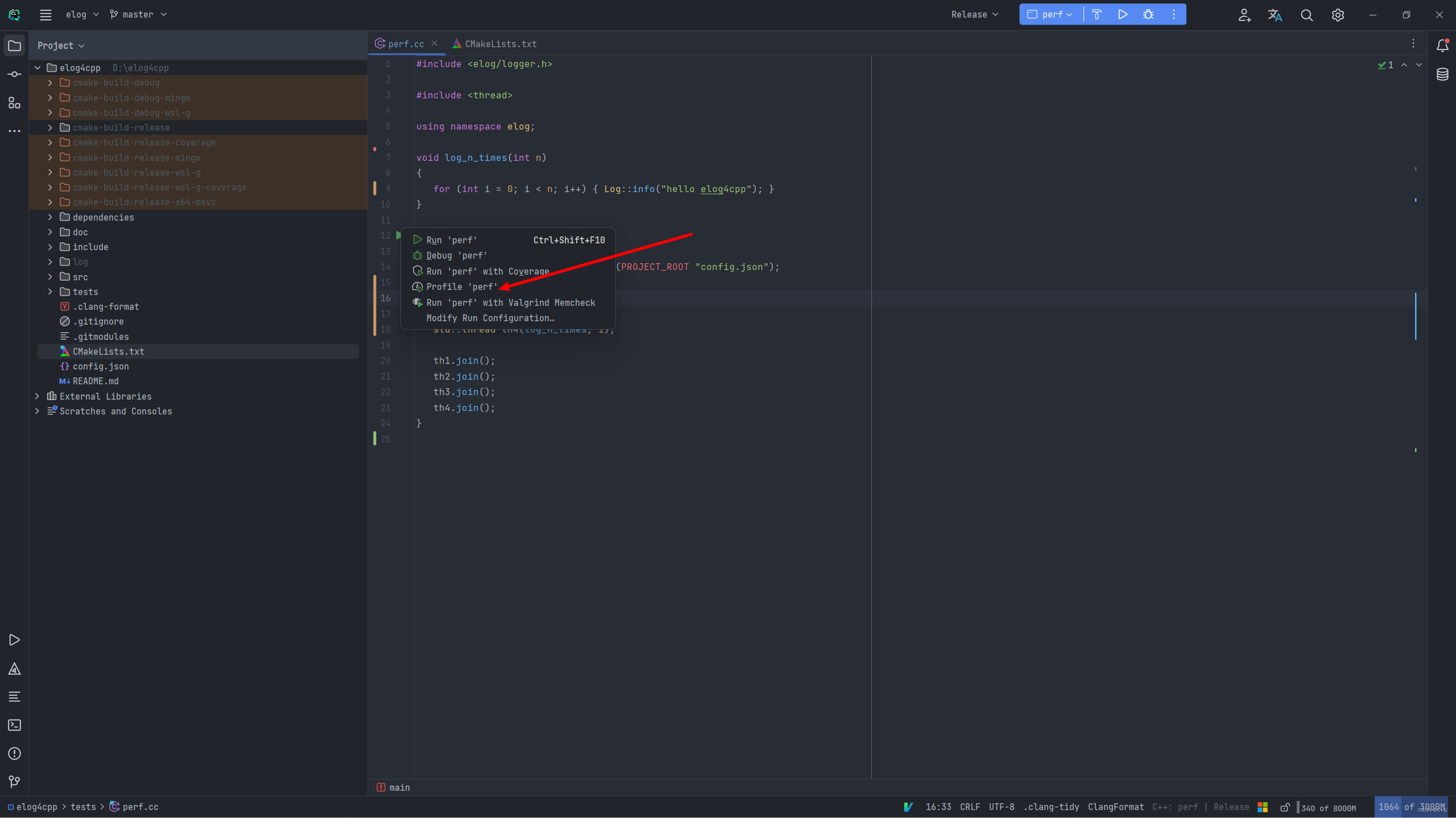
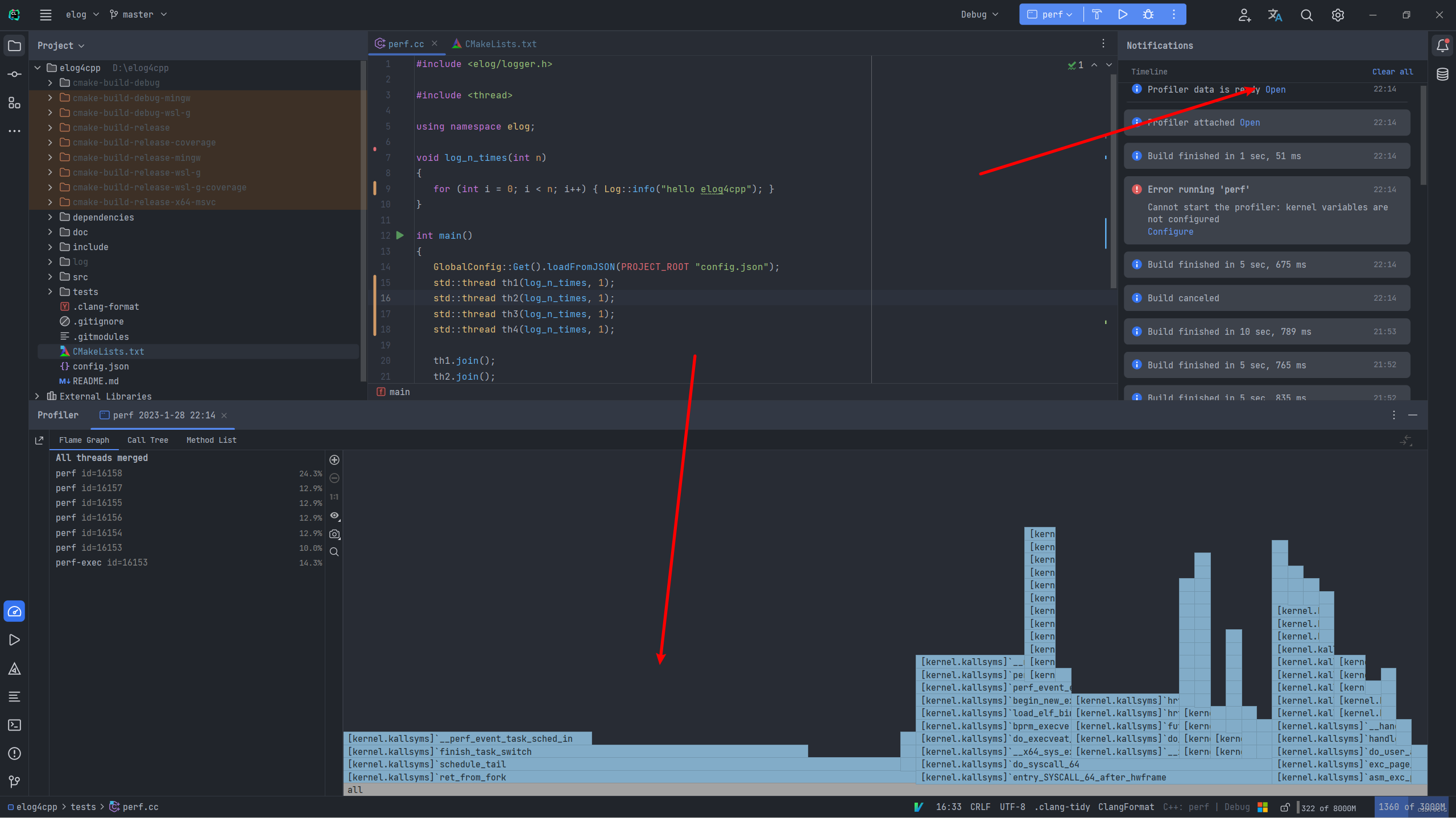
运行后等一会儿,然后CLion里会有个通知告诉你可以查看profiler了,我的结果如下图(有bug,只能显示出系统调用的函数):








![[MRCTF2020]PixelShooter1题解](https://img-blog.csdnimg.cn/img_convert/939e6917d299dd952ad519b7ea375bfe.jpeg)