文章目录
检测所用数据有几种文件格式,我们对于检测,将使用VOC格式做为基础,与其它格式的的互转实现部分如下:
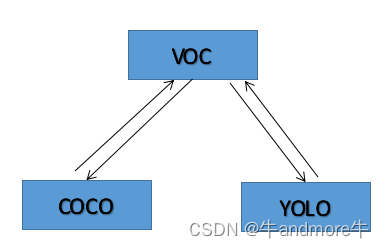
检测系列相关文章参考如下链接:
- VOC数据的结构介绍及自定义生成,用labelimg自已标注
- VOC标准数据的生成及分析,VOC易用labelimg生成,做为基础的检测数据类型
- VOC转YOLO,方便YOLO系列模型使用
- VOC转COCO,方便用于COCO map评估
- YOLO转VOC,方便使用我们的VOC相关分析和处理代码
- COCO转VOC,方便使用我们的VOC相关分析和处理代码
以上数据格式互转,方便我们处理各种收集的开源数据和自己标记的数据的整合。当然也不是特别的全面,但是工作中常用的主流的格式是包含的。
觉的有价值的小伙伴可以给点个赞。
在很多检测算法的官方实现,用的都是YOLO格式的数据,比如darknet YOLOV4,YOLOV5,YOLOV6,YOLOV7,YOLOV8这些不同人开发的算法,都是用的YOLO格式,所以我们在用labelimg标完数据,做完各种分析后,可以转换到YOLO格式,从而实现这些算法,本文实现一个完整的经过处理的VOC数据集转换成YOLO格式的代码。生成标准完整的VOC格式的数据集的方法请参见链接。对于基于Paddle的PaddleDetection和PaddleYOLO则是支持VOC和COCO两种的。
本文代码经过实测,如感觉对你有帮助,请点个小赞。
import os
import os.path as osp
import shutil
from glob import glob
from tqdm import tqdm
import xml.etree.ElementTree as ET
def convert(size, box):
"""_summary_
Args:
size (_type_): 图片宽高
box (_type_): bounding box 左右上下
Returns:
_type_: 返回bounding box的中心点及宽高的相对值
"""
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert2yolo(srcpath,savepath,background=False):
"""_summary_
Args:
srcpath (_type_): VOC数据集路径,在JPEGImages和Annotations上一级
savepath (_type_): YOLO格式数据集保存位置,自动生成下一级images和labels
background (bool, optional): 是否为背景数片,如果是背景那么生成空的txt文件.
"""
#直接把原有结果全部清理并生成新的保存路径
if osp.exists(savepath):
shutil.rmtree(savepath)
os.makedirs(savepath)
saveimgs = osp.join(savepath,'images')
savelbs = osp.join(savepath,'labels')
os.makedirs(saveimgs) #生成保存图片路径
os.makedirs(savelbs) #生成保存标签路径
#重新生成新的数据集
imgs = glob(osp.join(srcpath,"JPEGImages",'*.jpg'))
lbs = glob(osp.join(srcpath,"Annotations",'*.xml'))
for img in tqdm(imgs,desc="Start move images:"):
shutil.copy(img,saveimgs)
if not background:
#对于有标记文件的数据可以进行转换
#获取类别名称,从而按首字母顺序做类别的顺序排列并保存到classes.txt
classes = [] #获取类别名称,从而按首字母顺序做类别的顺序排列
for lb in lbs:
tree=ET.parse(lb)
root = tree.getroot()
for obj in root.iter('object'):
clsname = obj.find('name').text
classes.append(clsname)
classes = sorted(list(set(classes)))
class_names = [j+'\n' if i < len(classes)-1 else j for i,j in enumerate(classes)]
with open(osp.join(savepath,'classes.txt'),'w') as f:
f.writelines(class_names)
for lb in tqdm(lbs,desc="Start generate labels:"):
name = osp.splitext(osp.split(lb)[-1])[0]
out_file = osp.join(savelbs,name+'.txt')
fout = open(out_file,'w')
tree=ET.parse(lb)
root = tree.getroot()
size = root.find('size')
# print image_id
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
clsname = obj.find('name').text
if int(difficult) == 1:
continue
cls_id = classes.index(clsname)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h),b)
fout.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
fout.close()
else:#对没有标记的图片,称为背景图片,则产生的yolo标注文件是空的即可
for img in tqdm(imgs,desc="Start generate labels:"):
name = osp.splitext(osp.split(img)[-1])[0]
out_file = osp.join(savelbs,name+'.txt')
fout = open(out_file,'w')
fout.close()
print("all Done!")