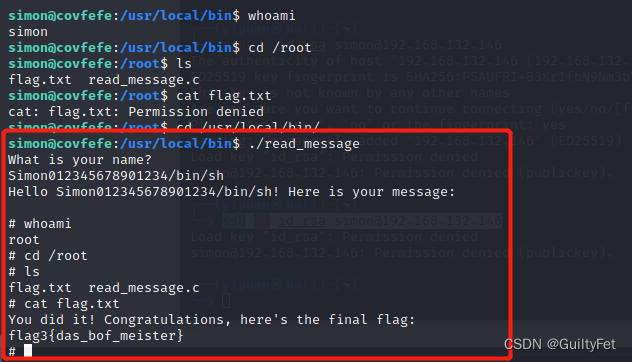
transformer库建立思路
(1) Model类: 如BertModel , 目前收录有超过30个PyTorch模型或Keras模型;
(2) Configuration类: 如BertConfig , 用于存储搭建模型的参数;
(3) Tokenizer类: 如BertTokenizer , 用于存储分词词汇表以及编码方式;
使用from_pretrained()和save_pretrained()方法来调用和保存这三种类的实例对象;
语言模型
带掩码的语言模型
: 即通过挖去语句中的部分单词,对这些单词进行预测得到的结果
因果语言模型
Causal Language Modeling: 即通过n-gram单词序列预测下一个单词的方法
目前收录一些文本生成模型
GPT-2
OpenAi-GPT
CTRL
XLNet
Transfo-XL
Reformer
模型汇总
transformer模型可以分为以下几类:
自回归(autoaggressive)模型:
自编码(autoencoding)模型: 破坏(corrupting)输入分词序列, 并试图将其用另一种设法重构原始序列, 一般来说这类模型都会对整个语句进行双向(bidirectional)表示, 最经典的模型就是BERT;
sequence-to-sequence模型: 即使用transformer架构中的编码器与解码器;
多模式的(multimodal)模型: 将文本输入转换为其他类型的输出(如图片);
基于检索的(retrieval-based)模型;
模型保存与调取
模型保存与调取**: save_pretrained()与from_pretrained()方**法;
模型共享
使用 g i t git git上传到模型指定的仓库。
多语言模型





![[2019红帽杯]easyRE1题解](https://img-blog.csdnimg.cn/img_convert/da6342e2299e1a2fe2aa7989043ed58c.jpeg)