大数据之路 读书笔记 Day2
日志采集——浏览器的页面采集
一、分类
二、流程
浏览日志采集流程图
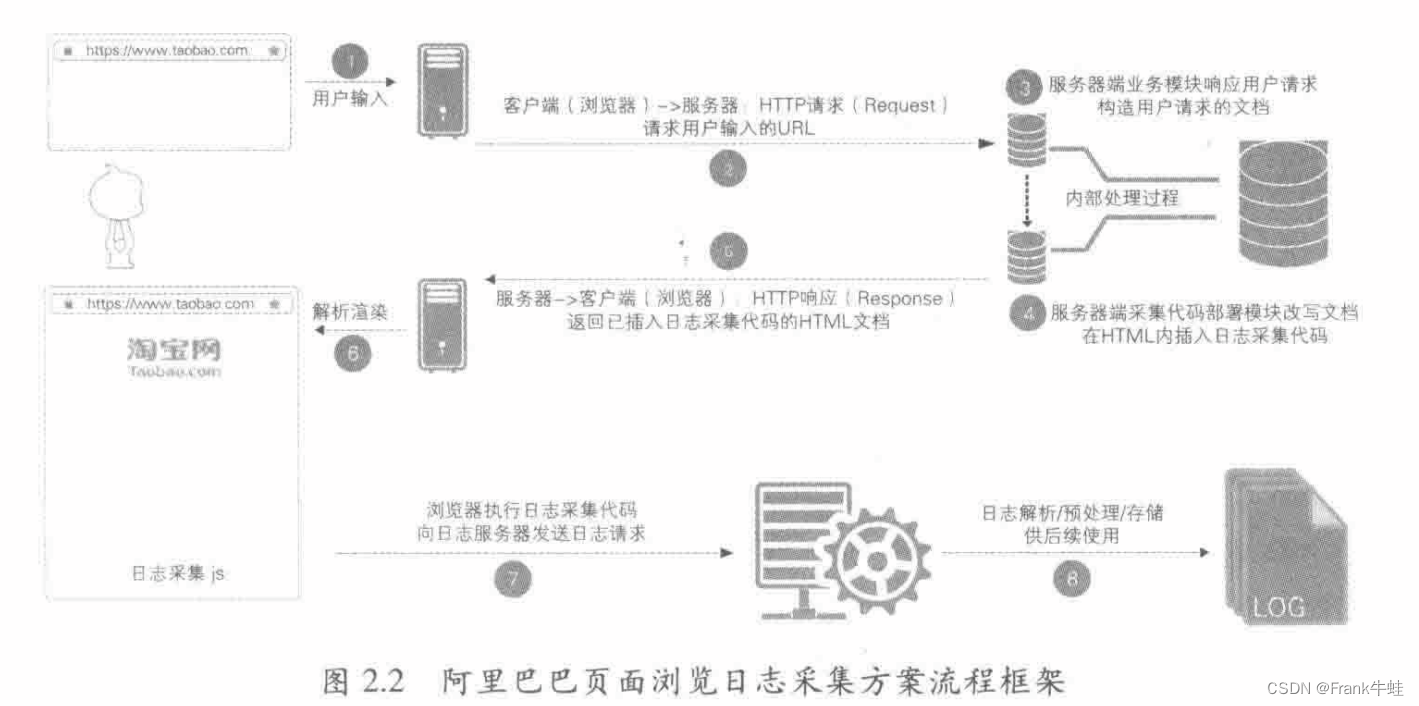
本质就是在用户请求联网时,阿里的服务器会在构造用户所需文档时,插入日志采集代码,在用户界面解析渲染成功时,将用户成功浏览的日志传到特定的服务器做下一步处理
“黄金令箭”——交互日志采集
- 黄金令箭是一个开放的基于HTTP协议的日志服务
关于黄金令箭的日志采集有以下四个步骤:
(1)业务方在“黄金令箭”的元数据管理界面依次注册需要采集交互日志的业务、具体的业务场景以及场景下的具体交互采集点,在注册完成之后,系统将生成与之对应的交互日志采集代码模板。
(2)业务方将交互日志采集代码植入目标页面,并将采集代码与需要监测的交互行为做绑定。
(3)当用户在页面上产生指定行为时,采集代码和正常的业务互动响应代码一起被触发和执行。
(4)采集代码在采集动作完成后将对应的日志通过HTTP协议发送到日志服务器,日志服务器接收到日志后,对于保存在HTTP请求参数部分的自定义数据,即用户上传的数据,原则上不做解析处理,只做简单的转储。
经过上述步骤采集到日志服务器的业务日志可被业务方按需自行解析处理,并与正常的PV日志做关联运算。
三、页面日志的服务端清晰和预处理
-
识别流量攻击、网络爬虫和流量作弊
依托算法识别,道阻且长。
流量攻击
流量攻击,是一种恶意尝试,通过大量无效的请求占用目标系统的资源,如带宽、CPU、内存等,导致其无法为合法用户提供服务。攻击者通常利用一个庞大的计算机网络(僵尸网络)向目标网站或服务器发送大量的数据包或请求,使得目标系统超负荷运行,最终导致服务中断或响应极其缓慢。常见的流量攻击类型包括SYN Flood、UDP Flood、ICMP Flood等。
网络爬虫
网络爬虫,也叫网页蜘蛛或网络机器人,是一种自动化程序,用于遍历万维网,连续抓取网页内容。它们根据预先设定的规则或算法自动请求网页、解析HTML代码并提取所需信息,常用于搜索引擎索引构建、数据分析、价格监控、内容聚合等领域。合理使用网络爬虫可以高效收集公开信息,但过度或不遵守网站爬虫政策的爬取行为可能对网站服务器造成负担,甚至违反法律法规。
流量作弊
流量作弊是指采用非正常手段人为制造虚假的网站访问量、点击率、观看次数或其他在线互动指标的行为。这种行为旨在欺骗广告商、投资者或提高网站排名,以获取不当利益。常见的作弊手段包括自动点击广告、使用僵尸网络模拟真实用户访问、购买假流量等。流量作弊不仅损害了广告主的利益,破坏了市场公平竞争环境,也干扰了数据分析的准确性,影响了互联网生态的健康发展。
-
数据缺项补正
例如,在用户登陆后,对登陆前页面日志做身份信息的回补
-
无效信息剔除
-
日志隔离分发
基于数据安全、业务特性考虑,某些日志在进入公共数据环境之前需要做隔离。
原始日志经过上述的清洗、修正,并结构化变形处理之后,Web 页面日志的采集流程就算完成了。此时的日志已经具备了结构化或者半结构化的特征,可以方便地被关系型数据库装载和使用。
今天的笔记分享到这里就结束啦~
点赞收藏关注,获取更多干货知识~