本文借助Huggingface Tranformer库完成一个摘要生成任务,参考自https://github.com/datawhalechina/learn-nlp-with-transformers/,在本文,将展示如何使用简单的加载数据集,同时针对相应的任务使用transformer中的Trainer接口对模型进行微调。这里解决的是摘要生成任务。
本文的结构和Transformers官方文档一样,处理的文本也是英文文本,这里附上一个中文文本的很好的教程https://transformers.run/,github仓库为https://github.com/jsksxs360/How-to-use-Transformers
只要预训练的transformer模型包含seq2seq结构的head层,那么理论上可以使用各种各样的transformer模型,解决任何摘要生成任务。教程这里使用t5-small模型的checkpoint。
model_checkpoint = "t5-small"
环境配置
- 安装Transformers和Datasets库
! pip install datasets transformers rouge-score nltk
- 实践中会遇到的环境配置问题:
在使用Transformers的Seq2SeqTrainer时,可能会遇到如下报错:
ImportError: Using the Trainer with PyTorch requires accelerate: Run pip install --upgrade accelerate
这是因为Transformers和accelerate和pytorch的版本不兼容,经过查资料得到解决方案:使用版本为accelerate==0.27.2,transformers=4.38.1,torch=2.2.0(conda install pytorch2.2.0 torchvision0.17.0 torchaudio==2.2.0 pytorch-cuda=11.8 -c pytorch -c nvidia)可解决这个问题,详细的issue讨论参考https://github.com/hiyouga/LLaMA-Factory/issues/2552,https://github.com/huggingface/blog/issues/1042。
加载数据
使用Datasets库来加载数据和对应的评测方式,数据加载和评测方式加载只需要简单使用load_dataset和load_metric即可。
from datasets import load_dataset, load_metric
raw_datasets = load_dataset("xsum", trust_remote_code=True)
metric = load_metric("rouge", trust_remote_code=True)
这个datasets对象本身是一种DatasetDict数据结构,对于训练集、验证集和测试集,只需要使用对应的key(train, validation, test)即可得到相应的数据。
raw_datasets

给定一个数据的切分的key和下标即可查看数据:
raw_datasets["train"][0]

为了能够进一步理解数据长什么样子,下面的函数将从数据集里随机选择几个例子进行展示。
import datasets
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=2):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset) - 1)
while pick in picks:
pick = random.randint(0, len(dataset) - 1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, datasets.ClassLabel):
df[column] = df[column].transform(lambda i : typ.names[i])
display(HTML(df.to_html()))
show_random_elements(raw_datasets["train"])

metirc是datasets.Metric类的一个实例,查看metric和使用的例子:
metric
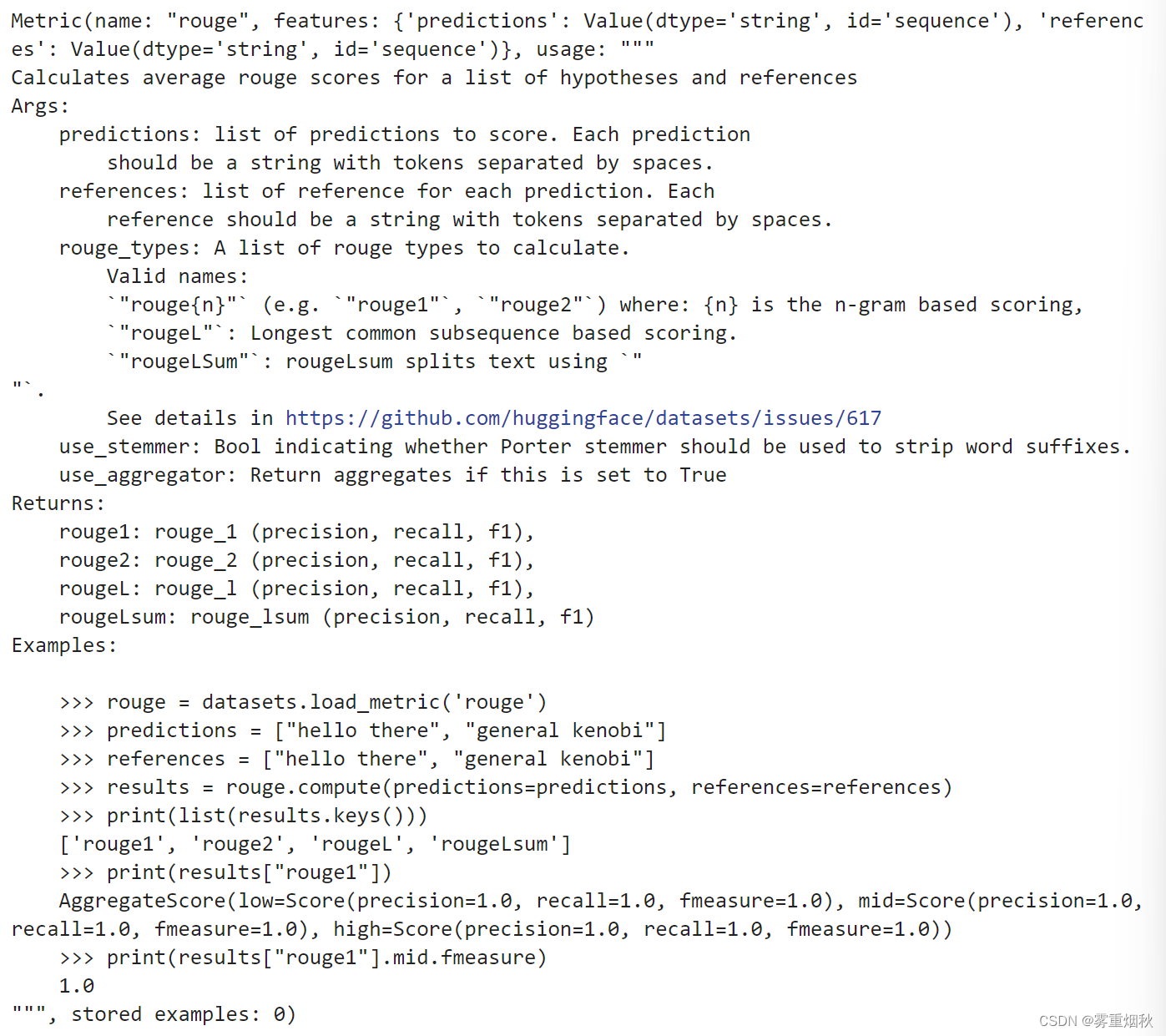
我们使用compute方法来对比predictions和labels,从而计算得分。predictions和labels都需要是一个list。具体格式见下面的例子:
fake_preds = ["hello there", "general kenobi"]
fake_labels = ["hello there", "general kenobi"]
metric.compute(predictions=fake_preds, references=fake_labels)

数据预处理
在将数据喂入模型之前,我们需要对数据进行预处理。预处理的工具叫Tokenizer。Tokenizer首先对输入进行tokenize,然后将tokens转化为预模型中需要对应的token ID,再转化为模型需要的输入格式。
为了达到数据预处理的目的,我们使用AutoTokenizer.from_pretrained方法实例化我们的tokenizer,这样可以确保:
- 我们得到一个与预训练模型一一对应的tokenizer。
- 使用指定的模型checkpoint对应的tokenizer的时候,我们也下载了模型需要的词表库vocabulary,准确来说是tokens vocabulary。
这个被下载的tokens vocabulary会被缓存起来,从而再次使用的时候不会重新下载。(这里使用了镜像源进行下载)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, proxies={"http": "https://hf-mirror.com/"})
默认情况下,上面的调用将使用 Tokenizers 库中的一个快速分词器(由 Rust 支持)。
tokenizer既可以对单个文本进行预处理,也可以对一对文本进行预处理,tokenizer预处理后得到的数据满足预训练模型输入格式
tokenizer("Hello, this one sentence!")

上面看到的token IDs也就是input_ids一般来说随着预训练模型名字的不同而有所不同。原因是不同的预训练模型在预训练的时候设定了不同的规则。但只要tokenizer和model的名字一致,那么tokenizer预处理的输入格式就会满足model需求的。关于预处理更多内容参考https://huggingface.co/docs/transformers/preprocessing
除了可以tokenize一句话,我们也可以tokenize一个list的句子。
tokenizer(["Hello, this one sentence!", "This is another sentencce."])

注意:为了给模型准备好翻译的targets,我们使用as_target_tokenizer来控制targets所对应的特殊token(现在的版本可以不这么做):
with tokenizer.as_target_tokenizer():
print(tokenizer(["Hello, this one sentence!", "This is another sentencce."]))

如果您使用的是T5预训练模型的checkpoints,需要对特殊的前缀进行检查。T5使用特殊的前缀来告诉模型具体要做的任务,具体前缀例子如下:
if model_checkpoint in ["t5-small", "t5-base", "t5-larg", "t5-3b", "t5-11b"]:
prefix = "summarize: "
else:
prefix = ""
现在我们可以把所有内容放在一起组成我们的预处理函数了。我们对样本进行预处理的时候,我们还会truncation=True这个参数来确保我们超长的句子被截断。默认情况下,对与比较短的句子我们会自动padding。
max_input_length = 1024
max_target_length = 128
def preprocess_function(examples):
inputs = [prefix + doc for doc in examples['document']]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
with tokenizer.as_target_tokenizer():
labels = tokenizer(examples["summary"], max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
以上的预处理函数可以处理一个样本,也可以处理多个样本exapmles。如果是处理多个样本,则返回的是多个样本被预处理之后的结果list。
preprocess_function(raw_datasets['train'][:2])

接下来对数据集datasets里面的所有样本进行预处理,处理的方式是使用map函数,将预处理函数prepare_train_features应用到(map)所有样本上。
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
更好的是,返回的结果会自动被缓存,避免下次处理的时候重新计算(但是也要注意,如果输入有改动,可能会被缓存影响!)。datasets库函数会对输入的参数进行检测,判断是否有变化,如果没有变化就使用缓存数据,如果有变化就重新处理。但如果输入参数不变,想改变输入的时候,最好清理调这个缓存。清理的方式是使用load_from_cache_file=False参数。另外,上面使用到的batched=True这个参数是tokenizer的特点,以为这会使用多线程同时并行对输入进行处理。
微调模型
既然数据已经准备好了,现在我们需要下载并加载我们的预训练模型,然后微调预训练模型。既然我们是做seq2seq任务,那么我们需要一个能解决这个任务的模型类。我们使用AutoModelForSeq2SeqLM这个类。和tokenizer相似,from_pretrained方法同样可以帮助我们下载并加载模型,同时也会对模型进行缓存,就不会重复下载模型啦。
from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
由于我们微调的任务是seq2seq任务,而我们加载的是预训练的seq2seq模型,所以不会提示我们加载模型的时候扔掉了一些不匹配的神经网络参数(比如:预训练语言模型的神经网络head被扔掉了,同时随机初始化了机器翻译的神经网络head)。
为了能够得到一个Seq2SeqTrainer训练工具,我们还需要3个要素,其中最重要的是训练的设定/参数Seq2SeqTrainingArguments。这个训练设定包含了能够定义训练过程的所有属性。
batch_size = 16
args = Seq2SeqTrainingArguments(
"test-summarization",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
predict_with_generate=True,
fp16=True,
)
上面evaluation_strategy = "epoch"参数告诉训练代码:我们每个epcoh会做一次验证评估。"test-summarization"是输出目录的名称,模型检查点和日志将保存在这个目录下,``fp16=True启用混合精度训练,使用16位浮点数进行计算以加速训练并减少内存使用,同时尽量保持模型精度。predict_with_generate=True设置在predict阶段使用模型的generate方法,用于文本生成任务。
上面batch_size在这个notebook之前定义好了。
由于我们的数据集比较大,同时Seq2SeqTrainer会不断保存模型,所以我们需要告诉它至多保存save_total_limit=3个模型(保留最新的3个检查点)。
最后我们需要一个数据收集器data collator,将我们处理好的输入喂给模型。
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
设置好Seq2SeqTrainer还剩最后一件事情,那就是我们需要定义好评估方法。我们使用metric来完成评估。将模型预测送入评估之前,我们也会做一些数据后处理:
import nltk
import numpy as np
def compute_metrics(eval_pred):
# 将传入的元组eval_pred解构成预测结果和实际的标签
predictions, labels = eval_pred
# 将模型生成的预测结果(经过编码的token id序列)解码成可读的文本,skip_special_tokens是跳过特殊的控制token
decoded_preds = tokenizer.batch_decode(predictions, skip_special_tokens=True)
# 使用numpy的where函数替换标签中的-100,如果labels不等于-100,则保留原值,否则用pad_token_id替换
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
# 解码label
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Rouge expects a newline after each sentence
# 使用nltk库的sent_tokenize函数对解码后的预测结果和标签进行句子分割,并将分割后的句子用换行符连接起来
decoded_preds = ["\n".join(nltk.sent_tokenize(pred.strip())) for pred in decoded_preds]
decoded_labels = ["\n".join(nltk.sent_tokenize(label.strip())) for label in decoded_labels]
# 调用评估指标函数,use_stemmer=True启用词干提取,有助于在计算相似度时提高评估的准确性
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
# Extract a few results
# 提取每个指标的F分数-Fmeasure
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
# Add mean generated length
# 计算每个预测结果的长度
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in predictions]
# 计算所有预测结果的长度的平均值,并将这个平均值作为gen_len(生成长度)添加到结果字典中
result["gen_len"] = np.mean(prediction_lens)
# 返回一个新字典,其中包含结果字典中的所有项,并将每个值四舍五入到四位小数
return {k: round(v, 4) for k, v in result.items()}
最后将所有的参数/数据/模型传给Seq2SeqTrainer即可
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
调用train方法进行微调训练。
trainer.train()
不同预训练模型和指标结果
首先先介绍一下指标:
- BLEU(BiLingual Evaluation Understudy):是一种衡量模型生成序列和参考序列之间的N-Gram重合度的算法,最早用来评价机器翻译模型的质量,目前也广泛应用在各种序列生成任务中,令
x
\bm x
x为从模型分布
p
δ
p_{\delta}
pδ中生成的一个候选(Candidate)序列,
s
(
1
)
,
.
.
.
,
s
(
K
)
s^{(1)},...,s^{(K)}
s(1),...,s(K)为从真实数据分布中采集的一组参考(Reference)序列,
W
W
W为从生成的候选序列中提取所有N元组合的集合,这些N元组合的精度(Precision)
P N ( x ) = ∑ w ∈ W min ( c w ( x ) , max k = 1 K c w ( s ( k ) ) ) ∑ w ∈ W c w ( x ) , P_N(\boldsymbol{x})=\frac{\sum_{w \in \mathcal{W}} \min \left(c_w(\boldsymbol{x}), \max _{k=1}^K c_w\left(\boldsymbol{s}^{(k)}\right)\right)}{\sum_{w \in \mathcal{W}} c_w(\boldsymbol{x})}, PN(x)=∑w∈Wcw(x)∑w∈Wmin(cw(x),maxk=1Kcw(s(k))),
其中 c w ( x ) c_w(x) cw(x)是 N N N元组合 w w w在生成序列 x x x中出现的次数, c w ( s ( k ) ) c_w(s^{(k)}) cw(s(k))是 N N N元组合 w w w在参考序列 s ( k ) s^{(k)} s(k)中出现的次数。 N N N元组合的精度 P N ( x ) P_N(x) PN(x)是计算生成序列中的 N N N元组合有多少比例在参考序列中出现。
由于精度只衡量生成序列中的
N
N
N元组合是否在参考序列中出现,生成序列越短,其精度会越高,因此可以引入长度惩罚因子(Brevity Penalty)。如果生成序列的长度短于参考序列,就对其进行惩罚:
b
(
x
)
=
{
1
if
l
x
>
l
s
exp
(
1
−
l
s
/
l
x
)
if
l
x
≤
l
s
b(\boldsymbol{x})=\left\{\begin{array}{ccc} 1 & \text { if } & l_x>l_s \\ \exp \left(1-l_s / l_x\right) & \text { if } & l_x \leq l_s \end{array}\right.
b(x)={1exp(1−ls/lx) if if lx>lslx≤ls
其中
l
x
l_x
lx为生成序列
x
\bm x
x的长度,
l
s
l_s
ls为参考序列的最短长度。
BLEU算法是通过计算不同长度的
N
N
N元组合的精度,并进行集合加权平均得到。
BLEU
−
N
(
x
)
=
b
(
x
)
×
exp
(
∑
N
=
1
N
′
α
N
log
P
N
)
\operatorname{BLEU}-\mathrm{N}(\boldsymbol{x})=b(\boldsymbol{x}) \times \exp \left(\sum_{N=1}^{N^{\prime}} \alpha_N \log P_N\right)
BLEU−N(x)=b(x)×exp
N=1∑N′αNlogPN
其中
N
′
N'
N′为最长
N
N
N元组合的长度,
α
N
\alpha_N
αN为不同
N
N
N元组合的权重,一般设为
1
N
′
\frac{1}{N'}
N′1,BLEU算法的值域范围是
[
0
,
1
]
[0,1]
[0,1],越大表明生成的质量越好。但是BLEU算法只计算精度,而不关心召回率(即参考序列里的
N
N
N元组合是否在生成序列中出现)。
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation):最早应用于文本摘要领域,和BLEU算法类似,但ROUGE算法计算的是召回率(Recall)。令
x
x
x为令
x
\bm x
x为从模型分布
p
δ
p_{\delta}
pδ中生成的一个候选(Candidate)序列,
s
(
1
)
,
.
.
.
,
s
(
K
)
s^{(1)},...,s^{(K)}
s(1),...,s(K)为从真实数据分布中采集的一组参考(Reference)序列,
W
W
W为从生成的候选序列中提取所有N元组合的集合,ROUGE-N算法的定义为:
ROUGE − N ( x ) = ∑ k = 1 K ∑ w ∈ W min ( c w ( x ) , c w ( s ( k ) ) ) ∑ k = 1 K ∑ w ∈ W c w ( s ( k ) ) , \operatorname{ROUGE}-\mathrm{N}(\boldsymbol{x})=\frac{\sum_{k=1}^K \sum_{w \in \mathcal{W}} \min \left(c_w(\boldsymbol{x}), c_w\left(\boldsymbol{s}^{(k)}\right)\right)}{\sum_{k=1}^K \sum_{w \in \mathcal{W}} c_w\left(\boldsymbol{s}^{(k)}\right)}, ROUGE−N(x)=∑k=1K∑w∈Wcw(s(k))∑k=1K∑w∈Wmin(cw(x),cw(s(k))),
其中 c w ( x ) c_w(x) cw(x)是 N N N元组合 w w w在生成序列 x x x中出现的次数, c w ( s ( k ) ) c_w(s^{(k)}) cw(s(k))是 N N N元组合 w w w在参考序列 s ( k ) s^{(k)} s(k)中出现的次数。
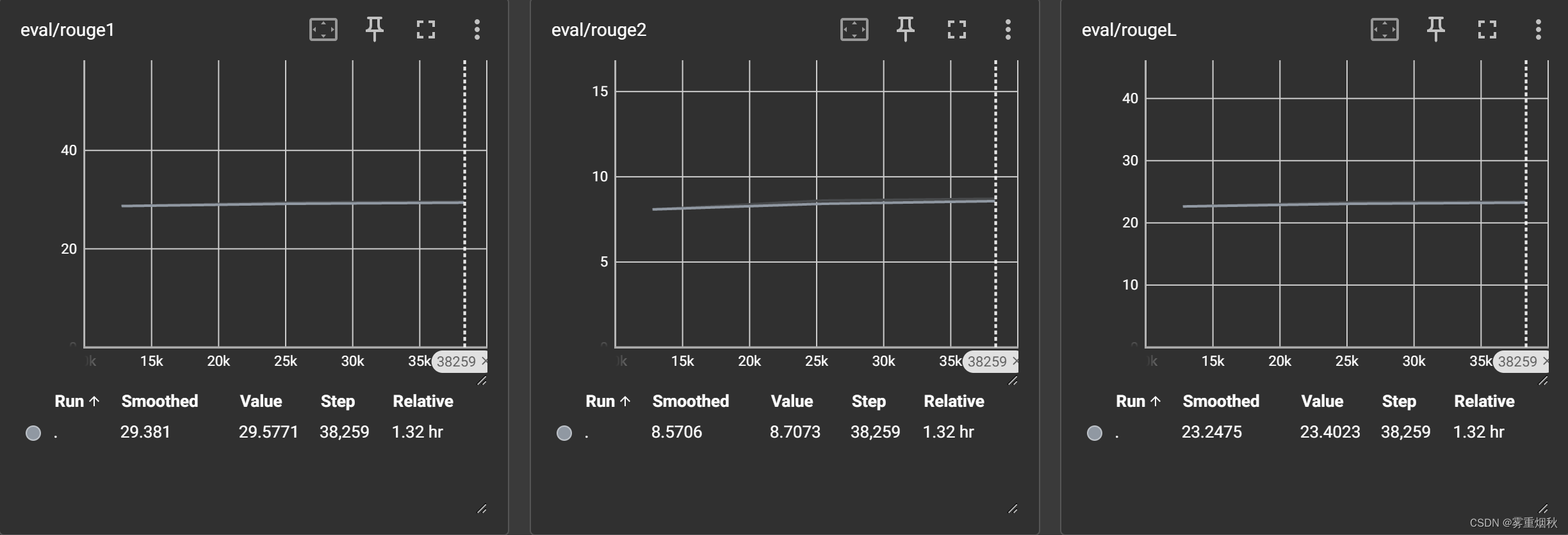
这里使用ROUGE-1、ROUGE-2、ROUGE-L、BLEU这4个指标(结果中的指标是*100的值,比如3%显示3)。
除了使用上文的t5-small模型之外,这里还使用mT5_multilingual_XLSum,pegasus-xsum,bart-large-cnn。
t5-small
训练结果
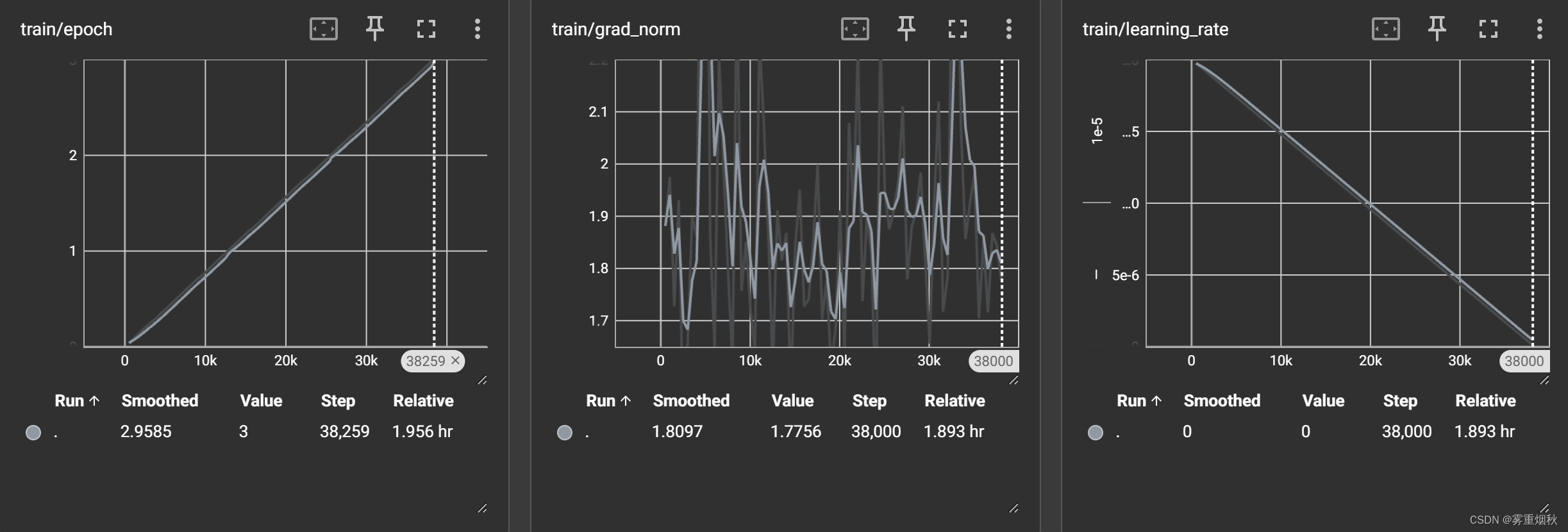
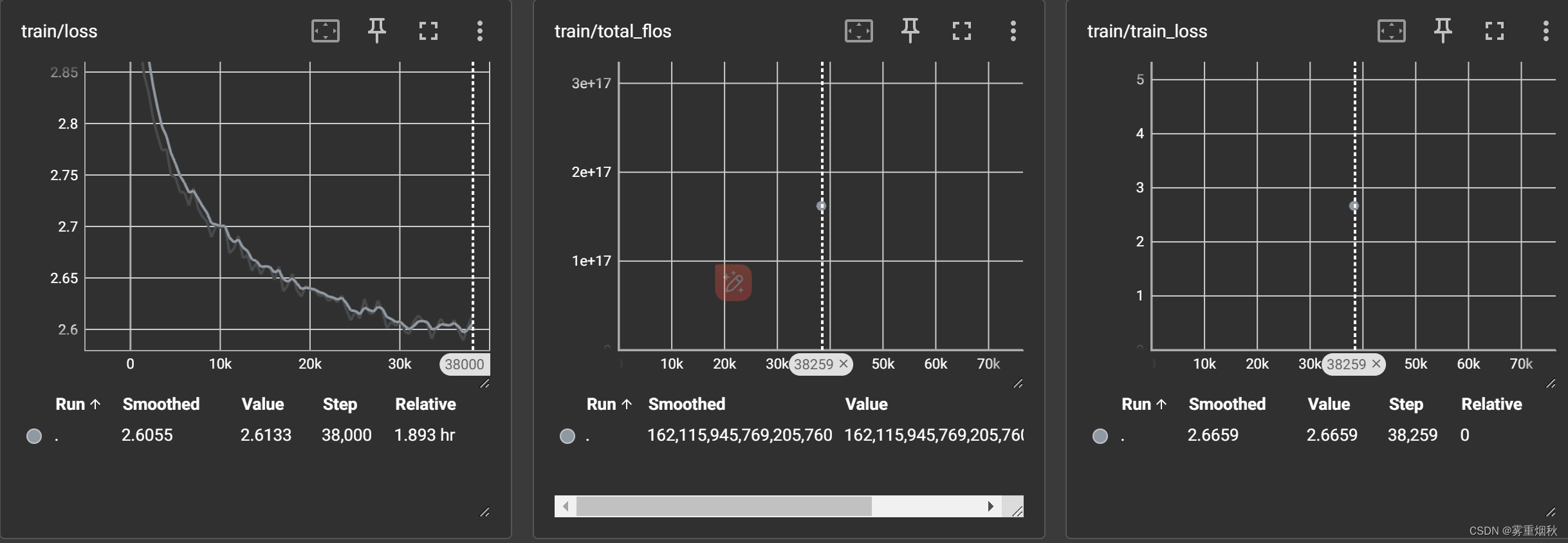
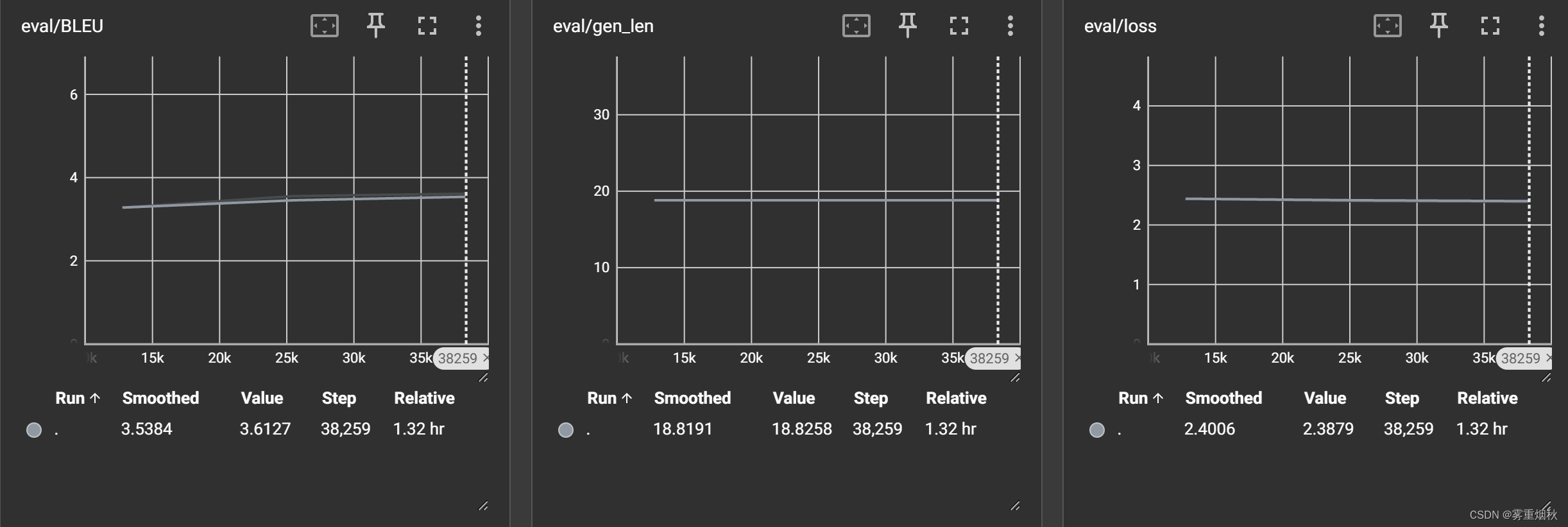
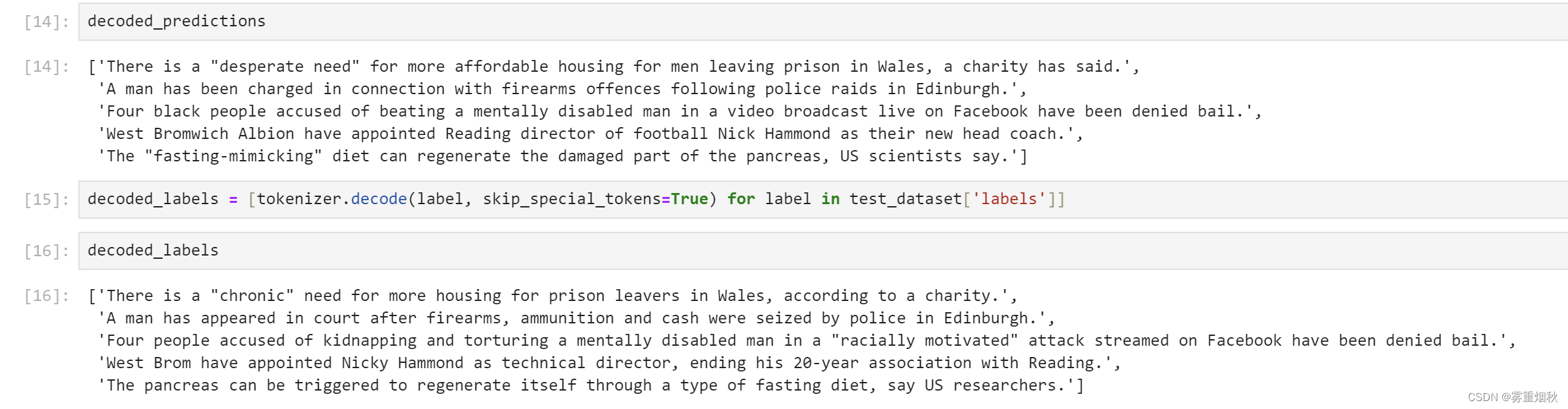
模型预测
test_dataset = tokenized_datasets["test"].select(range(5))
predictions = trainer.predict(test_dataset)
test_dataset

predictions

decoded_predictions = [tokenizer.decode(pred, skip_special_tokens=True) for pred in predictions.predictions]
decoded_predictions

decoded_labels = [tokenizer.decode(label, skip_special_tokens=True) for label in test_dataset['labels']]
decoded_labels

pegasus-xsum
训练结果

bart-large-cnn