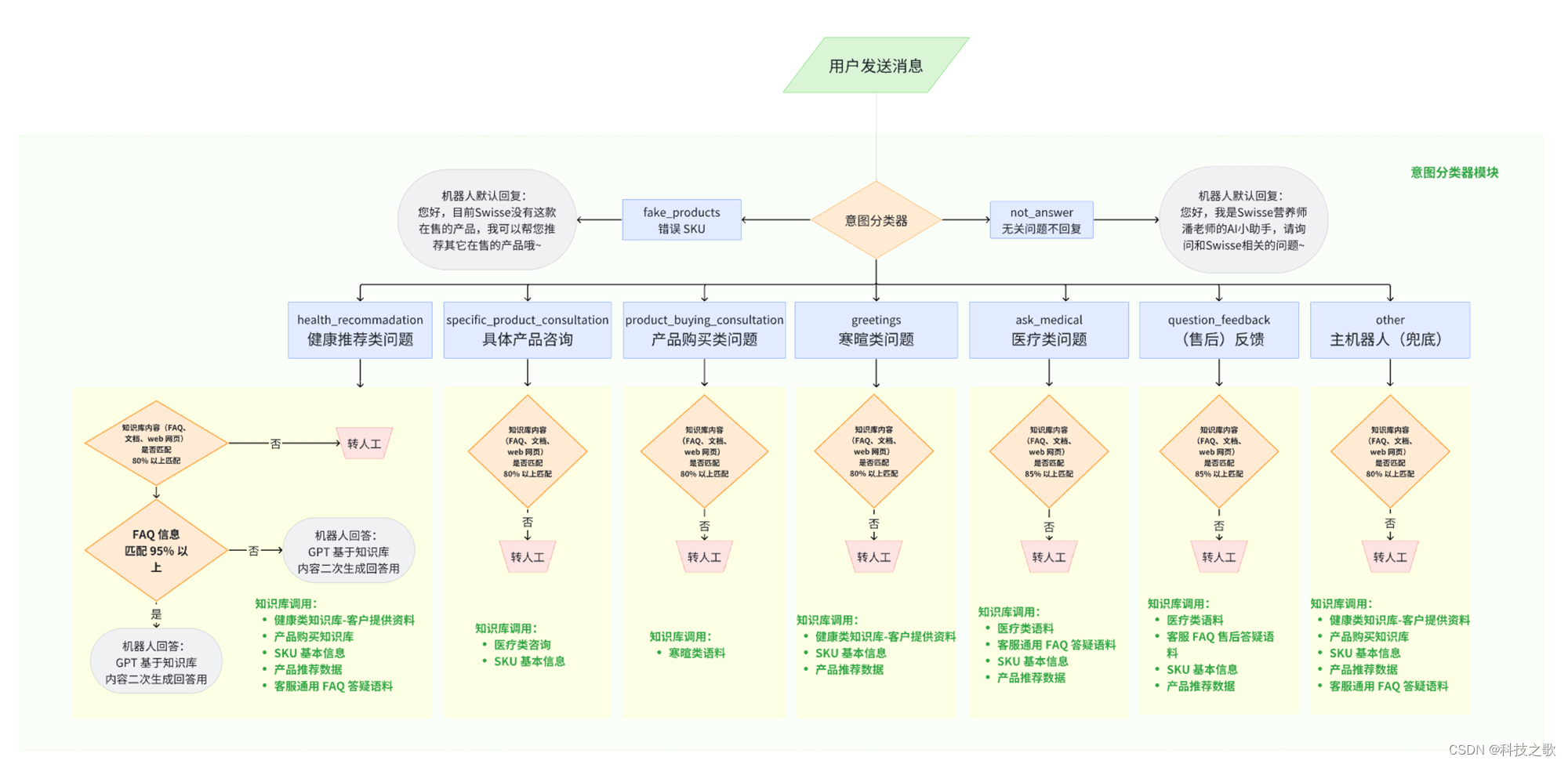
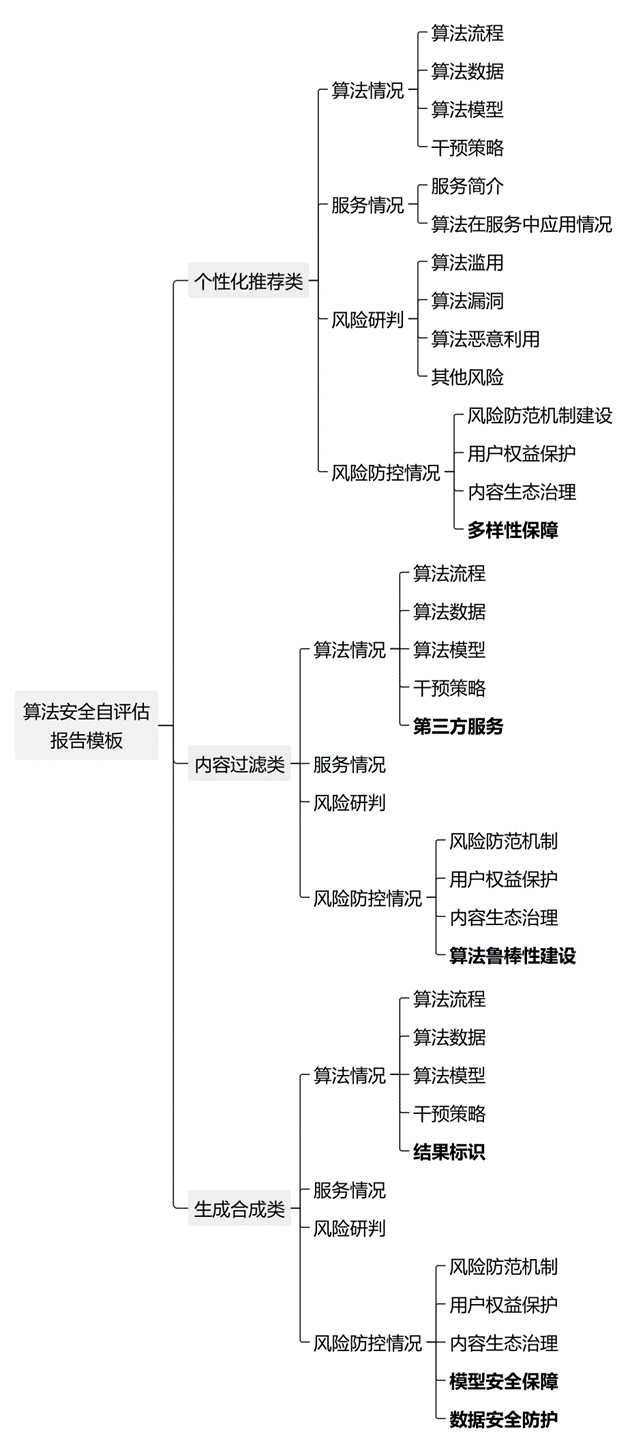
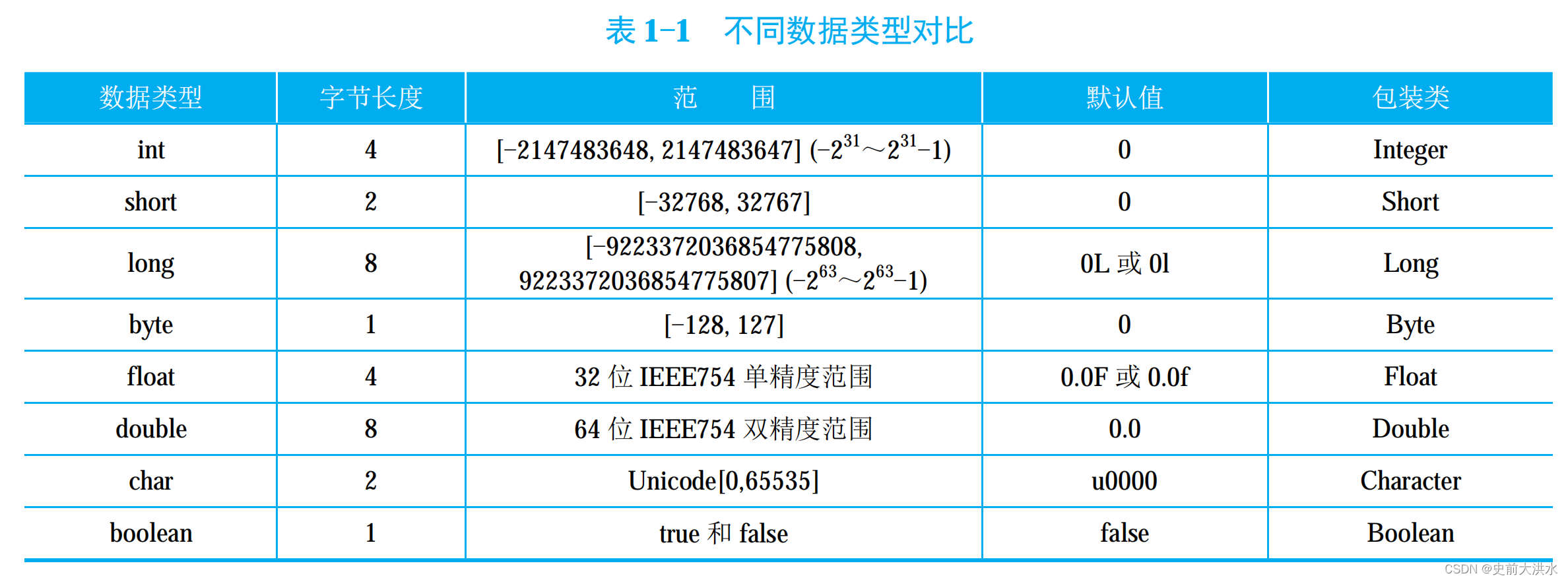
1.简介
1.1目的
在过去的一段时间里,对基于剪枝的模型压缩的算法进行了一系列的实现和实验,特别有引入的稀疏矩阵的方法实现了对模型大小的压缩,以及在部分环节中实现了模型前向算法的加速效果,但是总体上模型加速效果不理想。所以本文档针对这些实验结果进行分析和总结。
1.2范围
本文档描述的代码修改以及实验方法都是基于caffe-Progress-m40框架进行的,主要的压缩策略是模型剪枝策略,并引入的稀疏矩阵的操作,实验的网络结构lenet。
1.3定义、首字母缩写词和缩略语
| 序号 | 术语或缩略语 | 说明性定义 |
| 1 | ||
| 2 | ||
| 3 | ||
| 4 | ||
| 5 | ||
| 6 | ||
| 7 |
1.4 参考资料
2.实验的方法
本文档中的实验是基于caffe-Progress-m40框架进行的,修改了其中的源码,使得这个框架可以按照制定的剪枝策略对模型进行剪枝,并修改对应参数层中前向和后向算法将对应可训练的参数的稠密矩阵乘法替换为稀疏矩阵乘法,具体的修改方法可以参考《模型压缩实验设计》。
实验中用到的剪枝策略是将可训练参数取绝对值,然后按照升序的方法排序,按照事先给定的剪枝率选出阈值,之后根据这个阈值对参数进行剪枝判断,绝对值大于这个阈值的参数保留,小于这个阈值的参数减除。
基于修改完毕的上述框架,做了两组对比实验。第一组实验主要是观察不同压缩率对模型压缩效果的影响。第二组实验主要是观察不同压缩率对前向算法耗时的影响。实验中的压缩率包括0.5,0.6,0.7,0.8,0.9,压缩率从0.5开始的原因是,稀疏矩阵的表示形式是csr/csc结构,全部的参数数量是2x+y,其中x表示的是矩阵中非零元素的个数,y表示矩阵的行或者列的大小。很显然,只有压缩率超过一半,即非零元素的个数小于全部元素的一半的时候,稀疏矩阵的存储才有优势。
实验中都是对剪枝后的模型进行了retrain,最大程度上保证了模型的acc,第一组实验给出不同压缩率的模型压缩效果,第二组实验给出不同压缩率的模型前向耗时情况。所有的实验都是基于mnist数据集在LeNet网络上进行的,具体的实验结果以及实验分析在下一节给出。
3.实验结果及其分析
3.1 模型尺寸压缩效果
| (LeNet)mnist | commom train acc lr = 0.01 | Pruning acc | Pruning with retrain acc lr = 0.001 | size |
| Sparse=0.9 | 0.9911 | 0.2972 | 0.9874 | 1.7M->252K |
| Sparse=0.8 | 0.9072 | 0.9899 | 1.7M->496K | |
| Sparse=0.7 | 0.9824 | 0.9914 | 1.7M->744K | |
| Sparse=0.6 | 0.9819 | 0.9912 | 1.7M->984K | |
| Sparse=0.5 | 0.9878 | 0.9923 | 1.7M->1.3M |
表1 不同压缩率的模型压缩效果
不同压缩率的模型的压缩效果如表1所示。从表中可以看出随着压缩率的增加模型的尺寸越来越小,模型retrain后的模型acc也越低,特别当压缩率超过0.7之后,压缩后模型的acc会低于压缩前的模型的acc,所以为了保证模型的精度,压缩率在0.7的时候效果是最好的。这说明在压缩率为0.7的时候剩下的权值信息基本上可以代表完整的权值信息,证明原始模型神经元还是有很大的冗余的,通过剪枝的方法可以有效的降低模型的尺寸。
3.2 模型前向加速的效果
| Sparse | (LeNet)mnist前向耗时(us) | |
| cpu_time | gpu_time | |
| 0 | 118912 | 1748 |
| 0.5 | 2415347 | 2582 |
| 0.6 | 1987526 | 2272 |
| 0.7 | 1540937 | 2200 |
| 0.8 | 1071417 | 2057 |
| 0.9 | 728792 | 1978 |
表2 不同压缩率的前向算法耗时
不同压缩率的前向算法耗时如表2所示,对模型压缩之后模型的前向速度比压缩之前要慢,无论是在cpu还是gpu上,特别是在cpu上压缩后模型前向的耗时要比之前大一个量级。但是从表2中还可以得到另一个结论,那就是随着压缩率的增加,模型的前向算法的耗时都是下降的,无论是在cpu上还是gpu上,这说明当压缩率超过0.5后,稀疏矩阵的乘法是比稠密矩阵的乘法要快的,这个在相关的论文中以及自己的测试中都是得到验证的。但是为什么在本次实验结果中稀疏矩阵乘法的引入导致模型前向变慢了呢,本文对其中的原因做了总结:
- cpu方面,在处理float或者double类型的数据时,Eigen矩阵运算库相比于cublas矩阵运算库要慢不少,而且为了代码中支持稀疏矩阵的运算引入了很多额外的操作,造成的前向耗时开销增加。
- gpu方面,引入的稀疏矩阵运算库是cusparse库,这个运算库对稀疏矩阵乘法的支持只是支持稀疏矩阵的左乘,这样就导致cusparse只可以很好的适配ip层,而不能很好的支持卷积层,因为卷积层的稀疏操作是右乘,否则需要对得到输出进行转置,大大的增加了开销。而且caffe中卷积层的gpu支持有两种实现方法,其中cudnn加速版本的卷积层比无cudnn加速版本的卷积层的前向也要快,目前还没有发现支持cudnn加速的稀疏矩阵乘法运算库。所以每次在进行卷积操作的时候要将稀疏矩阵转换为稠密矩阵也增加了前向耗时的开销。
3.3 稀疏矩阵乘法耗时效果对比
以上,介绍了在CPU上使用Eigen库的稀疏矩阵以及GPU上使用的cuSparse的矩阵乘法替换原本caffe上矩阵乘法的前向耗时情况。因为总体的性能不行,所以下面单独会对稀疏矩阵矩阵乘法耗时的情况进行统计,并进行分析。耗时的统计分为两大类:一是Mat*Mat的类型;二是Mat*Vec的类型。每个大类会分成三种情况:
- DenseMat*DenseMat/Vector:两个稠密矩阵的乘法耗时,其中第一个矩阵没有非零元素:使用MKL的cblas_sgemm()或者cblas_sgemv()函数
- DenseMat* DenseMat/Vector:两个稠密矩阵的乘法耗时,其中第一个矩阵是普通存储方式的稀疏矩阵: 使用MKL的cblas_sgemm()或者cblas_sgemv()函数
- SparseMat* DenseMat/Vector:csr存储格式的稀疏矩阵乘上稠密矩阵或者向量:分别使用MKL的mkl_scsrmm()或者mkl_scsrmv()函数以及eigen库的方法
3.3.1 Mat*Mat乘法耗时效果对比
当稀疏率为0.7时,各种矩阵和稠密矩阵乘法随着矩阵尺寸变化耗时的情况如图1所示,其中yMklNzDenseMm表示的是稠密矩阵和稠密矩阵的乘法耗时情况,其中稠密矩阵中无零元素;yMklDenseMm表示的是稠密矩阵和稠密矩阵的乘法耗时情况,其中稠密矩阵是由稀疏矩阵填充的;yMklSparseMm表示的是csr格式存储基于MKL库的稀疏矩阵和稠密矩阵的乘法耗时情况;yEigenSparseMm表示的是csr格式存储基于Eigen库的稀疏矩阵和稠密矩阵的乘法耗时情况。

图 1 稀疏率为0.7时,各种矩阵和稠密矩阵乘法随着矩阵尺寸变化耗时的情况
当稀疏率为0.8时,各种矩阵和稠密矩阵乘法随着矩阵尺寸变化耗时的情况如图2所示。

图 2 稀疏率为0.8时,各种矩阵和稠密矩阵乘法随着矩阵尺寸变化耗时的情况
当稀疏率为0.9时,各种矩阵和稠密矩阵乘法随着矩阵尺寸变化耗时的情况如图3所示。

图 3 稀疏率为0.9时,各种矩阵和稠密矩阵乘法随着矩阵尺寸变化耗时的情况
从图中可以看出,稀疏率只有0.7的时候,稠密矩阵乘法的速度还是比较慢的,即使矩阵的稀疏率达到了0.9,无论是基于Eigen库的稀疏矩阵还是基于MKL库的稀疏矩阵来看,稀疏矩阵乘法相比稠密矩阵乘法也几乎没有什么优势。所以可以断定利用稀疏矩阵和稠密矩阵乘法加速的办法是不可行的。
3.3.2 Mat*Vec乘法耗时效果对比
当稀疏率为0.7时,各种矩阵和向量乘法随着矩阵尺寸变化耗时的情况如图4所示,其中yMklNzDenseMv表示的是稠密矩阵和向量的乘法耗时情况,其中稠密矩阵中无零元素;yMklDenseMv表示的是稠密矩阵和向量的乘法耗时情况,其中稠密矩阵是由稀疏矩阵填充的;yMklSparseMv表示的是csr格式存储基于MKL库的稀疏矩阵和向量的乘法耗时情况;yEigenSparseMv表示的是csr格式存储基于Eigen库的稀疏矩阵和向量的乘法耗时情况。

图 4 稀疏率为0.7时,各种矩阵和向量乘法随着矩阵尺寸变化耗时的情况
可以看出稀疏率为0.7的时候随着矩阵尺寸变大,稠密矩阵乘以向量和稀疏矩阵乘以向量的耗时基本上差不多。并且对比yMklNzDenseMv和yMklDenseMv可以看出稠密矩阵中0元素的多少对于稠密矩阵的运算没有影响。而基于Eigen的稀疏矩阵的乘法的速度和Mkl库还是有一定差距。
当稀疏率为0.8时,各种矩阵和向量乘法随着矩阵尺寸变化耗时的情况如图5所示。从图中可以看出,稀疏矩阵乘以向量上的速度优势已经体现出来了,无论是基于Eigen库还是Mkl库实现的稀疏矩阵乘法的运算速度都比稠密矩阵的运算速度要快,并且同样尺寸的矩阵,基于MKL库的稀疏矩阵运算速度最快。并且稠密矩阵中0元素多少得出的结论和之前的结论一致。
当稀疏率为0.9时,各种矩阵和向量乘法随着矩阵尺寸变化耗时的情况如图6所示。从图中可以看出稀疏矩阵的运算速度的优势更加明显了,当矩阵尺寸达到一定程度后,这种优势愈发明显,如矩阵尺寸到达2560*2560,稀疏矩阵比稠密矩阵的速度要快3倍多。

图 5 稀疏率为0.8时,各种矩阵和向量乘法随着矩阵尺寸变化耗时的情况

图 6 稀疏率为0.9时,各种矩阵和向量乘法随着矩阵尺寸变化耗时的情况
为了验证随着稀疏率的越增加,稀疏矩阵乘法的速度与稠密矩阵乘法速度差距越大的这个观点,我们给出固定矩阵尺寸为2560*2560,观察不同稀疏率对矩阵乘法速度的影响,结果如图7所示。对于Eigen库的稀疏矩阵乘法来说,当稀疏率达到0.8左右,稀疏矩阵与向量的乘法的耗时就比稠密矩阵与向量的乘法的耗时要少了。同样的对于基于MKL库的稀疏矩阵来说,稀疏率达到0.7左右就可以了。所以上述的观点得到了验证。

图 7 各种矩阵和向量乘法随着矩阵稀疏率变化耗时的情况
4.总结
通过一系列的实验和结果分析,可以看出剪枝策略可以很好解决模型尺寸压缩的问题,特别是如果允许模型精度有些许下降的前提下,模型的压缩率可以达到0.9,然而要是同时还想达到模型前向加速的效果,目前使用的基于稀疏矩阵和稠密矩阵的乘法的加速方法是无效的,但是稀疏矩阵乘以向量的方法是可以尝试的。根据caffe中卷积层和全连接层的计算方法可知,当batchsize设置为1的时候全连接层的矩阵运算可以表示为矩阵和向量乘积的方法,即可以使用稀疏矩阵加速的方法来实现,但是对于卷积层来说,即使将batchsize设置为1,卷积层的运算还是矩阵和矩阵的乘法运算,所以无法用稀疏矩阵乘向量的方法进行加速。重要的是我们实验中还发现,用循环调用稀疏矩阵乘以向量的方法来替换稠密矩阵乘法的方法时,当循环次数到达10次以上之后,即使稀疏率达到0.9,循环调用的方法比直接矩阵乘法的方法要慢很多。总之,最后的实验说明,当稀疏率达到一定程度之后,只有稀疏矩阵和向量的乘法和稠密矩阵和向量的乘法对比才会有加速的效果。








![[SD必备知识18]修图扩图AI神器:ComfyUI+Krita加速修手抽卡,告别低效抽卡还原光滑细腻双手,写真无需隐藏手势](https://img-blog.csdnimg.cn/direct/4ef6c3c84f424b47afa657004903bf17.png)