今日目标

1、理解分库分表基础概念【垂直分库分表、水平分库分表】
2、能够说出sharding-jdbc为我们解决什么问题
3、理解sharding-jdbc中的关键名词
4、理解sharding-jdbc的整体架构及原理
5、掌握sharding-jdbc的集成方式
1.分库分表介绍
1.1 分库分表概述
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题;
1.将原来独立的数据库拆分成若干数据库组成;
2.将原来的大表(存储近千万数据的表)拆分成若干个小表;
目的:使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
1.2 分库分表示例
老王是一家初创电商平台的开发人员,负责卖家模块的功能开发,其中涉及了店铺、商品的相关业务,设计如下数据库:
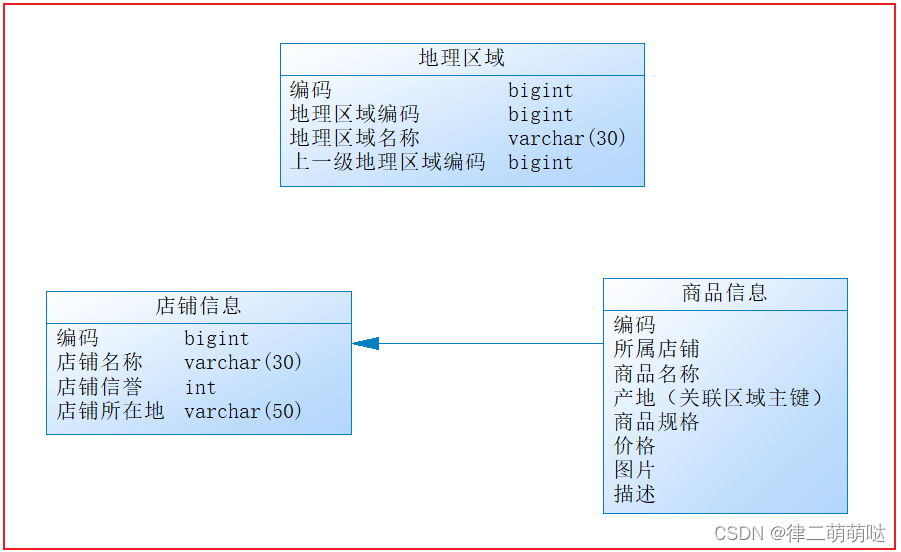
通过以下SQL能够获取到商品相关的店铺信息、地理区域信息:
SELECT p.*,r.[地理区域名称],s.[店铺名称],s.[信誉]
FROM [商品信息] p
LEFT JOIN [地理区域] r ON p.[产地] = r.[地理区域编码]
LEFT JOIN [店铺信息] s ON p.id = s.[所属店铺]
WHERE p.id = ?
形成类似的列表展示:
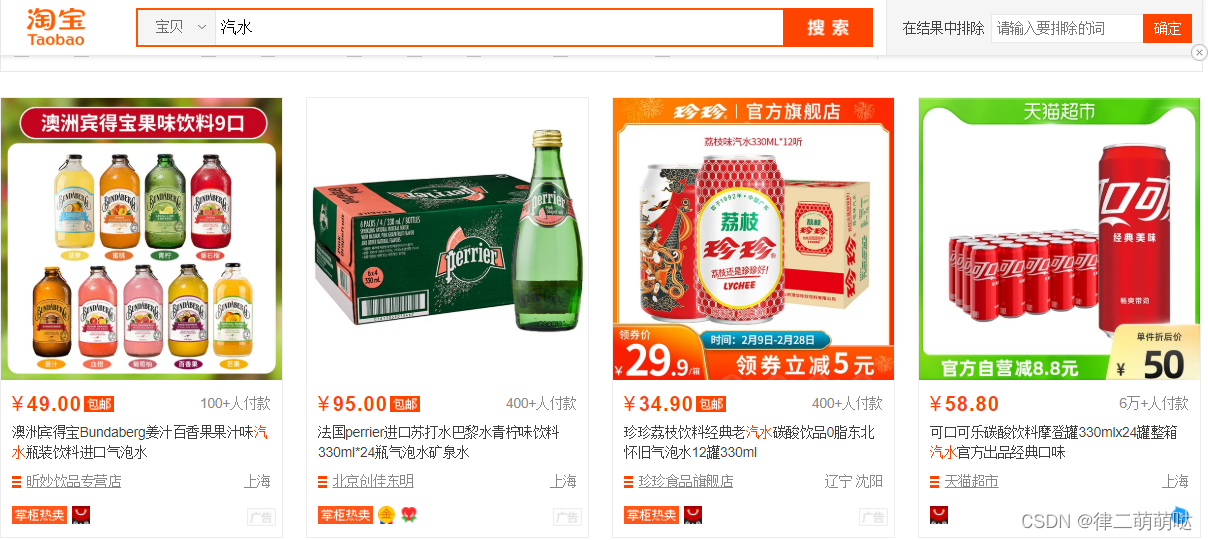
随着公司业务快速发展,数据库中的数据量猛增,访问性能也变慢了,优化迫在眉睫。
分析一下问题出现在哪儿呢?
1.关系型数据库本身比较容易成为系统瓶颈:单机存储容量、数据库连接数、处理能力都有限。
2.当单表的数据量达到1000W或100G以后,由于查询维度较多,即使做了优化索引等操作,
查询性能仍下降严重。
方案1:
通过提升服务器硬件能力来提高数据处理能力,比如增加存储容量 、CPU等,这种方案成本很高,并且如果瓶颈在MySQL本身那么提高硬件也是有很的。
方案2:
把数据分散在不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的;
如下图:将电商数据库拆分为若干独立的数据库,并且对于大表也拆分为若干小表,通过这种数据库拆分的方法来解 决数据库的性能问题。
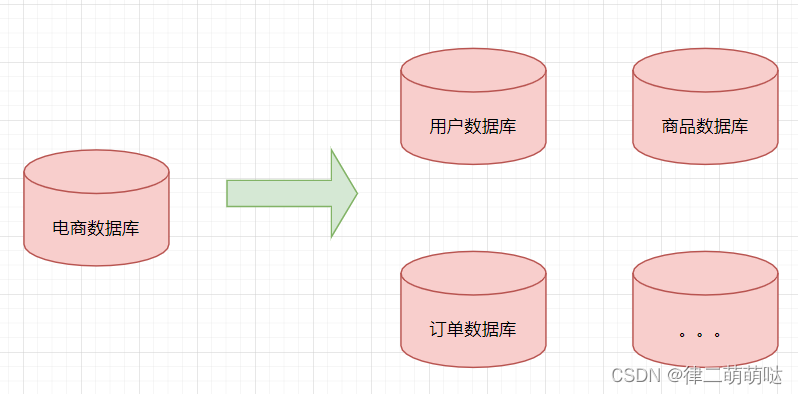
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
2.分库分表的方式
分库分表包括分库和分表两个部分,在生产中通常包括:垂直分库、水平分库、垂直分表、水平分表四种方式。
2.1 垂直分表
【1】定义
垂直分表定义:将一个表按照字段分成多表,每个表存储其中一部分字段。
【2】示例场景
下边通过一个商品查询的案例讲解垂直分表。
通常在商品列表中是不显示商品详情信息的,如下图:
用户在浏览商品列表时,只有对某商品感兴趣时才会查看该商品的详细描述。因此,商品信息中商品描述字段访问频次较低,且该字段占用存储空间较大,访问单个数据IO时间较长,而商品信息中商品名称、商品图片、商品价格等其他字段数据访问频次较高。
由于这两种数据的特性不一样,因此我们可以考虑将商品信息表拆分如下:
将访问频次低的商品描述信息单独存放在一张表中,访问频次较高的商品基本信息单独放在一张表中。
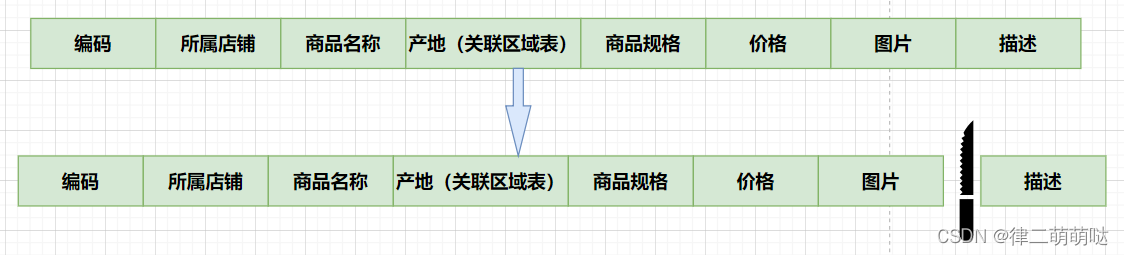

商品列表可采用以下sql:
SELECT p.*,r.[地理区域名称],s.[店铺名称],s.[信誉]
FROM [商品信息] p
LEFT JOIN [地理区域] r ON p.[产地] = r.[地理区域编码]
LEFT JOIN [店铺信息] s ON p.id = s.[所属店铺]
WHERE...ORDER BY...LIMIT...
需要获取商品描述时,再通过以下sql获取:
SELECT *
FROM [商品描述]
WHERE [商品ID] = ?
【3】垂直分表优势
1.避免了IO过度争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响;
2.充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累
(冷热数据分离);
【4】垂直分表原则
1.把不常用的字段单独放在一张表;
2.把text,blob等大字段拆分出来放在附表中;
3.经常组合查询的列放在一张表中;
2.2 垂直分库
【1】定义
名词解释:垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是【专库专用】。
通过垂直分表性能确实得到了一定程度的提升,但是因为存储的数据始终限制在一台服务器上,服务器物理硬件存在性能瓶颈(比如:CPU、内存、网络IO、磁盘等),而通过库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
【2】示例场景
经过思考,我们可以将原有的卖家库,拆分为分为商品库和店铺库,并把这两个库分散到不同服务器上,如下图:
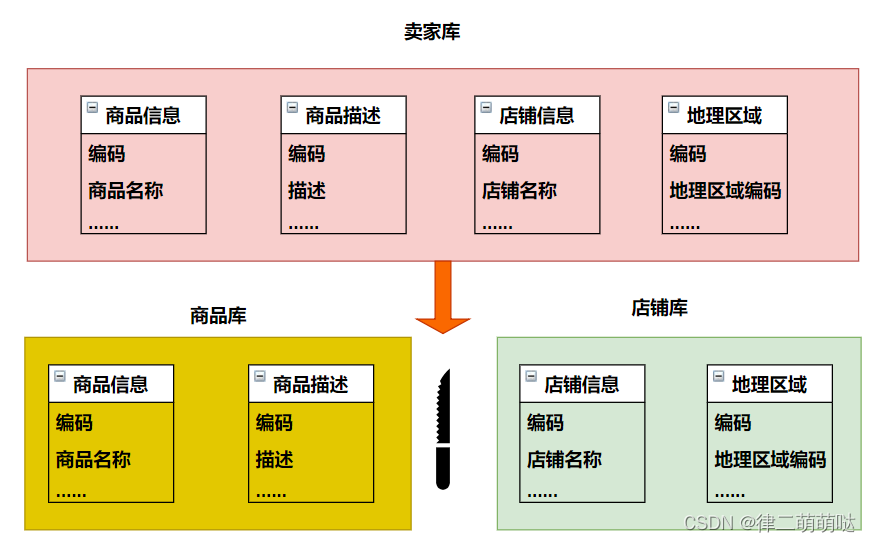

说明:
由于商品信息与商品描述业务耦合度较高,因此一起被存放在商品库(避免跨库联查);
而店铺信息相对独立,因此单独被存放在店铺库下;
以上操作就可以称为垂直分库。
【3】垂直分库优势
垂直分库带来的提升是:
-
通过不同表的业务聚合(聚合为库),使得数据库维护更加清晰;
-
能对不同业务的数据进行分级管理、维护、监控、扩展等;
-
高并发场景下,垂直分库在一定程度上提高了磁盘IO和数据库连接数,并改善了单机硬件资源的瓶颈问题;
【不同表分摊到不同的数据库,分摊了访问压力】;
但是,垂直分库依然没有解决单表数据量过大的问题!
2.3 水平分库
【1】定义
名词解释:水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上(解决单库数据量大的问题)。
【2】示例场景
经过垂直分库后,数据库性能问题得到一定程度的解决,但是随着业务量的增长,商品库单库存储数据已经超出预估。
假如当前有8w店铺,每个店铺平均150个不同规格的商品,那商品数量得往1200w+上预估,并且商品库属于访问非常频繁的资源,单台服务器已经无法支撑。
此时该如何优化?
目前情况是再次垂直分库已经无法解决数据瓶颈问题。我们可以尝试水平分库,将商品ID为单数的和商品ID为双数的商品信息分别放在两个不同库中(各个库下的表结构一致)。
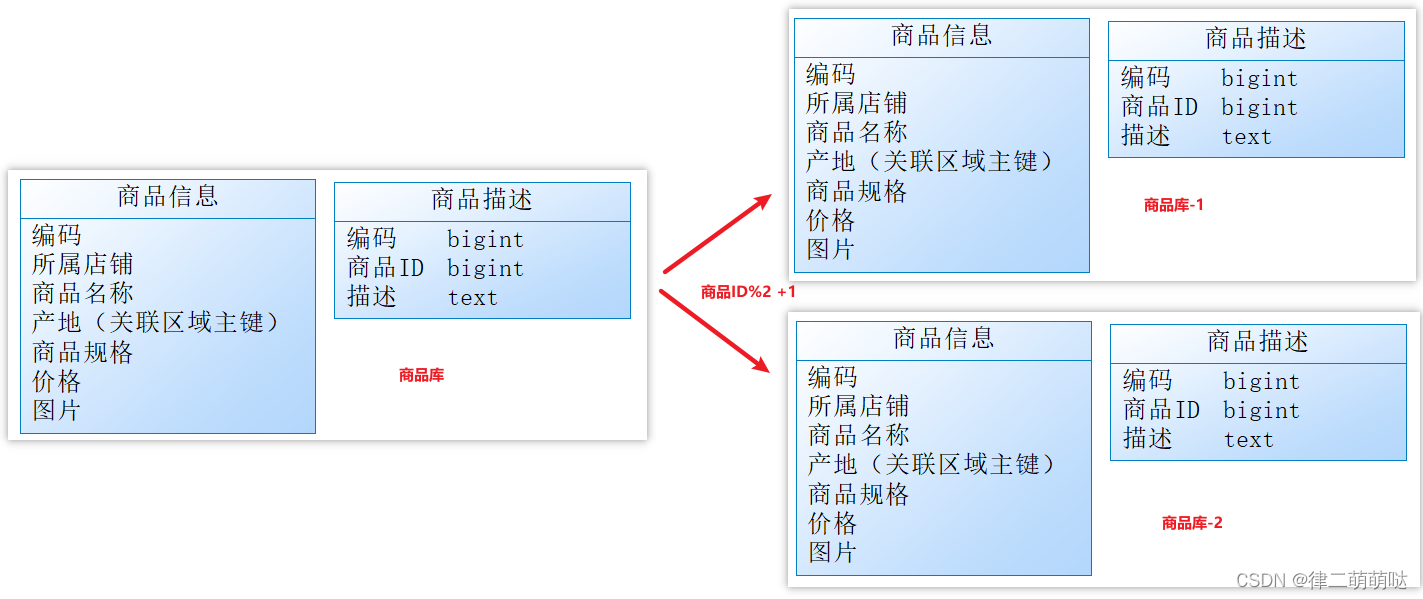
如果商品ID为双数,将此操作映射至【商品库-1】;
如果店铺ID为单数,将操作映射至【商品库-2】;
此操作要访问数据库名称的表达式为商品ID%2 + 1;
这种操作就叫水平分库。
【3】水平分库优势
水平分库带来的提升是:
解决了单库大数据,高并发的性能瓶颈问题;提高了系统的稳定性及可用性;
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
2.4 水平分表
【1】定义
水平分表就是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中(解决单表数据量大的问题)。
【2】水平分表示例
按照水平分库的思路,我们也可把商品库内的表也进行水平拆分,只不过拆分后的表在同一个,其目的也是为解决单表数据量大的问题,如下图:

如果商品ID为双数,将此操作映射至商品信息1表;如果商品ID为单数,
将操作映射至商品信息2表。此操作要访问表名称的表达式为商品信息[商品ID%2 + 1];
这种操作就叫做:水平分表。
【3】水平分表优势
水平分表是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中,它带来的提升是:
优化单一表数据量过大而产生的性能问题避免IO争抢并减少锁表的几率
2.5 分库分表带来的问题
分库分表能有效的缓解了单机和单库带来的性能瓶颈和压力,突破网络IO、硬件资源、连接数的瓶颈,同时也带来了一些问题。
事务一致性问题跨节点关联查询跨节点分页、排序函数主键避重公共表(小数据量的表且经常备用,可能存在联查的情况)
2.6 分库分表小结
分库分表方式:垂直分表、垂直分库、水平分库和水平分表
垂直分表:可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
垂直分库:可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。
水平分库:可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题(数据路由问题后边介绍)。
水平分表:可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
最佳实践:
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案。
3. sharding-jdbc架构
3.1 ShardingSphere简介
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈。
组成部分: JDBC、Proxy 和 **Sidecar(规划中)**这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。
功能特性:它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
官方网站:https://shardingsphere.apache.org/index_zh.html
文档地址:
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/overview
本教程主要介绍:Sharding-JDBC;
3.2 Sharding-JDBC简介
Sharding-jdbc是ShardingSphere的其中一个模块,定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
Sharding-JDBC的核心功能为数据分片和读写分离,通过Sharding-JDBC,应用可以透明的使用jdbc访问已经分库分表、读写分离的多个数据源,而不用关心数据源的数量以及数据如何分布。
3.3 sharding-jdbc相关名词解释
参考官网-核心概念
-
逻辑表(LogicTable):进行水平拆分的时候同一类型(逻辑、数据结构相同)的表的总称。例:用户数据根据主键尾数拆分为2张表,分别是tab_user_0到tab_user_1,他们的逻辑表名为tab_user。
-
真实表(ActualTable):在分片的数据库中真实存在的物理表。即上个示例中的tab_user_0到tab_user_1。
-
数据节点(DataNode):数据分片的最小单元。由数据源名称和数据表组成,例:spring-boot_0.tab_user_0,spring-boot_0.tab_user_1,spring-boot_1.tab_user_0,spring-boot_1.tab_user_1。
-
动态表(DynamicTable):逻辑表和物理表不一定需要在配置规则中静态配置。如,按照日期分片的场景,物理表的名称随着时间的推移会产生变化。
-
广播表(公共表):指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
-
绑定表(BindingTable):指E。例如:
t_order表和t_order_item表,均按照order_no分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);让order的数据落库位置,与order_item落库的位置在同一个数据节点。
在不配置绑定表关系时,假设分片键
order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11); SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order`的条件。故绑定表之间的分区键要完全相同。
-
分片键(ShardingColumn):分片字段用于将数据库(表)水平拆分的字段,支持单字段及多字段分片。例如上例中的order_id。
3.4 Sharding-JDBC执行原理
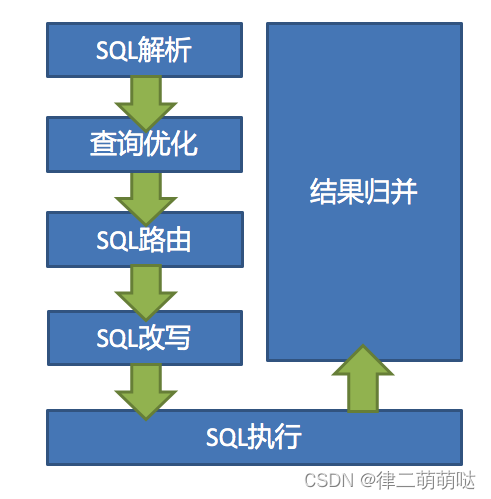
参考官网-内部剖析:
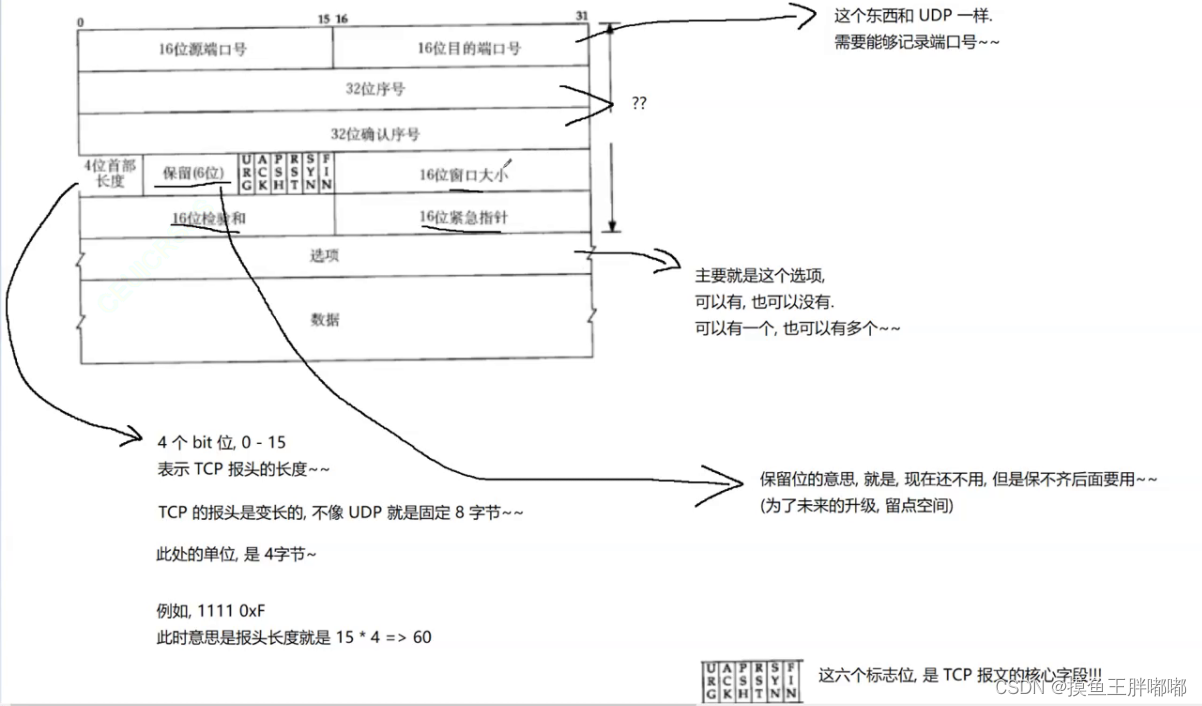
shardingSphere的3个产品的数据分片主要流程是完全一致的。 核心由SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程组成。
例如现在有一条查询语句:
select * from t_user where id=10
进行了分库分表操作,2个库ds0,ds1,采用的分片键为id,逻辑表为t_user,真实表为t_user_0、t_user_1两张表,分库、分表算法为均为取余(%2)。
-
sql解析:通过解析sql语句提取分片键列与值进行分片,例如比较符 =、in 、between and,及查询的表等。
-
执行器优化:合并和优化分片条件,如OR等。
-
sql路由:找到sql需要去哪个库、哪个表执行语句,上例sql根据采用的策略可以得到将在ds0库,t_user_0表执行语句。
-
sql改写:根据解析结果,及采用的分片逻辑改写sql,SQL改写分为正确性改写和优化改写。
上例经过sql改写后,真实语句为:
select * from ds0.t_user_0 where id=10;==>ds0.t_user_0 2S
select * from ds0.t_user_1 where id=10;==>ds0.t_user_1 2S
select * from ds1.t_user_0 where id=10;==>ds1.t_user_0 2S
select * from ds1.t_user_1 where id=10;==>ds1.t_user_1 2S
- sql执行:通过多线程执行器异步执行。
- 结果归并:将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
4. sharding-jdbc入门
sharding-jdbc实现分片有4中策略:
1.inline模式-行表达式分片策略(单片键)★
2.standard模式-标准分片策略(单片键)★
3.complex模式-用于多分片键的复合分片策略(多片键)
4.Hint模式-强制分片策略(强制路由)
4.1 inline模式实现水平分表
【1】数据库结构
order_db_1
├── t_order_1
└── t_order_2
SQL准备
#创建数据库
CREATE DATABASE `order_db_1` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
#建表
USE order_db_1;
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
#逻辑表 后面会删除
CREATE TABLE `t_order` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB;
【2】项目集成
第一步:测试工程引入核心依赖
<dependencies>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
第二步:主配置
application.properties
【1】主配置:
# 应用名称
spring.application.name=sharding-demo
#下面这些内容是为了让MyBatis映射
#指定Mybatis的Mapper文件
mybatis.mapper-locations=classpath:mappers/*xml
#指定Mybatis的实体目录
mybatis.type-aliases-package=com.itheima.pojo
#配置sharding jdbc数据源
# 数据源名称,多数据源以逗号分隔
spring.shardingsphere.datasource.names=ds1
# 数据库连接池类名称
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
# 数据库驱动类名
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
# 数据库 url 连接
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/order_db_1?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai
# 数据库用户名
spring.shardingsphere.datasource.ds1.username=root
# 数据库密码
spring.shardingsphere.datasource.ds1.password=root
#配置数据节点
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
#配置分片策略 说明:$是占位符,占位符的范围来自箭头指定的范围(1..2) 表示1到2 也就是说可能的真实节点是ds1.t_order_1,ds1.t_order_2
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds1.t_order_$->{1..2}
#配置分片,因为当前库仅仅只有一个ds1,所以无需指定分片库的策略,只需指定分表的策略即可
# 行表达式分片策略
# 分片列名称 指定分片字段
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
# 分片算法行表达式,需符合 groovy 语法 配置分片规则
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2 +1}
【2】定义mapper接口和xml,pojo
TOrderMapper
package com.itheima.shardingjdbc.mapper;
import com.itheima.shardingjdbc.pojo.TOrder;
import org.apache.ibatis.annotations.Mapper;
/**
* @Entity com.itheima.shardingjdbc.pojo.TOrder
*/
@Mapper
public interface TOrderMapper {
int deleteByPrimaryKey(Long id);
int insert(TOrder record);
int insertSelective(TOrder record);
TOrder selectByPrimaryKey(Long id);
int updateByPrimaryKeySelective(TOrder record);
int updateByPrimaryKey(TOrder record);
}
TOrderMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.mapper.TOrderMapper">
<resultMap id="BaseResultMap" type="com.itheima.pojo.TOrder">
<id property="orderId" column="order_id" jdbcType="BIGINT"/>
<result property="price" column="price" jdbcType="DECIMAL"/>
<result property="userId" column="user_id" jdbcType="BIGINT"/>
<result property="status" column="status" jdbcType="VARCHAR"/>
</resultMap>
<sql id="Base_Column_List">
order_id,price,user_id,
status
</sql>
<select id="selectByPrimaryKey" parameterType="java.lang.Long" resultMap="BaseResultMap">
select
<include refid="Base_Column_List" />
from t_order
where order_id = #{orderId,jdbcType=BIGINT}
</select>
<delete id="deleteByPrimaryKey" parameterType="java.lang.Long">
delete from t_order
where order_id = #{orderId,jdbcType=BIGINT}
</delete>
<insert id="insert" keyColumn="id" keyProperty="id" parameterType="com.itheima.pojo.TOrder" useGeneratedKeys="true">
insert into t_order
( order_id,price,user_id
,status)
values (#{orderId,jdbcType=BIGINT},#{price,jdbcType=DECIMAL},#{userId,jdbcType=BIGINT}
,#{status,jdbcType=VARCHAR})
</insert>
<insert id="insertSelective" keyColumn="id" keyProperty="id" parameterType="com.itheima.pojo.TOrder" useGeneratedKeys="true">
insert into t_order
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="orderId != null">order_id,</if>
<if test="price != null">price,</if>
<if test="userId != null">user_id,</if>
<if test="status != null">status,</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="orderId != null"> #{orderId,jdbcType=BIGINT},</if>
<if test="price != null"> #{price,jdbcType=DECIMAL},</if>
<if test="userId != null"> #{userId,jdbcType=BIGINT},</if>
<if test="status != null"> #{status,jdbcType=VARCHAR},</if>
</trim>
</insert>
<update id="updateByPrimaryKeySelective" parameterType="com.itheima.pojo.TOrder">
update t_order
<set>
<if test="price != null">
price = #{price,jdbcType=DECIMAL},
</if>
<if test="userId != null">
user_id = #{userId,jdbcType=BIGINT},
</if>
<if test="status != null">
status = #{status,jdbcType=VARCHAR},
</if>
</set>
where order_id = #{orderId,jdbcType=BIGINT}
</update>
<update id="updateByPrimaryKey" parameterType="com.itheima.pojo.TOrder">
update t_order
set
price = #{price,jdbcType=DECIMAL},
user_id = #{userId,jdbcType=BIGINT},
status = #{status,jdbcType=VARCHAR}
where order_id = #{orderId,jdbcType=BIGINT}
</update>
</mapper>
TOrder
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class TOrder implements Serializable {
/**
* 订单id
*/
private Long orderId;
/**
* 订单价格
*/
private BigDecimal price;
/**
* 下单用户id
*/
private Long userId;
/**
* 订单状态
*/
private String status;
private static final long serialVersionUID = 1L;
}
注意:xml中使用的逻辑表t_order,而不是t_order1、t_order2
【4】测试
@SpringBootTest
public class ShardingDemoApplicationTests {
@Autowired
private TOrderMapper tOrderMapper;
@Test
public void test1() {
int orderId=0;
Random random=new Random();
for (int i = 1; i <=20; i++) {
//0,1 +1 ==>1,2
//保证随机生成奇数或者偶数
orderId+=random.nextInt(2)+1;
TOrder order = TOrder.builder().orderId(Long.valueOf(orderId))
.userId(Long.valueOf(i))
.status("1")
.price(new BigDecimal(300)).build();
tOrderMapper.insert(order);
}
}
}
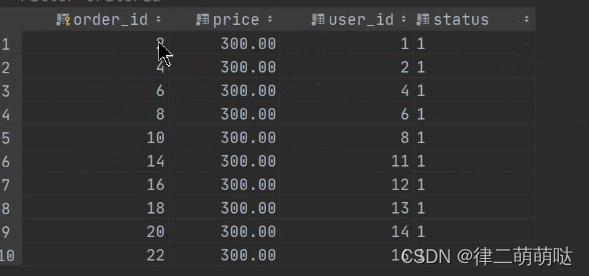
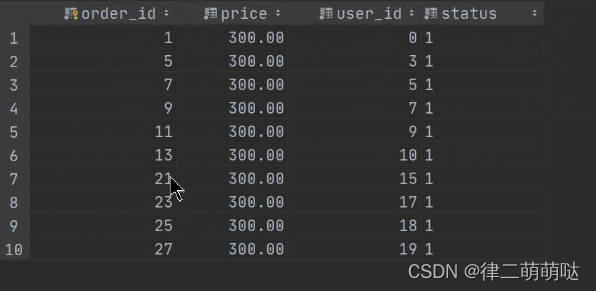
运行结果:
4.2 inline模式实现水平分库分表
【1】数据库结构
order_db_1
├── t_order_1
└── t_order_2
order_db_2
├── t_order_1
└── t_order_2
SQL准备:
#继续构建order_db_2数据库
CREATE DATABASE `order_db_2` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
#建表
USE order_db_2;
DROP TABLE IF EXISTS `t_order_1`;
CREATE TABLE `t_order_1` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `t_order_2`;
CREATE TABLE `t_order_2` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
CREATE TABLE `t_order` (
`order_id` BIGINT (20) NOT NULL COMMENT '订单id',
`price` DECIMAL (10, 2) NOT NULL COMMENT '订单价格',
`user_id` BIGINT (20) NOT NULL COMMENT '下单用户id',
`status` VARCHAR (50) CHARACTER
SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = INNODB;
【2】配置
第一步:定义application-test2.properties环境配置:
# 分表配置
# 数据源名称,多数据源以逗号分隔
spring.shardingsphere.datasource.names=ds1,ds2
# 数据库连接池类名称
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
# 数据库驱动类名
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
# 数据库 url 连接
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/order_db_1?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai
# 数据库用户名
spring.shardingsphere.datasource.ds1.username=root
# 数据库密码
spring.shardingsphere.datasource.ds1.password=root
# 数据库连接池类名称
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
# 数据库驱动类名
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
# 数据库 url 连接
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/order_db_2?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai
# 数据库用户名
spring.shardingsphere.datasource.ds2.username=root
# 数据库密码
spring.shardingsphere.datasource.ds2.password=root
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{1..2}.t_order_$->{1..2}
# 定义库分片
分片列名称
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=user_id
# 分片算法行表达式,需符合 groovy 语法
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2 +1}
# 行表达式分片策略
# 分片列名称
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=order_id
# 分片算法行表达式,需符合 groovy 语法
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{order_id % 2 +1}
在主配置文件中激活test2环境:
# 应用名称
spring.application.name=sharding-demo
#下面这些内容是为了让MyBatis映射
#指定Mybatis的Mapper文件
mybatis.mapper-locations=classpath:mappers/*xml
#指定Mybatis的实体目录
mybatis.type-aliases-package=com.itheima.pojo
spring.profiles.active=test2
【3】测试
与分表操作一致
//测试水平分库分表
@Test
public void test2() {
int orderId=0;
int userId=0;
Random random=new Random();
for (int i = 1; i <=40; i++) {
//0,1 +1 ==>1,2
//保证随机生成奇数或者偶数
orderId+=random.nextInt(2)+1;
userId+=random.nextInt(2)+1;
TOrder order = TOrder.builder().orderId(Long.valueOf(orderId))
.userId(Long.valueOf(userId))
.status("1")
.price(new BigDecimal(300)).build();
tOrderMapper.insert(order);
}
}
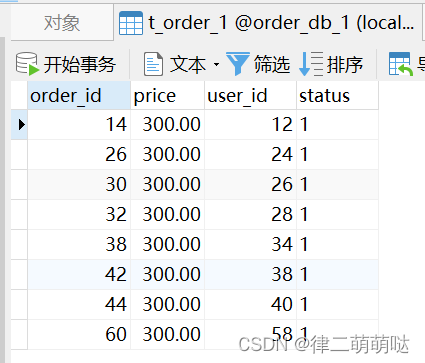
运行结果:数据均匀分布
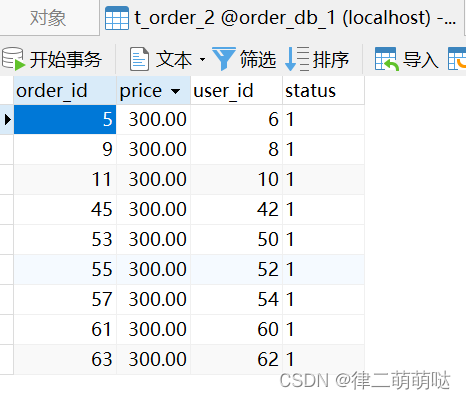
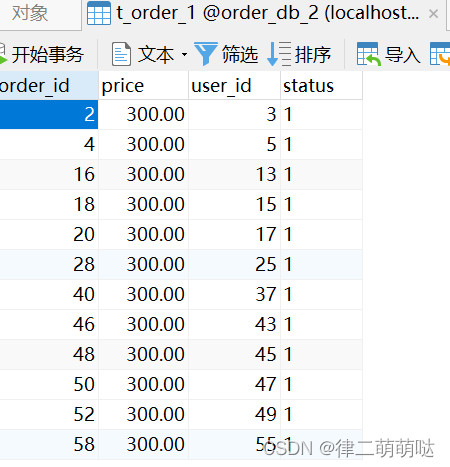
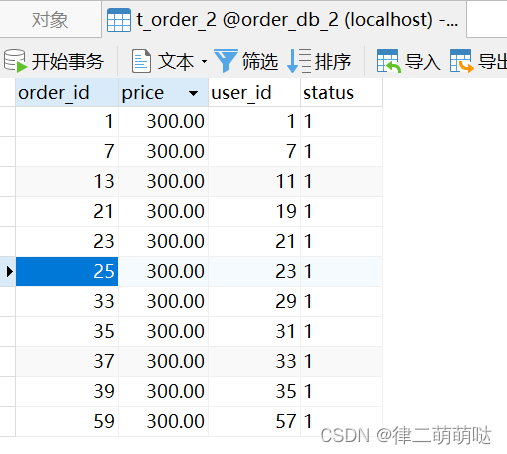
4.3.sharding-jdbc公共表
公共表属于系统中数据量较小,变动少,而且属于高频联合查询的依赖表;
参数表、数据字典表等属于此类型。可以将这类表在每个数据库都保存一份,所有更新操作都同时发送到所有分库执行。接下来看一下如何使用Sharding-JDBC实现公共表。
【1】SQL准备
#在数据库 user_db、order_db_1、order_db_2中均要建表
CREATE TABLE `t_dict` (
`dict_id` BIGINT (20) NOT NULL COMMENT '字典id',
`type` VARCHAR (50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典类型',
`code` VARCHAR (50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典编码',
`value` VARCHAR (50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '字典值',
PRIMARY KEY (`dict_id`) USING BTREE
) ENGINE = INNODB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
Idea 连接mysql数据库,并通过
mybatis-X逆向工程生成表的映射文件
生成的映射文件和实体类如下:
给TDict类添加注解
给TDictMapper类添加注解

【2】配置
application-test3.properties
# 分表配置
# 数据源名称,多数据源以逗号分隔
spring.shardingsphere.datasource.names=ds1,ds2
# 数据库连接池类名称
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
# 数据库驱动类名
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
# 数据库 url 连接
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/order_db_1?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai
# 数据库用户名
spring.shardingsphere.datasource.ds1.username=root
# 数据库密码
spring.shardingsphere.datasource.ds1.password=root
# 数据库连接池类名称
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
# 数据库驱动类名
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
# 数据库 url 连接
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/order_db_2?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai
# 数据库用户名
spring.shardingsphere.datasource.ds2.username=root
# 数据库密码
spring.shardingsphere.datasource.ds2.password=root
#配置公共表
spring.shardingsphere.sharding.broadcast-tables=t_dict
#显示sql
spring.shardingsphere.props.sql.show=true
【3】测试
@Autowired
private TDictMapper tDictMapper;
@Test
public void commonTable(){
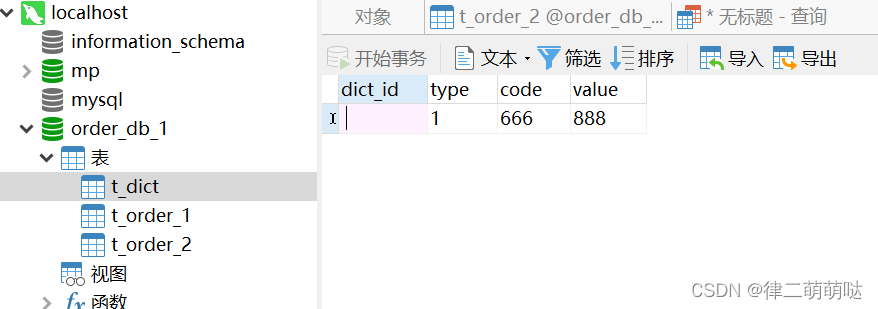
TDict build = TDict.builder().dictId(1l).code("666").type("1").value("888")
.build();
tDictMapper.insert(build);
}
4.4 垂直分库实操
【1】数据库结构
user_db
└── t_user
SQL准备
#创建数据库
CREATE DATABASE `user_db` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
#建表
USE user_db;
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`user_id` BIGINT (20) NOT NULL COMMENT '用户id',
`fullname` VARCHAR (255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '用户姓名',
`user_type` CHAR (1) DEFAULT NULL COMMENT '用户类型',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
使用mybatis-X逆向工程生成表的映射文件 参考4.3操作
【2】配置
我们可以水平分库分表的配置文件基础上添加如下配置:
application-test4.properties
# 数据库连接池类名称
spring.shardingsphere.datasource.ds3.type=com.alibaba.druid.pool.DruidDataSource
# 数据库驱动类名
spring.shardingsphere.datasource.ds3.driver-class-name=com.mysql.cj.jdbc.Driver
# 数据库 url 连接
spring.shardingsphere.datasource.ds3.url=jdbc:mysql://localhost:3306/user_db?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai
# 数据库用户名
spring.shardingsphere.datasource.ds3.username=root
# 数据库密码
spring.shardingsphere.datasource.ds3.password=root
# 配置用户表信息
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds3.t_user
# 分片列名称 在库和表直接定位时,分片键可以不指定
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=user_id
# 分片算法行表达式,需符合 groovy 语法
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user
测试:
@Autowired
private TUserMapper tUserMapper;
//测试垂直分库
@Test
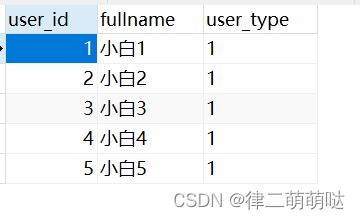
public void test4(){
for (int i = 1; i <= 5; i++) {
TUser user = TUser.builder().userId(Long.valueOf(i))
.userType("1").fullname("小白"+i).build();
tUserMapper.insert(user);
}
}
4.5 默认数据源模式
create database default_db character set utf8;
use default_db;
create table tb_log(
id bigint primary key,
info varchar(30)
);
使用mybatis-X逆向工程生成表的映射文件 参考4.3操作
【2】配置
application-test5.properties
# 分表配置
# 数据源名称,多数据源以逗号分隔
spring.shardingsphere.datasource.names=ds4
# 数据库连接池类名称
spring.shardingsphere.datasource.ds4.type=com.alibaba.druid.pool.DruidDataSource
# 数据库驱动类名
spring.shardingsphere.datasource.ds4.driver-class-name=com.mysql.cj.jdbc.Driver
# 数据库 url 连接
spring.shardingsphere.datasource.ds4.url=jdbc:mysql://localhost:3306/default_db?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai
# 数据库用户名
spring.shardingsphere.datasource.ds4.username=root
# 数据库密码
spring.shardingsphere.datasource.ds4.password=root
#显示sql
spring.shardingsphere.props.sql.show=true
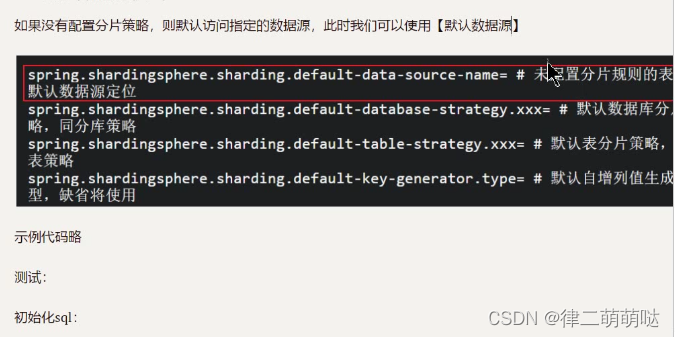
#配置默认数据源(特点,对于不做分片处理的操作,都会直接访问默认数据源
spring.shardingsphere.sharding.default-data-source-name=ds4
【3】测试
@Autowired
private TbLogMapper tbLogMapper;
//测试默认数据源,对于没有做分片处理的操作,直接访问默认数据源
@Test
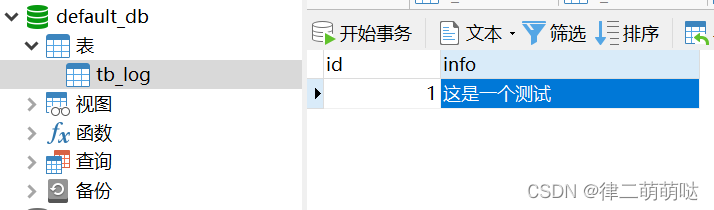
public void test5(){
TbLog tbLog = TbLog.builder().id(Long.valueOf(1))
.info("这是一个测试").build();
tbLogMapper.insert(tbLog);
}
4.6 inline模式弊端
inline模式对范围查询支持不太友好,动辄全节点查询,对于高版本的sharding-jdbc直接报错不予支持!
示例:
在TOrderMapper定义接口方法:
List<TOrder> findGt(@Param("orderId") Long orderId);
在TOrderMapper.xml下定义绑定的方法:
<select id="findGt" resultMap="BaseResultMap">
select
<include refid="Base_Column_List" />
from t_order
where order_id > #{orderId}
</select>
测试:
@Test
public void test06(){
List<TOrder> orders = tOrderMapper.findGt(1483696382506325732l);
System.out.println(orders);
}
错误信息:

5. 源码下载
https://download.csdn.net/download/qq_22075913/87403360