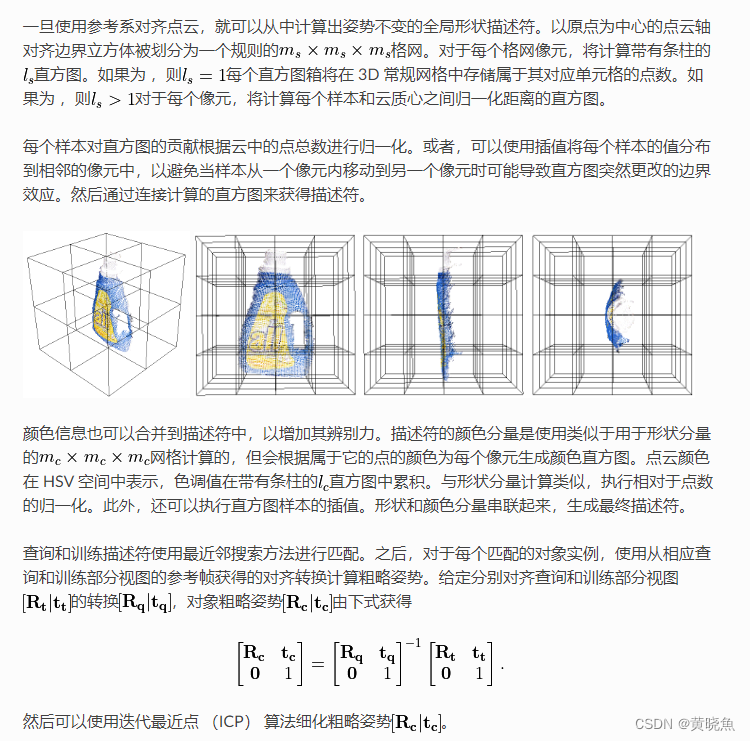
了解什么是 Web Worker
提供了可以在后台线程中运行 js 的方法。可以不占用主线程,不干扰用户界面,可以用来执行复杂、耗时的任务。
在worker中运行的是另一个全局上下文,不能直接获取 Window 全局对象。不同的 worker 可以分为专用和共享,专用 worker 仅在单一脚本中被使用,它的上下文对象是DedicatedWorkerGlobalScope;共享 worker 可以同时被多个脚本占用,它的上下文对象是SharedWorkerGlobalScope
在Worker中可以使用什么,不可以使用什么,只要不影响主线程,就可以使用。
- 不能直接操作 DOM
- 不能访问 Window 对象的默认方法和属性
- 可以访问并使用 Window 下的其他 API 对象,比如:websocket、indexDB、Navigator、XMLHttpRequest 等
worker和主线程之间通过postMessage发送消息,使用onmessage事件来监听收到的消息。交互过程中的数据是被复制传输的。
检测当前浏览器环境中是否支持worker。
if (window.Worker) {
// ...
}
测试生成大量的数据并排序,模拟耗时的任务。
console.log("执行任务1");
let start = performance.now();
let arr = [];
for (let i = 0; i < 1000000; i++) {
let num = Math.random() * 10000;
arr.push(num);
}
arr.sort();
let end = performance.now();
console.log("耗时-----", end - start);
console.log("执行任务2");

任务 2 被中间的耗时任务占用了主线程,等待耗时任务执行完才去执行。这样就造成了任务 2 的延后,得不到任务 2 的及时响应反馈。我们使用 worker 来解决,将这种任务放到其他线程去执行,最后只需要拿到结果就行。
专用Worker
创建一个work.js,将耗时任务放到这个 js 中。并通过postMessage向主线程发送消息。
// ...耗时任务
postMessage(arr);
在主线程中调用 work.js,并接收来自 work 的数据。
console.log("执行任务1");
let work = new Worker("./work.js");
work.onmessage = (e) => {
// ...
console.log("来自worker的数据:", e.data.length);
};
console.log("执行任务2");

放入Worker的耗时任务不会影响主线程其他任务执行,可以看到任务 1/2 很快执行完。主线程接收来自 worker 的数据,本质意义是让这些任务不要在主线程中执行,那么前端采用worker增加线程去执行,也可以直接将任务甩给后台去执行,在通过接口拿到结果。
worker 执行完毕后,如不使用则可以主动关闭。通过worker.terminate()调用方法终止线程,方法调用不会等待 worker 完成它剩余的任务。
错误处理,通过监听onerror监听 worker 运行中的错误.
错误事件参数包含:
message错误消息filename发生错误的脚本文件lineno发生错误所在脚本文件的代码位置
如果 worker 接收到一条无法被反序列化的消息时,将在对象上触发messageerror事件。
所有的事件也可以通过对象方法addEventListener去监听。
嵌套Worker
在一个 worker 中仍然可以调用另一个 worker。子 worker 解析的 URI 是相对父 worker 的地址而不是自身地址;它们必须托管在同源的父页面内。
创建一个subWorker.js,加入同样的代码,在worker.js中调用
// sub worker
let worker = new Worker("./subWork.js");
let start = performance.now();
// ... 耗时任务
let end = performance.now();
console.log("耗时-----", end - start);
worker.onmessage = (e) => {
console.log("sub worker数据:", e.data.length);
};
postMessage(arr);
在父 worker 中的耗时任务则会堵塞后续代码的执行,导致实际上子 worker 可能已经执行完了,但由于worker.onmessage在后面执行,导致迟迟拿不到结果,这就需要对于复杂并行的任务需要有一个很好的调度,以便更快拿到不受其他任务影响的当前任务的执行结果。
加载脚本
在 worker 中通过importScripts来加载第三方脚本,它可以接受多个参数来引入多个资源。
浏览器会并行列加载每一个脚本,每个脚本中的全局对象可以被 worker 使用。如果脚本加载失败,则抛出异常,停止后面代码的执行。importScripts 会等待所有脚本加载执行完毕才会继续执行,
可以利用 worker 加载前端的一些资源然后利用浏览器的缓存,主线程再去请求加载时则可以直接使用缓存。从而加快主线程的页面渲染;
我们提供一个utils.js函数,在work.js中加载后调用里面的方法
importScripts("./utils.js");
// ...
postMessage(add(2, 3));
在成功加载utils.js后,worker 就可以使用add()方法了。importScripts 加载的脚本是同步执行的,因此可以放心使用。
共享Worker
可以被多个脚本使用,即使这些脚本是被不同的 window、iframe 或者作为子 worker 访问。共享的 worker 必须是同源的,不能跨域。
共享 worker 一个最大的区别就是与脚本之间的通信必须通过port属性,它是一个确切打开的端口供脚本与 worker 通信,这在专用 worker 是隐形的。
通过SharedWorker来创建共享 worker,我们在创建一个 htmltest.html,和之前的index.html一样,让它们共享work.js
在页面中,重新创建共享 worker 加载 share-worker.js
console.log("执行任务1");
let work = new SharedWorker("./share-worker.js");
work.port.onmessage = (e) => {
// ...
console.log("来自worker的数据:", e.data.length);
};
console.log("执行任务2");
然后在share-worker.js中发送数据
// ...
onconnect = (e) => {
const port = e.ports[0];
port.postMessage(e);
};
结构化克隆算法
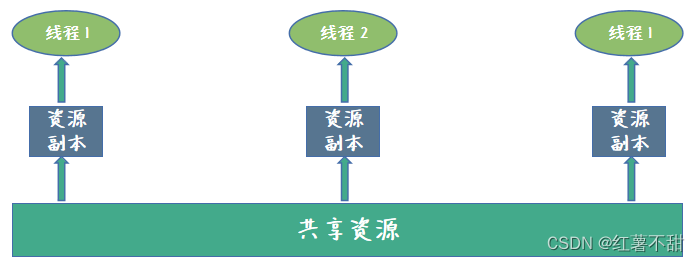
worker 在于脚本通信的时候,数据值复制的,而不是共享的。这里是用到了结构化克隆算法,有几个注意的地方:
Function不能被克隆,会抛出DATA_CLONE_ERR异常- DOM 节点不被允许克隆,抛出异常
- 对象的某些参数不被保留,比如:RegExp 对象的 lastIndex 字段不会被保留;属性描述符;原型链上的属性
全局的structuredClone()使用了结构化算法克隆对象,它是一种深拷贝,而且它还支持把可转移对象转移到新对象。就是将可转移对象与原对象分离,然后附加到新对象上。
可转移对象:ArrayBuffer \ MessagePort \ ReadableStream \ WritableStream \ TransformStream \ AudioData \ ImageBitmap \ VideoFrame \ OffscreenCanvas \ RTCDataChannel
里面就ArrayBuffer使用过,其他都没用过,做一个测试
let buffer = new ArrayBuffer(8);
console.log("buffer:", buffer.byteLength);
// 普通克隆
let newBuffer = structuredClone(buffer);
console.log("buffer:", buffer.byteLength, "newBuffer:", newBuffer.byteLength);
这时仅是数据的复制,原对象buffer的长度还在。使用对象转移拷贝:
let newBuffer = structuredClone(buffer, { transfer: [buffer] });
原对象还可以访问,只是分配占用的内存没有了,它已经转移给新对象了。structuredClone还可以处理循环引用

所以在 worker 之间传输可转移对象,效率是非常快的。当然这样就导致在主线程中不能再使用原始对象访问数据。
需要在脚本和 worker 之间转移对象,需要增加postMessage第二个参数:数组列出需要转移的对象
// ... 脚本其他任务
work.postMessage(buffer, [buffer]);
Worker API
创建Worker时,除了第一个参数为脚本的 URL,还接受第二个参数options,包含:
typeworker 类型,默认classic,可指定modulecredentials凭证,可以是omit \ same-origin \ include,未制定默认是omit(不要求凭证)nameworker 名称,用于调试。
在Worker中有自己的全局作用域,通过self访问,专用 worker 为DedicatedWorkerGlobalScope,包含了全局函数、命名空间以及构造器。除了name属性其余都继承于WorkerGlobalScope
name创建 worker 时设置的名称。console返回与当前 worker 相关联的Consolelocation返回与当前 worker 相关联的WorkerLocation(是浏览器 Location 的子级,适配了 worker)navigator返回与当前 worker 相关联的WorkerNavigator(是浏览器 Navigator 的子级,适配了 worker)performance返回与当前 worker 相关联的performance
实现了来自WindowTimers \ WindowBase64的方法,可以使用atob \ btoa \ setInterval \ setTimeout方法等。
共享 worker 的全局对象为SharedWorkerGlobalScope,它也是继承自WorkerGlobalScope
其他类型的Worker
除了Worker,还有其他的一些 workder。
Service Worker可作为代理服务器,目的是创建有效的离线体验,可以拦截网络请求、缓存网路资源,并根据网络采取合适的行动,比如导航到不同的服务器。结合Push API可以实现离线消息推送,即使用户没有打开当前应用,也能及时收到消息。
Audio Worklet 用于处理音频数据,它允许开发者在音频工作线程中运行 JavaScript 代码。实时音频效果处理,合成器等