1.配置settings文件
(1)注意:需要先创建app(djnago-admin startapp app名称)

(2)配置模板文件
'DIRS': [os.path.join(BASE_DIR, 'templates')],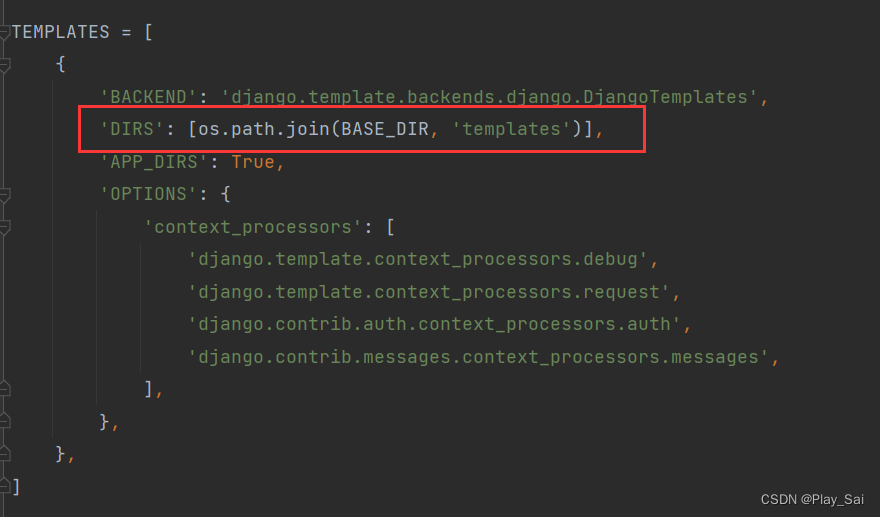
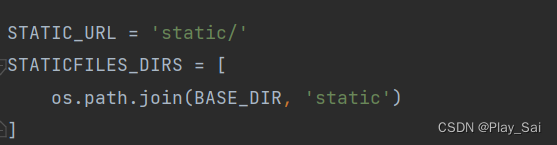
(3)配置静态文件(这里我由于存放清洗好的需要进行可视化的文件)
STATIC_URL = 'static/'
STATICFILES_DIRS = [
os.path.join(BASE_DIR, 'static')
]
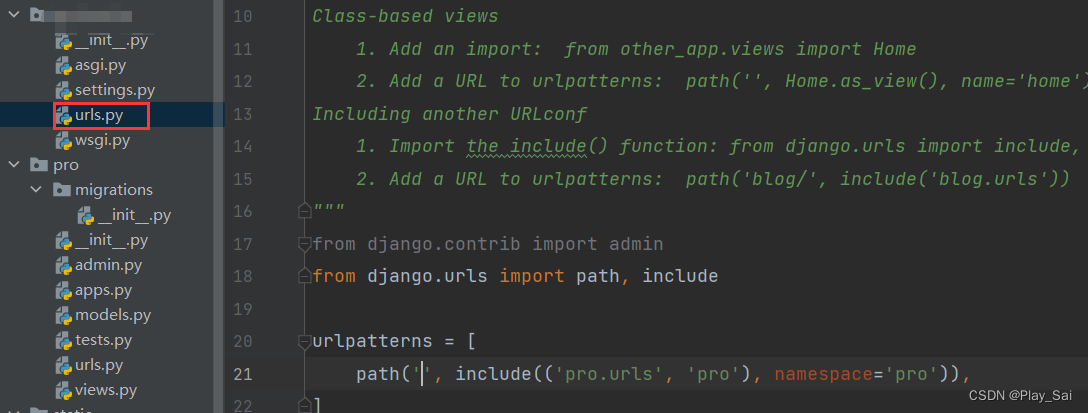
2.配置主路由(path后面的为“”表示默认,假设有多个会直接跳转到默认的)
urlpatterns = [
path('', include(('pro.urls', 'pro'), namespace='pro')),
]
3.app中的views文件
import pandas as pd
from django.shortcuts import HttpResponse, render, redirect
from pyecharts.charts import Page, Map3D, Pie, Line, Timeline, Radar
from pyecharts.components import Table
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ChartType
from django.contrib import auth, messages
from django.contrib.auth.models import User
data = pd.read_csv('static/data/更新后的水质.csv')
data = pd.DataFrame(data)
fn = """
function(params) {
if(params.name == '其他')
return '\\n\\n\\n' + params.name + ' : ' + params.value + '%';
return params.name + ' : ' + params.value + '%';
}
"""
def new_label_opts():
return opts.LabelOpts(formatter=JsCode(fn), position="center")
def map_pro(request):
# 2. 统计每个省份的水质类别总数
province_counts = data.groupby('省份')['水质类别'].count().reset_index()
province_counts['水质类别'] = province_counts['水质类别'].astype(int)
# 3. 提取每个省份的第一个经纬度
province_coords = data.groupby('省份').first()[['实测经度', '实测纬度']].reset_index()
# 使用 merge 函数将两个 DataFrame 合并
merged_data = pd.merge(province_counts, province_coords, on='省份')
# 使用 apply 函数对每一行进行操作,转换为所需格式
converted_data = merged_data.apply(lambda row: (row['省份'], [row['实测经度'], row['实测纬度'], row['水质类别']]),
axis=1).tolist()
print(converted_data)
# 打印转换后的数据
for item in converted_data:
print(item)
# 4. 绘制3D地图
c = (
Map3D(init_opts=opts.InitOpts(width="100%"))
.add_schema(
itemstyle_opts=opts.ItemStyleOpts(
color="rgb(5,101,123)",
opacity=1,
border_width=0.8,
border_color="rgb(62,215,213)",
),
map3d_label=opts.Map3DLabelOpts(
is_show=False,
formatter=JsCode("function(data){return data.name + " " + data.value[2];}"),
),
emphasis_label_opts=opts.LabelOpts(
is_show=False,
color="#fff",
font_size=10,
background_color="rgba(0,23,11,0)",
),
light_opts=opts.Map3DLightOpts(
main_color="#fff",
main_intensity=1.2,
main_shadow_quality="high",
is_main_shadow=False,
main_beta=10,
ambient_intensity=0.3,
),
)
.add(
series_name="质量分布情况",
data_pair=converted_data,
type_=ChartType.SCATTER3D,
bar_size=1,
shading="lambert",
label_opts=opts.LabelOpts(
is_show=False,
formatter=JsCode("function(data){return data.name + ' ' + data.value[2];}"),
),
)
.set_global_opts(visualmap_opts=opts.VisualMapOpts(is_show=False, max_=700),
legend_opts=opts.LegendOpts(textstyle_opts=opts.TextStyleOpts(color='#ededed')))
)
return HttpResponse(c.render_embed())
def pie_pro(request):
water_type = data.groupby('水质类别').size().reset_index(name='数量')
water_sum = sum(water_type['数量'])
print(water_type['水质类别'][4], water_type['数量'][4])
# for index, row in water_type[['水质类别', '数量']].iterrows():
# lis_col.append([row['水质类别'], '其他'])
# lis_other.append([row['数量'], water_sum])
p = (
Pie(init_opts=opts.InitOpts(width="100%"))
.add(
"",
[list(z) for z in zip(water_type['水质类别'][:3], water_type['数量'][:3])],
center=["20%", "30%"],
radius=[28, 40],
)
.add(
"",
[list(z) for z in zip([water_type['水质类别'][4], "其他"], [int(water_type['数量'][4]), water_sum])],
center=["38%", "30%"],
radius=[28, 40],
label_opts=new_label_opts(),
)
.add(
"",
[list(z) for z in zip([water_type['水质类别'][3], "其他"], [int(water_type['数量'][3]), water_sum])],
center=["56%", "30%"],
radius=[28, 40],
label_opts=new_label_opts(),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="水质类别占比", pos_top='20px', pos_left='20px',
title_textstyle_opts=opts.TextStyleOpts(color='#FFF', font_size=16)),
legend_opts=opts.LegendOpts(
type_="scroll", pos_top="20%", pos_left="80%", orient="vertical", is_show=False,
textstyle_opts=opts.TextStyleOpts(color='#FFF')
),
)
.set_series_opts(label_opts=opts.LabelOpts(color='#FFF'))
# .render('templates/pie.html')
)
return HttpResponse(p.render_embed())
def line_pro(request):
grouped_data = data.groupby(['省份', '监测时间', '水质类别']).size().reset_index(name='数量')
# 将监测时间的类型更改为日期时间类型
grouped_data['监测时间'] = pd.to_datetime(grouped_data['监测时间'])
# 格式化日期时间为年份和月份,并存储到新的列中
grouped_data['年月'] = grouped_data['监测时间'].dt.strftime('%Y-%m')
# 获取时间列表
dates = grouped_data['年月'].unique()
# 创建时间轴组件
timeline = Timeline(init_opts=opts.InitOpts(width='350px', height='290px'))
for date in dates:
# 获取该时间点的数据
data_by_date = grouped_data[grouped_data['年月'] == date]
# 创建折线图
line_chart = Line()
# 添加四种水质类别的数据
for water_type in ['一类', '二类', '三类', '四类']:
water_data = data_by_date[data_by_date['水质类别'] == water_type]
line_chart.add_xaxis(water_data['省份'].tolist())
line_chart.add_yaxis(water_type, water_data['数量'].tolist(), is_smooth=True, linestyle_opts={
'normal': {
'width': 3,
'shadowColor': '#696969',
'shadowBlur': 10,
'shadowOffsetY': 10,
'shadowOffsetx': 10,
'curve': 10
}
})
line_chart.set_global_opts(
title_opts=opts.TitleOpts(title="水质类别数量随时间变化"),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(type_="value"),
)
line_chart.set_global_opts(title_opts=opts.TitleOpts(title='各类监测水质时间',
title_textstyle_opts=opts.TextStyleOpts(color='#FFF',
font_size=16),
pos_left='left'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(is_show=True, color="pink")),
yaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(color='#F37282', is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True,
linestyle_opts=opts.LineStyleOpts(
type_='dashed',
color='#F37282')),
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color='#FFFFFF'))),
tooltip_opts=opts.TooltipOpts(axis_pointer_type='shadow'),
legend_opts=opts.LegendOpts(pos_top='30px',
textstyle_opts=opts.TextStyleOpts(color='#FFF'))
)
line_chart.set_series_opts(label_opts=opts.LabelOpts(color="#3CA6DE"))
# 将折线图添加到时间轴组件中
timeline.add(line_chart, date)
timeline.add_schema(
# axis_type='time', # axis_type表示时间轴类型,值可以是value(连续数值型)、category(离散型)、time(时间),如果是time,程序会自动计算时间间隔选择合适的显示格式
play_interval=1000, # 表示播放的速度(跳动的间隔),单位毫秒(ms)
is_auto_play=True, # 设置自动播放
is_timeline_show=True, # 不展示时间组件的轴
width='310px',
pos_left='1px',
is_loop_play=True # 是否循环播放
)
return HttpResponse(timeline.render_embed())
def table_pro(request):
# 创建 Table 组件实例
table = Table()
# 从数据中筛选出水质类别为“劣四类”的行
low_four = data[data['水质类别'] == '劣四类']
# 对省份进行分组,并求劣四类数量的总和
low_four_sum = low_four.groupby(['省份', '海区']).agg({'水质类别': 'count', 'pH': 'sum'}).reset_index()
# 按照劣四类数量的总和对省份进行降序排序
low_four_sum = low_four_sum.sort_values(by='水质类别', ascending=False)
low_four_sum = low_four_sum.rename(columns={'水质类别': '水质-劣四类'})
# 将数据转换为二维数组形式
rows = low_four_sum.values.tolist()
# 添加
table.add(headers=low_four_sum.columns.tolist(), rows=rows,
attributes={'align': 'left',
"style": "color:#3CA6DE;width:350px;height:500px; "
"font-size: 16px; padding:10px;text-align:center;border-collapse: collapse;"})
# 设置全局配置
table.set_global_opts(
{'title': '重点关注劣四类水资源', 'title_style': "style='color:#FFF';style='font-size:30px'"},
)
# table.render('templates/table.html')
return HttpResponse(table.render_embed())
def radar_pro(request):
sum_time = data.groupby(['省份', '监测时间']).size().reset_index(name='总数')
# 提取省份和监测时间数据
provinces = sum_time['省份'].unique()
times = sum_time['监测时间'].unique()
# 创建雷达图实例
radar = Radar(init_opts=opts.InitOpts(width='330px', height='500px'))
# 添加雷达图的 schema,将时间作为标签
radar.add_schema(
schema=[
opts.RadarIndicatorItem(name=time, max_=sum_time[sum_time['省份'] == time]['总数'].max()) for time in provinces
],
splitarea_opt=opts.SplitAreaOpts(is_show=False), # 不显示分割区域
)
# 添加数据到雷达图
color_list = ['#FF4500', '#4169E1', '#32CD32', '#FFD700', '#BA55D3', '#4682B4', '#FFA07A', '#87CEEB', '#20B2AA',
'#FF69B4'] # 颜色列表
for i, province in enumerate(times):
province_data = sum_time[sum_time['监测时间'] == province]['总数'].tolist()
color = color_list[i % len(color_list)] # 循环使用颜色列表
radar.add(
series_name=province, # 省份作为标签
data=[province_data],
linestyle_opts=opts.LineStyleOpts(width=2),
areastyle_opts=opts.AreaStyleOpts(opacity=0.2),
color=color,
)
# 设置雷达图全局配置
radar.set_global_opts(
title_opts=opts.TitleOpts(title="水质量分布情况",
title_textstyle_opts=opts.TextStyleOpts(color='#FFF', font_size=16)),
legend_opts=opts.LegendOpts(pos_top='35px', textstyle_opts=opts.TextStyleOpts(color="#FFF"))
)
radar.set_series_opts(label_opts=opts.LabelOpts(color='#3CA6DE'), linestyle_opts=opts.LineStyleOpts(color='pink'))
return HttpResponse(radar.render_embed())
def pic_all(request):
return render(request, 'index.html')
def login(request):
if request.method == "GET":
return render(request, "login.html")
if request.method == "POST":
username = request.POST.get("username")
password = request.POST.get("password")
print(username, password, 11111)
# 必须同时传入账户和密码
user = auth.authenticate(username=username, password=password)
# 验证
if user:
print('a')
auth.login(request, user)
return redirect("pro:looking")
else:
messages.add_message(request, messages.WARNING, "用户名或密码错误")
return render(request, "login.html", locals())
return render(request, "login.html")
4.查看效果图
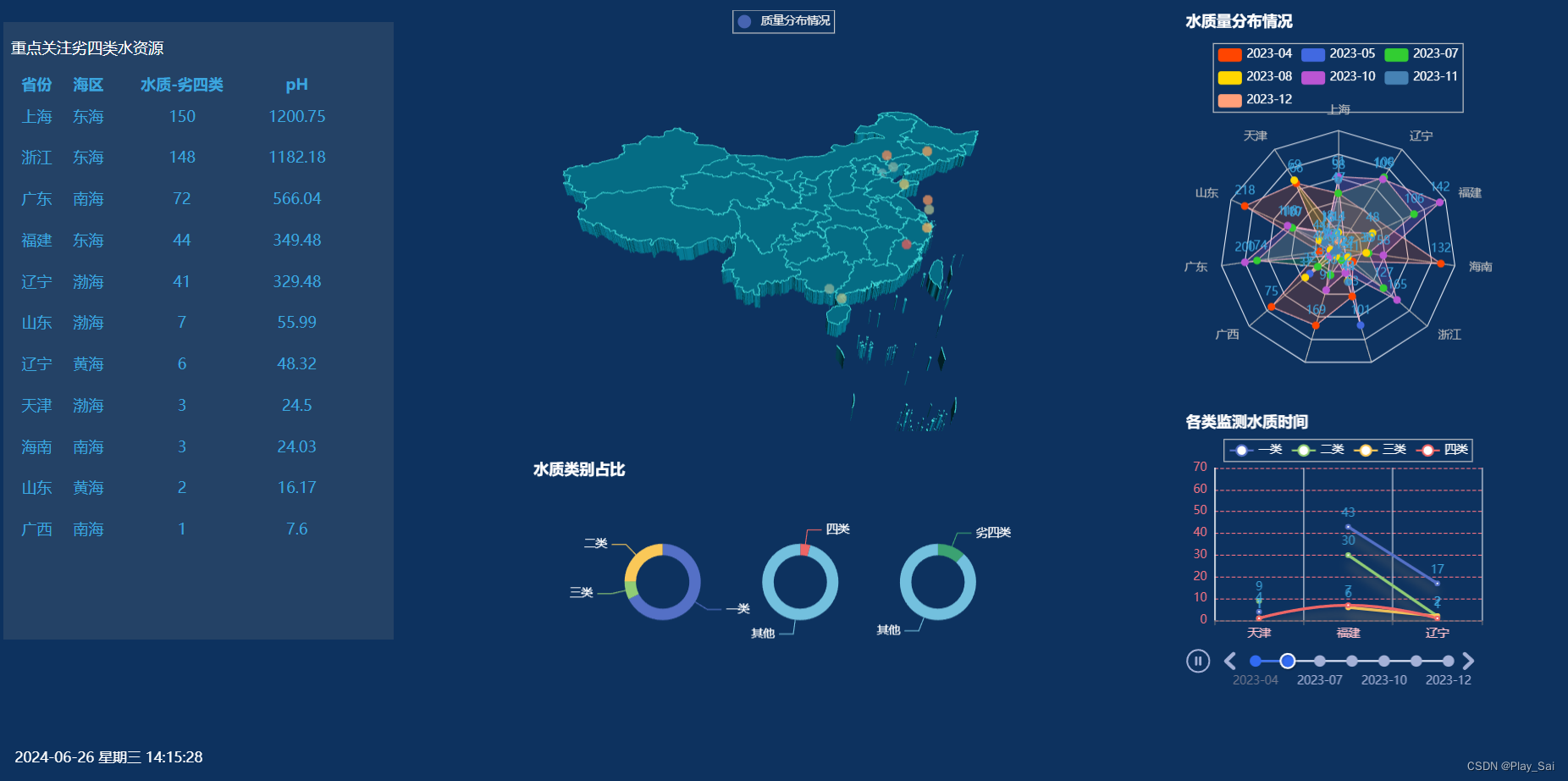
有其他问题可私信


![[leetcode]assign-cookies. 分发饼干](https://img-blog.csdnimg.cn/direct/5d2d1941f83e4bda9ed38f7d0460a3de.png)